技术拆解(十一):为什么你连7B模型都微调不动?从 SFT 到 QLoRA,再到 AWQ/GPTQ 部署,算清这笔显存账
一AWQ 量化 / GPTQ 量化
1.原理
两者的原理已在上一篇有具体讲解,不再阐述。两种方法的区别也很清晰:AWQ 的核心在于“激活感知的缩放保护”,GPTQ 的核心在于“逐列量化 + 二阶误差补偿”。两者均可用于 4-bit 权重量化,且推理时都是 W4A16 的权重反量化计算。
2.训练显存占用
严格来说,AWQ 和 GPTQ 不属于训练/微调方法,而是后训练量化方法,因此不存在传统意义上的训练显存占用。但在量化过程中仍有显存消耗,以7B模型为例,主要由以下主要部分构成:
|
组件 |
显存占用 |
说明 |
|---|---|---|
|
FP16/BF16 原始权重 |
~14 GB |
必须先加载全精度模型才能量化 |
|
校准数据激活 |
1–4 GB |
批量前向传播,收集逐层统计或 Hessian |
|
量化中间缓冲 (scale/zero等) |
0.5–2 GB |
取决于 group size |
|
临时计算缓冲 |
2–4 GB |
矩阵运算、Cholesky 分解等 |
|
合计(量化期间) |
≈20–30 GB |
小于 SFT 训练,但高于最终推理显存 |
注:做 AWQ 或 GPTQ 时,需要准备一小批校准数据(通常只需几百条样本,batch size 不大),主要用于处理异常激活值。量化通常需要将原始模型完整加载在显存中,再加上校准数据的中间激活、量化过程中一些元数据的存储(例如 scale、zero-point、group-wise 参数),总显存占用一般在 20–30 GB 级别,一般单张 A100 80G 通常可以完成,但 70B 模型就必须多卡或使用 CPU offload。量化阶段的显存通常小于全量 SFT(因为不需要存梯度和优化器状态),但仍然可能明显高于最终推理显存,因为推理时权重已经是 4-bit 压缩格式,且没有校准数据带来的激活和中间缓存。
3.具体实现细节
从工程角度来看,AWQ/GPTQ 量化的典型流程如下:
①准备 FP16/BF16 基座模型,例如从 HuggingFace 加载 LLaMA、Mistral 等。
②准备校准数据集,比如从训练集中随机采样 128–512 条样本,确保数据分布尽量覆盖真实使用场景。
③选择量化 bit 数和 group size:通常 weight 量化到 4-bit,group size 设为 32、64 或 128。group size 越小,量化粒度越细,精度通常越高,但元数据 (scale/zero) 的开销也更大。一般来说128比较常用。
④逐层收集信息:
- AWQ:使用校准数据跑一次前向,收集每个线性层的输入激活,计算逐通道统计(如均值),进而得到缩放因子,再执行权重量化。
- GPTQ:按层依次量化,每层对权重列使用基于 Hessian 的补偿公式,通过贪心顺序完成量化。
⑤执行权重量化并保存,常见格式如 GPTQ 的量化 checkpoint 或 AWQ 的模型文件,内部包含 int4 权重 pack 格式以及 scale、zero 等参数。
⑥推理时加载量化权重,由推理引擎在计算时实时反量化为 FP16,完成 W4A16 矩阵乘法。
常用工具链:AutoAWQ(AWQ 的易用封装)、AutoGPTQ、GPTQ-for-LLaMa 等。推理部署方面,vLLM、TensorRT-LLM、llama.cpp 等均已支持 AWQ/GPTQ 量化模型的加载与高效推理。
注:量化训练时一般直接用封装好的组件就可以直接做,嫌麻烦一般社区都有做好的开源量化模型,下载使用即可,例如千问系统就很丰富。
4. 推理显存占用
推理显存由以下主要部分构成:
|
组件 |
显存占用 |
说明 |
|---|---|---|
|
量化权重 + 元数据 (4-bit) |
3.5–4.5 GB |
int4 打包权重约 3.5 GB,group_size=128 时 scale/zero 约 0.2–0.5 GB |
|
KV Cache (FP16) |
2–4 GB |
每个 token 约 0.5 MB,seq_len=4096 时约 2 GB,8192 时约 4 GB |
|
激活缓冲 |
0.5–1.5 GB |
单次前向的中间张量,与序列长度相关 |
|
框架 / 运行时开销 |
1–2 GB |
CUDA context、workspace、memory pool |
|
合计 |
≈8–9 GB |
推理不需要梯度和优化器,显存主要被权重和 KV Cache 瓜分 |
需要特别强调的是:以上推理都是只考虑单线程使用的资源消耗情况,当并发请求下,会带来KV Cache线性增长导致显存爆炸,所以要留出显存冗余应对。此时也可以进行 KV Cache 量化或 paged attention 等优化。
二 全量SFT
1.原理
SFT (Supervised Fine-Tuning) 是在预训练模型基础上,使用人工标注或构造的 instruction-response 数据继续训练,让模型学习特定任务、问答格式、领域知识或指令跟随能力。
SFT 与其他训练范式的区别在于:
①预训练数据规模极大、分布广泛、无特定格式约束,目标是学习语言的基础知识和推理能力【学习通用知识】
②SFT 数据量相对小且高度结构化,目标是对齐到具体任务和交互方式。【学会怎么答题】
③RLHF/DPO/GRPO 强化学习:SFT 仅通过 next-token prediction 学习,而 RLHF 会引入奖励模型和策略优化,DPO 则直接基于偏好对数据优化策略,这两者更侧重于对齐人类偏好。此外强化学习范式还有DeepSeek的基于策略的强化学习GRPO,以上三种强化学习后续可以单独拿出来仔细讲解。【人类价值对齐,怎么答好题】
2.训练显存占用
全量 SFT 的显存构成十分庞大,对于使用 AdamW 优化器进行混合精度训练的情况,每个可训练参数大致需要存储:
| 组件 | 显存 |
|
模型参数(FP16) |
14GB |
|
梯度(FP16) |
14GB |
|
Adam优化器状态(FP32的精度)(只存一阶动量+二阶动量,一个大小就是28) |
56GB(28*2) |
|
激活值(batch=32, seq=1024) |
~40GB |
|
合计 |
~120-130GB |
因此全量 SFT 7B 模型在实际中基本需要多卡,例如 4 张 A100 80G 使用 ZeRO-3 策略。降低训练显存的方法包括:
-
Gradient checkpointing:用额外的计算换显存,只保留部分激活的 checkpoint,反向传播时重新计算中间激活。
-
ZeRO 分布式策略:ZeRO-1 将优化器状态分片,ZeRO-2 增加梯度分片,ZeRO-3 进一步将参数也分片到各卡,极大降低单卡显存。
-
混合精度训练:FP16/BF16 前向,FP32 主权重,动态 loss scaling。
3.具体实现细节
SFT 本质上仍然是语言模型的 next-token prediction,只不过数据从无标注文本变成了“问题-答案”对。工程上,SFT 训练时通常只对 answer 部分计算 loss,而 prompt/question 部分的 label 设置为 -100(PyTorch 的 CrossEntropyLoss 默认忽略 index=-100 的 token)。这样做是因为:如果模型在 prompt 部分也计算 loss,它会学习去复述问题,而不是专注于生成正确的答案;同时这还浪费了模型容量去拟合固定的提示文本,对下游泛化没有帮助。因此 label=-100 是一种标准做法。
工程流程如下:
①加载 FP16/BF16 基座模型。
②构造 instruction-response 数据集,每条数据包含 prompt 和 answer。
③使用 tokenizer 对文本编码。一般拼接成固定格式,例如 :"<|user|>\n{instruction}\n<|assistant|>\n{response}",并附加 eos token。
④构造 labels 数组:将 prompt 部分的 token 对应的 label 置为 -100,answer 部分保留原始 token id。
⑤设置 max_length、padding(通常左侧或右侧 padding,并设 pad_token_id)、truncation。
⑥训练精度选 BF16 或 FP16,配置 per_device_train_batch_size 和 gradient_accumulation_steps,使 global batch size 合理(常见 64–128)。
⑦设置学习率(例如 2e-5)、warmup ratio(0.03)、cosine 学习率衰减。
⑧根据需要开启 gradient_checkpointing(梯度检查点)
⑨定期保存 checkpoint 并评估。
4.推理显存占用
SFT 后模型的参数规模没有变,如果是全量微调,推理时加载的是完整的微调后权重。例如 7B FP16 模型权重仍然约 14 GB,再加上 KV Cache 和激活,推理显存与基座模型基本一致。SFT 本身不会降低推理显存,由以下主要部分构成:
|
组件 |
显存占用 (7B, r=8) |
说明 |
|---|---|---|
|
微调后模型权重 (FP16) |
14 GB |
与基座相同 |
|
KV Cache |
2–10 GB+ |
取决于 seq_len 和 batch |
|
中间激活 |
0.5–2 GB |
单层缓冲 |
|
合计 |
≈17–26 GB |
推理显存没有任何降低 |
三LoRA
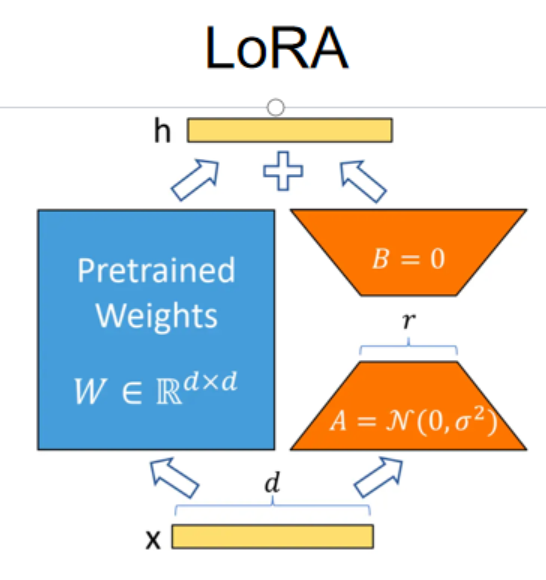
1.原理
LoRA (Low-Rank Adaptation) 的核心思想是:冻结预训练模型的全部参数,在每个需要调整的线性层旁边增加一个低秩旁路分支,只训练该分支的参数。

有意思的问题:
问题1:为什么 LoRA 先降维再升维?传统的 FNN(如 SwiGLU 的 FFN)结构是先升维再降维?
回答:
①LoRA 的核心目的是在微调时修改模型,但只引入极少的新参数。它是一个参数高效的修改器,用两个小矩阵去近似一个大矩阵的“变化量”,方向是“降维提取核心变化,再升维应用回去"
②传统 FNN(如前馈层)的目的是增加模型的表达能力和非线性。它是一个容量巨大的特征提取器,通过先拓宽维度来捕捉复杂关系,再压缩成有用特征。
问题2:缩放因子 α 为什么可以设为 32?
回答:h=W0x+α/r⋅BAx。原来矩阵是通过α/r来控制对原始权重的修改的。α/r 就像一个全局的学习率缩放器,用来控制这个低秩分支对原始输出的影响强度。常见配置 r=8,α=16时实际缩放为 2;r=8,α=32 时为 4。太小的α导致LoRA更新缓慢、微调效果不明显;太大的α可能过度扰动原始模型学到的先验,导致训练不稳定甚至灾难性遗忘。32这一经验值在r=8或r=16时往往能提供一个合理的初始扰动比例,结合适当的学习率能稳定收敛,但具体仍需要根据任务规模和数据量调参,并非绝对标准。
2.训练显存占用
LoRA 训练显存远小于全量 SFT,原因在于:基座模型权重冻结,不需要为这些权重存储梯度和优化器状态。优化器仅维护 LoRA 参数(A和 B)的状态,这部分参数量极小。前向传播仍需加载整个基座模型(FP16 14 GB),并产生中间激活,因此 LoRA 训练显存并不是只由 LoRA 参数决定,而是基座权重 + 激活 + LoRA 参数/梯度/优化器状态。
| 组件 | 估算显存 | 说明 |
|---|---|---|
| 基座模型 (FP16) | 14 GB | 7B参数 × 2字节/参数-1。 |
| LoRA 参数 (FP16) | ~0.02 GB | 与QLoRA相同,仅训练少量参数-。 |
| LoRA 梯度 | ~0.02 GB | 与可训练参数大小一致。 |
| LoRA 优化器状态 | ~0.08 GB | 与QLoRA一致,假设使用Adam优化器。 |
| 激活值 (Gradient Checkpointing) | ~5-15GB | 开启Gradient Checkpointing后,与QLoRA 几乎一致。 |
| 其他缓冲 | ~1-2 GB | 用于框架预留等。 |
| 合计 | ~22-30 GB | 常见于24GB+高容量显卡。 |
3.具体实现细节
LoRA可应用于任意线性层,因为其形式y=Wx可以直接叠加ΔW。实际中最常加在注意力层的q_proj、k_proj、v_proj、o_proj,也可加在MLP的up_proj、down_proj、gate_proj等,但过多模块会增加可训参数量,需要权衡显存和效果。
工程流程:
① 加载 FP16/BF16 基座模型,设置
torch_dtype和device_map。② 使用 PEFT 库配置 LoRA:指定
r、lora_alpha、lora_dropout、target_modules(例如["q_proj", "v_proj"]),task_type=CAUSAL_LM。③ 调用
get_peft_model(model, lora_config)注入 adapter,自动冻结原始参数。④ 构造 SFT 数据,prompt 部分
label=-100。⑤ 仅训练 LoRA 参数(PyTorch 中
requires_grad会自动设置)。⑥ 保存 adapter 权重(通常只有几 MB),而不是整个模型。
⑦ 推理时:可以选择加载基座模型 + adapter 权重并用 PEFT 的前向逻辑计算;也可以调用
merge_and_unload()将 ΔW 合并进基座权重,得到完整 FP16 模型。LoRA 插件与基座模型merge 与不 merge 的区别:不 merge 时模型结构保持“基座 + LoRA 旁路”,适合需要频繁切换多个 adapter 的场景(如多租户),但推理多了额外分支计算;merge 后 LoRA 的权重被吸收进 W0,模型恢复为普通线性层,部署简单,推理与原生模型无异,但不能再解绑 adapter。
4.推理显存占用
LoRA 本身并不会天然降低推理显存,模型结构等价于原始 FP16 模型,推理显存与同精度基座模型完全相同。LoRA 的收益在于训练时显存和存储 adapter,推理并没有压缩。
|
组件 |
显存占用 |
说明 |
|---|---|---|
|
基座权重 (FP16) |
14 GB |
完整加载 |
|
LoRA adapter |
<0.1 GB |
额外开销极小 |
|
KV Cache |
2–10 GB+ |
取决于 seq_len 和 batch |
|
中间激活 |
0.5–2 GB |
单层缓冲 |
|
合计 |
≈17–26 GB |
几乎等于 FP16 基座推理 |
如果想在 LoRA 微调后降低推理显存,标准路径是:LoRA 微调 → (7B基座模型+16bitLORA权重文件)merge 得到 FP16 微调模型 → 使用 AWQ/GPTQ 量化为 4-bit → 推理时加载量化模型。这样最终推理显存落在 4-bit 级别,同时兼具 LoRA 的高效微调能力。
而且LORA有个优点是可拔插,方便取用别人微调好的LORA插件,在社区可与他人交流获取,获取不一样的模型输出风格(可爱、御姐、严肃、专业等)。
4. QLoRA
1.原理
QLoRA = 4-bit 量化基座模型 + 16-bit LoRA adapter 训练。它把“训练省显存”推到了极致。
QLoRA 的核心做法是:基座模型以 4-bit 格式加载并冻结,前向计算时通过反量化恢复权重到 16-bit 进行计算(即 W4A16),反向传播时梯度只流经 LoRA adapter 参数,不更新基座权重。因此,基座模型的 4-bit 权重始终只是“只读”的,而 LoRA adapter 保持着 FP16/BF16 的高精度。
其中 QLoRA 使用的 NF4 (NormalFloat4) 是一种专门为近似正态分布的神经网络权重量身定制的 4-bit 数据类型。预训练模型的权重通常呈类正态分布,普通 int4 均匀量化会丢失分布的尖峰特性,NF4 通过信息论最优的分位点划分,在量化时保留更多信息。QLoRA 还配合 double quantization(对 scale 进一步量化)和 paged optimizer(利用统一内存分页优化梯度检查点)进一步压缩显存。
需要明确:QLoRA 不是把 LoRA adapter 也量化为 4-bit 训练,adapter 通常仍是 16-bit。训练时是“4-bit 基座 + 16-bit LoRA”,推理时若直接使用 adapter 方式加载,就是 4-bit 基座 + LoRA adapter,推理显存主要由 4-bit 基座决定。也可以先 merge 再重新量化,但需注意顺序:直接 merge 后模型会变成 FP16,然后需再经 AWQ/GPTQ 量化。
2.训练显存占用
| 组件 | 显存 | 说明 |
| 基座模型 (4-bit量化) | ~4-5 GB | 4-bit理论值约3.5GB,加上量化元数据总量约4-5GB。 |
| LoRA 参数 (BF16) | ~0.02 GB | 参数极小,几乎可忽略-。 |
| LoRA 梯度 | ~0.02 GB | 与可训练参数相同精度,大小基本一致。 |
| LoRA 优化器状态 | ~0.08 GB | 假设使用Adam,每个参数需维护两个状态。 |
| 激活值 (Gradient Checkpointing) | ~5-10 GB | 2048长度下实测约5-10GB. |
| Paged Optimizer及其他缓冲 | ~1-3 GB | 分页优化器使用CPU内存,显存占用小。 |
| 总计 | ~16-23 GB | 主流消费级24GB显卡可运行。 |
QLoRA 的显存优势来源于基座模型以 4-bit 形式存储。
-
7B 模型 FP16 权重约 14 GB,4-bit 理论仅 3.5 GB,加上 scale/zero 等量化元数据约额外 0.5–1 GB,因此基座权重部分约 4–5 GB。
-
LoRA adapter 参数很小(数 MB),但梯度、优化器状态和激活仍占显存。激活显存与序列长度和 batch size 强相关,假如序列长度 2048,激活约需 10–15 GB。
-
Paged optimizer 使用 CPU 内存作为 paging 缓冲,可在显存紧张时将优化器状态分页到 CPU。
典型 7B QLoRA 训练,在序列 2048、batch size 1、开启 gradient checkpointing 时,单卡 24 GB 显存(如 RTX 3090/4090)即可训练,而同样的 LoRA(FP16 基座)可能需要 22-30 GB。相比全量 SFT,QLoRA 的显存减少超过 70%。
3.具体实现细节
工程流程:
① 使用
bitsandbytes以 4-bit 加载基座模型,设置load_in_4bit=Truebnb_4bit_compute_dtype=torch.bfloat16,bnb_4bit_quant_type="nf4"bnb_4bit_use_double_quant=True。② 基座模型加载后所有参数自动冻结。
③ 通过 PEFT 注入 LoRA adapter,设置
r、lora_alpha、target_modules、lora_dropout等,adapter 默认 FP16/BF16。④ 构造 SFT 数据,prompt 部分
label=-100。⑤ 训练,只更新 LoRA 参数。
⑥ 保存 LoRA adapter(不含基座)。
⑦ 推理时加载 4-bit 基座 + LoRA adapter 即可直接使用。
4.推理显存占用
分情况讨论:
-
场景 A(QLoRA 训练,adapter 推理)【推荐】:训练阶段基座是 4-bit,LoRA插件 是 16-bit;推理时直接加载 4-bit 基座 + 16-bit adapter → 显存 ≈ 基座(4-5 GB) + adapter(<0.1 GB) + KV Cache + 激活 ≈ 6–9 GB。。这是“一步到位”的训练+推理低显存方案。
-
场景 B(QLoRA后-再merge 后-再 AWQ 量化):QLoRA训练完后,将16bit的LoRA插件merge 到 FP16 模型,再对该 FP16 模型做 AWQ 4-bit 量化。最终推理显存同 AWQ/GPTQ 推理显存 ≈ 6–8 GB。该路径训练阶段显存需求更大(通常需 24GB+),但有时能获得稍好的微调精度。
五横向对比总结
|
方法 |
主要目标 |
是否更新基座权重 |
训练显存 |
推理显存 |
多 adapter 切换 |
典型场景 |
注意事项 |
|---|---|---|---|---|---|---|---|
|
AWQ/GPTQ |
降低推理显存,加速推理 |
否 |
仅量化过程需要原始模型 + 校准数据(中等) |
显著降低(7B 约 6–8 GB) |
不适合(不同任务需重量化) |
模型部署、推理优化 |
长上下文时 KV Cache 可能仍是瓶颈 |
|
SFT (全量微调) |
任务适配、指令跟随 |
是 |
极大(7B 需 120 GB+,需多卡) |
与原始模型相同(7B 约 14 GB+) |
不适合 |
高精度任务适配、后接量化 |
训练成本高,需分布式 |
|
LoRA |
参数高效微调,降低训练显存 |
否 |
中(7B 约 22–30 GB) |
与基座 FP16 相当(约 14 GB+),加微量 adapter |
非常适合(切换 adapter 文件) |
多任务微调、领域适配 |
推理不降显存,可后续量化 |
|
QLoRA |
极低训练显存的微调 |
否 |
低(7B 约 16–20GB,消费级可跑) |
情况一:4-bit 基座 + adapter(6–8 GB);情况二:merge后量化 |
非常适合(切换 adapter 文件) |
消费级显卡微调大模型 |
基座已是 4-bit,如 merge 需重量化 |
核心总结:
-
SFT 是任务适配最直接的方法,但训练显存最大,推理显存不降。
-
LoRA 是参数高效微调,大幅降低训练显存,但推理显存不天然降低;它天然适合多 adapter 切换。
-
QLoRA 在 LoRA 基础上进一步将基座量化为 4-bit,训练显存再次大幅降低,使单卡 24 GB 训练 7B 成为现实。
-
AWQ/GPTQ 专门解决推理显存与部署效率问题,不属于微调方法。
-
工程上常见的组合路径:LoRA 微调 → merge → AWQ/GPTQ 量化,或 QLoRA 微调 → 直接 4-bit adapter 推理,根据训练资源和部署需求灵活选择。
重点:无论哪种方法,推理显存都不等于理论权重大小,KV Cache、量化元数据、激活缓冲和框架开销必须纳入评估,尤其是在长上下文、大 batch 的线上服务中。
哲学视角
——“微调不是让模型固守参数,而是让模型学会用更少的变化回应世界。”
全量 SFT 执着于扰动全部记忆,试图用 FP16 的刻刀雕琢每一个权重;LoRA 率先承认:真正的适应不需要翻天覆地,低秩分解便是效率与表达的握手。QLoRA 走得更远——它用 4-bit 的骨架承载 16-bit 的灵魂,让消费级显卡也能撬动百亿参数。而 AWQ 与 GPTQ 在推理时刻追问:我们是否真的需要还原每一个数值?量化不是对知识的背叛,而是对“什么才是理解的核心”的再定义。少一点精度,未必少一点智能;更低的位数,也可能是更高维的抽象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)