国内 AI Coding Plan 指南:高性价比套餐对比 × 榨干GLM × 套餐选择
一份写给开发者的「每一分钱都花在刀刃上」手册
前言
本人从 2023 年 2 月开始接触 AI 工具辅助编程,近 3 年 AI IDE(Cursor、Trae、Qoder)和 1 年终端 Agent(CC、OpenCode)的使用经验,国内外基本所有套餐都用过,各厂商的政策变动都很熟悉。
最近很多在国企工作的朋友都在问我国内有没有好的推荐,因为国企只报销国产模型,打工人谁会自愿付费上班呢,问的人多了就有了这篇文章,希望这篇文章能帮到囊中羞涩的个人开发者和打工族,当然还有我们可爱的学生党。
这半年国内的 Coding Plan 大起大落,福利吃到撑了,但是这个世界的信息差真的巨大,有人买 99 元 1 亿 Token 套餐,有人爽用 1 亿 Token 只需 1.3 元。
这篇文章帮你打破信息差,不是只有 DeepSeek 才有性价比。
目前国内我最看好的厂商只有两个,都是各自赛道的顶流:智谱和 DeepSeek。
目录
-
一、评判模型实力的 5 个核心指标
-
二、国内高性价比套餐 Token 额度解密
-
2.1 智谱 Coding Plan
-
2.2 OpenCode Go 套餐
-
2.3 Kimi Code
-
2.4 OpenCode 免费模型
-
-
三、把 GLM Coding Plan 的固定额度用出更多 Token
-
3.1 组合模型:GLM-5.1 + DeepSeek V4 Flash Free
-
3.2 触发"自然重置":让 5 小时窗口滚动起来
-
3.3 不要跟风引入过多无用 Skill
-
3.4 错峰使用:把 GLM-5.1 留到非高峰期
-
3.5 任务分级:把旗舰模型留给硬骨头
-
3.6 一次给足上下文,别多次小请求
-
3.7 配置多模型路由:让对的模型干对的活
-
-
四、套餐怎么买最划算:人群画像 × 订阅策略
-
4.1 人群画像与推荐套餐
-
4.2 各厂商个人体验
-
-
附录 1:自动刷新 5 小时窗口脚本
一、评判模型实力的 5 个核心指标
不看榜单,不看刷分,只看实战表现
核心指标判断
-
指令遵循能力:模型"听话"程度,指它是否严格按照指令的格式、步骤等要求进行回复。测试方法:让模型按 JSON Schema 输出,看它是否严格遵循格式。
-
长文本能力:模型在处理大量信息时,对前后文的记忆和整合能力。你可以用超长文档进行提问(如"总结第 100 页的第 3 段"),来测试其"大海捞针"的能力。
-
自主能力:指模型在修改代码时,能否顾全大局、保持整体一致性。具体来说,当模型修改一处代码后,应能主动识别该改动所影响的范围,并准确定位到所有受牵连的代码段。
-
深度用户口碑:统计有长期项目经验的开发者对模型持续使用后的真实评价,反映模型在实际工程环境中的长期稳定性和可靠性。
-
生态覆盖度:模型在主流编程平台(如 Qoder、Trae、Cursor、OpenCode 等)及 AI 编程产品中被列为可用选项的频率。出现次数越多的模型,通常意味着其通用性、稳定性和性价比已获得开发者社区的广泛验证,是市场选择的"用脚投票"结果。这一指标可有效排除榜单刷分和营销噪音,反映模型的真实工业级受欢迎程度。
二、国内高性价比套餐 Token 额度解密
国内比较划算的套餐的额度对比(仅列举我觉得值得推荐的套餐)
2.1 智谱 Coding Plan
前提:不能在高峰期使用,才能达到以下换算之后的额度。
| 套餐类型 | 每 5 小时限额 | 每周限额 | 每月限额 (按4.3周算) |
|---|---|---|---|
| Lite 新套餐 | 最多约 80 次 prompts | 最多约 400 次 prompts | 最多约 1720 次 prompts |
| Pro 新套餐 | 最多约 400 次 prompts | 最多约 2000 次 prompts | 最多约 8600 次 prompts |
| Max 新套餐 | 最多约 1600 次 prompts | 最多约 8000 次 prompts | 最多约 34400 次 prompts |
Lite新套餐 每 5 小时能用 1800w-2200w Token——这是仅使用 GLM-5.1 的精确数字(60 组后台数据差值计算),范围内浮动是因为多次少量和少次多量的使用方式导致的。
也就是 1 prompt 是 25w Token(取平均数)。
| 套餐类型 | 月付费(不含折扣) | 年付费(8 折) | 每 5 小时限额 | 每周限额 | 每月限额(按 4.3 周算) |
|---|---|---|---|---|---|
| Lite 新套餐 | 49 元 | 39 元×12 | 2000w Token | 1 亿 Token | 4.3 亿 Token |
| Pro 新套餐 | 149 元 | 119 元×12 | 1 亿 Token | 5 亿 Token | 21.5 亿 Token |
| Max 新套餐 | 469 元 | 375 元×12 | 4 亿 Token | 20 亿 Token | 86 亿 Token |
新Max如果一 半时间高峰期用,一半时间非高峰期用,一周只能用10亿token左右
新套餐计费机制:双限额 + 倍率
-
GLM-5/5.1 倍率:
-
高峰期(UTC+8 14:00-18:00):3 倍消耗
-
非高峰期(其他时段):2 倍消耗
-
限时福利(截至 2026 年 6 月底):GLM-5.1 和 GLM-5-Turbo 在非高峰期仅 1 倍消耗
-
如果你是老套餐,那就比较厉害了,因为老套餐 Lite 在极限情况比新套餐 Pro 额度还高,下面是我的 Lite 老套餐的使用截图。
看下面的曲线图,5 月 28 日当日用 4 个 5 小时就是 1.2 亿 Token(1M 是 100w Token),侧面印证 Lite 每 5 小时能用 2800w-3200w Token。
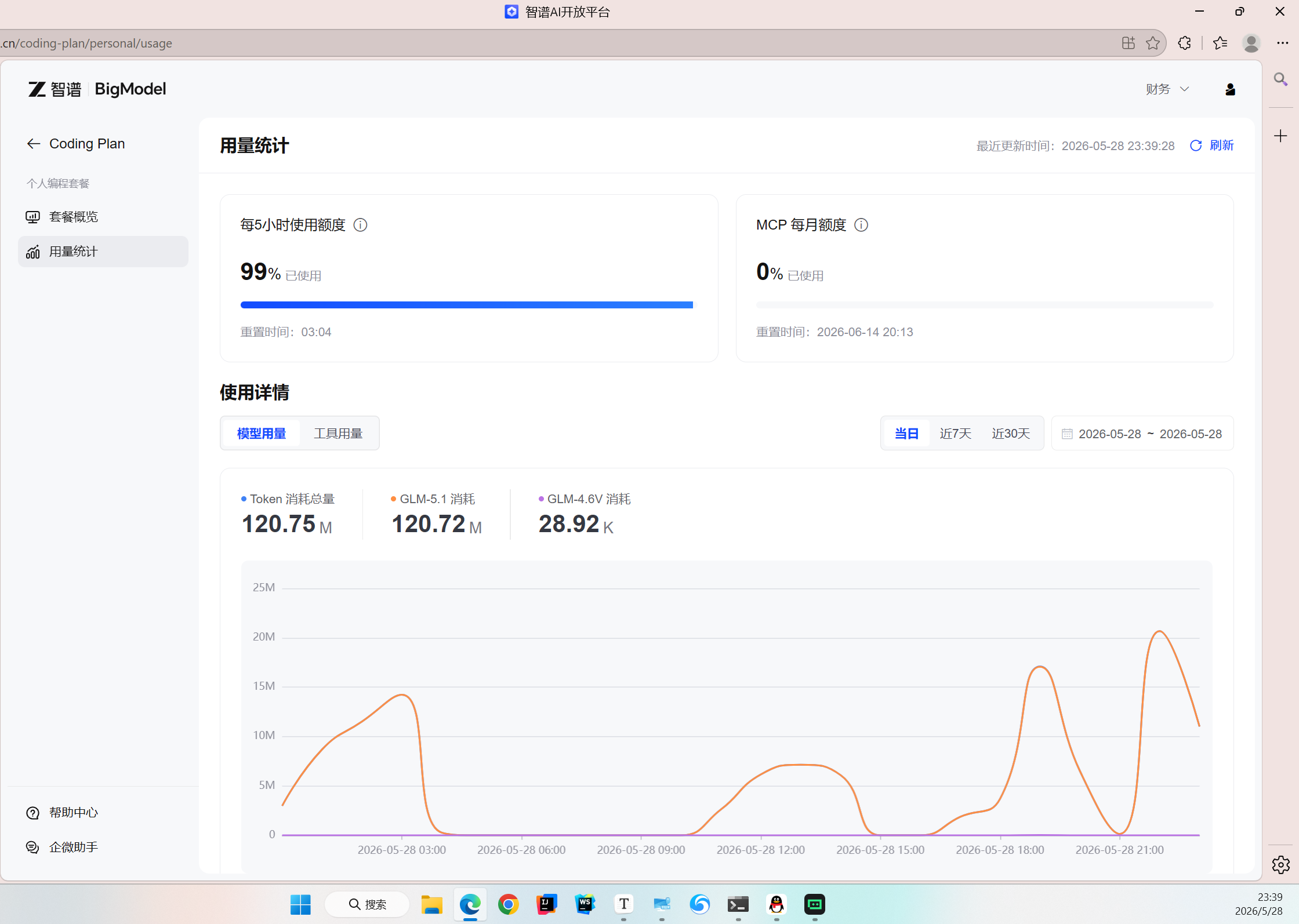
5 月 12 日当日用 3 个 5 小时就是 0.9 亿 Token(1M 是 100w Token),侧面印证 Lite 每 5 小时能用 2800w-3200w Token。
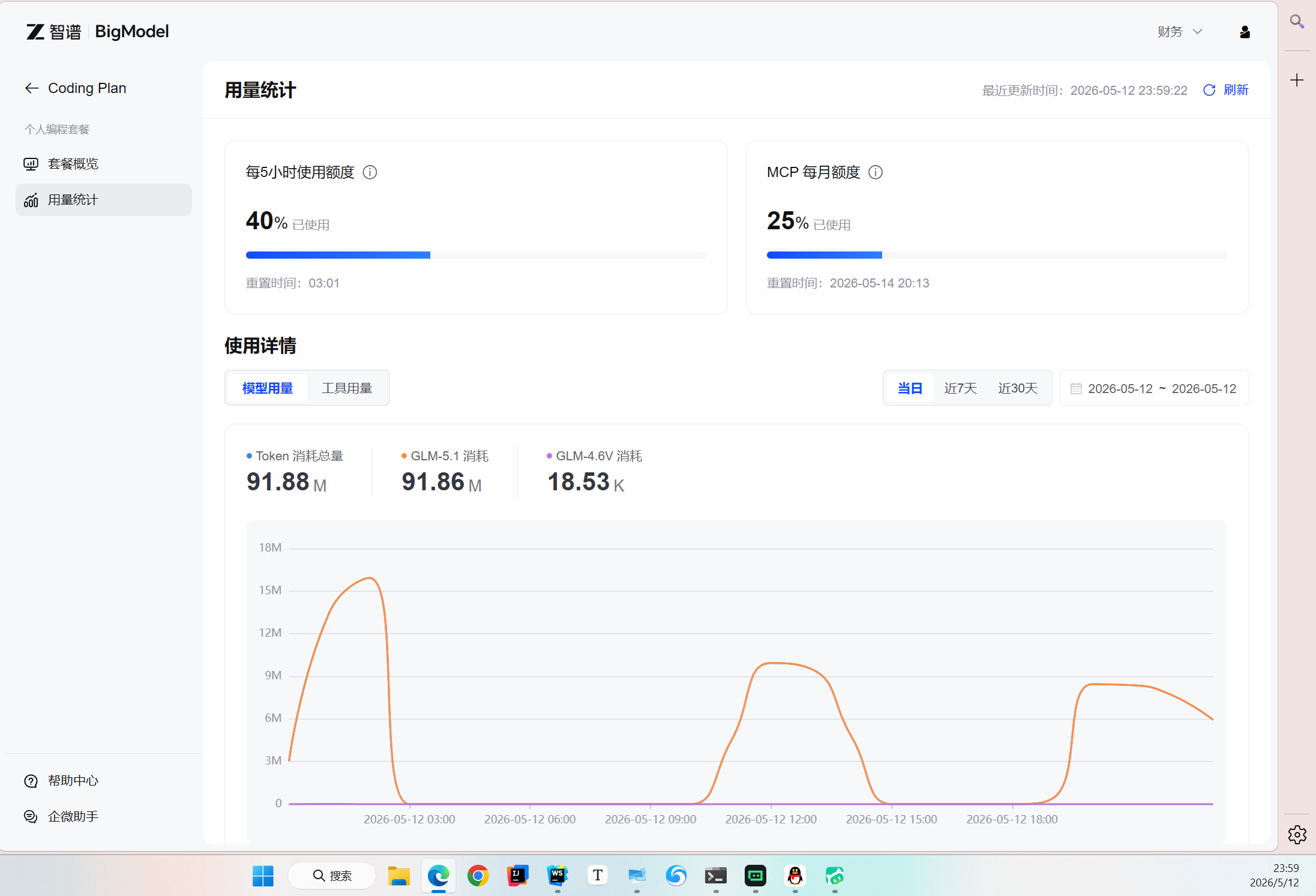
本人亲测,Pro 老套餐一天可以 6 亿 Token,所以 Lite 老套餐只是看着很厉害,其实不可能天天 1.2 亿,而且 5 小时额度太低了,很被动,本章(第三章)会教老套餐用户如何榨干套餐 Token 额度,涉及 5 小时重置和错峰使用。
补充说明——速度差异:阿里的 Token Plan 的 GLM-5.1 速度比 Lite 快,比 Pro/Max 慢(智谱官网的速度波动挺大的)。所有模型在 WSL 下的终端 Agent 中永远是最快的,在 AI IDE 中永远是最慢的,因为侧重不一样,AI IDE 太侧重交互了。
🙋蹲队友拼智谱 Coding Plan!
🧩国内顶流编程大模型,20+主流工具全适配,性价比拉满,
👉立即参与「拼好模」:https://www.bigmodel.cn/glm-coding?ic=LJEKCPOQLP
2.2 OpenCode Go 套餐
结论: 仅使用 DeepSeek V4 模型时划算,其他的额度太少,不值得。
OpenCode Go 套餐首月 35 元,续费 70 元(持续 35 元的方法读者自行研究),而且一个账号可以多开工作区,也就是一个账号可以开两个套餐。
这是opencode官方的示例:
DeepSeek V4 Pro: 一个月能使用 17,150 次请求 — 每次请求 750 个输入 token,82,000 个缓存 token,290 个输出 token DeepSeek V4 Flash: 一个月能使用 158,150 次请求 — 每次请求 790 个输入 token,68,000 个缓存 token,280 个输出 token
但是实际上我们正常使用不可能有这么高的缓存命中,所以我会把这个换算成金额,再用同等金额重新分配缓存命中率。
在计算前,我们先明确一下每个模型的具体单价:
| 模型 | 单价计算单位 | 输入(缓存未命中) | 输入(缓存命中) | 输出 |
|---|---|---|---|---|
| DeepSeek V4 Pro | 人民币/百万 tokens | 3 元 | 0.025 元 | 6 元 |
| DeepSeek V4 Flash | 人民币/百万 tokens | 1 元 | 0.02 元 | 2 元 |
💎 DeepSeek V4 Pro 成本计算
-
输入(未命中缓存)成本
计算式:(17,150 次 × 750 tokens) ÷ 1,000,000 × 3 元/百万 tokens = 38.5875 元 -
输入(命中缓存)成本
计算式:(17,150 次 × 82,000 tokens) ÷ 1,000,000 × 0.025 元/百万 tokens = 35.1575 元 -
输出成本
计算式:(17,150 次 × 290 tokens) ÷ 1,000,000 × 6 元/百万 tokens = 29.841 元 -
总成本
38.5875 元 + 35.1575 元 + 29.841 元 = 103.586 元
⚡️ DeepSeek V4 Flash 成本计算
-
输入(未命中缓存)成本
计算式:(158,150 次 × 790 tokens) ÷ 1,000,000 × 1 元/百万 tokens = 124.9385 元 -
输入(命中缓存)成本
计算式:(158,150 次 × 68,000 tokens) ÷ 1,000,000 × 0.02 元/百万 tokens = 215.084 元 -
输出成本
计算式:(158,150 次 × 280 tokens) ÷ 1,000,000 × 2 元/百万 tokens = 88.564 元 -
总成本
124.9385 元 + 215.084 元 + 88.564 元 = 428.5865 元
结论:35 元的 OpenCode Go 套餐可以用出 103 元 DeepSeek V4 Pro 或者 428 元 DeepSeek V4 Flash 的效果
| 模型 | 请求次数 | 未命中缓存输入 | 命中缓存输入 | 输出 | 总费用 |
|---|---|---|---|---|---|
| DeepSeek V4 Pro | 17,150 | 38.59 元 | 35.16 元 | 29.84 元 | 103.59 元 |
| DeepSeek V4 Flash | 158,150 | 124.94 元 | 215.08 元 | 88.56 元 | 428.59 元 |
注:计算结果保留了小数点后两位,四舍五入。
为了模拟真实使用情况,我列举了 3 种命中缓存给大家做参考(大家都知道 DeepSeek V4 的缓存命中率普遍很高)。
📊 OpenCode Go 套餐仅使用 DeepSeek 的每月可用 Token 对比汇总(单位:百万 tokens)
| 模型 | 场景(命中/输入/输出) | 未命中缓存输入 | 命中缓存输入 | 输出 | 请求次数 | 总 Token | 换算成亿 |
|---|---|---|---|---|---|---|---|
| Pro | 原始(98.74% / 0.90% / 0.35%) | 12.86 | 1406.30 | 4.97 | 17,150 | 1424.13 | 14 亿 |
| Flash | 原始(98.44% / 1.14% / 0.41%) | 124.94 | 10754.20 | 44.28 | 158,150 | 10923.42 | 109 亿 |
| Pro | 假设 95% / 3.5% / 1.5% | 16.57 | 449.85 | 7.10 | 5,702 | 473.52 | 4.7 亿 |
| Flash | 假设 95% / 3.5% / 1.5% | 178.56 | 4848.70 | 76.54 | 73,882 | 5103.80 | 51 亿 |
| Pro | 假设 90% / 7% / 3% | 17.58 | 226.08 | 7.53 | 3,024 | 251.19 | 2.5 亿 |
| Flash | 假设 90% / 7% / 3% | 202.73 | 2606.60 | 86.88 | 41,927 | 2896.21 | 29 亿 |
2.3 Kimi Code
我没有长时间使用过,无法给出详细的额度数据,只能基于我姐(Allegretto 包年)和朋友的使用体验。
只有 Allegretto 包年套餐值得买,每个月折合 159 元/月,其他额度的套餐不值得考虑。
而且套餐额度不透明,按道理来讲,月之暗面主要客户是 C 端,但是我没有觉得对 C 端特别友好。
在我的推荐列表中位于智谱 Coding Plan 和 OpenCode Go 套餐之后,但是远远比国内其他套餐性价比高。
2.4 OpenCode 免费模型
我目前使用免费没有遇到过上限,唯一限制就是免费模型的上下文只有 200k,我个人在使用中发现弱模型和强模型的执行力差异还是很大的,表现在弱模型即使有很强的规则束缚,在长上下文的细节中也会出现不按规则执行的情况。实际使用 DeepSeek V4 Flash Max Free 和 MiniMax M3 Free 的执行力一样,让人有点惊讶,所以弱模型即便开放了 1M 上下文,使用效果也会很不理想。在我的使用体验中,我个人觉得 DeepSeek Flash Max Free 是把握不住 1M 上下文细节的,性能毕竟有限。
三、把 GLM Coding Plan 的固定额度用出更多 Token(新老套餐都适用)
3.1 组合模型:GLM-5.1 + DeepSeek V4 Flash Free:智能路由与 Spec 粒度控制的协同优化方案
GLM-5.1 是将,免费模型是兵。
方案 A 的 OMO 路由模板在 3.7 配置多模型路由:让对的模型干对的活
这里的重点是方案 C,这个属于 OMO 的小补丁,只有当主代理 GLM-5.1 派发给 DeepSeek V4 Flash 子代理写代码的任务时才会触发,不会一直触发。
方案 C 我只是列举了一个大致思路,这一模板是半年前的 V0.1 版本,对于学生和个人开发者而言足够使用,复制粘贴放在全局 AGENTS.md 中,依然能够节省 Token,但是无法直接用于工作使用,需要自行调整。
## AI 模型配置优化方案(A+C 组合)
### 背景
当前环境使用两个 AI 模型:
- **GLM-5.1**(`zhipuai-coding-plan/glm-5.1`):智慧高,但生成速度慢(500行代码20分钟起步),30分钟超时会丢失所有输出
- **DeepSeek V4 Flash Free**(`opencode/deepseek-v4-flash-free`):速度快(约为GLM-5.1的6-7x),免费,但推理能力弱于GLM-5.1
**目标**:取两者优势——GLM-5.1 的规划智慧 + DeepSeek V4 Flash 的执行速度,同时最小化与纯 GLM-5.1 的代码质量差距。
### 方案 A:任务复杂度分流
通过 omo 的 `categories` 和 `agents` 配置,按任务复杂度路由到不同模型。
### 方案 C:Spec 粒度控制
主代理(sisyphus)在派发任务给 DeepSeek V4 Flash 子代理时,必须根据任务类型生成对应粒度的 spec。
#### Spec 粒度等级
**填空题级别(DeepSeek V4 Flash子代理几乎不需要自己想)**:
适用于以下场景:
- 复刻/参照已有代码(有参考文件可提取精确结构)
- 模式化CRUD页面
- 简单组件实现
主代理必须输出的 spec 内容:
1. **文件路径**:明确写要创建/修改的文件完整路径
2. **参考文件**:写明要参考的现有文件路径和具体行号
3. **import 列表**:列出所有需要的 import 语句及其来源路径
4. **数据结构**:列出涉及的接口/类型/字段/API端点/返回格式
5. **DOM 结构**:列出组件的标签层级、class名、绑定关系
6. **核心逻辑**:写出关键函数的伪代码或直接写函数签名+返回值
7. **禁止项**:明确不能做的事(如"不要自己设计composable")
**伪代码级别(DeepSeek V4 Flash子代理需要自己推断部分实现细节)**:
适用于以下场景:
- 从零开发新功能(没有参考文件)
- 需要一定创造性的实现
- 不熟悉的框架/库(主代理也不确定具体API)
主代理必须输出的 spec 内容:
1. **文件路径**
2. **整体架构**:组件层级、数据流方向、状态管理方案
3. **核心函数签名**:关键函数的参数和返回值类型
4. **数据模型**:涉及的数据结构和接口
5. **约束条件**:不能做的事、边界条件、性能要求
**原始级别(仅描述目标,子代理自由发挥)**:
**仅在子代理使用 GLM-5.1 时使用**,因为 GLM-5.1 有足够的推理能力自行规划实现。
### Spec 粒度决策规则
```
if 子代理模型 == GLM-5.1:
spec粒度 = 原始级别(信任子代理的推理能力)
elif 有参考文件可对照:
spec粒度 = 填空题级别(照抄参考 + 详细spec)
elif 从零开发:
spec粒度 = 伪代码级别(给框架,子代理填细节)
```
### 主代理派发 prompt 模板
#### 填空题级别模板
```
【任务】在 {文件路径} 创建/修改 {简要描述}
【参考文件】{参考文件路径}(照抄其 {具体部分},行 {起始行}-{结束行})
【必须 import】
- {import语句1} // 参考自 {文件名} 第 {行号} 行
- {import语句2}
- ...
【数据层】
- API端点:{method} {url}
- 返回格式:{示例JSON或类型定义}
- composable/hooks:{路径},返回值 {列出返回的方法和响应式变量}
【模板结构】(照抄 {参考文件} 的DOM树,替换以下差异)
- {差异点1:如"页面标题改为'XX'"}
- {差异点2:如"表格列改为A,B,C"}
- {差异点3}
【不需要自己想的】
- {明确告诉子代理哪些已经封装好了,直接调用}
- {哪些逻辑已在其他文件实现}
【禁止】
- {不能做的事}
```
#### 伪代码级别模板
```
【任务】在 {文件路径} 创建 {简要描述}
【整体架构】
- 组件层级:{父组件} → {本组件} → {子组件}
- 数据流:{描述数据从哪来到哪去}
- 状态管理:{使用什么方案}
【核心函数】
- {函数名}({参数类型}): {返回值类型} — {一句话描述功能}
- {函数名}({参数类型}): {返回值类型} — {一句话描述功能}
【数据模型】
{TypeScript接口或JSON示例}
【约束】
- {边界条件}
- {性能要求}
- {不能做的事}
```3.2 触发"自然重置":让 5 小时窗口滚动起来
老套餐用这种方法可以一天轻松用 4 个 5 小时。
很多用户不知道:5 小时窗口是从你"第一次消耗"开始计时的,不是从 0 点开始。
举个例子:早上 9 点开工,消耗了 1 prompt。5 小时窗口从 9 点开始计算,到 14:00 才会重置。而高峰期恰好是 14:00-18:00——你的额度刚好在高峰期恢复,等于把最贵的额度浪费在高峰期。
正确做法:
-
刻意在早上 6 点问 GLM-5.1 一个极为简单的问题(比如询问今天的日期),让 5 小时窗口往后挪。如无法早起,可通过云服务器定时脚本自动触发,我本人就是在云服务器上使用定时脚本来让 Coding Plan 自动刷新时间。
如果你使用了云服务器这个方法,可以抄下脚本作业:附录 1:自动刷新 5 小时窗口脚本
3.3 不要跟风引入过多无用 Skill
比如我使用 OpenCode + OMO 框架(插件形式引入)本身自带了这几个(Brainstorming → Verification → Debugging → TDD → Git-master),装好、打开、老老实实用,就已经超过 80% 的"所谓的神级技巧"了。
推荐安装的 Skill
Brainstorming Skill — 必须装,排第一
理由:你每次说"加个功能",它会让你停下来想清楚再动手。不是限制你,是防止你跟 Agent 来回 10 轮才发现方向错了。
Verification-before-completion — 戒掉"看起来对了"
硬规则:Agent 不能说"done"或"fixed"——它必须先跑验证命令,把输出给你看。杀幻觉最有效的招,没有之一。
Systematic Debugging — 修 bug 时用
修 bug 最忌讳的就是"这个看起来像是 X,改一下试试"。这 Skill 让你按步骤来:复现 → 缩小范围 → 找根因 → 修 → 验证。单这一条就能省你一半的 debug 时间。
Test-Driven Development
不是让你 TDD 狂热,而是修 bug 时先写一个失败测试证明 bug 存在,再修。这样你确定 bug 真的修了,而且以后不会 regress。
Git-master
如果你要 Commit、bisect、rebase、squash——这个 Skill 让 Agent 直接处理,不用你自己敲 git 命令。Atomic commit + bisect 的组合就是 GSD 的那套思路,这个 Skill 帮你做到。
除此之外,我仅额外装了 Superpowers。
我来具体列举几个SKILL的例子:
要有自己的判断能力
Graphify
优点:
-
思路对——减少 token 消耗是刚需,尤其是接非 Claude 模型时
-
本地 Whisper 转写 + Tree-sitter 解析 = 不花 LLM 钱的部分都省了
问题:
-
维护成本高。代码变、图要重建,watch 模式一直跑着也是资源
-
小项目用不上。repo < 1000 文件时,grep 比查图快
-
多了一个要维护的产物(graph.json/HTML viewer)。如果你是 solo dev,这笔账不一定划算
适用场景: 超大 monorepo、多语言项目、经常查跨模块调用关系的。小项目过重。
AwesomeDesign
优点:
-
确实解决了一个真实问题——换模型后设计风格统一,这个痛点切得准
-
零配置心智——放个文件到根目录就行
问题:
-
31 个知名网站的 design.MD,你的项目不是 Stripe/Linear
-
真正需要的是 你自己的设计规范,不是抄别人的
-
万一项目本身有设计师、有 Figma、有设计系统,这个文件反而制造不一致
适用场景: solo dev、没设计师、项目不需要独特品牌识别的。正经产品不建议直接套 Stripe 的设计文件。
GetShitDone (GSD)
优点:
-
解决方案本身设计得不错——fresh context 避免 context rot,atomic commit 配合 bisect,这些思路对
-
plan mode 和 build mode 的搭配是很好的实践
问题:
-
6 步 workflow,每一步都要你参与(discuss、verify、ship)——这是给了你一个完整的流程,不是"提升效率"。很多步骤是你自己手动做的
适用场景: 喜欢结构化管理、做长周期项目的。不喜欢被人引导流程的,会觉得烦。
UI-UX ProMax
优点:
-
行业 specific anti-pattern 的设计思路非常好——FinTech 不用紫色渐变,Beauty Spa 不用暗色模式,这些细节是 AI 默认踩的坑
-
161 条规则的覆盖面确实广
问题:
-
吹得最狠,实际效用最可疑。 "67 种 UI 风格、15 种技术栈、161 条规则"——量很大但质量参差不齐
-
设计系统的核心不是配色方案,是信息架构、交互流程、用户心理。一个 skill 给不了这些,不更新就过时
适用场景: 做 MVP、demo、side project,快速出个能看的 UI。做产品不建议依赖一个 NPM 包来决定设计方向。
不是所有工具和 Skill 都能提高质量或者效率,很多都是边际改进,或者根本没有效果。
3.4 错峰使用:把 GLM-5.1 留到非高峰期
这是单点收益最大的一条策略。GLM-5.1 在高峰期消耗 3 倍额度,同样的 Lite 套餐每 5 小时额度:
-
高峰期使用 GLM-5.1:仅有 1000w Token
-
非高峰期使用 GLM-5.1:3000w Token 左右
14:00-18:00 之间有 4 个小时高峰期,我们要把高峰期拆解进 2 个 5 小时之中,而不是让 4 个小时高峰期挤占近乎一整个 5 小时窗口。
老套餐的错峰策略核心:让高峰期(14:00-18:00)的 4 小时被拆到两个不同的 5 小时窗口中,而不是挤在一个窗口里。
示例:
-
窗口一:11:00 ~ 16:00(包含 14:00-16:00 高峰)→ 在 11:00-14:00 的非高峰时段把额度用完
-
窗口二:16:00 ~ 21:00(包含 16:00-18:00 高峰)→ 在 18:00-21:00 的非高峰时段把额度用完
这样每个窗口只有 2 小时高峰期被浪费,而不是 4 小时高峰期吃掉一整个窗口。
3.5 任务分级:把旗舰模型留给硬骨头
| 任务类型 | 推荐模型 |
|---|---|
| 格式化、补全、查文档 | OpenCode 免费模型 |
| 单文件修改、写测试 | GLM-5.1 + OpenCode 免费模型混合 |
| 多文件重构、复杂调试 | GLM-5.1 |
| Agent 任务、长流程自动化 | GLM-5.1 + OpenCode 免费模型混合 |
核心原则:
-
80% 的任务用 DeepSeek V4 Flash Free 就够,别无脑上 GLM-5.1,在 OpenCode 中使用 F2 和 Shift+F2 切换很方便。
3.6 一次给足上下文,别多次小请求
不要停留在 AI IDE 的交互式编程阶段——那种"你一句,我一句"的对话模式。如果每次优化和微调都要来回反复,你就会和 AI 陷入"相爱相杀"的低效循环。
更好的做法:
每次需要微调代码时,不要一条一条地告诉 AI"改这里""改那里"。而是:
-
统一记录:把所有改动需求集中写在一份临时文档中。
-
引用文档:在对话中引用这份临时文档,让 AI 一次性读取全部调整项。
-
迭代追加:AI 完成修改后,如果还有新的调整需求,继续在同一份临时文档中追加,而不是开启新对话。
为什么有效?
所有 AI 模型都会自动对提示词进行二次优化。当你把一个个零散的改动提示词叠加在同一份文档中时,它们之间会产生 1+1 > 2 的协同效应——模型能更好地理解改动之间的关联,做出更全局、更一致的修改,而不是机械地执行孤立指令。
示例:下方截图右侧展示了一份用于优化和调整的临时文档。想要好的效果就要投入相应的精力,你敷衍 AI 模型,AI 模型自然给不出好的效果,我这个是版本的调整,所以写的有点多了,正常微调不用这样。
3.7 配置多模型路由:让对的模型干对的活
请确保已安装 OpenCode 和 OMO 框架,然后可以直接复制粘贴使用,注释什么的都写好了。还有 JSON 文件要改成 JSONC 才能正常使用注释。
/root/.config/opencode/oh-my-openagent.jsonc
{
"$schema": "https://raw.githubusercontent.com/code-yeongyu/oh-my-openagent/dev/assets/oh-my-opencode.schema.json",
"agents": {
// 主调度器 — 必须用GLM-5.1,负责规划、分解、派发、质量把控
"sisyphus": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 架构顾问 — 必须用GLM-5.1,处理复杂架构决策和深度调试
"oracle": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 代码搜索 — Flash即可,不需要推理
"explore": {
"model": "opencode/deepseek-v4-flash-free"
},
// 外部文档查询 — Flash即可,查文档不需要创造力
"librarian": {
"model": "opencode/deepseek-v4-flash-free"
},
// 多模态分析 — Flash即可
"multimodal-looker": {
"model": "opencode/deepseek-v4-flash-free"
},
// 战略规划师 — 用GLM-5.1,制定策略需要高智商
"prometheus": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 规划前分析 — 用GLM-5.1,识别隐藏意图和歧义需要高智商
"metis": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 计划审查 — 用GLM-5.1,审查质量需要深度推理
"momus": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 计划执行协调 — 用GLM-5.1,需要系统性管理能力
"atlas": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// GPT专属深度执行 — 当前未用GPT,配Flash
"hephaestus": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 基础任务执行者 — Flash即可,靠主代理的详细spec弥补推理差距
"sisyphus-junior": {
"model": "opencode/deepseek-v4-flash-free"
}
},
"categories": {
// 前端UI — Flash + 详细spec即可完成
"visual-engineering": {
"model": "opencode/deepseek-v4-flash-free"
},
// 高难度逻辑 — 必须GLM-5.1
"ultrabrain": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 自主研究+执行 — GLM-5.1,需要深度理解
"deep": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 简单任务 — DeepSeek Flash
"deepseek-quick": {
"model": "opencode/deepseek-v4-flash-free"
},
// 简单任务 — MiniMax M3(与 deepseek-quick 交替并行,提高吞吐)
"minimax-quick": {
"model": "opencode/minimax-m3-free"
},
// 简单任务 — 保留旧名 quick 兼容其他场景
"quick": {
"model": "opencode/deepseek-v4-flash-free"
},
// 低负载 — Flash
"unspecified-low": {
"model": "opencode/deepseek-v4-flash-free"
},
// 高负载 — GLM-5.1
"unspecified-high": {
"model": "zhipuai-coding-plan/glm-5.1"
},
// 文档编写 — Flash即可
"writing": {
"model": "opencode/deepseek-v4-flash-free"
},
// 创意性复杂问题解决 — GLM-5.1
"artistry": {
"model": "zhipuai-coding-plan/glm-5.1"
}
}
}四、套餐怎么买最划算:人群画像 × 订阅策略
4.1 人群画像与推荐套餐
OpenCode Go 套餐仅使用 DeepSeek V4 Pro 和 Flash,其他模型的额度太少。
| 人群 | 推荐套餐 | 月消耗额度 | 理由 |
|---|---|---|---|
| 学生 / 尝鲜用户 | OpenCode Go 套餐 + OpenCode 免费模型 | 6 亿 Token 以内 | 没闲钱,技术储备不多,GLM 套餐你抢不到,35 元 OpenCode Go 套餐的 DeepSeek 模型完全满足需求,更重要的是提升自己,而不是追模型性能,AI 模型是一面镜子,这时候的瓶颈在于自己而不是模型 |
| 个人开发者 / 中等强度 | GLM Pro 新套餐包季 + OpenCode 免费模型 | 30 亿 Token 左右 | 只能找人抢,包季费划算,智谱的留存率还是挺高的 |
| 日常高频编程 / 副业接单 | GLM Pro 新套餐包年 + OpenCode Go 套餐 + Kimi Code Allegretto 包年 | 60 亿 Token 左右 | 免费模型能力已经不足以支撑你的开发需求,硬用免费模型会拖累开发效率,开两种既可以相互印证也不会鸡蛋放一个篮子 |
| 重度用户 / 复杂项目 | GLM Max 新套餐包年 + Kimi Code Allegretto 包年 | 150 亿 Token 起步 | 同上 |
4.2 各厂商个人体验
以下为个人主观体验,仅供参考。
文心一言:百度属于起了个大早,赶了个晚集,先发优势没能转化为持续的领先,现在和豆包一起被视为"第二梯队"甚至"大众娱乐"。但是 2023 年作为首个网页端免费的模型,掀起普惠大众的浪潮,就这一壮举依然值得尊敬。
腾讯:模型和套餐属于放飞自我了……
阿里:服务器最稳定,最早时候的 Coding Plan 额度贼高,请求没有出现过中断或者超时的情况,速度中等,GLM-5.1 或者 Kimi 2.6 这类成本较高模型的输出速度一般。换成 Token Plan……我都不好意思说缩水了多少倍,算了三遍,还以为算错了,智谱 49 元的 Lite 新套餐至少是阿里 198 元套餐 Token 额度的 1.6 倍,这么说懂了吧,但是人家真的诚实。至于模型 Qwen……需要一个像 GLM-5.1 一样的亮眼的明星产品,而不是流水线一样一直发布新型号。我唯一觉得不错的是2025年8月在海外上线的qoder中的Repowiki这一功能
字节:这家厂商亏的恐怕是最少的,算力成本全部转嫁消费者。字节方舟套餐……全网公认的额度消耗最快,比阿里 Token Plan 还黑,是因为 Trae 免费的缘故吗?Trae新上架的套餐也很幽默呢,Trae对我来说唯一的作用是可以免费连接远程资源,至于AI模型: 豆包,完全的大众娱乐产品。
月之暗面:实在抢不到智谱 Coding Plan 套餐的次选,我没有长时间使用过,智谱入坑太早了。同时拥有智谱和月之暗面 Coding Plan 的朋友跟我说 Allegretto 5 小时额度略低于智谱,我没具体看过后台数据,没法算出详细值,而且现在只有包月和包年可选,包月的 99 元不够用,故意让你买 199 的。我姐姐买的包年(159 元×12)的 Kimi Code,做 PPT 商用演示和财务报表,和智谱是旗鼓相当的竞争对手
MiniMax:MiniMax M3 之前主打性价比,估计是想转型,但是这大棒也太狠了。股市的下降和模型性能没有关系,很多人利好套现罢了。性能有待商榷,模型执行力我觉得低了一点。使用脚本提取 OpenCode 数据库会话,同样的会话模板生成对话素材,GLM-5.1 和 Kimi 2.6 没问题,DeepSeek Flash Max Free 和 MiniMax M3 Free 都出现了自行更换格式细节的情况,我觉得两个由 OpenCode 提供的免费模型可能在处理复杂、长指令时的稳定性或对齐精细度上确实有差距。
MiMo:虽然我家很多小米的产品,但是模型我还是抱着怀疑态度。没有否定是因为小米模型的核心开发者之一是 DeepSeek 跳槽过去的,DeepSeek 还真是 AI 人才培养基地啊。小米给符合要求的程序员海量发放 Token,一是宣传,二是检验模型能力和收集用户使用数据用于后续优化。但是雷总,大家拿你模型都是用来玩的啊,我身边的人都是用来写小说、玩酒馆等娱乐了,我真怕 MiMo 成为第三个豆包。
DeepSeek 官网 Token 计费:模型算力成本属于性价比赛道的王,DeepSeek 模型没少用,但是没给官网充过钱,API 的价格跟套餐去比,没竞争力啊。
国外御三家:也就 GPT 和 Claude 大幅领先,Gemini……后发力不够啊。国内很多知名的中转站,但是恕我直言,我不建议用。截止到 2026 年 6 月 6 日,我身边一半的人使用中转站的 Claude Opus 4.7 和 4.8,我一个朋友的使用额度,400 元拼车用了 Claude Opus 4.7 一个月,消耗了 71 亿 Token。额……这么搞,一个月一换号是肯定的,反正我是觉得不长久,而且这消耗额度 100% 有水分。(不构成推荐,仅陈述身边案例)
附录 1:自动刷新 5 小时窗口脚本
这个自动刷新每天只消耗约 400 Token(3 次请求 × 输入输出约 130 Token/次)。
云服务器纯终端下创建目录(若已有会跳过)
mkdir -p ~/scripts
直接用 cat 写入脚本内容,注意把 YOUR_REAL_API_KEY 换成你的真实密钥
cat > ~/scripts/good_morning.sh << 'EOF'
#!/bin/bash
API_KEY="YOUR_REAL_API_KEY"
MESSAGE="1加1等于几"
# 发送请求,丢弃响应体,只获取状态码
http_code=$(curl -s -o /dev/null -w "%{http_code}" --max-time 30 \
-X POST "https://open.bigmodel.cn/api/coding/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${API_KEY}" \
-d '{
"model": "glm-5.1",
"messages": [
{"role": "system", "content": "极简短回复"},
{"role": "user", "content": "'"${MESSAGE}"'"}
],
"temperature": 1.0,
"stream": false
}')
# 同时输出状态码 + 时间(成功或失败都记录状态码)
echo "$http_code $(date '+%Y-%m-%d %H:%M:%S')" >> ~/scripts/zhipu_daily.log
EOF
赋予执行权限
chmod 700 ~/scripts/good_morning.sh
定时任务
加入 cron
crontab -e
查看 cron
crontab -l
添加:
59 5 * * * /bin/bash /root/scripts/good_morning.sh 00 11 * * * /bin/bash /root/scripts/good_morning.sh 01 16 * * * /bin/bash /root/scripts/good_morning.sh
测试
> ~/scripts/zhipu_daily.log # 清空 /bin/bash ~/scripts/good_morning.sh # 执行 cat ~/scripts/zhipu_daily.log # 看结果,应该只有一行时间
如果本文对你有帮助,欢迎点赞 / 在看 / 转发。有具体使用问题可以在评论区留言。 配套工具:OpenCode

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)