OCRmyPDF:给扫描件加上可搜索的文字层
OCRmyPDF:给扫描件加上可搜索的文字层
OCRmyPDF 在 GitHub 上已经拿到 33,782 Star。
它是一个命令行工具,只做一件事:给扫描版 PDF 加上 OCR 文字层,让原本不可搜索、不可复制的文件变得可用。底层用的是 Tesseract OCR 引擎,支持 100 多种语言。
1、这工具是干嘛的
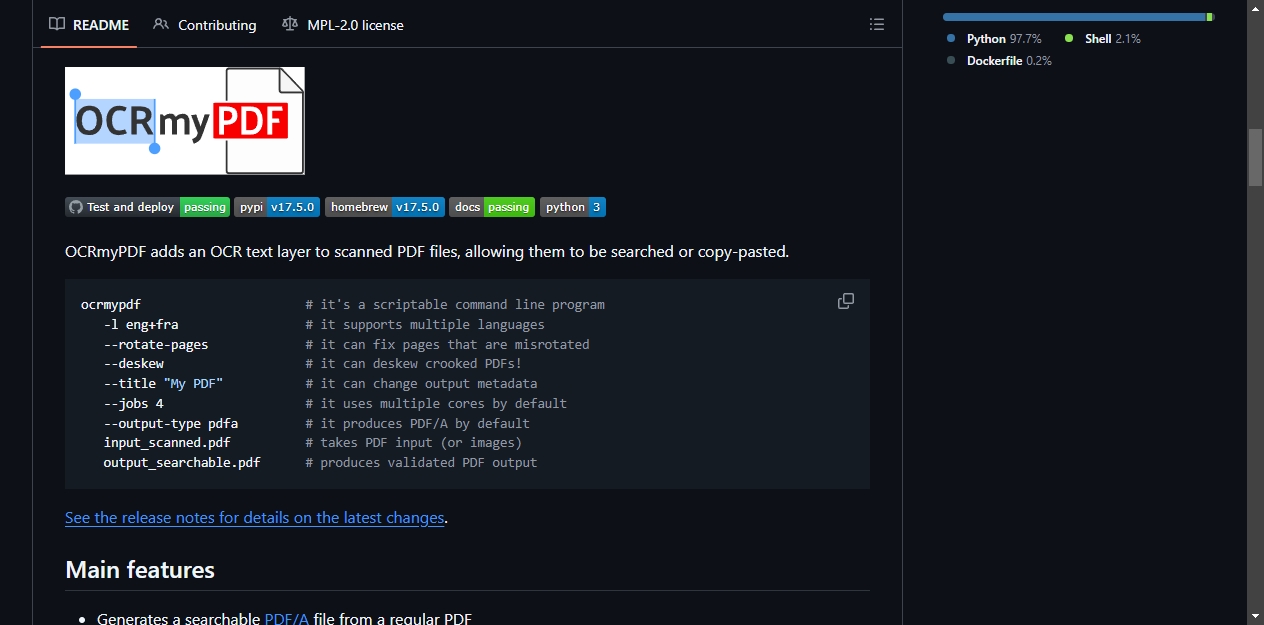
把纯图像构成的 PDF 转成可搜索、可复制的文档。
你扫描了一份合同,或者从某个系统导出的 PDF 里只有图片没有文字,这时候想搜索关键词、复制段落、或者把内容丢给 LLM 处理,都会碰壁。OCRmyPDF 在这类 PDF 下面铺一层隐藏的文字,视觉上完全不变,但文字已经可以被检索和复制。
2、为什么要用它
市面上做 PDF OCR 的工具不少,但大多有硬伤。有的文字层和图像对不齐,复制出来是一团乱码;有的处理完文件体积暴涨几倍;有的遇到多语言文档就识别错误;还有的直接改了原始图像的分辨率。
OCRmyPDF 的设计目标就是避开这些坑。它保持原图分辨率不变,文字层精准对齐在图像下方,复制粘贴时不会错位。输出文件经过图像优化,通常比输入更小。还能直接生成 PDF/A 格式,满足长期存档的需求。
多核并行是默认行为,处理大文件时会自动把所有 CPU 核心用上。
3、安装
Linux、macOS、Windows、FreeBSD 都支持,各大包管理器里都能直接装:
apt install ocrmypdf # Debian/Ubuntu
dnf install ocrmypdf # Fedora
brew install ocrmypdf # macOS
pkg install py-ocrmypdf # FreeBSD
用之前需要确保系统里已经装了 Tesseract OCR 和 Ghostscript。
4、怎么用
最简单的用法,一行命令:
ocrmypdf input.pdf output.pdf
多语言文档指定语言包:
ocrmypdf -l chi_sim+eng document.pdf document.pdf
纠偏和自动旋转歪掉的页面:
ocrmypdf --deskew --rotate-pages input.pdf output.pdf
直接覆盖原文件,只有成功时才替换:
ocrmypdf myfile.pdf myfile.pdf
需要 PDF/A 格式用于存档:
ocrmypdf --output-type pdfa input.pdf output.pdf
5、插件和生态
Tesseract 是默认的 OCR 引擎,识别准确率已经很高。如果有特殊需求,可以通过插件换成其他方案:
AppleOCR 在 macOS 上调用 Apple Vision 框架;EasyOCR 基于 PyTorch,有 GPU 的话速度更快;PaddleOCR 是百度开源的方案,中文场景下表现更好。
文档管理系统 paperless-ngx 也集成了 OCRmyPDF,扫描件进去,可搜索的归档文件出来。
6、适合谁用
- 需要批量处理扫描件、合同、发票的办公场景
- 做文档归档系统,需要输出 PDF/A 长期存储
- 要把 PDF 内容灌进 RAG 或向量数据库,但原始文件是图像型 PDF
- 经常和扫描版论文、报告打交道,需要提取文字的研究人员
输出 PDF/A 长期存储
- 要把 PDF 内容灌进 RAG 或向量数据库,但原始文件是图像型 PDF
- 经常和扫描版论文、报告打交道,需要提取文字的研究人员

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)