Linux线程池硬核解析:从固定线程池、单例线程池到线程安全、死锁与锁模型|附源码
与本文内容密切相关的热文:
Linux 线程日志系统设计:从策略模式、RAII 到 pthread 线程安全与内核写入路径|附源码
Linux 线程同步硬核解析:从条件变量、阻塞队列到信号量环形队列
Linux线程互斥与互斥锁:从抢票Demo到RAII锁的硬核封装
目录
前言
线程池不是“创建一堆线程然后执行任务”这么简单。一个真正能跑在多线程场景中的线程池,至少要解决这些问题:线程如何封装、任务如何表示、多个线程如何安全访问任务队列、没有任务队列时线程如何休眠、有任务时如何唤醒线程、线程池如何退出、日志如何记录线程行为、多线程下哪些函数是线程安全的、什么情况下会死锁、STL、智能指针、锁模型在多线程下有哪些边界?本文将基于 pthread、mutex、cond、Logger、ThreadPool 的 C++ 代码,完整拆解一个线程池从工程设计到内核机制的实现逻辑。深入到 Linux 内核层面:pthread_create 背后的 clone、线程调度、pthread_mutex 和 pthread_cond_wait 背后的 futex、线程休眠和唤醒、上下文切换、缓存局部性、死锁形成条件,以及不同锁模型的本质区别。
源码
main.cc:
#include "Task.hpp"
#include "ThreadPool.hpp"
#include <memory>
int main()
{
ENABLE_CONSOLE_LOG_STRATEGY();
std::unique_ptr<ThreadPool<task_t>> tp = std::make_unique<ThreadPool<task_t>>();
tp->Start();
int cnt = 10;
while (cnt--)
{
LOG(LogLevel::DEBUG) << "-------------------------: " << cnt;
sleep(1);
tp->Enqueue(task1);
sleep(1);
tp->Enqueue(task2);
}
tp->Wait();
return 0;
}Makefile:
CXX = g++
CXXFLAGS = -std=c++17 -Wall -g
TARGET = main
SRCS = main.cc
OBJS = $(SRCS:.cc=.o)
$(TARGET): $(OBJS)
$(CXX) $(CXXFLAGS) -o $@ $^
%.o: %.cc Logger.hpp
$(CXX) $(CXXFLAGS) -c -o $@ $<
clean:
rm -f $(OBJS) $(TARGET)
.PHONY: clean
Cond.hpp:
#ifndef __COND_HPP
#define __COND_HPP
#include <pthread.h>
#include "Mutex.hpp"
class Cond
{
public:
Cond()
{
pthread_cond_init(&_cond, nullptr);
}
void Wait(Mutex &mutex)
{
pthread_cond_wait(&_cond, mutex.Orgin());
}
void NotifyOne()
{
pthread_cond_signal(&_cond);
}
void NotifyAll()
{
pthread_cond_broadcast(&_cond);
}
~Cond()
{
pthread_cond_destroy(&_cond);
}
private:
pthread_cond_t _cond;
};
#endifLogger.hpp:
#ifndef __LOGGER_HPP
#define __LOGGER_HPP
#include <iostream>
#include <cstdio>
#include <string>
#include <ctime>
#include <filesystem>
#include <fstream>
#include <sstream>
#include <unistd.h>
#include <memory>
#include "Mutex.hpp"
namespace LogModule
{
// 获取时间
std::string GetTimeStamp()
{
time_t timestamp = time(nullptr);
struct tm data_time;
localtime_r(×tamp, &data_time);
char data_time_str[128];
snprintf(data_time_str, sizeof(data_time_str), "%4d-%02d-%02d %02d:%02d:%02d",
data_time.tm_year + 1900,
data_time.tm_mon + 1,
data_time.tm_mday,
data_time.tm_hour,
data_time.tm_min,
data_time.tm_sec);
return data_time_str;
}
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
// 日志等级
std::string LogLevel2String(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
// 基类:策略基类,设置刷新策略
class LogStrategy
{
public:
virtual ~LogStrategy() = default;
virtual void SyncLog(const std::string &logmessage) = 0;
};
// 子类:继承纯虚接口类
// 策略1
class ConsoleLogStrategy : public LogStrategy
{
public:
ConsoleLogStrategy() {}
~ConsoleLogStrategy() {}
void SyncLog(const std::string &logmessage) override
{
LockGuard lockguard(&_mutex);
std::cout << logmessage << std::endl;
}
private:
Mutex _mutex;
};
static const std::string glogdir = "./log/";
static const std::string glogfilename = "log.log";
// 子类:继承纯虚接口类
// 策略2
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const std::string &dir = glogdir, const std::string &filename = glogfilename)
: _logdir(dir), _logfilename(filename)
{
// 创建目录
LockGuard lockguard(&_mutex);
if (std::filesystem::exists(_logdir))
{
return;
}
else
{
try
{
std::filesystem::create_directories(_logdir);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << '\n';
}
}
}
~FileLogStrategy()
{
}
void SyncLog(const std::string &logmessage) override
{
LockGuard lockguard(&_mutex);
std::string logfilename = _logdir + _logfilename;
std::ofstream out(logfilename, std::ios::app); // 追加写入文件
if (!out.is_open())
{
return;
}
out << logmessage << "\n";
out.close();
}
private:
std::string _logdir;
std::string _logfilename;
Mutex _mutex;
};
// 日志类
class Logger
{
public:
Logger()
{
UseConsoleLogStrategy();
}
~Logger()
{
}
void UseConsoleLogStrategy()
{
_strategy = std::make_unique<ConsoleLogStrategy>();
}
void UseFileLogStrategy()
{
_strategy = std::make_unique<FileLogStrategy>();
}
// 内部类
// 将类变为string
class LogMessage
{
public:
LogMessage(LogLevel level, std::string &filename, int line, Logger&self)
: _level(level), _curr_time(GetTimeStamp()), _pid(getpid()), _filename(filename), _line(line), _logger(self)
{
std::stringstream ss;
ss << "[" << _curr_time << "]"
<< "[" << LogLevel2String(_level) << "]"
<< "[" << _pid << "]"
<< "[" << _filename << "]"
<< "[" << _line << "]"
<< "-";
_loginfo = ss.str();
}
template<typename T>
LogMessage &operator << (const T &info)
{
std::stringstream ss;
ss << info;
_loginfo += ss.str();
return *this;
}
~LogMessage() // RAII风格的日志刷新
{
if(_logger._strategy)
{
_logger._strategy->SyncLog(_loginfo);
}
}
private:
LogLevel _level; // 日志等级
std::string _curr_time; // 当前时间
pid_t _pid; // 进程pid
std::string _filename; // 文件名
int _line; // 行号
std::string _loginfo; // 一条完整日志
Logger &_logger; // 外部类的引用
};
// Logger 对象打印日志的时候,故意返回一个临时的LogMessage对象
LogMessage operator()(LogLevel level, std::string filename, int line)
{
return LogMessage(level, filename, line, *this);
}
private:
std::unique_ptr<LogStrategy> _strategy; // 刷新日志的策略
};
Logger logger;
// 使用宏,包装我们的日志打印过程
#define LOG(level) logger(level, __FILE__, __LINE__)
// 动态调整日志策略
#define ENABLE_CONSOLE_LOG_STRATEGY() logger.UseConsoleLogStrategy()
#define ENABLE_FILE_LOG_STRATEGY() logger.UseFileLogStrategy()
}
#endifMutex.hpp:
#ifndef __MUTEX_HPP
#define __MUTEX_HPP
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
pthread_mutex_t *Orgin()
{
return &_lock;
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};
class LockGuard
{
public:
LockGuard(Mutex *lockp): _lockp(lockp)
{
_lockp->Lock();
}
~LockGuard()
{
_lockp->Unlock();
}
private:
Mutex *_lockp;
};
#endifTask.hpp:
#pragma once
#include <iostream>
#include <functional>
#include <pthread.h>
#include "Logger.hpp"
using task_t = std::function<void()>;
using namespace LogModule;
void task1()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
LOG(LogLevel::DEBUG) << "执行任务1: 打印消息 |" << name << "|";
}
void task2()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
LOG(LogLevel::DEBUG) << "执行任务2: 计算 1+1 = " << 1 + 1 << " |" << name << "|";
}Thread.hpp:
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <functional>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h> /* Definition of SYS_* constants */
using func_t = std::function<void()>;
enum class TSTATUS
{
THREAD_NEW,
THREAD_RUNNING,
THREAD_STOP
};
inline static int gcnt = 1;
class Thread
{
private:
void getprocessid()
{
_pid = getpid();
}
void getlwp()
{
_lwpid = syscall(SYS_gettid);
}
static void *routine(void *args)
{
Thread *ts = static_cast<Thread *>(args);
ts->getprocessid();
ts->getlwp();
pthread_setname_np(pthread_self(), ts->Name().c_str());
ts->_func();
return nullptr;
}
public:
Thread(func_t f) : _tid(0), _joinable(true), _status(TSTATUS::THREAD_NEW), _func(f)
{
_name = "Worker-" + std::to_string(gcnt++);
}
void start()
{
if (_status == TSTATUS::THREAD_RUNNING)
{
std::cout << "thread is already running" << std::endl;
return;
}
int n = pthread_create(&_tid, nullptr, routine, this);
(void)n;
_status = TSTATUS::THREAD_RUNNING;
}
void stop()
{
if (_status == TSTATUS::THREAD_RUNNING)
{
int n = pthread_cancel(_tid);
(void)n;
_status = TSTATUS::THREAD_STOP;
}
else
{
std::cout << "thread status is : THREAD_NEW or THREAD_STOP! stop error" << std::endl;
}
}
void join()
{
if (_joinable)
{
int n = pthread_join(_tid, nullptr);
(void)n;
printf("lwp : %d, name: %s, join success\n", _lwpid, _name.c_str());
}
else{
printf("lwp : %d, name: %s, join failed, because thread is detach\n", _lwpid, _name.c_str());
}
}
void detach()
{
if (_joinable && _status == TSTATUS::THREAD_RUNNING)
{
_joinable = false;
int n = pthread_detach(_tid);
(void)n;
}
}
std::string Name()
{
return _name;
}
~Thread()
{
// if (_status == TSTATUS::THREAD_RUNNING)
// {
// pthread_detach(_tid);
// }
}
private:
pthread_t _tid;
pid_t _pid;
pid_t _lwpid;
std::string _name;
bool _joinable;
TSTATUS _status;
func_t _func;
};
#endifThreadPool.hpp:
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include "Thread.hpp"
#include "Logger.hpp"
#include "Mutex.hpp"
#include "Cond.hpp"
static const int gnum = 5;
using namespace LogModule;
#if 0
void DefaultRun()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
while(true)
{
LOG(LogLevel::DEBUG) << name << "线程执行默认方法";
sleep(1);
}
}
#endif
template <typename T>
class ThreadPool
{
private:
bool IsTaskQueueEmpty()
{
return _queue.empty();
}
T PopHelper()
{
T t = _queue.front();
_queue.pop();
return t;
}
void ThreadRoutine()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
while (true)
{
T task;
{
// 临界区
LockGuard lockguard(&_lock);
// 没有任务 && 线程池不退出 -> 休眠
while (IsTaskQueueEmpty() && _isrunning)
{
_sleeper_cnt++;
LOG(LogLevel::DEBUG) << "没有任务,线程休眠: |" << name << "|";
_cond.Wait(_lock);
LOG(LogLevel::DEBUG) << "有任务,线程唤醒:|" << name << "|";
_sleeper_cnt--;
}
// 没有任务 && 线程池退出 -> 线程结束
if (IsTaskQueueEmpty() && !_isrunning)
{
LOG(LogLevel::INFO) << "Thread: " << name << " quit";
break;
}
// 有任务 && 线程池退出,不关心线程有没有退出
// 有任务 && 线程池没退出,不关心线程有没有退出
task = PopHelper();
}
task(); // 处理任务不应该在临界区内部处理,获取任务之后,任务已经从公有变成私有了
}
}
public:
ThreadPool(int num = gnum) : _num(num), _isrunning(false), _sleeper_cnt(0)
{
for (int i = 0; i < _num; i++)
{
_threads.emplace_back([this]()
{ this->ThreadRoutine(); });
}
}
void Start()
{
LockGuard lockguard(&_lock);
if (_isrunning)
return;
_isrunning = true;
for (auto &thread : _threads)
thread.start();
}
void Enqueue(T task)
{
LockGuard lockguard(&_lock);
if (!_isrunning) // 线程池没有运行,禁止push任务
return;
_queue.push(task);
if (_sleeper_cnt > 0)
_cond.NotifyOne();
}
void Stop()
{
LockGuard lockguard(&_lock);
if (_isrunning)
{
LOG(LogLevel::DEBUG) << "关闭线程池";
_isrunning = false;
if (_sleeper_cnt > 0)
_cond.NotifyAll();
// for (auto &thread : _threads)
// thread.stop();
}
}
void Wait()
{
for (auto &thread : _threads)
thread.join();
}
~ThreadPool() {}
private:
std::vector<Thread> _threads; // 所有线程
int _num;
bool _isrunning;
// int _status; // rinning, stop, quit
int _sleeper_cnt;
std::queue<T> _queue;
Mutex _lock;
Cond _cond;
};1.线程池
1.1线程池的意义
在 Linux 多线程编程中,线程并不是越多越好。
线程的创建、销毁、调度都需要成本。对于短任务、高并发场景,如果每来一个任务就创建一个线程,任务执行完成后再销毁线程,那么系统会把大量时间浪费在线程管理上,而不是业务处理上。
线程池的核心思想是:
提前创建一批线程,让它们长期存在;任务到来时放入任务队列,由空闲线程取出并执行。
线程池解决的主要问题有三个:
- 降低线程创建和销毁成本
- 控制系统中的并发线程数量
- 使用任务队列缓冲突发请求,避免系统瞬间被大量线程拖垮
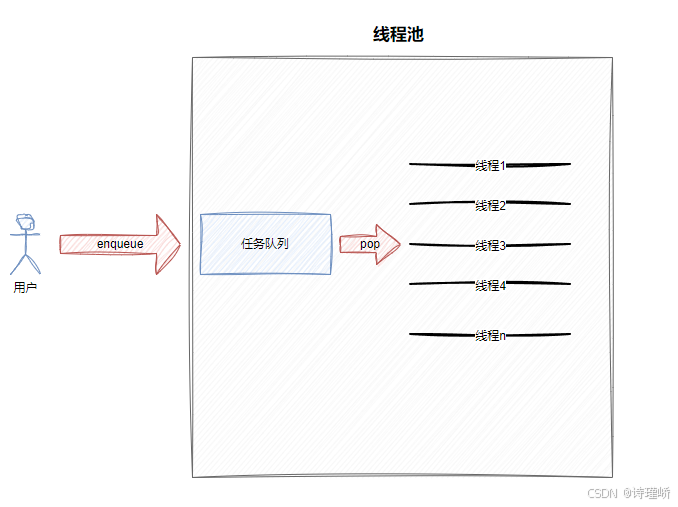
一个典型线程池模型如下:
提交任务的线程 -> 任务队列 -> 多个工作线程循环取任务执行
从设计角度看,线程池本质上仍然是生产者消费者模型。
任务提交者:生产者任务队列:交易场所工作线程:消费者
线程池不是为了“让程序看起来用了多线程”,而是为了控制并发度、提升资源复用率,并让系统在高并发场景下保持稳定。
1.2线程池的使用场景
1. 任务数量大,但单个任务执行时间短
例如 Web 服务器处理 HTTP 请求。每个请求处理时间可能很短,但请求数量巨大。如果每个请求都创建一个线程,会造成严重的线程创建和调度开销。
线程池可以让固定数量的线程不断复用:
请求 1 -> worker 线程处理
请求 2 -> worker 线程处理
请求 3 -> worker 线程处理
...
2. 对响应速度要求高
线程池中的线程已经提前创建好,任务来了可以直接入队,由空闲线程处理。相比临时创建线程,响应路径更短。
3. 请求具有突发性
服务器可能突然收到大量请求。如果没有线程池,程序可能瞬间创建大量线程,导致内存消耗暴涨、调度开销增加,甚至触发系统资源限制。
线程池通过任务队列把突发流量缓冲下来:
大量请求瞬间到达 -> 进入任务队列排队 -> 固定数量worker按能力处理
4. 希望限制资源使用
线程数量不是无限的。线程越多,调度器负担越重,内存占用越大,CPU cache 命中率也可能下降。
线程池可以明确控制线程数量,例如固定创建 5 个或 10 个工作线程:
static const int gnum = 5;这可以避免程序在高并发场景下失控。
1.3线程池两种常见类型
1.3.1固定线程池
固定线程池在初始化时创建固定数量的线程,后续线程数量不再变化。
特点:线程数量稳定,实现简单,资源使用可控,适合多数基础服务场景
固定线程池的工作模式如下:
- 创建 N 个工作线程
- 每个线程循环等待任务
- 任务到来后取出并执行
- 没有任务时进入等待
- 线程池停止时统一退出
1.3.2浮动线程池
浮动线程池会根据任务数量动态增加或减少线程数量。
特点:任务多时增加线程,任务少时回收线程,资源利用更灵活,实现复杂度更高
浮动线程池需要额外考虑:最小线程数,最大线程数,线程空闲时间,任务积压阈值,线程回收策略。
在基础线程池实现中,固定线程池更适合作为第一版设计。它结构清晰,易于验证,也更适合学习线程池的核心思想。
1.4固定线程池
一个固定线程池通常包含以下成员:
template <typename T>
class ThreadPool
{
private:
std::vector<Thread> _threads; // 工作线程集合
int _num; // 线程数量
bool _isrunning; // 线程池是否运行
int _sleeper_cnt; // 正在休眠的线程数量
std::queue<T> _queue; // 任务队列
Mutex _lock; // 保护任务队列和线程池状态
Cond _cond; // 用于唤醒等待任务的线程
};任务类型可以使用模板参数 T 表示。在线程池场景中,常见任务类型是:
using task_t = std::function<void()>;这样线程池不关心任务具体是什么,只要求任务能够像函数一样被调用。
例如:
void task1()
{
// 执行任务 1
}
void task2()
{
// 执行任务 2
}提交任务:
tp->Enqueue(task1);
tp->Enqueue(task2);工作线程执行任务:
task();1.4.1std::function<void()>讲解
线程池中的任务本质上是一段可执行逻辑。
这段逻辑可能是:普通函数,lambda 表达式,函数对象,绑定后的成员函数,包装后的回调
使用 std::function<void()> 可以统一这些任务类型。
例如普通函数:
void Download()
{
std::cout << "download task" << std::endl;
}lambda:
auto task = [](){
std::cout << "lambda task" << std::endl;
};绑定成员函数:
std::bind(&ClassName::Func, object_ptr)他们都被封装为:
std::function<void()>线程池只关心:
task();1.4.2线程池启动流程
线程池构造时,可以先创建线程对象,但不立即启动线程。
ThreadPool(int num = gnum)
: _num(num), _isrunning(false), _sleeper_cnt(0)
{
for (int i = 0; i < _num; i++)
{
_threads.emplace_back([this]()
{
this->ThreadRoutine();
});
}
}这里做了两件事:1. 创建指定数量的 Thread 对象 2. 给每个线程绑定工作函数 ThreadRoutine
真正启动线程时调用:
void Start()
{
LockGuard lockguard(&_lock);
if (_isrunning)
return;
_isrunning = true;
for (auto &thread : _threads)
thread.start();
}启动流程如下:
构造 ThreadPool
|
v
创建多个 Thread 对象
|
v
Start 设置 _isrunning = true
|
v
依次调用 pthread_create
|
v
worker 线程进入 ThreadRoutine
1.4.3工作线程的核心循环
void ThreadRoutine()
{
while (true)
{
T task;
{
LockGuard lockguard(&_lock);
while (IsTaskQueueEmpty() && _isrunning)
{
_sleeper_cnt++;
_cond.Wait(_lock);
_sleeper_cnt--;
}
if (IsTaskQueueEmpty() && !_isrunning)
{
break;
}
task = PopHelper();
}
task();
}
}这段代码可以拆成四个阶段。
1. 队列为空,线程池仍在运行
while (IsTaskQueueEmpty() && _isrunning)
{
_cond.Wait(_lock);
}此时 worker 没有任务可做,但线程池仍然处于运行状态,所以 worker 不能退出,只能等待新任务到来。
2. 队列为空,线程池已经停止
if (IsTaskQueueEmpty() && !_isrunning)
{
break;
}如果线程池已经停止,并且任务队列为空,说明没有剩余任务需要处理,worker 可以退出。
3. 队列中有任务
task = PopHelper();只要队列不为空,就取出一个任务。
4. 在锁外执行任务
task();这是线程池设计中非常重要的一点。任务执行不能放在临界区内部。
错误思路:
lock();
task = queue.front();
queue.pop();
task(); // 错误:持锁执行任务
unlock();这样会导致严重问题:其他线程无法继续取任务;提交任务的线程可能被阻塞;Stop 操作可能无法及时执行;任务如果耗时很长,会扩大锁竞争;任务如果再次调用线程池接口,可能造成死锁
正确方式是:
锁内取任务 锁外执行任务
任务从队列中取出后,已经变成当前线程的私有数据,不再属于共享资源,因此应该释放锁后再执行。
1.4.4任务入队流程
任务入队接口如下:
void Enqueue(T task)
{
LockGuard lockguard(&_lock);
if (!_isrunning)
return;
_queue.push(task);
if (_sleeper_cnt > 0)
_cond.NotifyOne();
}逻辑很清晰:
1. 线程池未运行,不允许提交任务
2. 线程池正在运行,任务进入队列
3. 如果有 worker 正在休眠,则唤醒一个
任务入队后只唤醒一个线程:
_cond.NotifyOne();原因是一次 Enqueue 通常只提交一个任务。一个任务只需要一个 worker 处理,唤醒一个线程即可。
如果一次唤醒所有线程,可能出现“惊群”:
- 多个线程同时被唤醒
- 只有一个线程拿到任务
- 其他线程醒来后发现没任务
- 再次睡眠
这会造成不必要的调度开销。因此,单任务入队时唤醒一个等待线程是更合理的策略。
1.4.5线程池停止流程
线程池停止不是直接杀死线程,而是通知所有 worker:线程池准备退出了。
停止接口:
void Stop()
{
LockGuard lockguard(&_lock);
if (_isrunning)
{
_isrunning = false;
if (_sleeper_cnt > 0)
_cond.NotifyAll();
}
}停止时要做两件事:
- 设置 _isrunning = false
- 唤醒所有正在等待的 worker
为什么要唤醒所有 worker?
因为此时可能有多个线程正在等待任务。如果不唤醒它们,它们会一直阻塞,无法检查 _isrunning 的变化,也就无法退出。
停止后,每个 worker 被唤醒,重新检查状态:
if (IsTaskQueueEmpty() && !_isrunning)
{
break;
}如果任务队列已经为空,就退出线程函数。线程池停止之后,还需要等待所有线程退出:
void Wait()
{
for (auto &thread : _threads)
thread.join();
}完整生命周期应当是:
tp->Start();
tp->Enqueue(task1);
tp->Enqueue(task2);
tp->Stop();
tp->Wait();如果只调用 Wait(),不调用 Stop(),worker 在线程池仍然运行的情况下会继续等待任务,主线程会卡在 join()。
因此线程池退出顺序必须是:
- Stop 通知退出
- Wait 回收线程
1.5线程池中任务处理策略
线程池停止时,通常有两种策略。
1. 立即停止
线程池停止后,不再处理队列中剩余任务,worker 尽快退出。
这种策略适合:
程序即将退出
剩余任务可以丢弃
任务没有强一致性要求
2. 优雅停止
线程池停止后,不再接收新任务,但队列中已有任务仍然继续处理,直到队列为空后 worker 再退出。
本次的线程池设计更接近优雅停止。因为 worker 的退出条件是:
if (IsTaskQueueEmpty() && !_isrunning)
{
break;
}线程池停止 && 队列为空 -> 退出;线程池停止 && 队列不为空 -> 继续取任务执行。这种策略适合大多数任务队列场景。它保证已经提交的任务尽可能被处理完成。
1.6线程池怎么提高性能
线程池提高性能并不是因为“线程越多越快”,而是因为它减少了不必要的线程生命周期成本,并控制了并发规模。
1. 避免频繁创建线程
普通模式:
- 任务到来
- 创建线程
- 执行任务
- 销毁线程
线程池模式:
- 线程提前创建
- 任务到来
- 空闲线程执行
- 线程继续等待下一个任务
线程被复用,避免反复创建和销毁。
2. 限制线程数量
如果每个任务都创建线程,突发请求会导致线程数量暴涨。
线程池中线程数量固定:任务可以很多,线程数量固定。
任务多时排队,线程按能力消费。
3. 降低调度压力
Linux 调度器需要在可运行线程中选择下一个运行者。
线程过多会导致:调度队列变长;上下文切换增加;CPU cache 命中率下降;内存占用增加。
线程池通过控制线程数量,让系统并发度保持在合理范围。
4. 改善缓存局部性
频繁创建和销毁线程会破坏缓存局部性。线程池中的 worker 长期存在,反复执行相似逻辑,有利于 CPU cache 保持热数据。
1.7线程池与Linux内核调度
在 Linux 中,线程本质上也是一个内核调度实体。每个线程都有自己的 task_struct,也有自己的调度状态。
线程池中的 worker 大致经历这些状态:
创建 -> 可运行 -> 运行 -> 等待任务时阻塞 -> 被唤醒后重新进入可运行队列 -> 再次运行 -> 线程池停止后退出
当 worker 没有任务时,它不会一直占用 CPU,而是阻塞等待。阻塞线程不会被调度器继续分配时间片。
任务到来后,提交线程唤醒 worker,worker 重新进入可运行队列,等待调度器调度。
这就是线程池高效的关键:没任务时不消耗 CPU,有任务时快速唤醒处理
如果使用忙等:
while (queue.empty()) {}线程会一直占用 CPU,导致系统资源浪费。线程池必须使用阻塞等待模型,而不是空转模型。
2.线程安全的单例模式
2.1单例模式概念
单例模式的目标是:
一个类在整个进程中只创建一个实例。
线程池适合做成单例的原因是:一个进程中通常不希望每个模块都创建自己的线程池。如果多个模块各自创建线程池,线程数量会失控。
例如:
- 模块 A 创建 10 个线程
- 模块 B 创建 10 个线程
- 模块 C 创建 10 个线程
最终系统中可能出现大量 worker,而每个模块都不知道整体线程数量。
单例线程池可以让整个程序共享同一个任务调度中心:
所有模块 -> 同一个线程池 -> 统一任务队列和 worker 集合
这样可以集中控制并发规模。
2.2懒汉方式和饿汉方式实现单例模式
洗碗的例子:
吃完饭, 立刻洗碗, 这种就是饿汉⽅式. 因为下⼀顿吃的时候可以立刻拿着碗就能吃饭。
吃完饭, 先把碗放下, 然后下⼀顿饭用到这个碗了再洗碗, 就是懒汉方式。
2.2.1饿汉方式
template <typename T>
class Singleton {
static T data;
public:
static T* GetInstance() {
return &data;
}
};只要通过Singleton这个包装类来使用T对象,则一个进程中只有一个T对象的实例。
2.2.2懒汉方式
懒汉式单例是指:对象第一次被使用时才创建。
基本结构:
template <typename T>
class ThreadPool
{
private:
static ThreadPool<T> *_instance;
static Mutex _lock;
ThreadPool(int threadnum = gdefaultthreadnum)
: _threadnum(threadnum), _waitnum(0), _isrunning(false)
{}
public:
static ThreadPool<T> *GetInstance()
{
if (nullptr == _instance)
{
LockGuard lockguard(&_lock);
if (nullptr == _instance)
{
_instance = new ThreadPool<T>();
_instance->InitThreadPool();
_instance->Start();
}
}
return _instance;
}
};双重判断的意义是:
第一层 if:避免对象创建后每次获取都加锁
加锁:保证第一次创建时只有一个线程进入
第二层 if:防止多个线程排队进入锁后重复创建
如果没有第二层判断,可能出现:
线程 A 进入第一层 if,等待锁
线程 B 进入第一层 if,创建对象
线程 A 获得锁后继续创建对象
因此双重判断是为了保证只创建一次。
2.3现代C++更推荐的单例写法
传统双检锁写法涉及内存可见性和指令重排问题。课件中提到可以使用 volatile 防止过度优化,但在现代 C++ 中,volatile 不是线程同步工具。
更推荐的方式是使用 C++11 之后的局部静态变量:
template <typename T>
class ThreadPool
{
public:
static ThreadPool<T>& GetInstance()
{
static ThreadPool<T> instance;
return instance;
}
private:
ThreadPool() = default;
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
};C++11 起,函数内静态局部变量的初始化是线程安全的。
也可以使用:
std::call_once
std::once_flag例如:
static std::once_flag flag;
static ThreadPool<T>* instance = nullptr;
static ThreadPool<T>* GetInstance()
{
std::call_once(flag, [](){
instance = new ThreadPool<T>();
instance->Start();
});
return instance;
}这比手写双检锁更稳妥。不过从教学角度看,双重判断加锁能够帮助理解:
为什么懒汉单例有线程安全问题
为什么需要加锁
为什么需要第二次判断
为什么要减少锁竞争
2.4线程安全的本质
线程安全指的是:多个线程并发访问共享资源时,程序仍然能得到正确结果,不会互相破坏。
如果多个线程执行的代码只使用局部变量,一般不会出现线程安全问题。
例如:
int Add(int a, int b)
{
int ret = a + b;
return ret;
}局部变量位于各自线程的栈空间中,每个线程都有自己的副本。
但如果函数中访问了全局变量、静态变量、共享堆对象,就可能出现线程安全问题。
常见线程不安全情况包括:
- 不保护共享变量
- 函数内部状态会随着调用改变
- 返回指向静态变量的指针
- 调用线程不安全函数
例如:
int g_count = 0;
void Inc()
{
g_count++;
}g_count++ 并不是一条不可分割的 CPU 操作。它大致包含:
读取 g_count
加 1
写回 g_count
多个线程同时执行时可能发生数据覆盖,最终结果小于预期。
线程安全的解决方式通常有:
- 使用互斥锁保护共享变量
- 使用原子操作
- 避免共享数据
- 使用线程局部存储
- 让每个线程操作自己的数据副本
3.可重入函数
可重入指的是:同一个函数在上一次调用还没有结束时,又被其他执行流再次进入,仍然能正确执行。
重入可能来自两类场景:
- 多线程同时调用同一个函数
- 信号打断当前执行流后再次调用同一个函数
如果一个函数在重入情况下仍然不会出错,它就是可重入函数。
可重入函数通常具有这些特点:
- 不使用全局变量
- 不使用静态变量
- 不返回静态或全局数据地址
- 不调用不可重入函数
- 所有状态由调用者提供
- 只使用局部数据
不可重入函数常见情况:
内部使用静态数据结构
调用 malloc/free
调用很多标准 IO 函数
返回静态缓冲区地址
为什么 malloc/free 也可能不可重入?
因为堆管理器内部通常维护全局数据结构,例如空闲链表、arena 等。虽然现代 libc 会通过锁保证多线程安全,但在信号重入场景下仍然不是任意安全的。
4.线程安全和可重入的关系
线程安全和可重入很容易混淆,但二者不是同一个概念。
可以这样理解:
- 线程安全:强调多个线程访问共享资源时是否安全
- 可重入:强调一个函数能否被重复进入
他们的关系:
可重入函数一定是线程安全的
线程安全函数不一定是可重入的
为什么线程安全函数不一定可重入?
因为线程安全可以通过加锁实现。
例如:
void Func()
{
lock();
// 访问共享资源
unlock();
}这个函数对多线程可能是安全的,因为锁保护了共享资源。
但是如果当前线程在持锁期间被信号打断,信号处理函数又调用 Func(),它会再次申请同一把锁。由于第一次调用还没有释放锁,就可能死锁。
所以:加锁可以让函数线程安全,但加锁不一定让函数可重入
总结:可重入函数是线程安全函数的一种,线程安全不一定可重入,如果不考虑信号重入,二者在很多普通多线程场景中可以近似理解。
5.死锁
5.1死锁的概念
死锁是指多个执行流互相等待对方释放资源,最终全部永久阻塞。
一个经典场景:
线程 A 持有锁 1,等待锁 2
线程 B 持有锁 2,等待锁 1
线程 A 不释放锁 1,因为它在等锁 2。
线程 B 不释放锁 2,因为它在等锁 1。
两个线程都无法继续执行。
死锁的关键在于:
- 每个线程都持有一部分资源
- 每个线程又在等待别人持有的资源
- 没有线程愿意或能够释放已有资源
申请一把锁是原子的,但是申请两把锁就不一定了。
申请一把锁时,要么成功,要么阻塞。但申请两把锁时,可能已经拿到第一把锁,然后卡在第二把锁上。
5.2死锁的四个必要条件
死锁产生需要同时满足四个条件。
1. 互斥条件
资源一次只能被一个执行流使用。
例如一把互斥锁同一时刻只能被一个线程持有。
2. 请求与保持条件
一个执行流已经持有某些资源,同时又请求新的资源,并且在等待新资源时不释放已有资源。
例如:
线程 A 已经持有锁 1
现在继续请求锁 2
请求锁 2 期间不释放锁 1
3. 不剥夺条件
一个执行流已经获得的资源,在使用完之前,不能被其他执行流强行剥夺,只能由它主动释放。
锁就是典型例子。线程 A 持有锁后,线程 B 不能强行把锁抢走。
4. 循环等待条件
多个执行流之间形成首尾相接的等待关系。
例如:
线程 A 等待线程 B 的资源
线程 B 等待线程 C 的资源
线程 C 等待线程 A 的资源
只要四个条件同时成立,就可能发生死锁。
5.3如何避免死锁
避免死锁的思路是:破坏死锁四个必要条件中的任意一个。
工程中最常用的是破坏循环等待条件。
1. 保证加锁顺序一致
如果所有线程都按照相同顺序申请锁,就不会形成循环等待。
例如规定:所有线程必须先申请锁 1,再申请锁 2,不能出现一个线程先锁 1 后锁 2,另一个线程先锁 2 后锁 1。
2. 一次性申请多把锁
C++ 中可以使用:
std::unique_lock<std::mutex> lock1(mtx1, std::defer_lock);
std::unique_lock<std::mutex> lock2(mtx2, std::defer_lock);
std::lock(lock1, lock2);std::lock 会以避免死锁的方式同时锁定多把锁。
3. 使用超时机制
如果一个线程长时间拿不到锁,可以放弃当前持有的资源,稍后重试。
这种方式可以避免永久等待。
4. 减少持锁时间
临界区越大,死锁和锁竞争风险越高。
线程池中“锁内取任务,锁外执行任务”就是减少持锁时间的典型设计。
5. 避免持锁调用外部未知代码
如果在持锁状态下调用外部函数,而外部函数内部又尝试申请其他锁,就容易引入复杂锁顺序。
例如:
lock();
callback();
unlock();如果 callback() 内部又调用当前模块接口,就可能造成死锁。线程池执行任务时必须在锁外执行,也正是为了避免这类问题。
6.STL容器是否线程安全
STL 容器默认不是线程安全的。
原因很现实:STL 的设计目标是尽可能追求性能。如果每个容器内部都默认加锁,会让单线程场景和外部已经加锁的场景付出不必要成本。
例如:
std::queue<T> _queue;多个线程同时执行:
_queue.push(task);
_queue.pop();
_queue.front();
_queue.empty();如果没有外部锁保护,就可能出现数据竞争。
因此在线程池中,任务队列必须由线程池自己加锁保护:
LockGuard lockguard(&_lock);
_queue.push(task);以及:
LockGuard lockguard(&_lock);
task = _queue.front();
_queue.pop();不同 STL 容器的并发策略也不一样:
vector:插入、删除、扩容都需要保护
queue:push、pop、front、empty 都需要保护
map:树结构修改需要保护
unordered_map:可以锁整张表,也可以按桶加锁
STL 不默认加锁,是为了把并发控制权交给调用者。因为只有调用者最清楚业务需要什么粒度的锁。
7.智能指针是否线程安全
智能指针的线程安全需要分情况讨论。
1. unique_ptr
unique_ptr 是独占所有权。
std::unique_ptr<ThreadPool<task_t>> tp;它通常只在一个作用域或一个线程中拥有对象,因此不涉及共享引用计数问题。
但如果多个线程同时访问同一个 unique_ptr 对象本身,仍然需要外部同步。
2. shared_ptr
shared_ptr 的引用计数是线程安全的。
多个线程分别持有不同的 shared_ptr 副本时,引用计数的增加和减少通常通过原子操作保证安全。
但必须注意:
shared_ptr 的引用计数线程安全,不代表它指向的对象线程安全。
例如:
std::shared_ptr<std::queue<int>> q;多个线程拷贝 q 是安全的,但多个线程同时操作 *q 不安全:
q->push(1);
q->pop();这些仍然需要加锁。
智能指针解决的是对象生命周期问题,不解决对象内部状态的并发访问问题。
8.自旋锁
自旋锁是指:线程拿不到锁时,不进入睡眠,而是在 CPU 上循环等待。
while (!try_lock())
{
// retry
}自旋锁适合:
- 锁持有时间非常短
- 线程不希望进入内核睡眠
- 多核环境
- 临界区不会阻塞
自旋锁不适合:
- 锁持有时间长
- 单核环境
- 临界区可能执行 IO
- 临界区可能睡眠
因为自旋时线程一直占用 CPU。如果锁很久不释放,自旋线程会浪费大量 CPU 时间。
在 Linux 内核中,自旋锁常用于保护非常短的临界区,因为内核某些场景不能睡眠。
在用户态业务代码中,普通互斥锁通常更常用。只有在高性能、低延迟、临界区极短的场景下,才会考虑自旋锁。
9.线程池实现关键点
1. Wait() 前必须先 Stop()
线程池如果只等待线程退出,但没有通知线程退出,worker 会一直等待新任务。
正确顺序:
tp->Stop();
tp->Wait();如果省略 Stop(),程序可能卡在 join()。
2. 任务执行必须在锁外
正确:
{
LockGuard lockguard(&_lock);
task = PopHelper();
}
task();错误:
LockGuard lockguard(&_lock);
task = PopHelper();
task();持锁执行任务会扩大临界区,影响并发性能,并可能引入死锁。
3. 停止后是否处理剩余任务要设计清楚
如果希望优雅退出,停止后继续处理队列中的剩余任务。
如果希望立即退出,则停止后丢弃剩余任务。
两种策略都可以,但必须明确。
4. 线程池析构要考虑资源回收
如果线程池对象析构时 worker 仍然运行,就可能出现严重问题。
工程版本一般需要在析构中保证:
- 通知退出
- 唤醒线程
- join 回收
- 释放资源
但析构中自动 Stop/Wait 也要避免重复调用和死锁,需要设计状态机。
5. 不建议依赖 pthread_cancel 停止线程
pthread_cancel 会在线程的取消点终止线程。线程可能正在持锁、执行任务、写文件、修改共享状态。
更稳妥的方式是:
设置退出标志
唤醒所有 worker
让 worker 自然退出循环
主线程 join 回收
线程池中的 _isrunning 正是这种退出协议的核心。
10.总结
一个固定线程池的完整运行过程如下:
创建线程池对象
|
v
构造多个 worker 线程对象
|
v
Start 启动线程池
|
v
worker 线程进入循环
|
v
任务队列为空,worker 休眠
|
v
外部线程 Enqueue 提交任务
|
v
任务进入队列
|
v
唤醒一个 worker
|
v
worker 取出任务
|
v
释放锁
|
v
执行任务
|
v
继续循环等待任务
|
v
Stop 设置退出状态
|
v
唤醒所有 worker
|
v
worker 处理完剩余任务后退出
|
v
Wait 回收所有线程
这就是线程池最核心的生命周期。
线程池不是一个孤立的代码模块,而是 Linux 多线程编程中多个关键知识点的综合应用。
它涉及:
- 线程复用
- 任务队列
- 生产者消费者模型
- 固定线程池
- 单例模式
- 线程生命周期管理
- 线程安全
- 可重入
- 死锁
- STL 并发边界
- 智能指针线程安全边界
- 悲观锁
- 乐观锁
- CAS
- 自旋锁
- 读写锁
一个合格的线程池实现,重点不在于“能不能把任务跑起来”,而在于能不能正确处理这些问题:
- 没有任务时 worker 是否会浪费 CPU
- 任务入队后是否能正确唤醒线程
- 线程池停止时 worker 是否能退出
- 已提交任务是否会被处理完成
- 任务执行是否会扩大临界区
- 线程数量是否可控
- 共享队列是否线程安全
- 是否存在死锁风险
线程池真正解决的是系统工程问题:在高并发环境下,用有限数量的线程稳定处理大量任务。
理解线程池,也就理解了多线程程序中非常核心的一条设计原则:
并发不是无限创建执行流,而是用可控的执行资源,高效、安全地调度任务。
本章完。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 36
36 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)