AI名词科普
·
AI名词科普
一、前言
AI领域新词迭代速度极快,本文将AI应用开发划分为三代工程化跃迁,系统拆解主流专业名词、技术原理、应用场景及常见踩坑点,梳理完整知识体系。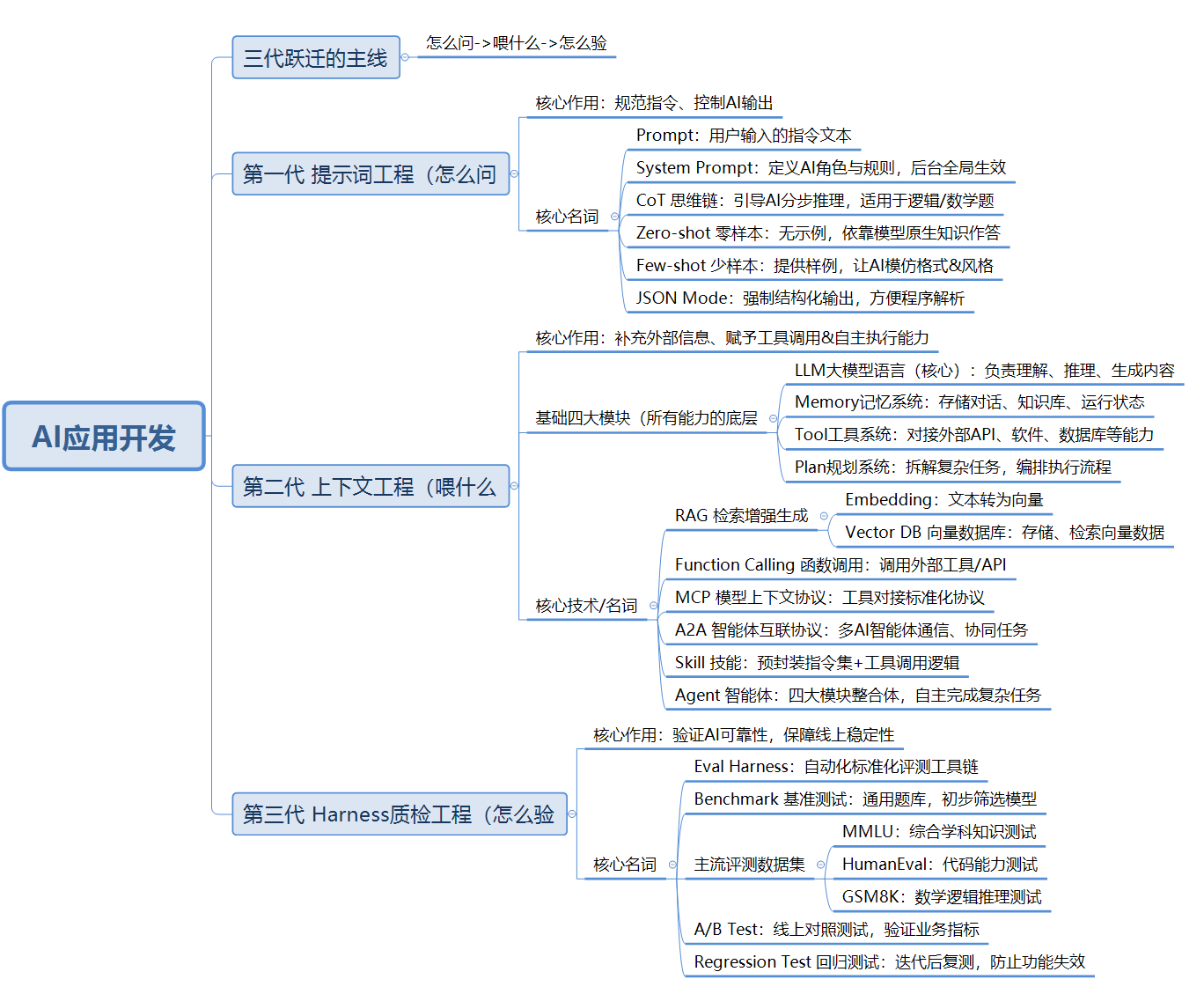
二、核心总览:AI三代工程化跃迁
AI应用开发两年完成三代能力升级,主线可概括为怎么问→喂什么→怎么验。
| 世代 | 核心能力 | 代表名词 | 核心作用 |
|---|---|---|---|
| 第一代 | 提示词工程 | Prompt、System Prompt、CoT、Few-shot、Zero-shot、JSON Mode | 教会AI听懂人类指令、规范输出结果 |
| 第二代 | 上下文工程 | RAG、Memory、Vector DB、Embedding、Function Calling、MCP、A2A、Skill、Agent、OpenClaw | 让AI调取外部资料、调用工具、自主完成任务 |
| 第三代 | Harness(质检)工程 | Eval Harness、Benchmark、MMLU、HumanEval、GSM8K、A/B Test、Regression Test | 搭建评测体系,验证AI输出可靠性 |
三、底座层:四大基础通用模块
所有AI工程化技术均基于以下四大模块组合而成,是理解各类名词的核心基础。
| 模块 | 通俗解释 | 形象类比 |
|---|---|---|
| LLM(大语言模型) | 核心主体,负责理解、推理、内容生成 | 团队中负责思考决策的核心员工 |
| Memory(记忆系统) | 存储对话历史、知识库、运行状态 | 档案柜/记事本,留存各类信息 |
| Tools(工具系统) | 对接外部能力,查数据、调用API、操作系统等 | 电脑、电话,连接外部世界 |
| Planning(规划系统) | 拆解复杂任务、规划执行流程与顺序 | 项目经理/秘书,制定待办流程 |
模块组合解读
完整AI系统需四大模块协同,缺一难以落地。以AI员工为例:LLM负责思考,Memory记录信息,Tools拓展外部能力,Planning拆分复杂工作。
四、第一代:提示词工程(Prompt Engineering)
1. 核心定位
AI基础入门能力,目标是规范AI输入指令,控制输出格式与内容,目前已是行业基础门槛。
2. 核心名词详解
- Prompt(提示词):用户输入给AI的指令文本,直接决定输出质量。
- System Prompt(系统提示词):后台隐藏配置,定义AI角色、身份、行为规则,全程生效。
- CoT(思维链):引导AI分步推理,输出思考过程,适用于数学、逻辑类难题。
- Few-shot(少样本提示):提供多组问题+答案示例,让AI模仿格式、风格作答。
- Zero-shot(零样本提示):无参考示例,AI仅凭预训练知识直接回答,仅适配简单问题。
- JSON Mode(结构化输出):强制AI以JSON格式返回内容,便于程序自动解析。
3. 阶段现状
技术趋于成熟,属于必备基础能力;局限性明显:无法读取企业内部数据、调用外部工具。
五、第二代:上下文工程(Context Engineering)
1. 核心定位
解决模型知识滞后、无法使用私有数据的问题,核心是为AI补充精准外部信息与工具能力,实现“开卷考试”。
2. 核心名词详解
- RAG(检索增强生成)
- 原理:外挂知识库,提问时先检索相关资料,再将资料并入提示词生成答案。
- 配套技术:
Embedding(文本转向量)、Vector DB(向量数据库,如Chroma、Milvus等,存储并检索向量数据)。
- Function Calling(函数调用):AI判断需外部数据时,输出结构化指令调用API/工具,获取结果后整合回复。
- MCP(模型上下文协议):Function Calling的标准化协议,统一AI与各类工具(数据库、文档、浏览器)的对接接口,实现即插即用。
- A2A(智能体互联协议):实现多个AI智能体之间通信、分发任务、同步状态,支撑多AI协同工作。
- Skill(技能):预封装的任务逻辑,包含指令与工具调用。区分标准:集成工具、有规范输入输出为真Skill;仅文本模板为假Skill。
- Agent(智能体):四大基础模块的完整组合体,可自主规划、调用工具、完成复杂任务。演进路径:工具聊天→单任务Agent→多Agent协作→通用自主Agent。
- OpenClaw:开源Agent应用框架,属于应用层封装,降低Agent开发门槛。
3. 阶段现状
中高阶AI开发必备能力,无此能力无法承接复杂企业级业务。
六、第三代:Harness(质检)工程
1. 核心定位
AI落地的关键环节,解决AI可靠性验证问题,区分业余开发者与专业团队,是2026年行业主流趋势。
2. 核心名词详解
- Eval Harness(评测框架):标准化自动化评测工具链,模型、Prompt、RAG策略更新后,一键批量测试。
- Benchmark(基准测试):行业通用测试题库,用于初步筛选劣质模型,仅作参考,高分不代表业务适配。
- 主流基准测试数据集
- MMLU:覆盖57个学科的综合能力测试,检验知识广度,衍生版本:MMLU-Pro、MMLU-R。
- HumanEval:代码能力测试,共164道编程题,衍生:HumanEval+、MBPP、LiveCodeBench。
- GSM8K:中小学数学推理题,检验多步逻辑推理能力,衍生:GSM-Hard、MATH、AIME。
- A/B Test(线上对照测试):线上分流测试不同模型/策略,关注用户满意度、任务完成率等真实业务指标。
- Regression Test(回归测试):维护标准测试题库,每次迭代后复测,避免新改动破坏原有可用功能。
3. 阶段现状
AI工业化落地分水岭,不懂质检工程难以保障线上产品稳定。
七、总结
- 主线逻辑:提示词(怎么问)→ 上下文(喂什么)→ 质检(怎么验),所有AI新词均可归入这三大类别。
- 快速判断技巧:遇到陌生名词,判断其属于优化指令、补充信息工具、能力评测哪一类,即可快速理解定位。
- 行业趋势:AI从“能对话”转向“能干活、可管控”,标准化、自动化、可评测是核心发展方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)