20.LangChain框架8-大模型记忆和LangSmith(执行过程)
内容参考于:图灵AI大模型全栈
我们的大模型都是没有记忆的,现在我们用的ai它只是在大模型的基础上进行了开发,把我们的聊天信息搞成了提示词,它分短期记忆和长期记忆,随着我们多轮的对话,提示词会非常大,提示词会爆,会非常销毁Token,现在的大模型都会有这个问题
短期记忆
一般记录十轮到三十轮左右的记录,如果超出了就提示网络不可用,或者说三十轮之前的聊天记录不要了
长期记忆
记录一百到二百轮,可以把聊天记录进行压缩,然后把聊天记录存储成知识库(RAG)
现在写的都是短期记忆,长期记忆后面再写
短期记忆LangChain给我们提供了ChatMessageHistory类
如下图内存存储
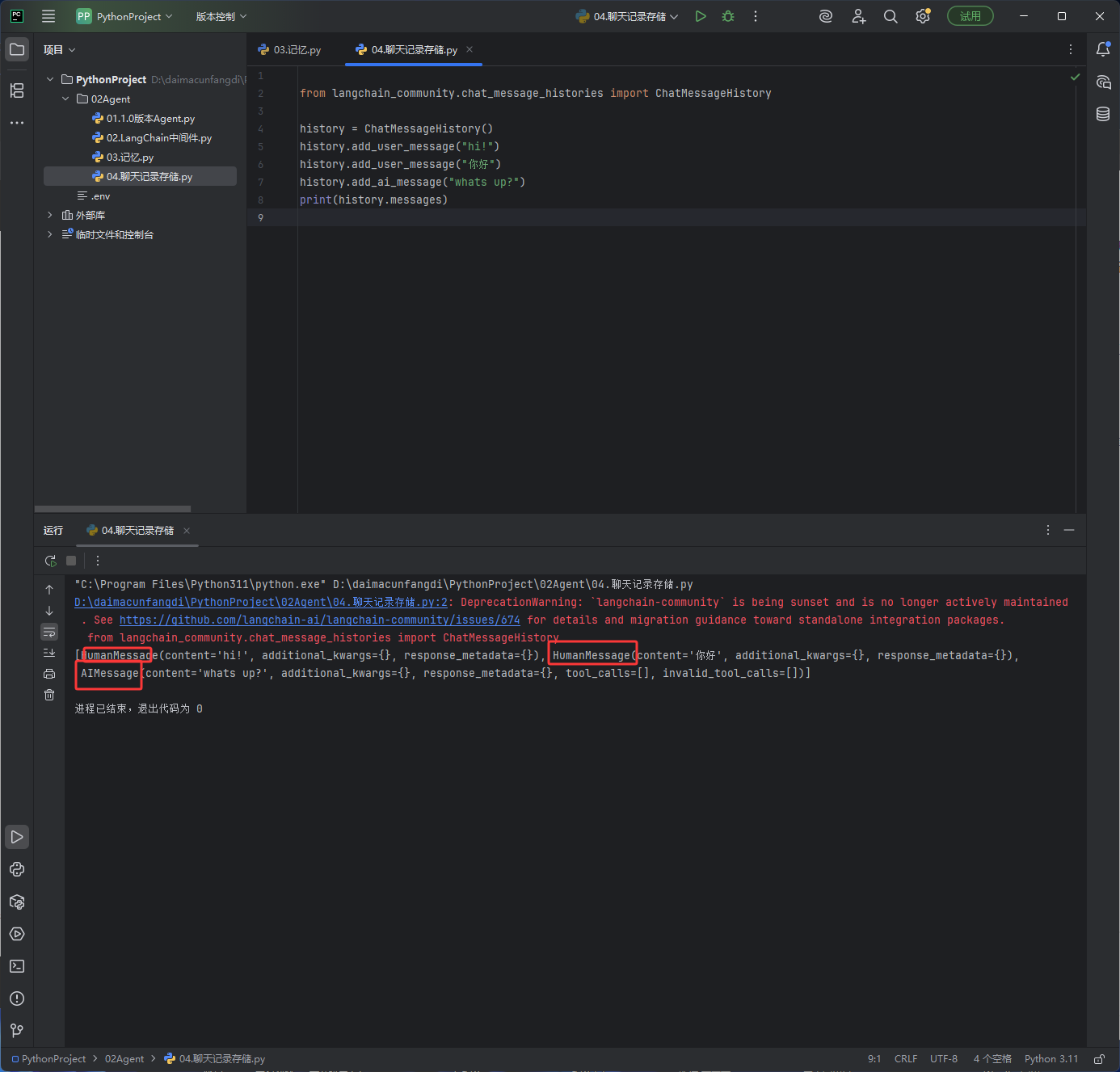
# 作用:导入聊天消息历史记录类,用于存储和管理对话消息 # 来源:langchain_community.chat_message_histories 社区库 # 入参:无 # 可传:无 # 值来源:固定导入 from langchain_community.chat_message_histories import ChatMessageHistory # 作用:创建对话消息历史实例,用于存储用户+AI的所有消息 # 入参:无 # 可传:无 # 值来源:实例化对象 history = ChatMessageHistory() # 作用:向消息历史中添加用户发送的消息 # 入参:字符串类型,用户发送的文本内容 # 可传:任意用户消息文本 # 值来源:自定义输入 history.add_user_message("hi!") # 作用:向消息历史中添加用户发送的消息 # 入参:字符串类型,用户发送的文本内容 # 可传:任意用户消息文本 # 值来源:自定义输入 history.add_user_message("你好") # 作用:向消息历史中添加AI回复的消息 # 入参:字符串类型,AI回复的文本内容 # 可传:任意AI回复文本 # 值来源:自定义输入 history.add_ai_message("whats up?") # 作用:打印消息历史中的所有消息列表 # 入参:history.messages 消息列表 # 可传:消息历史对象的messages属性 # 值来源:存储的所有对话消息 print(history.messages)
记忆
import json # 作用:带记忆的对话链 | 来源:langchain_core from langchain_core.runnables.history import RunnableWithMessageHistory # 作用:内存对话历史存储 | 来源:langchain_community from langchain_community.chat_message_histories import ChatMessageHistory # 作用:提示模板+历史占位符 | 来源:langchain_core from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder # 作用:大模型调用 | 来源:langchain_openai from langchain_openai import ChatOpenAI # 作用:消息与字典互转 | 来源:langchain_core from langchain_core.messages import messages_from_dict, messages_to_dict # 作用:加载环境变量 | 来源:python-dotenv from dotenv import load_dotenv # 作用:系统环境操作 | 来源:Python内置 import os # 作用:加载.env配置 | 入参:无 | 可传:无 | 来源:固定调用 load_dotenv() # 作用:初始化通义千问大模型 # api_key:密钥 | 入参:字符串 | 可传:阿里云API Key | 来源:.env # base_url:接口地址 | 入参:字符串 | 可传:官方地址 | 来源:阿里云 # model:模型名 | 入参:字符串 | 可传:qwen系列 | 来源:官方 llm = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus" ) # 作用:创建对话提示模板 # system:系统设定 | 入参:字符串 | 可传:自定义角色 | 来源:自定义 # MessagesPlaceholder:历史占位符 | 入参:变量名 | 可传:history | 来源:固定 # user:用户输入 | 入参:变量 | 可传:input | 来源:固定 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个友好的助手"), MessagesPlaceholder(variable_name="history"), ("user", "{input}") ]) # 作用:基础对话链 | 入参:提示词+模型 | 可传:自定义 | 来源:上方变量 base_chain = prompt | llm # 作用:全局存储会话历史 | 入参:无 | 可传:无 | 来源:内存存储 store = {} # 作用:获取/创建会话历史 # 入参:session_id 会话ID # 可传:任意字符串ID # 来源:函数调用 def get_session_history(session_id): if session_id not in store: store[session_id] = ChatMessageHistory() return store[session_id] # 作用:创建带记忆的对话链 # base_chain:基础链 | 来源:上方变量 # get_session_history:历史函数 | 来源:上方函数 # input_messages_key:输入键 | 来源:固定input # history_messages_key:历史键 | 来源:固定history conversation = RunnableWithMessageHistory( base_chain, get_session_history=get_session_history, input_messages_key="input", history_messages_key="history" ) # 作用:旧版预测接口 # 入参:input_text用户输入,session_id会话ID # 可传:任意文本、任意ID # 来源:调用传入 def legacy_predict(input_text: str, session_id: str = "default") -> str: return conversation.invoke( {"input": input_text}, config={"configurable": {"session_id": session_id}} ).content # 作用:保存历史到文件 # 入参:filepath路径,session_id会话ID # 可传:json路径、任意ID # 来源:调用传入 def save_memory(filepath, session_id): history = get_session_history(session_id) dicts = messages_to_dict(history.messages) with open(filepath, "w", encoding='utf-8') as f: json.dump(dicts, f, ensure_ascii=False) # 作用:从文件加载历史 # 入参:filepath路径,session_id会话ID # 可传:json路径、任意ID # 来源:调用传入 def load_memory(filepath, session_id): with open(filepath, "r", encoding='utf-8') as f: dicts = json.load(f) messages = messages_from_dict(dicts) store[session_id] = ChatMessageHistory(messages=messages) # 作用:主程序测试 if __name__ == "__main__": # 作用:会话ID | 入参:字符串 | 可传:任意 | 来源:自定义 SESSION_ID = "default" # 作用:连续对话测试 print("============================") print(legacy_predict("你好,我是计算机王", SESSION_ID)) print("============================") print(legacy_predict("你是谁", SESSION_ID)) print("============================") print(legacy_predict("我叫什么名字", SESSION_ID)) # 作用:保存对话历史 save_memory("./memory_new.json", SESSION_ID) # 作用:加载历史记录 # load_memory("./memory_new.json", SESSION_ID) # 作用:验证历史恢复 # reload_response = legacy_predict("我回来了,我们之前都聊了一些什么?", SESSION_ID) # print("\n恢复后的回答:", reload_response)
LangSmith是一个用来构建、监控和调试大模型的平台,由LangChain提供,LangSmith可以本地部署
首先注册LangSmith账号
LangSmith官网: https://smith.langchain.com/
如下图登录之后,可能会是下图的页面
需要再次访问LangSmith,就会来到下图的页面
然后点击下图红框的设置
然后点击下图红框创建一个API秘钥
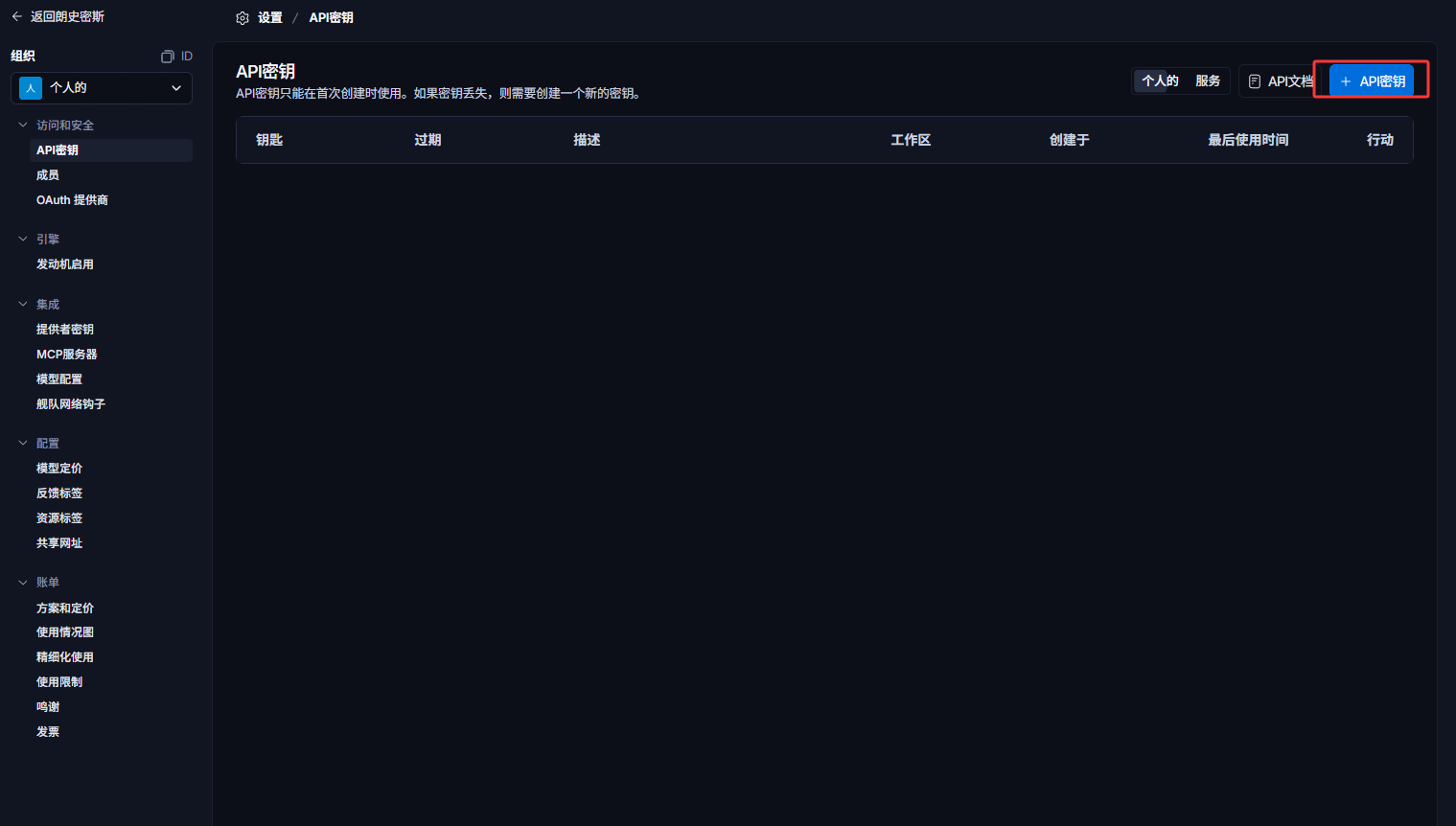
然后在.env文件中写下图红框的内容,写完之后就可以了,直接运行LangChain的代码就可以了
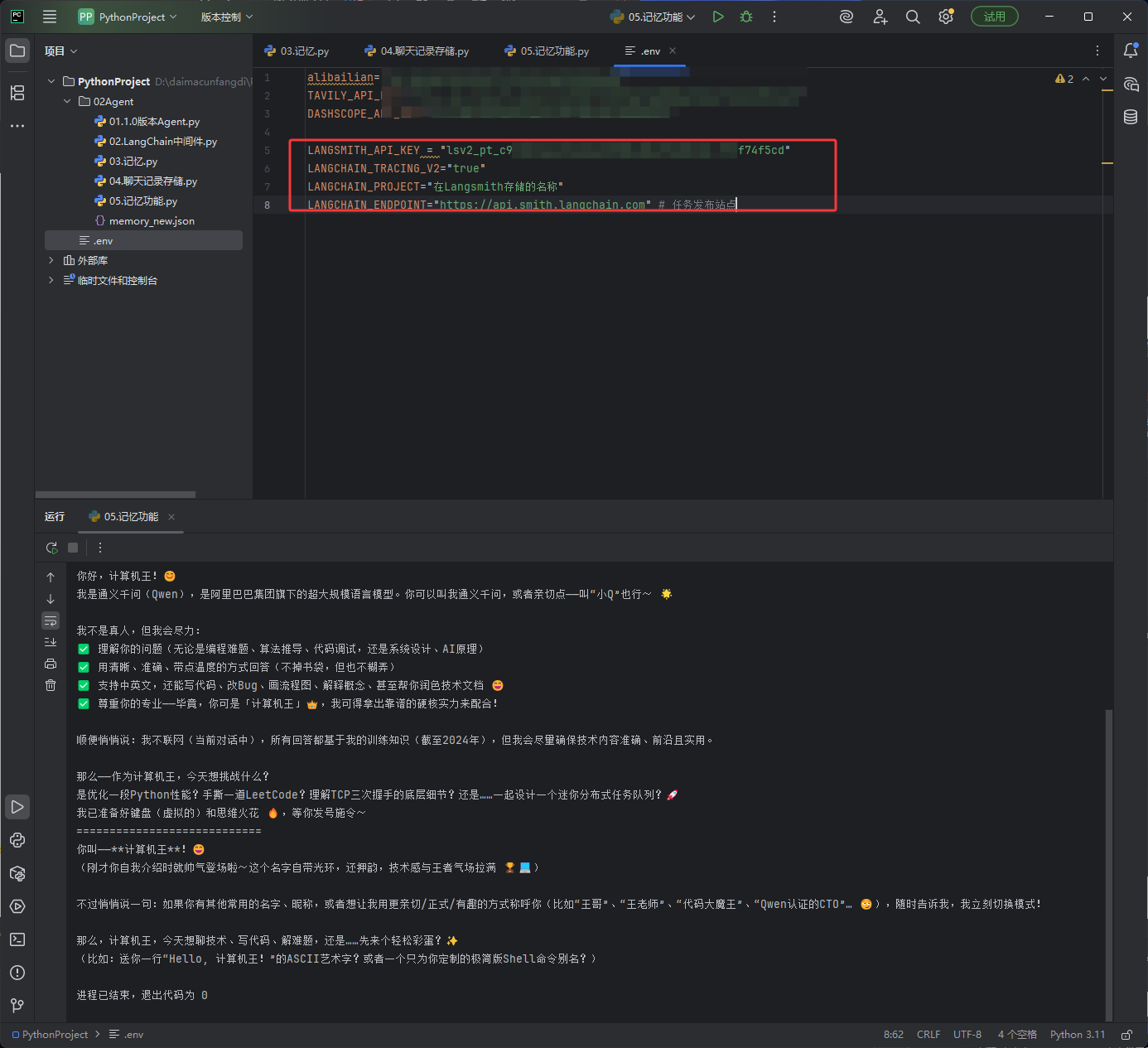
LANGSMITH_API_KEY = "这里替换成上方申请的api密钥" LANGCHAIN_TRACING_V2="true" LANGCHAIN_PROJECT="在Langsmith存储的名称" LANGCHAIN_ENDPOINT="https://api.smith.langchain.com" # 任务发布站点然后再次运行上方记忆的代码,如下图,点击下图红框
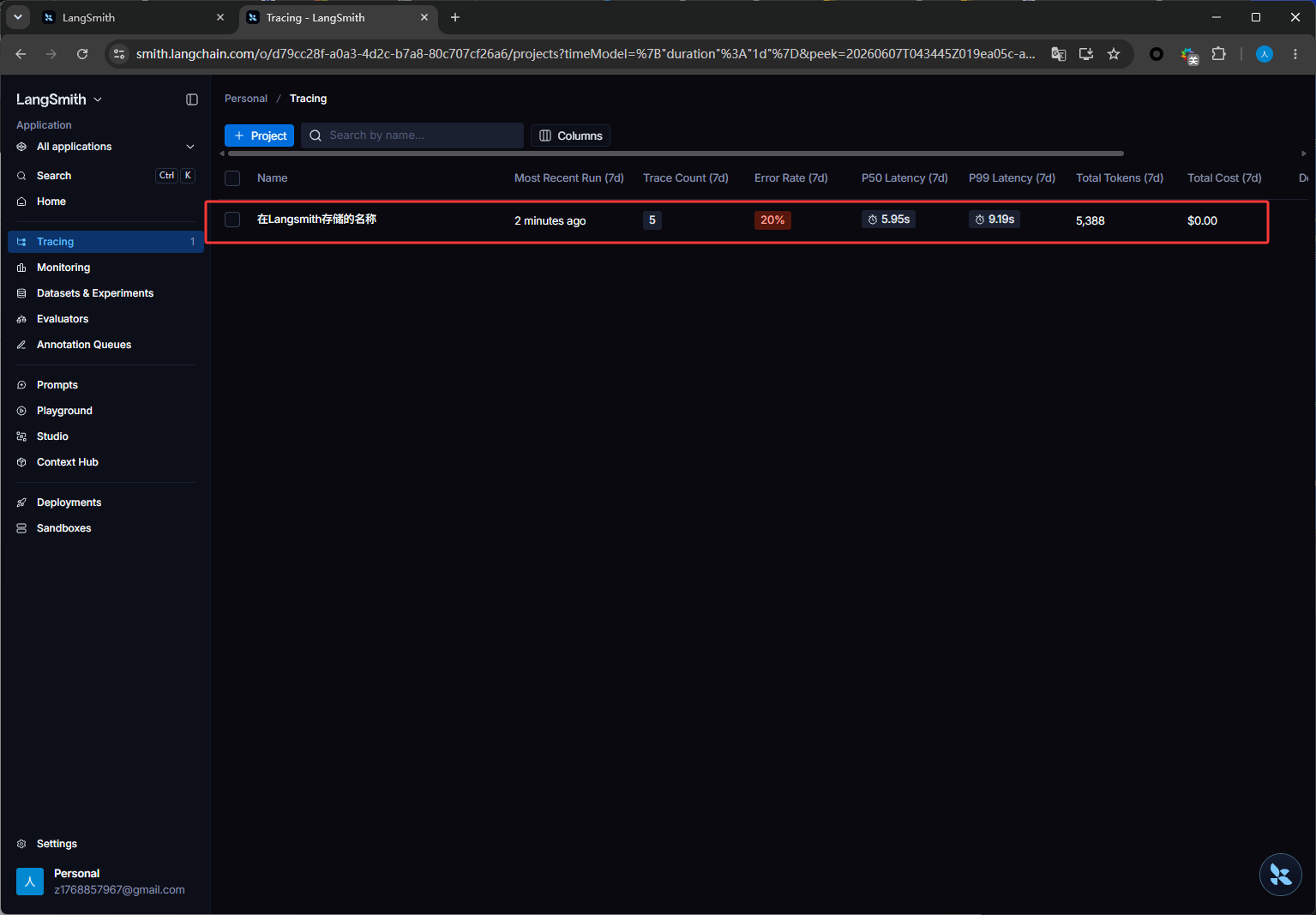
然后就可以看我们的内容了
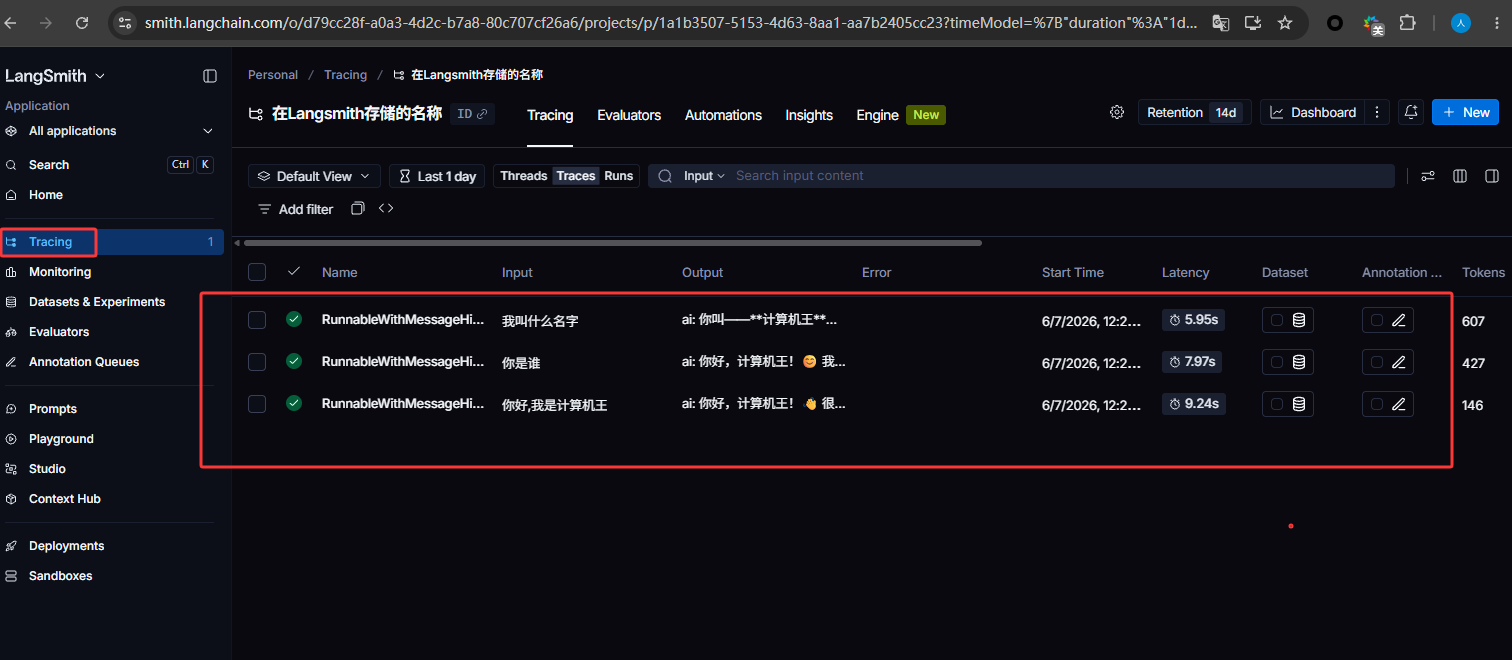
如下图,一个简单的LangSmith测试代码
如下图红框是代码调用的核心函数
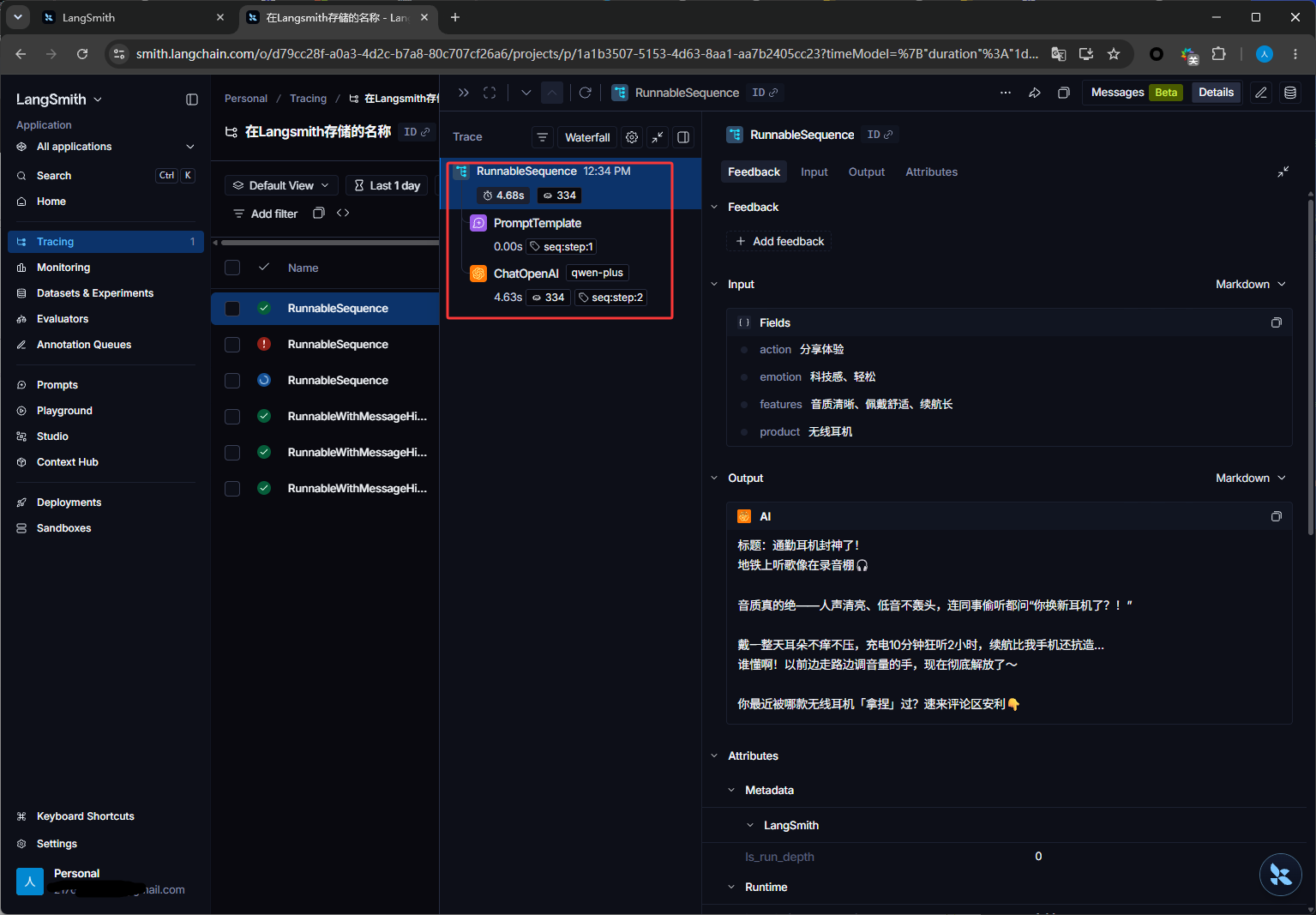
下图红框是入参和出参信息
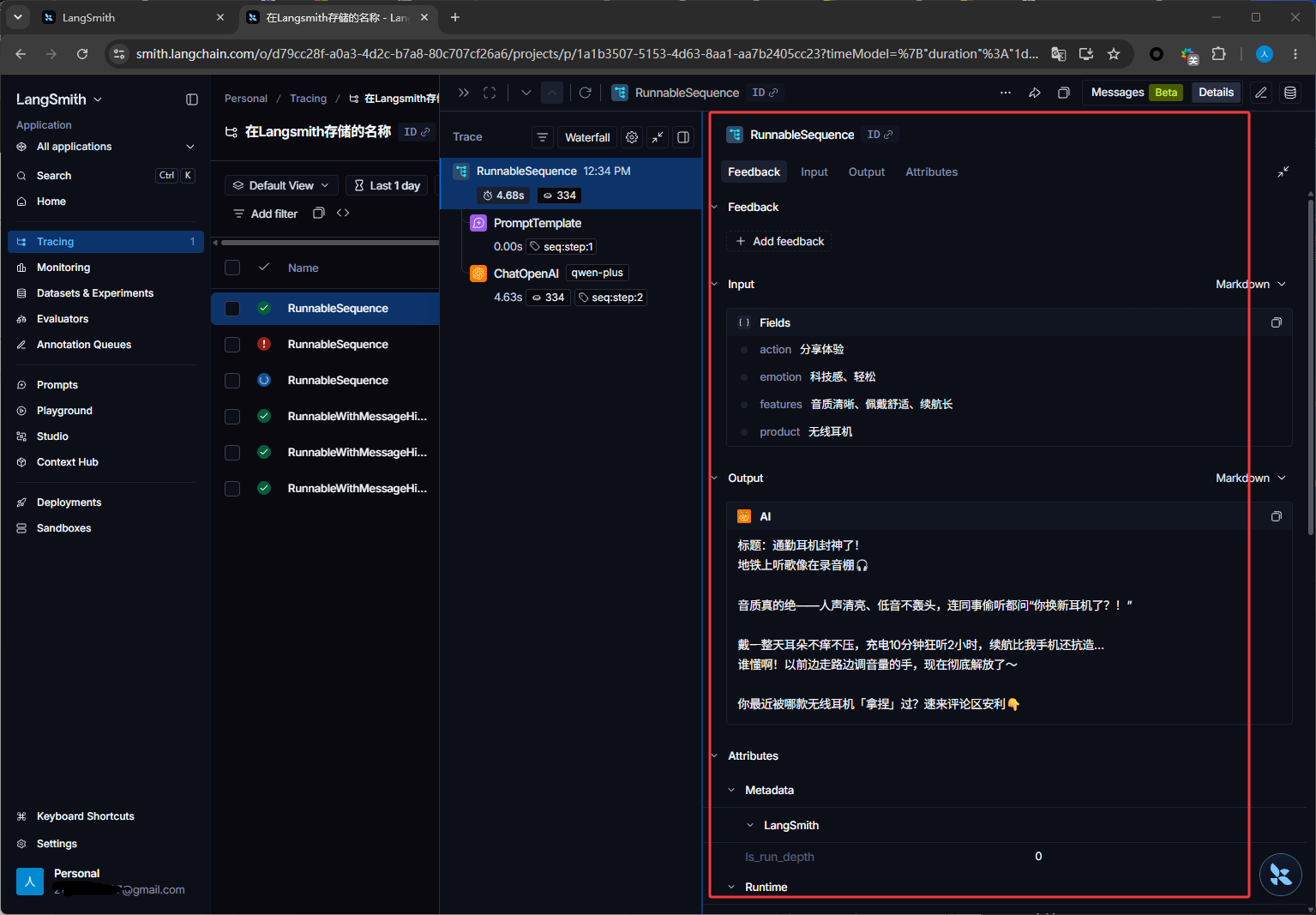
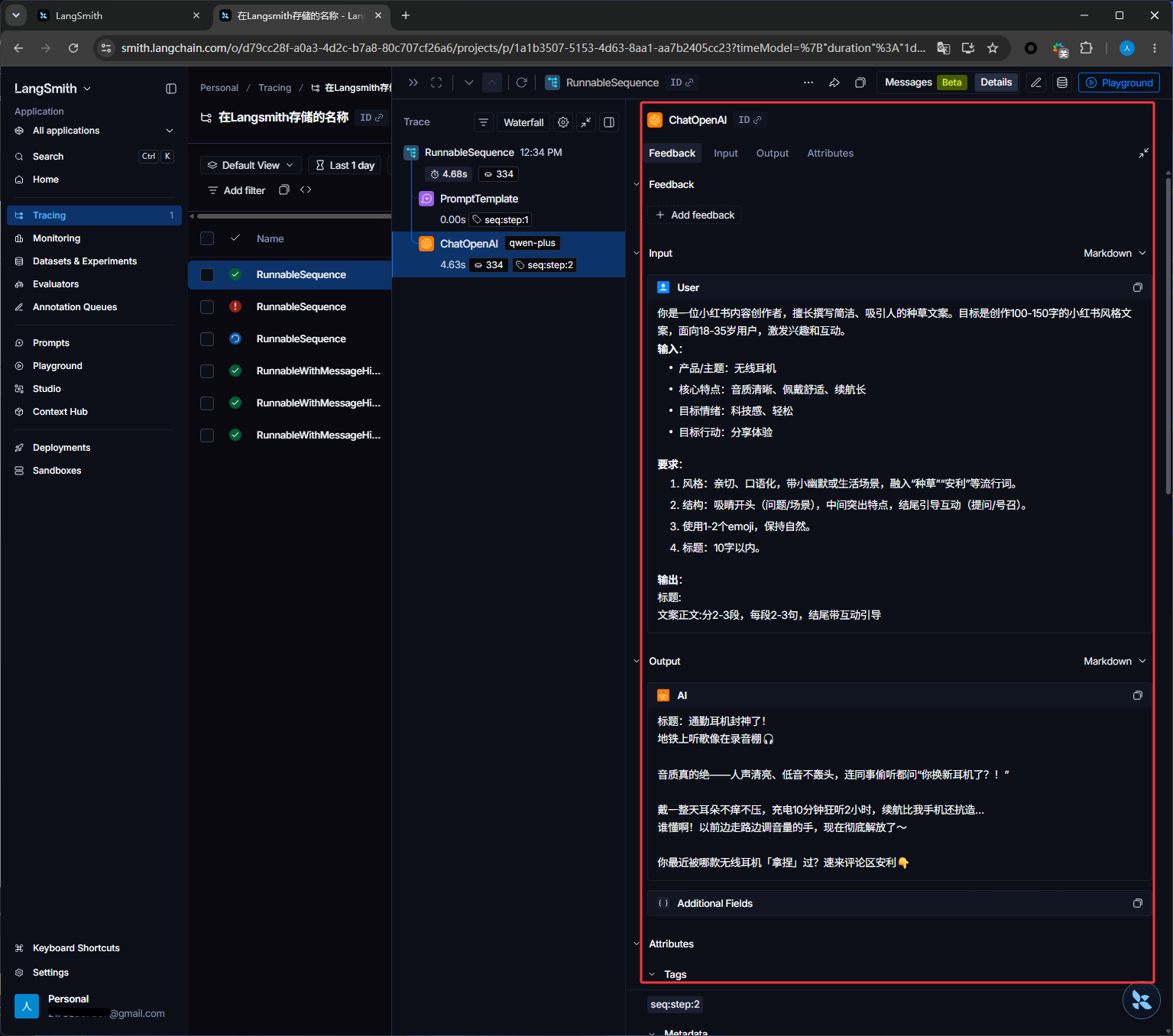
如下图红框调用OpenAi的入参和出参,也就是给大模型的提示词和大模型给我的答案
点击下图红框
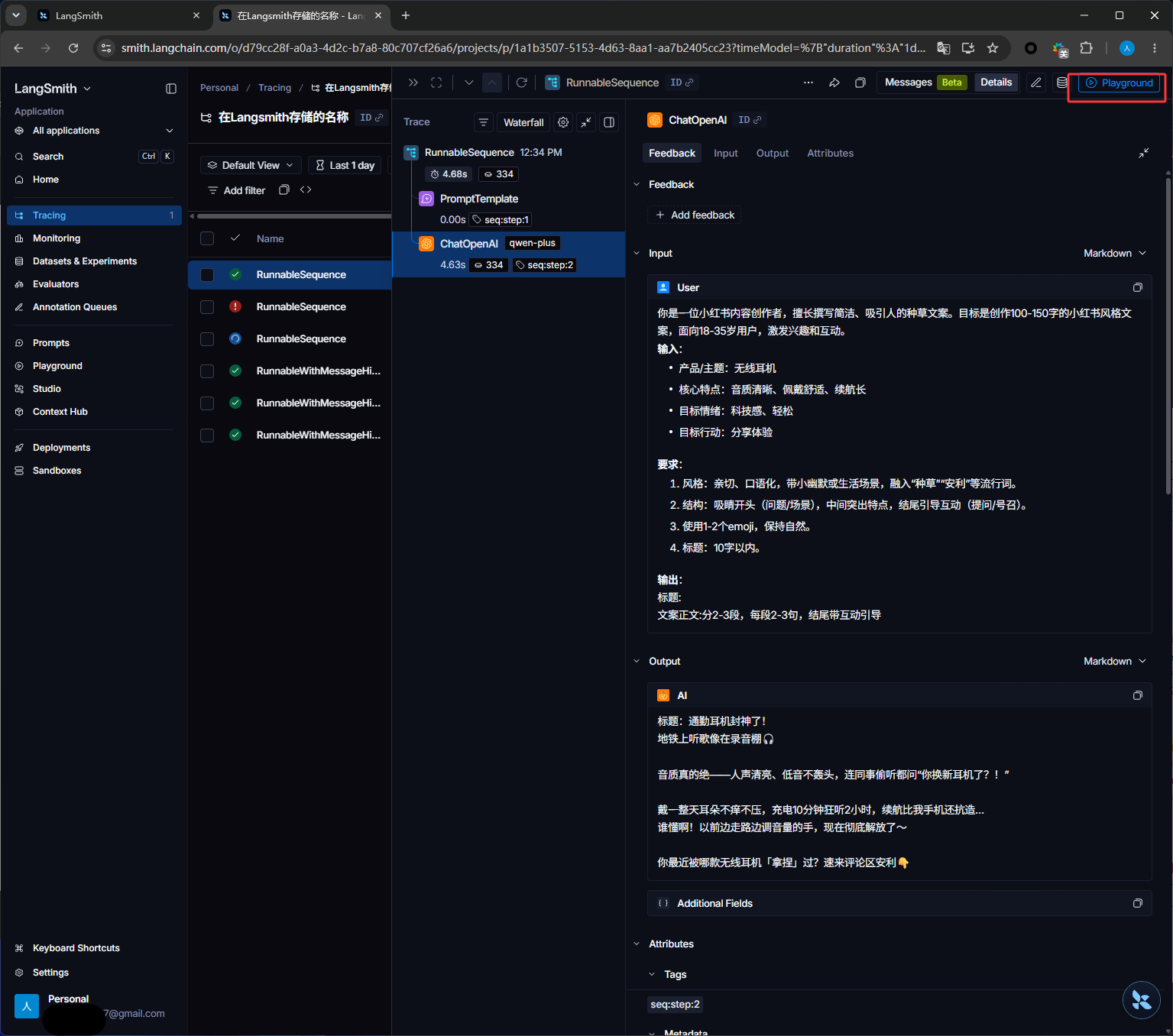
可以手动调整提示词
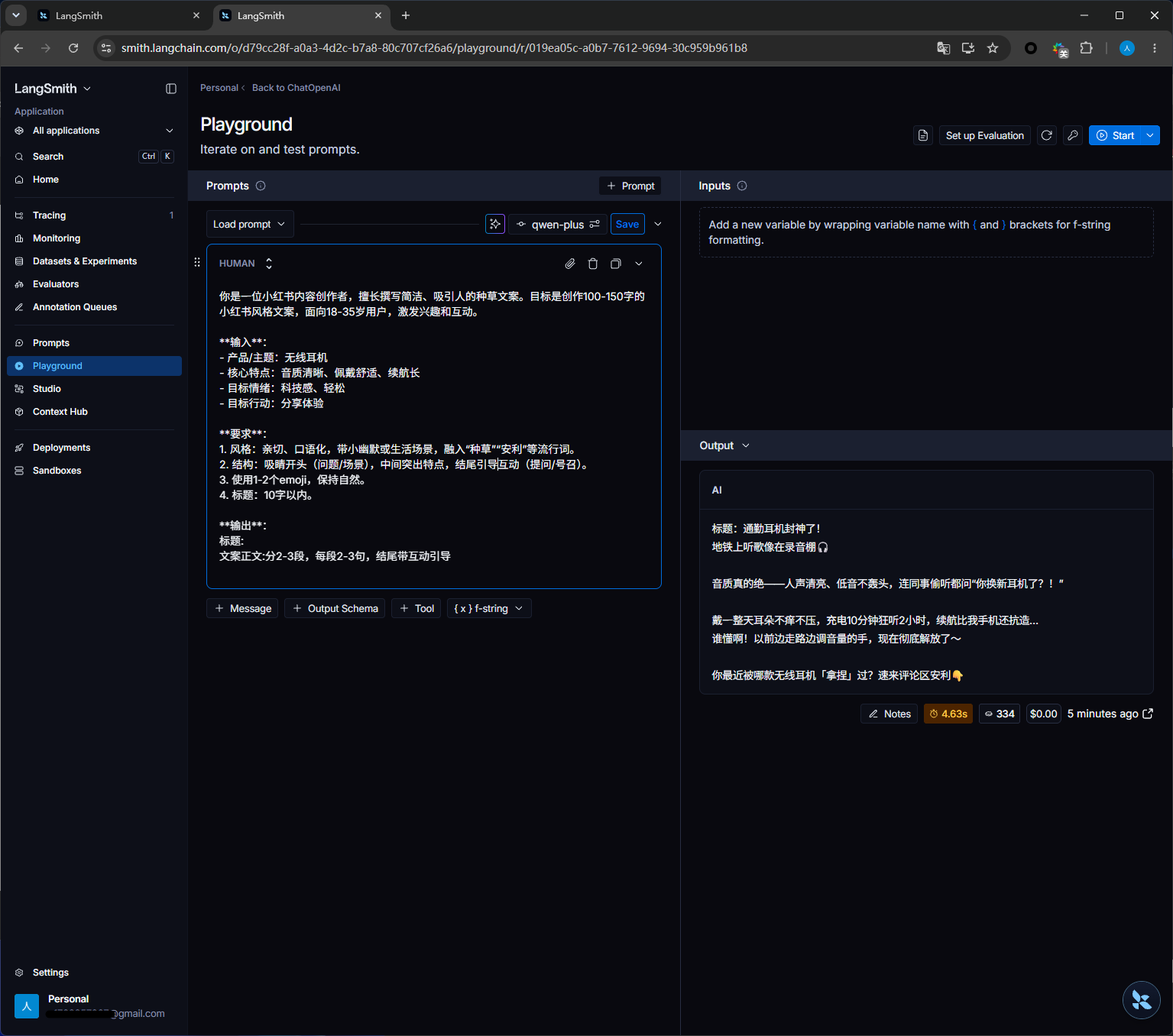
如下图红框改成了生成300到550字
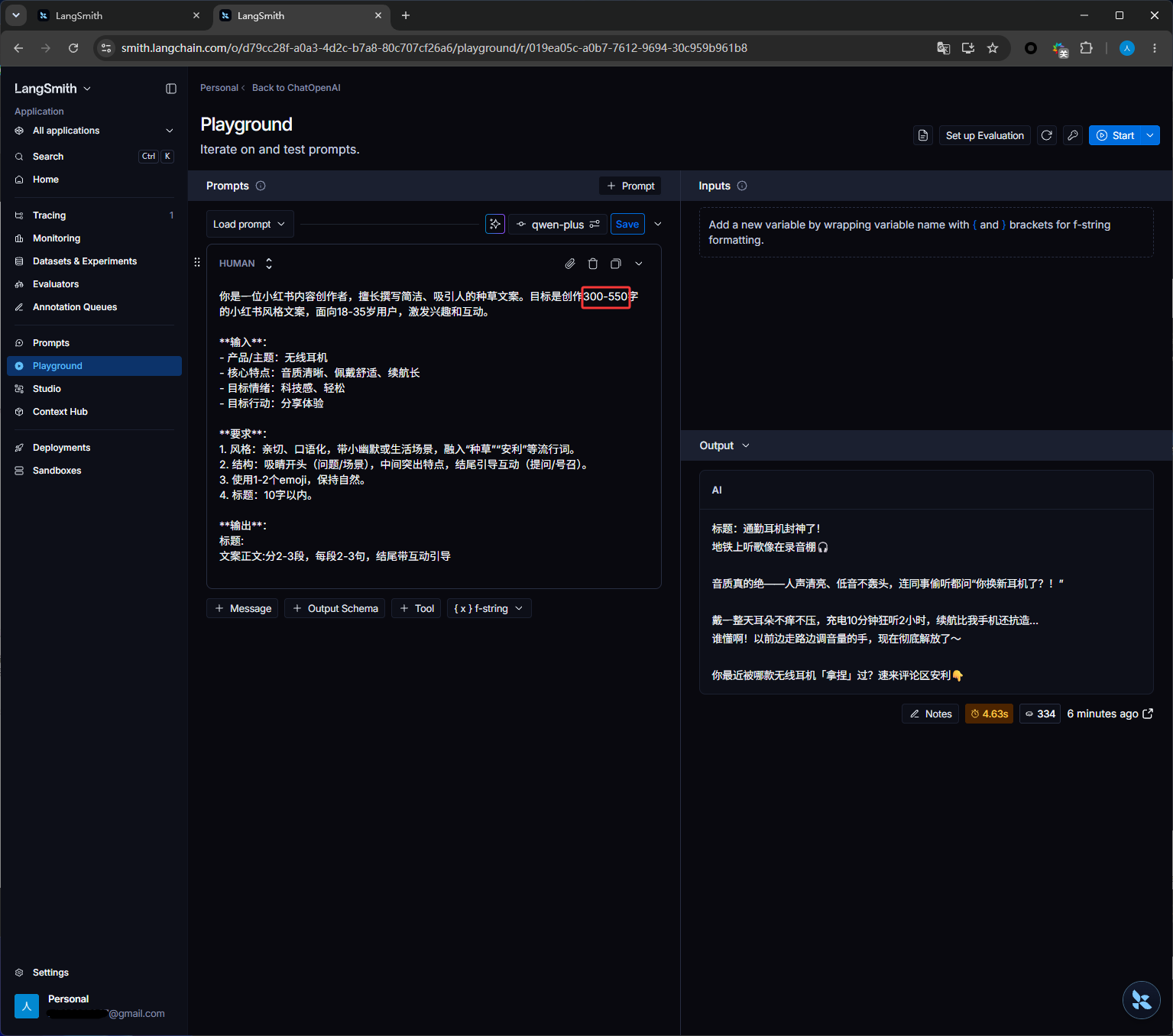
点击下图红框可以修改模型
点击下图红框
输入在大模型平台申请的apiKey
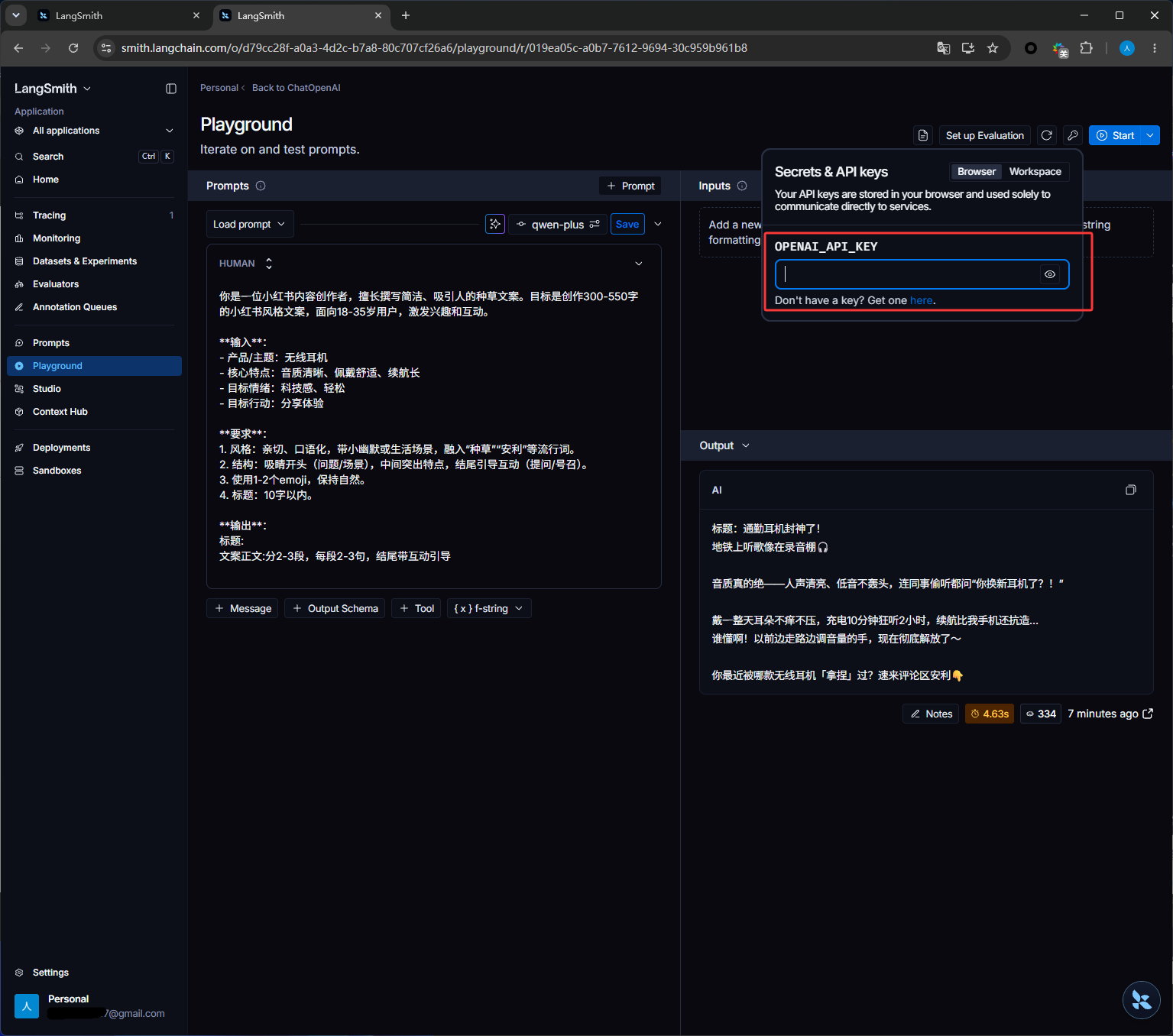
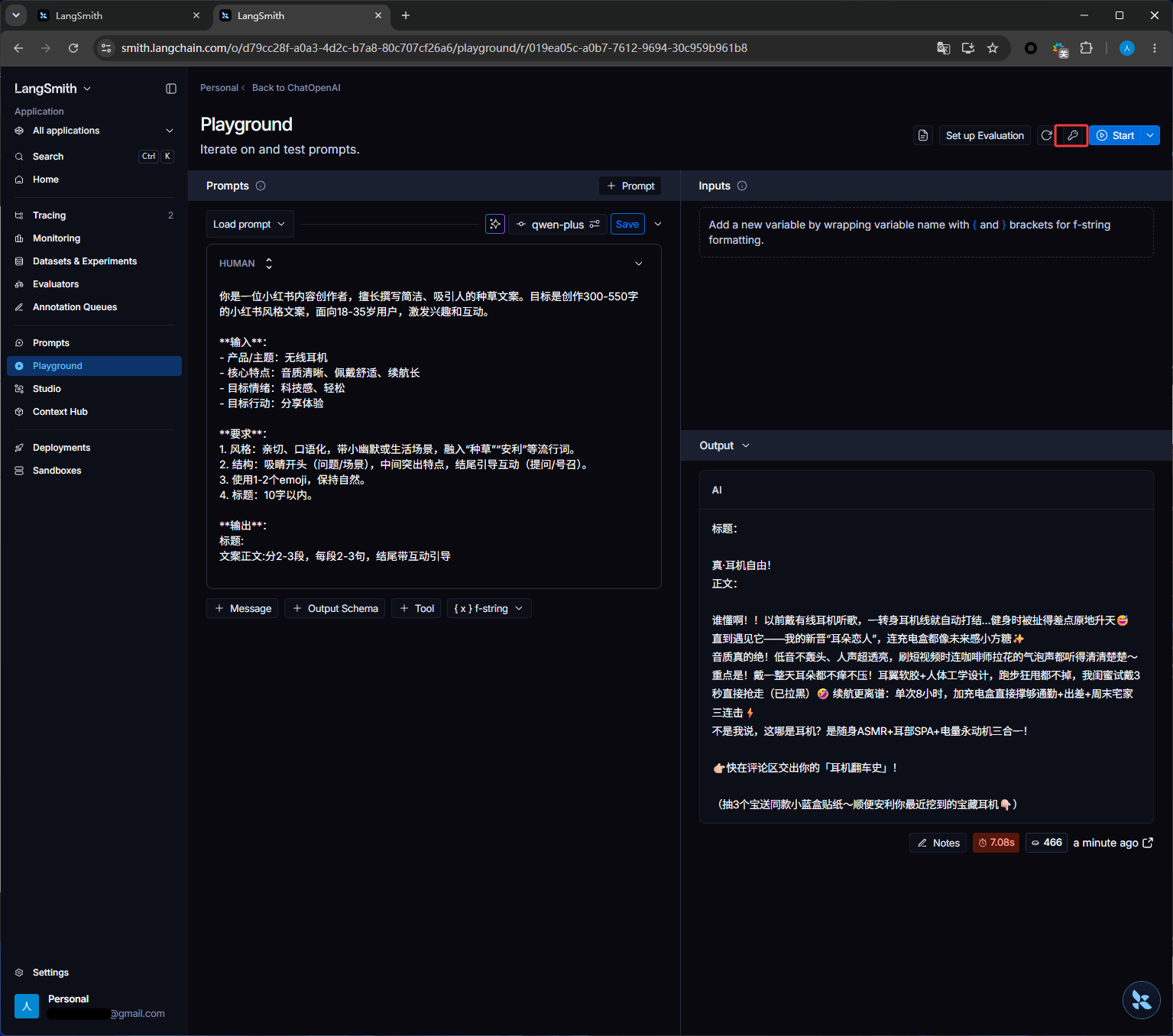
点击下图红框运行
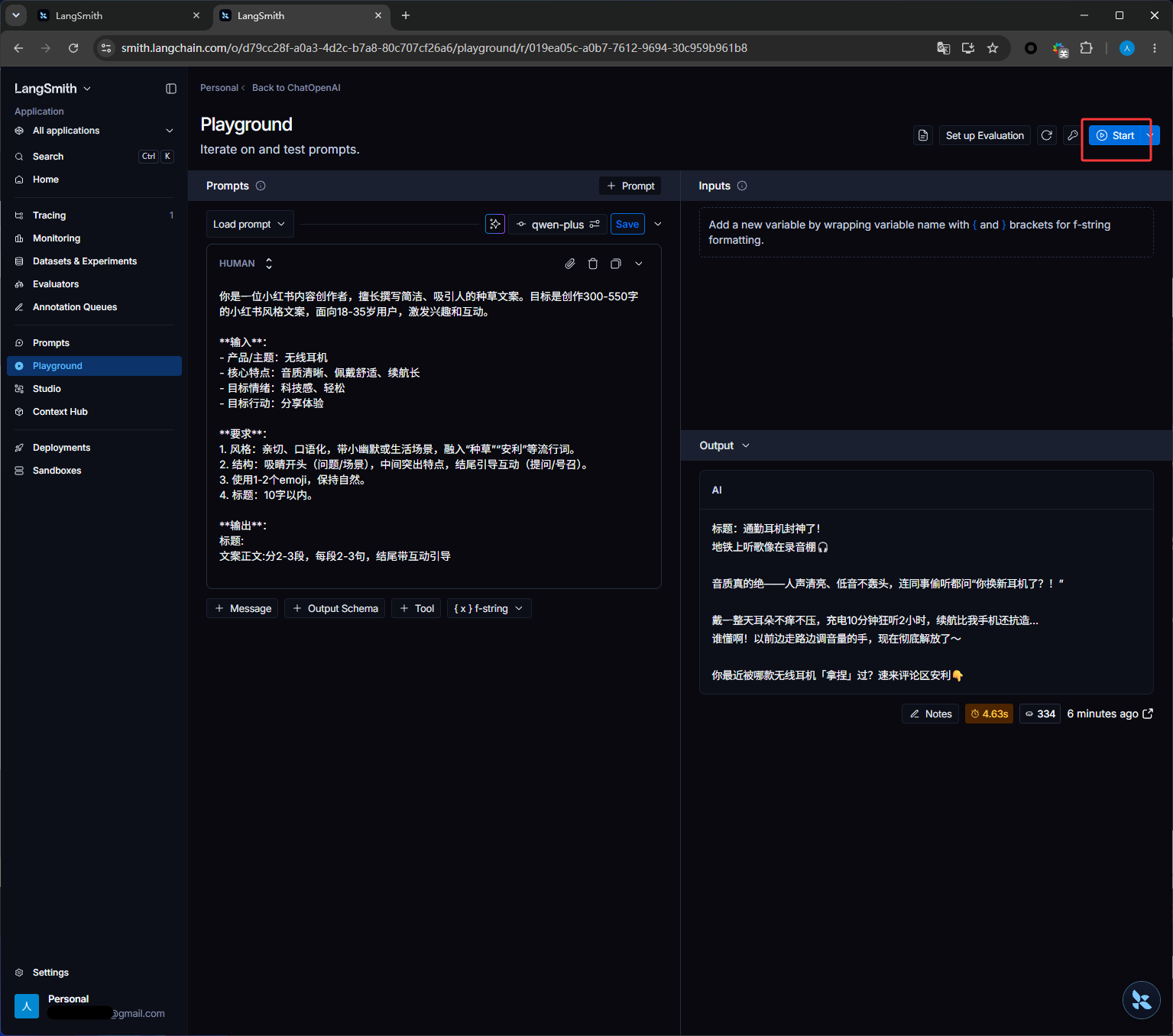
运行之后
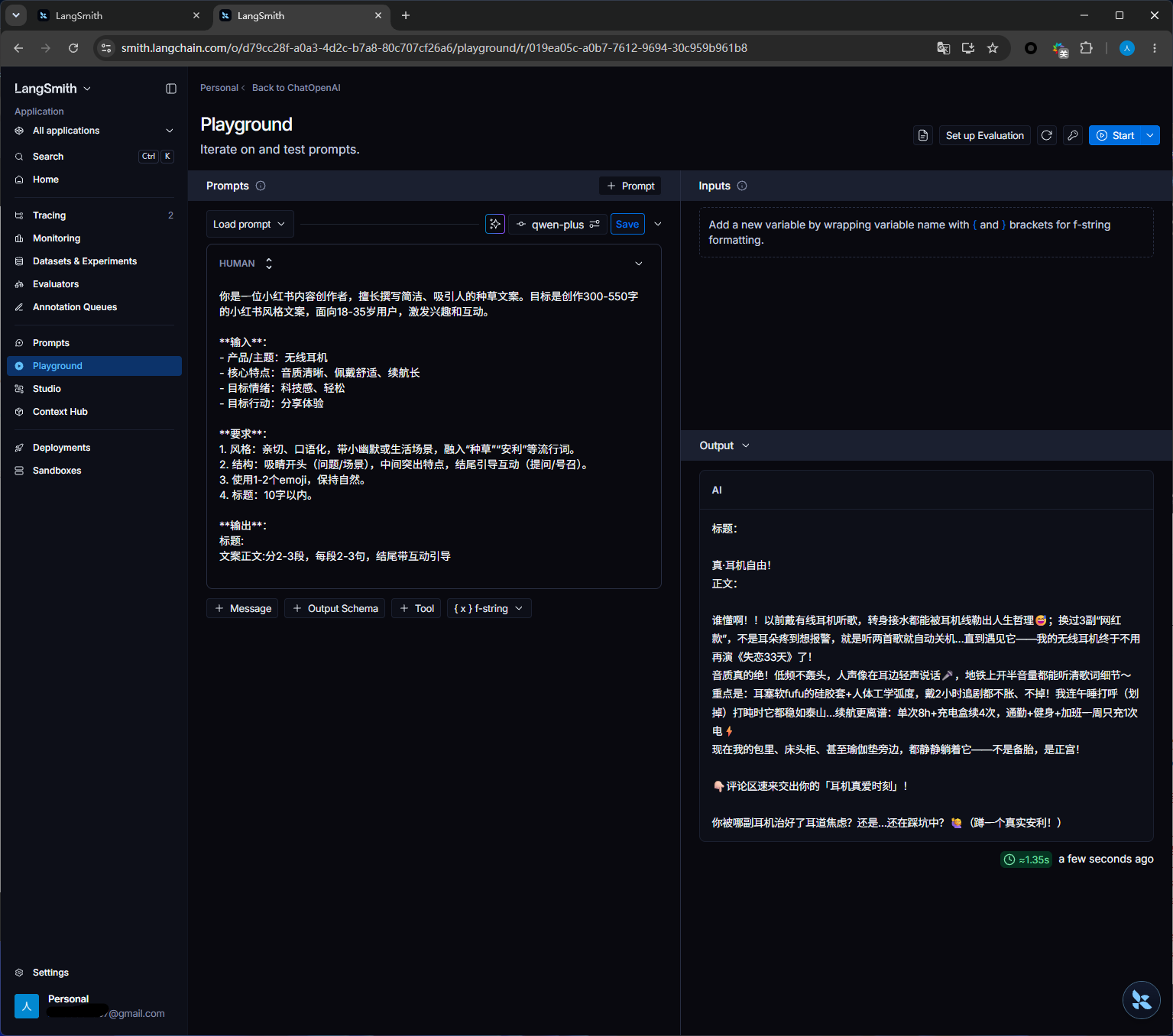
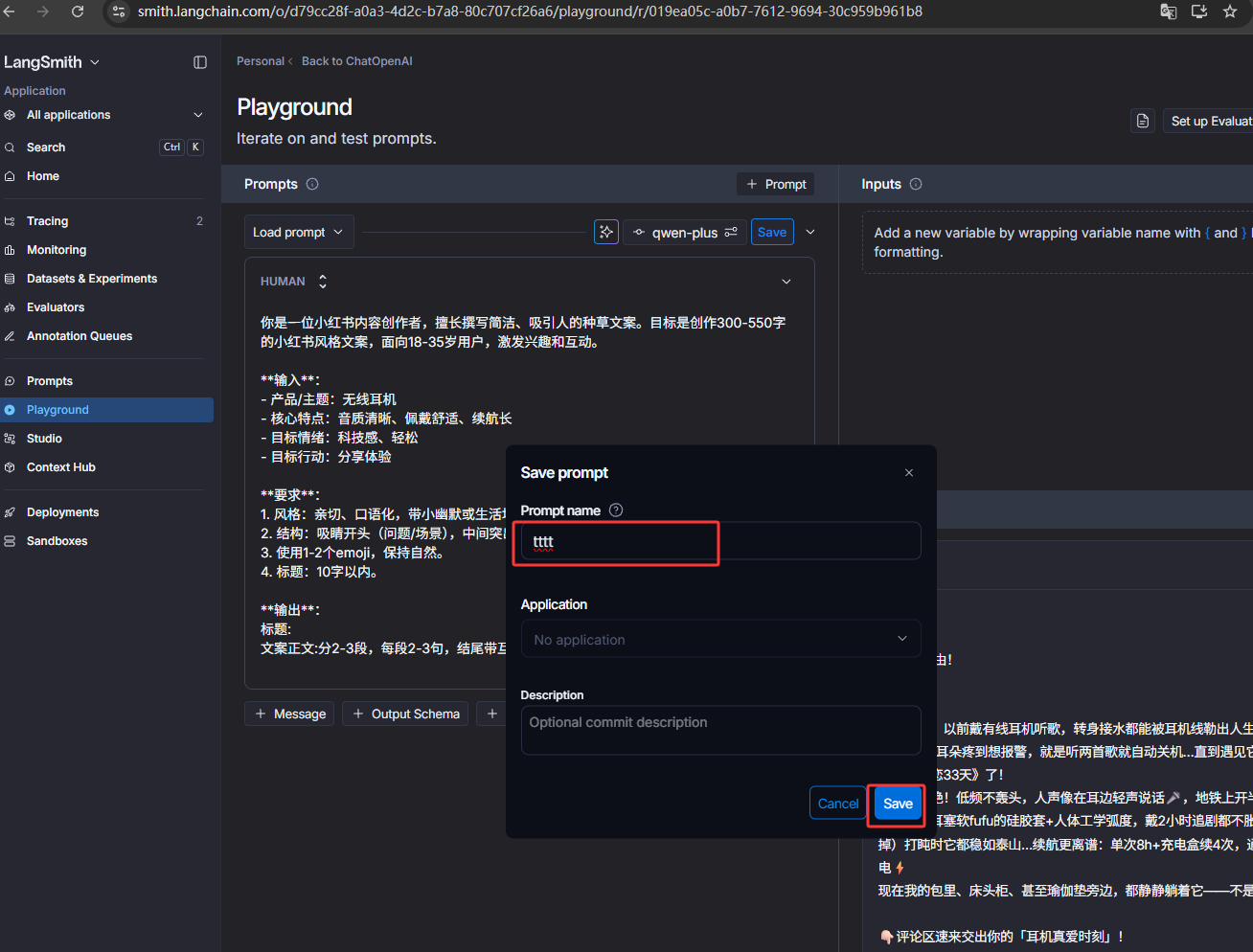
from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from dotenv import load_dotenv load_dotenv() import os # 定义小红书文案提示词 prompt = PromptTemplate.from_template(""" 你是一位小红书内容创作者,擅长撰写简洁、吸引人的种草文案。目标是创作100-150字的小红书风格文案,面向18-35岁用户,激发兴趣和互动。 **输入**: - 产品/主题:{product} - 核心特点:{features} - 目标情绪:{emotion} - 目标行动:{action} **要求**: 1. 风格:亲切、口语化,带小幽默或生活场景,融入“种草”“安利”等流行词。 2. 结构:吸睛开头(问题/场景),中间突出特点,结尾引导互动(提问/号召)。 3. 使用1-2个emoji,保持自然。 4. 标题:10字以内。 **输出**: 标题: 文案正文:分2-3段,每段2-3句,结尾带互动引导 """) llm = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容端点 model="qwen-plus" # 使用qwen-turbo模型 ) # 创建 LangChain 链 chain = prompt | llm # 输入示例 input_data = { "product": "无线耳机", "features": "音质清晰、佩戴舒适、续航长", "emotion": "科技感、轻松", "action": "分享体验" } response = chain.invoke(input_data) # 输出生成的小红书文案 print(response.content)点击下图红框可以保存提示词
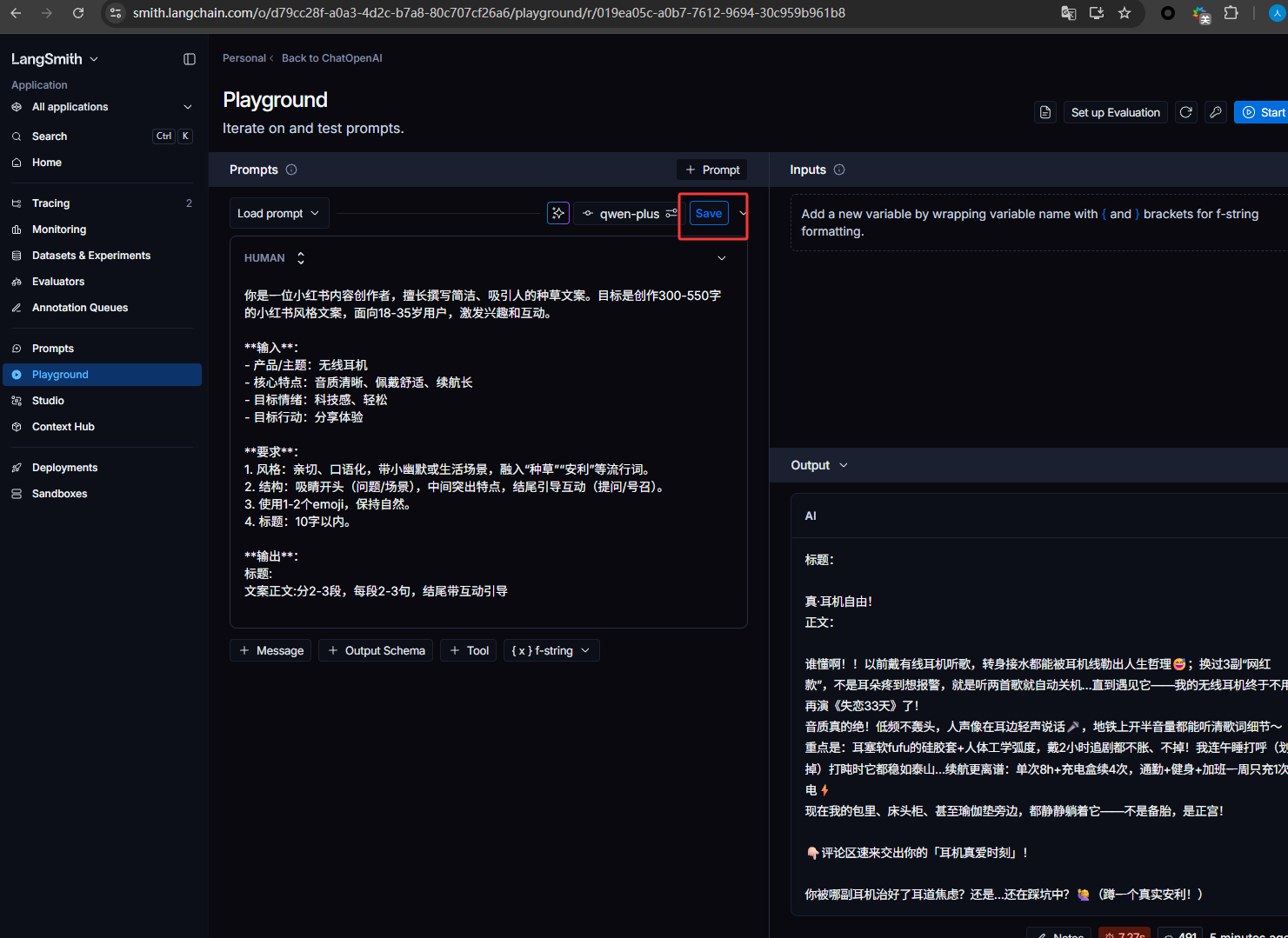
输入一个名字,然后点击Save保存
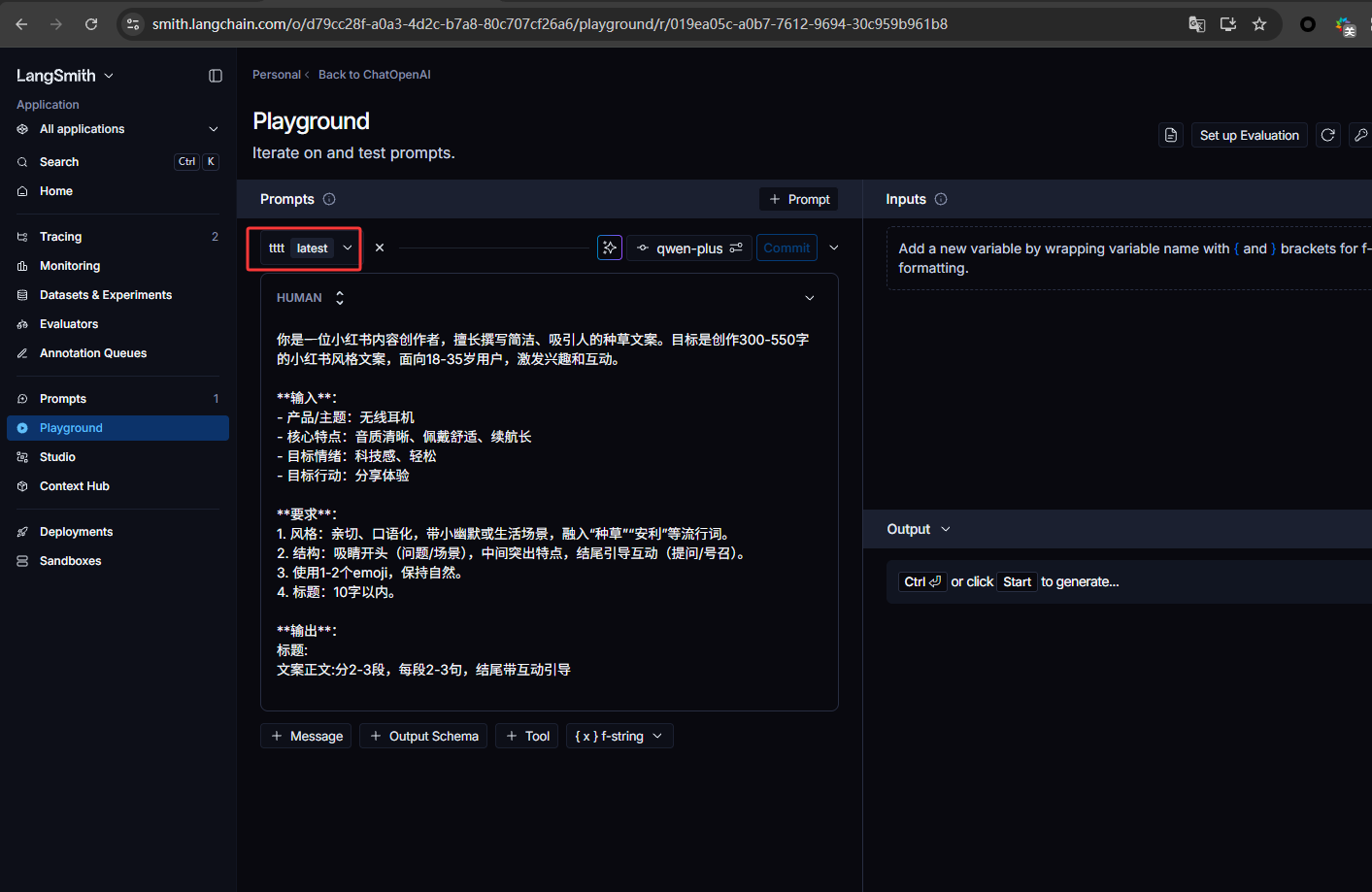
在下图红框位置就可以选择保存过的提示词
在代码中也可以使用,如下图效果图
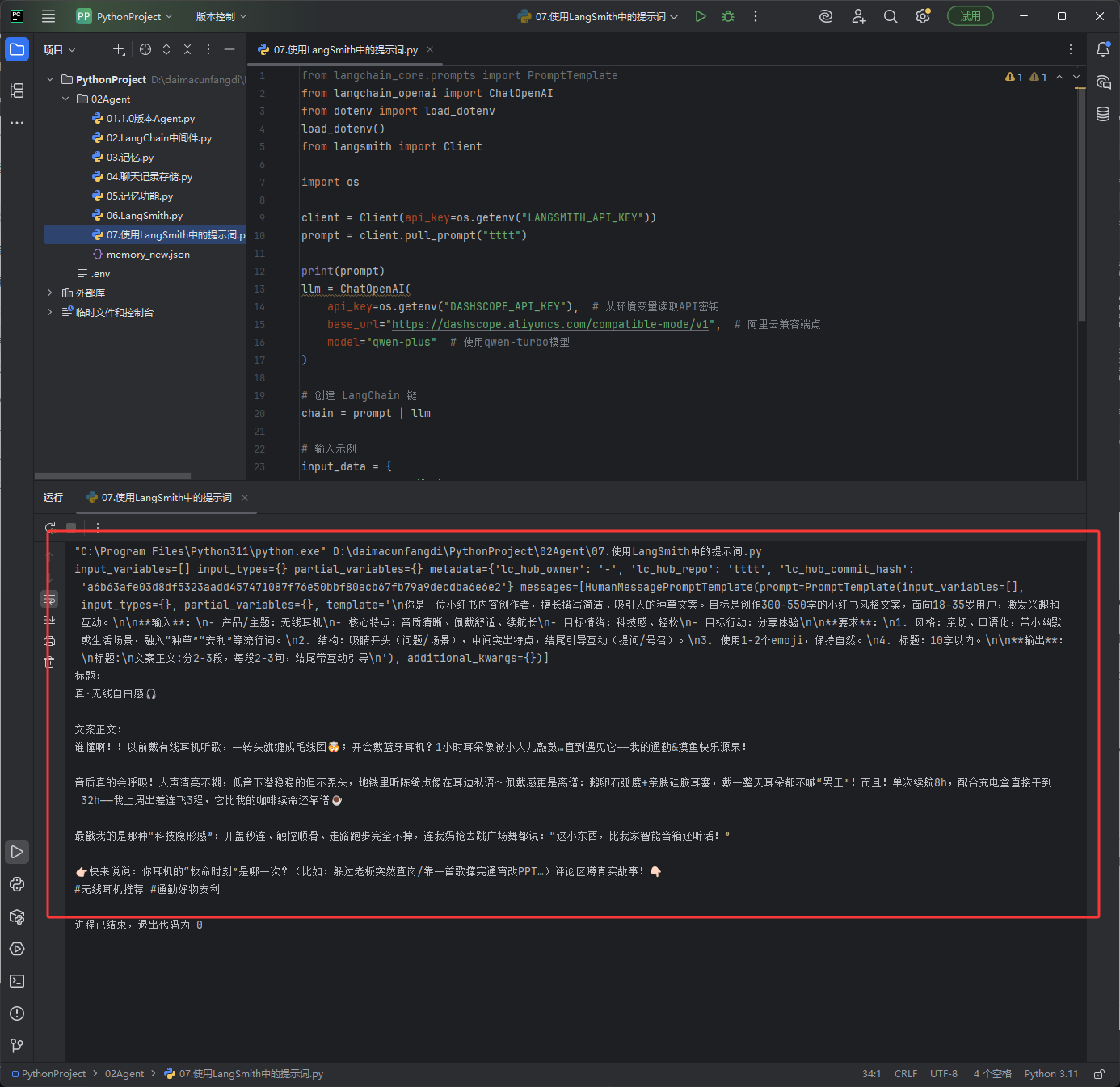
from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from dotenv import load_dotenv load_dotenv() from langsmith import Client import os client = Client(api_key=os.getenv("LANGSMITH_API_KEY")) prompt = client.pull_prompt("tttt") print(prompt) llm = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容端点 model="qwen-plus" # 使用qwen-turbo模型 ) # 创建 LangChain 链 chain = prompt | llm # 输入示例 input_data = { "product": "无线耳机", "features": "音质清晰、佩戴舒适、续航长", "emotion": "科技感、轻松", "action": "分享体验" } response = chain.invoke(input_data) # 输出生成的小红书文案 print(response.content)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 32
32 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)