Cosmos 3:面向物理 AI 的全模态世界模型
26年6月来自Nvidia的论文“Cosmos 3: Omnimodal World Models for Physical AI”。
Cosmos 3,是一系列全模态(omnimodal)世界模型,旨在利用统一的混合 Transformer(mixture-of-transformers)架构,协同处理并生成语言、图像、视频、音频及动作序列。通过支持高度灵活的输入输出配置,Cosmos 3 无缝整合物理人工智能(Physical AI)的关键模态,将视觉-语言模型、视频生成器、世界模拟器及世界-动作模型(WAM)有效地统一于单一框架之中。评估结果显示,Cosmos 3 证明了全模态世界模型可作为具身智体(embodied agents)可扩展的通用基础架构。经后训练的 Cosmos 3 模型已被 Artificial Analysis 评为最佳开源文生图(Text-to-Image)及图生视频(Image-to-Video)模型,并被 RoboArena 评为最佳策略模型。在 Linux 基金会的 OpenMDW-1.1 许可协议下,其公开发布代码、模型检查点(checkpoints)、精选合成数据集及评估基准在 github.com/nvidia/cosmos 和 huggingface.co/collections/nvidia/cosmos3。
Cosmos 3,是一系列全模态世界模型,旨在联合建模语言、图像、视频、音频和动作,以同时实现理解与生成功能。作为物理人工智能(Physical AI)的通用主干,Cosmos 3 将多种截然不同的模型类别统一到单一框架之中(如图 1)。根据输入输出配置的不同,Cosmos 3 能够在多种运行模式间无缝切换:既可作为用于多模态理解与推理的视觉-语言模型;也可作为文本到图像生成器、视频生成器(支持文本生成视频、图像动画化/图生视频、未来预测/视频生成视频以及音视频同步生成);还能作为用于联合动作预测和环境模拟的世界-动作模型。通过在无需修改架构的前提下统一感知、模拟与执行,Cosmos 3 消除对碎片化、特定任务流水线的依赖,并利用共享表征和联合多任务监督实现了可扩展的学习。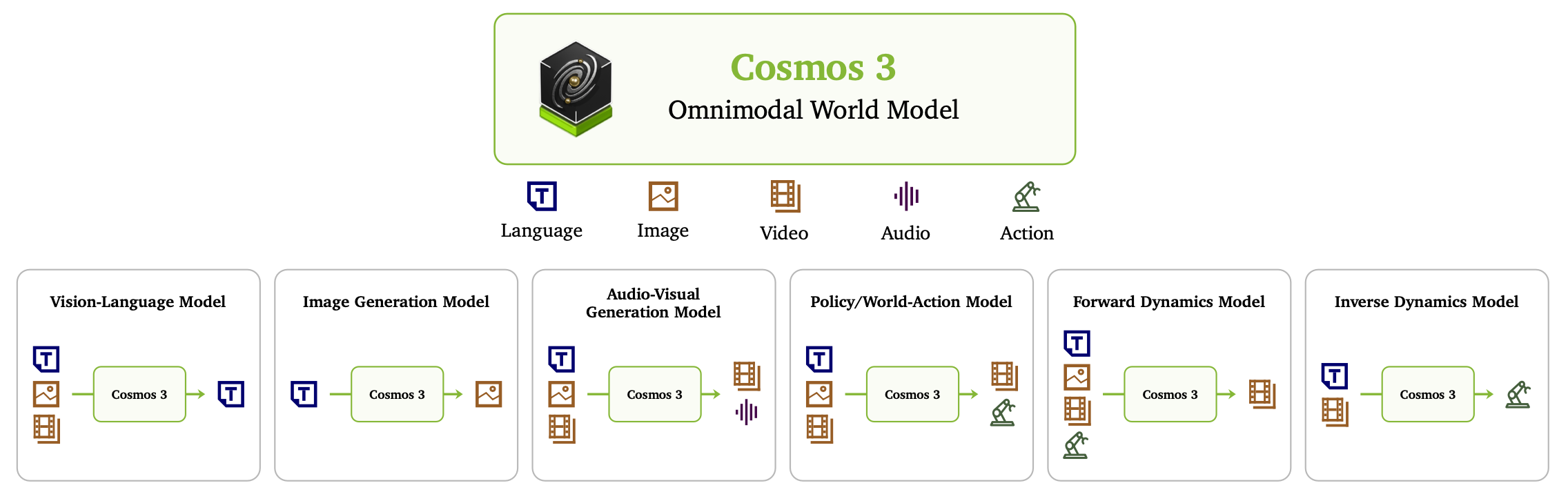
扩展物理AI智体的训练数据与环境,始终是一个亟待解决的瓶颈问题。Cosmos 3 为应对这一挑战提供一个强有力的起点,具体涵盖三个方面:(i) 合成数据生成,(ii) 针对特定任务的专业化,以及 (iii) 训练环境构建(见图2)。在短期内,Cosmos 3 能够生成高保真且多样化的视觉数据,从而增强物理AI智体的训练效果。通过后训练(post-training)将 Cosmos 3 转化为更出色的合成数据生成器。鉴于智体通过各种不同的具身形态(embodiments)和任务来感知环境并与之交互,Cosmos 3 支持在共享模型的基础上,针对特定任务和具身形态进行专业化适配。作为一种强大的物理AI中间训练模型(mid-training model),Cosmos 3 通过建模通用的世界动态和动作先验,确立更优的起点,同时保持极佳的下游适配能力。在实际应用中,该模型无需修改架构,即可利用目标数据进行后训练以适应不同场景;得益于其全模态(omnimodal)设计,这种数据驱动的专业化过程既能实现特定领域的优化,又能保留通用的世界表征。在 DROID 数据集上对 Cosmos 3 进行后训练,使其成为一个能力强大的世界-动作模型(world-action model)。从长远来看,Cosmos 3 旨在为物理AI智体生成高质量、复杂的训练环境。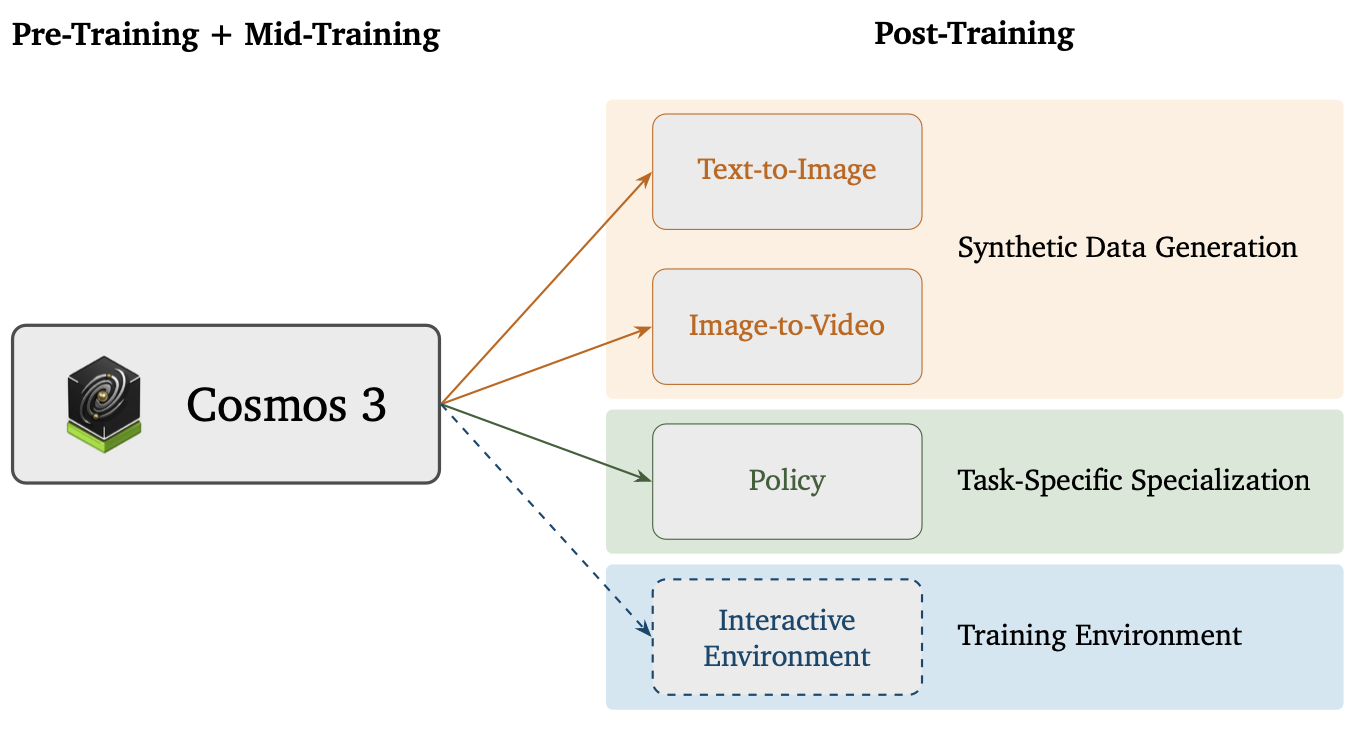
1. 编码器
针对语言、视觉、音频和动作构成的输入序列,第一步是利用模态特定的编码器将其映射到统一的表征空间。为了使共享的 Transformer 参数和位置编码能够区分不同模态,在将非语言模态数据输入 MoT 主干网络之前,会为每种非语言模态添加一个可学习的、模态特定的嵌入向量。
如图3所示统一动作表示。将异构的具身控制映射为由共享几何组件构成的紧凑动作向量。主体(ego)与末端执行器(effector)的运动利用 3D 平移和 6D 旋转(一种由 Zhou [2019] 提出的过参数化旋转表示,旨在涵盖 3 自由度旋转)被编码为相对位姿伪动作;与此同时,抓取状态则直接编码当前的操控状态,例如手部的指尖位置或机器人的夹爪开合数值。具备域感知能力的输入与输出投影机制在处理异构动作向量长度的同时,能够保持共享语义空间的一致性。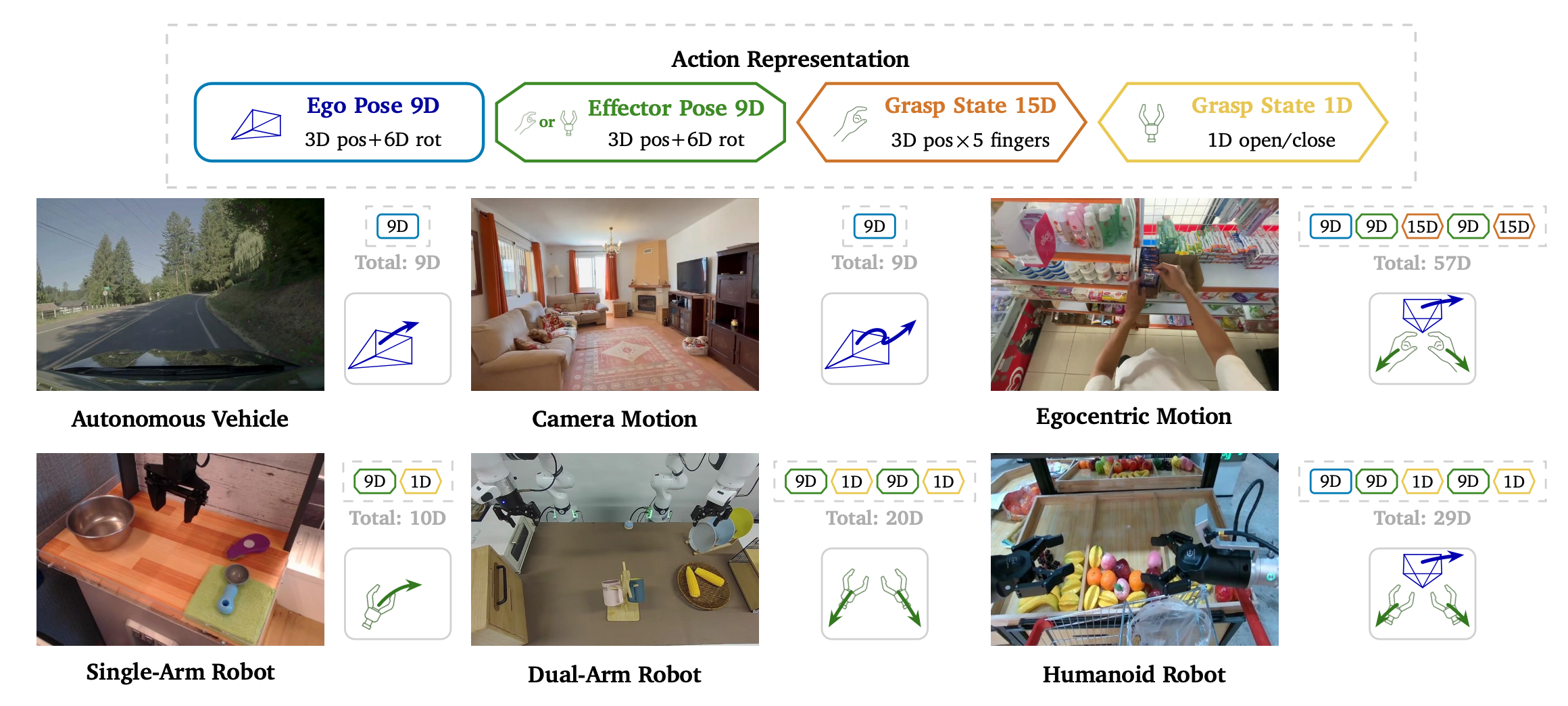
动作表征将各种不同的具身形态(embodiments)映射到一个共享的潜动作空间,同时保留各具身形态特有的结构与语义。因此,针对每个具身形态域使用具备域感知能力的输入与输出投影层(各域采用独立的权重矩阵,参见 Zheng et al., 2026),同时共享 MoT 主干网络。
对于输入 x ∈ R,例如由头部姿态变化量、左右手腕姿态变化量和指尖坐标拼接而成的以自我为中心动作向量,以及域标识符 𝑘 ∈ {1, …, 𝐾},输入投影为x和偏差b_in的组合:z。
为了将token解码回原始动作空间,用特定于域的输出投影,即z和偏差b_out的组合:x。
所有投影参数均从头开始初始化,并与 MoT 主干网络联合优化。用奇异值分解 (SVD) 将预测的 6D 旋转转换回 3 × 3 SO(3) 旋转矩阵。
2. Token 排列与生成模式
Cosmos 3 是一个支持多种模态与任务的统一模型。各类任务均可表述为交错的多模态序列,其中每个序列由来自不同模态的一系列片段构成。针对特定任务,所有片段首先利用前述的模态专用编码器被编码为嵌入(embeddings);完成嵌入后,来自不同模态的 Token 将按照一种适用于所有任务的统一格式进行打包。
Cosmos 3 支持多种模态:语言、视觉、音频和动作。
Cosmos 3 支持三种动作生成模式:正向动力学(forward dynamics)、逆向动力学(inverse dynamics)以及联合视频-动作预测(即策略模式,policy)。对于包含连续视频 token 的轨迹,每个动作 token a_t 表示从 v_t-1 到 v_t 的状态转移。正向动力学模式基于观测到的上下文和清晰的动作 token 预测未来的视觉状态;逆向动力学模式则推断出能够解释观测视觉状态转移的动作 token。在策略模式下,模型联合预测动作 token 和视频 token,从而能够在同一个序列模型中同时生成干预动作及其预期的视觉后果。各种条件生成方向总结于图 4 中。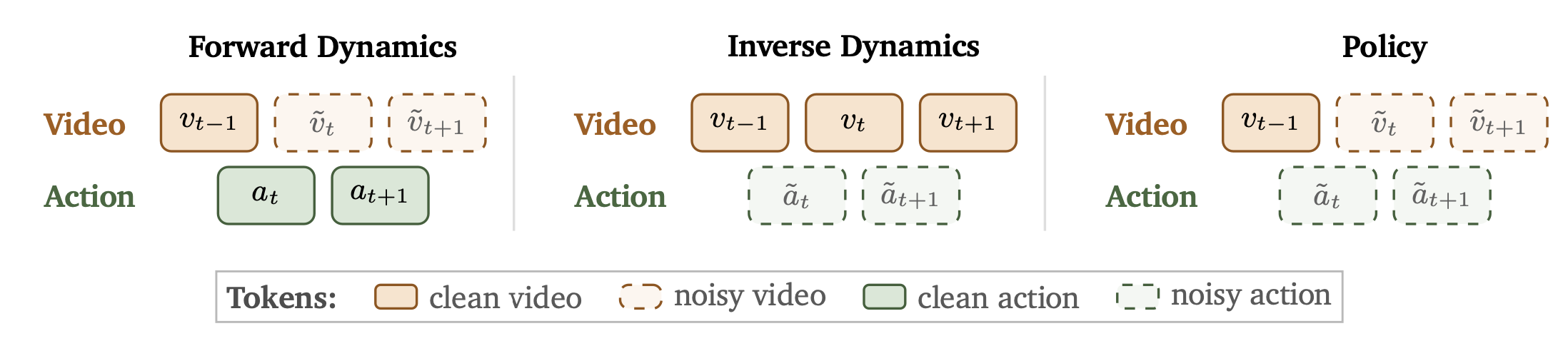
3. Mixture-of-Transformers (MoT) 架构
Cosmos 3 采用 Mixture-of-Transformers (MoT) 架构,用于处理来自不同模态的统一 Token 序列。在层级结构上,每个 Transformer 解码器层包含两组参数:一组用于推理任务(处理来自自回归/AR 子序列的 Token,即“推理器”),另一组用于生成任务(处理来自扩散/diffusion 子序列的 Token,即“生成器”)。尽管 Cosmos 3 在解码器层结构上与 De(2025) 提出的统一生成模型有相似之处,但在训练策略、位置编码以及整体能力方面则存在差异。
双塔层结构
标准的 Transformer 解码器层由自注意操作、前馈网络和若干归一化层组成。MoT 设计并未采用同一组参数来处理所有类型的 Token,而是如图 5 所示,使用两条处理路径。每条路径都是一个标准的 Transformer 层,拥有各自独立的参数,包括层归一化模块、注意投影矩阵和前馈网络。这两条路径均基于预训练视觉-语言模型(VLM)的权重进行初始化,使 Cosmos 3 既能继承强大的语言与视觉推理能力,又能学习生成高保真视频。在训练和推理过程中,位于前部的自回归(AR)子序列被路由至“推理塔”(reasoner tower),而位于后部的扩散(diffusion)子序列则被路由至“生成塔”(generator tower)。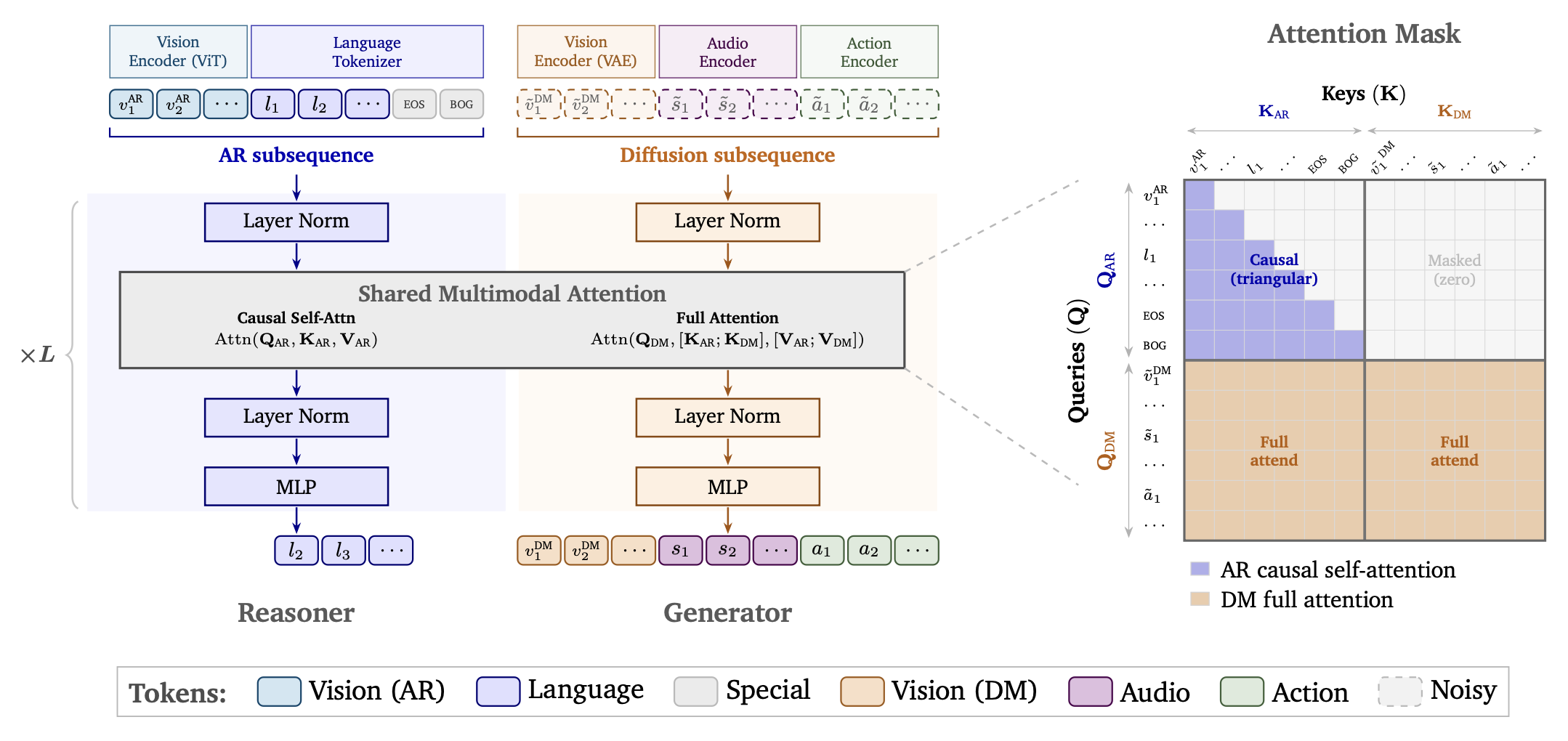
双流联合注意机制
尽管这两个分支(tower)使用独立的参数,但来自扩散子序列的 Token 会通过双流联合注意操作与自回归(AR)子序列进行交互。
4. 多模态位置编码
位置编码将时空结构引入注意机制,促使 Token 更多地关注在语义和几何上相关(通常在空间或时间上邻近)的 Token。由于 Cosmos 3 在统一的注意框架内联合建模语言、视觉、音频和动作 Token,因此设计一种能跨模态保持一致性的通用位置编码方案极具挑战性。
受 3D 多模态 RoPE (MRoPE)(Bai,2025a)的启发,设计一种具有绝对时间索引功能的 3D MRoPE,旨在将视频、音频和动作 Token 对齐到同一物理时间轴上。原始的 3D MRoPE 将每个注意头的隐维度划分为时间、高度和宽度分量,其中时间分量仅记录离散的 Token 索引。这种设计虽足以应对图像和视频理解任务,却无法满足需求,因为在场景中,视频、音频和动作 Token 可能会以不同的帧率或采样率同时生成。在这种情况下,必须将来自不同模态的 Token 对齐到绝对物理时间轴上。首先介绍遵循原始 3D MRoPE 设计的基础公式,随后阐述扩展与改进,特别是用于对齐绝对时间轴的“绝对时间调制”机制。
位置索引分配
自回归(Autoregressive)Token。为了保持与语言生成及图像/视频理解模型的向后兼容性,自回归子序列中所有语言 Token 和经 ViT 编码的媒体 Token 的位置索引均遵循原有的 3D MRoPE 设计。对于语言 Token,其 t、h 和 w 索引被设定为相同的单调递增值,从而使 3D MRoPE 退化为标准的 1D RoPE 形式。对于来自 ViT 编码器的 Token,同一帧内的所有 Token 共享同一个 t 索引,而 h 和 w 索引则根据各 Token 的空间位置独立变化。该自回归子序列中的位置索引分配方式与 Qwen3-VL(Bai et al., 2025a)中的 3D MRoPE 设计完全一致。
扩散token。如图6所示,视频 Token 在三个维度上均有变化:t 随时间维度潜在帧索引的增加而递增,而 h 和 w 则在空间网格(0. . .H-1,0. . .W-1)上分布,且在每一帧内独立变化。图像 Token 被视为单帧视频,仅在 (h, w) 维度上变化。空间和时间索引在每个视觉片段开始时均重置为零,因此模型将 t、h 和 w 视为视频内部的绝对坐标,而非全局序列中的位置。例如,在视频迁移任务中(用户同时提供文本提示和诸如深度图之类的受控视频帧),干净的控制视频 Token 和带有噪声的生成视频 Token,其起始时间偏移量均紧接在自回归子序列中最后一个 Token 之后。所有音频 Token 和动作 Token 仅包含时间坐标,其空间索引均设为零(h = w = 0)。对于音频 Token,时间索引随每个音频跳跃步长(hop)递增;对于动作 Token,时间索引则随每个采样步长递增。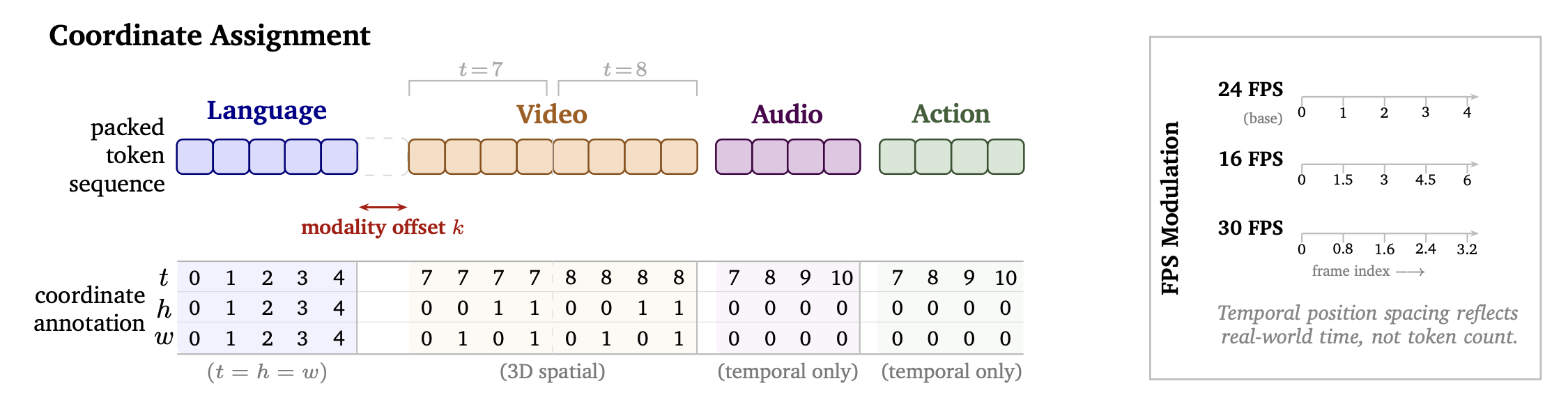
自回归与扩散 Token 之间的间隔。在实践中,如果直接让扩散 Token 紧接在最后一个自回归 Token 的时间偏移之后,会导致视频初始帧出现过饱和现象及棋盘格伪影。这种效应在 Cosmos 3 的大型变体(如 Super 模型)中尤为明显。这是因为最后一个语言 Token 与第一帧的视觉 Token 占据了相邻的时间位置,从而产生了几乎相同的时间嵌入(temporal embeddings)。为了解决这一问题,受 Cao(2025)的启发,在自回归子序列和扩散子序列之间插入一个固定的时间间隔,并将后续所有视觉、音频及动作 Token 的时间索引统一向后平移。这种做法在位置空间中创建一个缓冲区域,从而提供更清晰的“文本-到-视觉”转换信号,且无需更改模型架构或引入额外的可学习嵌入。在所有的模型中,该间隔均设定为 15000。
绝对时间调制
在时间维度上移动一个单位步长,在不同模态或数据源之间可能对应着不同的物理时间间隔。例如,在分别以 60 FPS 和 24 FPS 编码视频时,24 FPS 视频 Token 的时间索引增量所对应的物理时间间隔,是 60 FPS 视频 Token 对应间隔的 2.5 倍。动作 Token 和音频 Token 也存在类似差异,因为不同的数据源可能采用不同的采样率。FPS 调制旨在通过调节每个时间增量的有效大小,将具有不同时间分辨率的 Token 对齐到统一的物理时间轴上。
5. 模型变体
Cosmos 3 包含三种不同规模的模型:Edge、Nano 和 Super,涵盖从端侧部署到大型数据中心推理的广泛计算资源需求。Edge 是一个拥有 40 亿(4B)参数的模型,基于 20 亿(2B)参数的稠密(dense)Transformer 构建;Nano 是一个拥有 160 亿(16B)参数的模型,基于 80 亿(8B)参数的稠密 Transformer 构建;Super 是一个拥有 640 亿(64B)参数的模型,基于 320 亿(32B)参数的稠密 Transformer 构建。所有变体均基于预训练的视觉-语言模型(VLM)进行初始化,并采用前文所述的 Transformer 混合(MoT)架构。本文发布 Cosmos3-Nano 和 Cosmos3-Super 模型,Cosmos3-Edge 模型将在后续版本中发布。
训练 Cosmos 3 需要针对两个互补目标的数据:推理器(Reasoner)路径学习理解世界并进行推理,而生成器(Generator)路径则学习合成与模拟世界,或在其中采取行动。尽管两条路径共享相同的 Transformer 架构和 Token 表示,但它们依赖于不同类型的训练数据。推理器使用成对的视觉-语言数据(如图像-文本和视频-文本对)进行训练,以支持问答、空间定位、时序推理和动作理解等任务。相比之下,生成器利用包含图像、视频、音频和动作的大规模多模态语料库进行训练,采用基于重构的目标而非显式标注。
因此,这两条路径遵循不同但互补的训练课程。两者均采用多阶段训练策略,其中数据构成随时间推移而演变。推理器首先进行广泛的视觉-语言预训练,随后通过针对机器人、自动驾驶和空间智能等物理 AI 任务的监督微调进行专业化训练。这种分阶段的课程安排先建立强大的通用能力,再逐步引入更专业的领域知识。生成器则从大规模图像、视频和音频预训练开始,随后逐步整合动作、控制条件迁移及针对性合成数据等额外模态,以提升特定能力。
1. 推理器数据
推理器数据课程包含约 2420 万个样本:2200 万个用于预训练,220 万个用于监督微调(数据源自特定领域的物理 AI 数据集及合成数据)。预训练阶段以图像-文本和纯文本数据为主,旨在提供广泛的通用视觉理解能力。相比之下,监督微调阶段转向物理 AI 的专业化应用,其中视频-文本样本占混合数据的 50%,以增强时空理解能力,并提升在机器人、智能基础设施及自动驾驶领域的表现。如图 7 按能力类别总结这两个阶段的数据构成。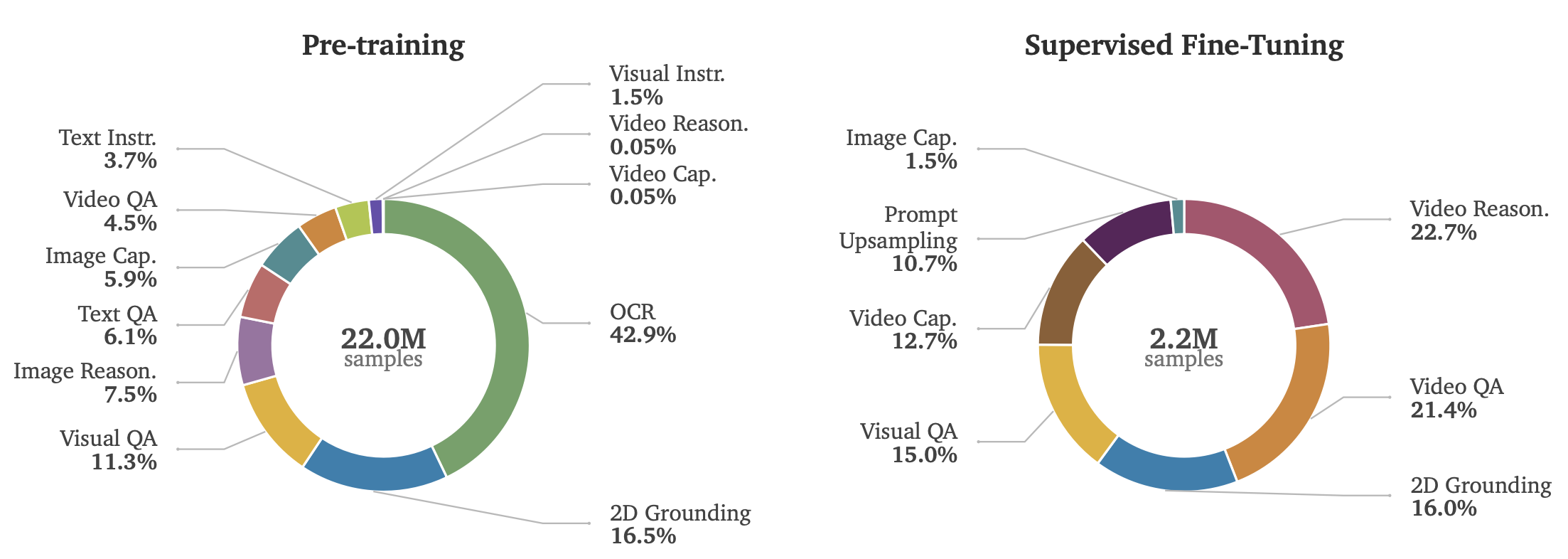
2. 生成器数据
生成器培训遵循渐进式多阶段课程,在培训过程中逐步引入新模式,从预培训期间的图像、视频和音频开始,然后在培训中期纳入动作和交错的多模式内容。 Cosmos 3 被定位为各种物理人工智能应用的良好起点。为了展示其功能,采用中间训练的检查点 Cosmos3-Nano 和 Cosmos3-Super 并对它们进行后训练,以使用专门的后训练数据集(包括 Cosmos3-Super-Text2Image、Cosmos3-Super-Image2Video 和 Cosmos3-Nano-Policy-DROID)产生领域专家。这些模型与其相应的中间训练模型共享相同的架构。图 8 总结了跨模式和阶段的生成器培训课程。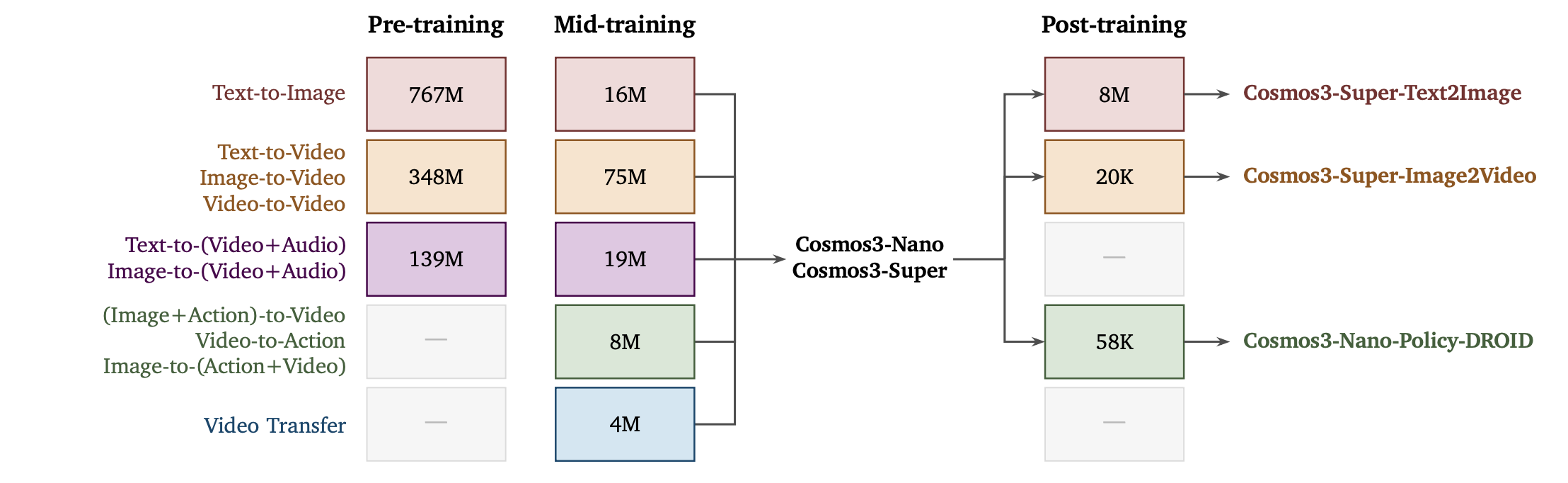
“动作”提供连接不同时间点所观测的世界状态因果变量。尽管仅基于视频的训练能让生成器学会推断可能的运动,但它无法让模型接触到可控的干预操作:同样的初始观测状态,在不同的机器人指令、摄像机轨迹、车辆行驶路线或人类手部动作下,可能会演化出截然不同的结果。因此,在训练中途引入“文本-视频-动作”配对数据,使 Cosmos 3 能够学习世界状态与动作之间双向的关联关系:即根据动作预测未来的观测状态、推断导致观测轨迹的动作,以及联合生成动作与未来视频。
在训练过程中重点关注物理人工智能(Physical-AI)的四大支柱领域:以自我为中心的运动、机器人技术、自动驾驶以及相机运动。如图9所示,最终筛选出的数据集涵盖这些领域,包含840万个片段,总时长达6.13万小时。
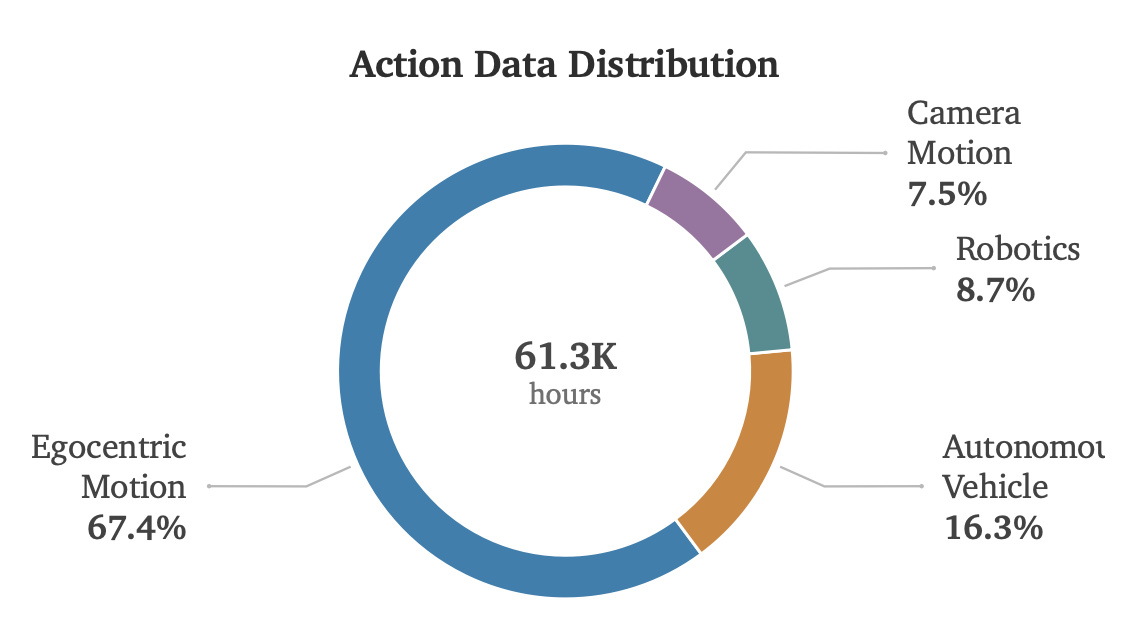
利用统一动作token化(unified action tokenization)方法对每个数据源进行转换。为在转换后平衡不同具身(embodiments)之间的动作幅度,根据训练数据计算各维度的归一化参数,并将动作通道缩放至大致 [−1, 1] 的可比范围内。对于包含多个同步视角的数据,将各视角拼接成一个画布(canvas),并将相机布局信息存储在元数据中(如图 29 所示)。并未剔除空闲操作,而是将其保留并在元数据中记录空闲步骤的数量,从而支持下游采样过程显式地平衡活跃片段与非活跃片段。

分两个主要阶段训练 Cosmos 3。首先,Reasoner 在大规模图像文本和视频文本语料库上进行预训练,随后在精心策划的物理 AI 混合体上进行微调,为视觉理解和推理产生强大的多模态骨干。由于 Reasoner 和 Generator 共享相同的 Transformer 块架构,因此训练后的 Reasoner 权重用于初始化 Generator,将语义和世界知识传输到能够合成像素、音频和动作的模型中。Generator 使用渐进式多阶段课程进行培训。它从大规模图像、视频和音频预训练开始,然后是逐渐引入动作和传输数据的中期训练。最后,该模型在较小的、精心策划的物理人工智能数据集上进行后训练,以改善下游行为、物理一致性和动作保真度。
1.推理器训练
Cosmos 3 Reasoner 分两个阶段进行训练:大规模多模式预训练,然后对策划的物理 AI 任务进行监督微调。在预训练期间,模型从大规模图像文本和视频文本语料库中学习通用的多模态表示。然后,有监督的微调将模型专门用于物理人工智能领域,包括机器人、自动驾驶和智能基础设施应用,同时保留在预训练期间获得的广泛功能。
2. 生成器训练
Cosmos 3 生成器采用渐进式多模态课程进行训练,旨在跨越不同的分辨率、时长和条件模态,联合建模视觉、听觉及动作条件下的世界动态。其训练方案强调可扩展性、高保真生成以及高效的长上下文学习能力。在预训练阶段,模型利用涵盖图像、视频和音频的大规模数据学习通用的生成先验知识;随后的训练阶段则逐步引入更丰富的多模态监督信号(包括动作和转换序列),使模型能够学习在时间上连贯的世界演变过程以及符合物理规律的交互行为。
预训练
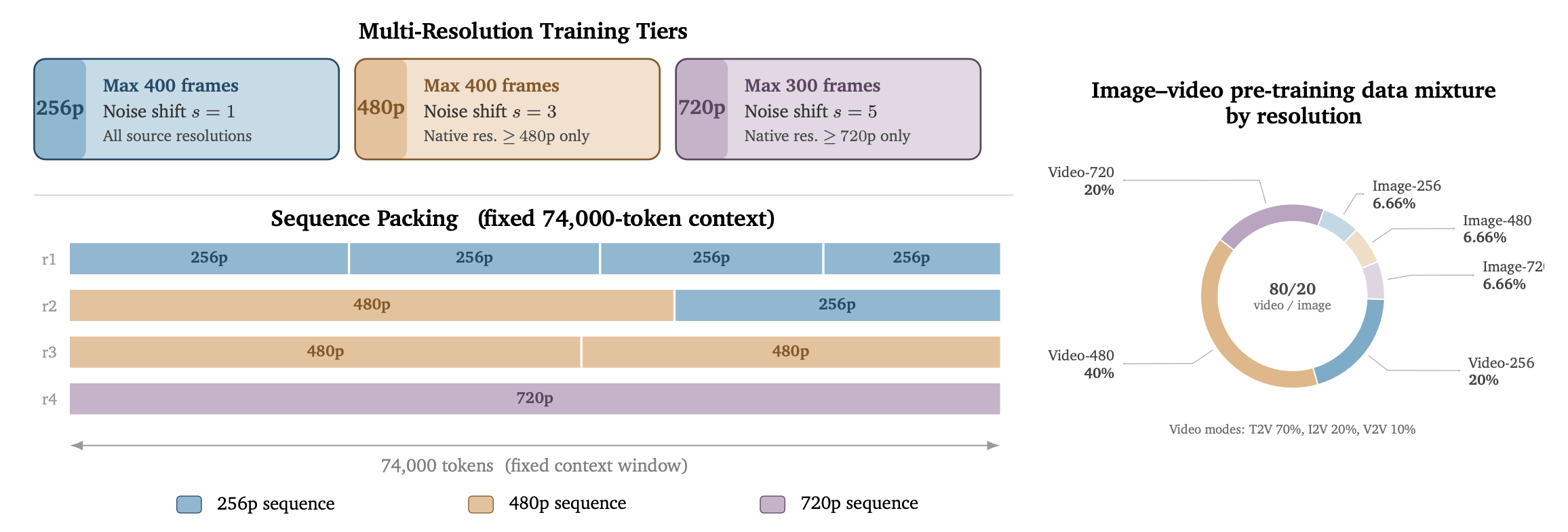
在预训练阶段,联合训练模型,使其能够生成涵盖多种分辨率和任务类型的图像、视频及音频。为此,采用多分辨率训练策略,并针对多种生成任务(包括“文本到图像”、“文本到视频+音频”、“图像到视频+音频”以及“视频到视频+音频”)对模型进行联合优化。
多分辨率训练。并未局限于单一的输出分辨率,而是同时在三个分辨率层级(256p、480p、720p)、五种长宽比以及可变帧数下进行训练。这种做法既让模型接触到高保真内容,又促进了对分辨率不敏感(resolution-agnostic)表征的学习。训练数据按层级划分:256p 数据流使用完整数据集(涵盖所有原始分辨率);480p 数据流仅限于原始分辨率不低于 480p 的素材;720p 数据流仅使用分辨率不低于 720p 的内容,从而在最高层级上保持清晰度和精细细节。每个分辨率层级设定了不同的最大帧数限制:256p 和 480p 层级最高支持 400 帧,720p 层级最高支持 300 帧。受限于序列长度,720p 层级的帧数上限设为 300 帧。训练批次由四个层级的样本按 1:1:2:1 的比例构成,分别对应“仅图像”、“视频-256p”、“视频-480p”和“视频-720p”样本。这种分布在学习高保真内容与保持样本多样性之间实现了良好的平衡,既让模型能够接触更多训练样本,又确保了对高分辨率内容的侧重。采用分辨率自适应的偏移值(shift values):256p 时 s=1,480p 时 s=3,720p 时 s=5。
为了在支持可变序列长度的同时避免不必要的重新编译开销,采用 Token 打包(token packing)技术,并将每个序列的 Token 总量固定为 74,000 个。不同分辨率的序列被组合打包以填满每个批次,从而在无需填充(padding)的情况下最大化 GPU 利用率(如图 10 所示)。
中期训练(Mid-Training)
训练中期阶段连接广泛的预训练与下游部署。此时,生成器已通过大规模数据学习了通用的图像、视频和音频生成能力;然而,目标物理 AI 应用需要模型更充分地涵盖罕见动态、具身场景、控制接口及高质量视觉领域。因此,基于预训练检查点继续训练,采用精心构建的混合数据,既保留原有的视觉生成模式,又引入新的监督信号。该阶段包含两个互补的目标:一是域专业化,即增加模型在具有高价值的物理 AI 领域的训练比重;二是多模态融合,即将模型能力从视觉与音频生成扩展至基于动作和控制条件的“世界建模”。
文生图(Text-to-Image)后训练
为了展示 Cosmos3-Super 的全模态能力,进一步将该模型微调为专用的文生图版本——Cosmos3-Super-Text2Image。目标是将模型对物理世界的深刻理解迁移至高质量图像生成任务中,在实现卓越的开源文生图效果的同时,提升生成图像的物理合理性与场景级一致性。
图生视频(Image-to-Video)后训练
图生视频能力对于实现全面的视觉理解至关重要。它不仅能考察模型对物理定律、物体恒存性及复杂场景几何结构的理解,还是具身智能与机器人规划领域的一项关键预测机制——通过模拟合理的未来帧,可构建出有效的世界模型(Wiedemer et al., 2025; Chen et al., 2025a)。尽管 Cosmos 3 在设计之初便具备原生处理多种任务的能力,仍采用监督微调(SFT)技术,旨在明确展示并强化其在图生视频领域的潜力。
机器人策略后训练
开展机器人策略后训练,旨在探究 Cosmos 3 全模态世界模型能否扩展为强大的机器人策略模型。Cosmos 3 具备对语言、视觉观测和动作等模态序列进行建模的能力,并能实现动作与视频的联合生成。在此基础上,针对机器人策略学习对模型进行进一步定制:引入本体感知信号,降低推理延迟,并调整模型以输出适用于闭环控制的可执行动作。
作为试点研究,用 DROID 机器人平台和数据集(Khazatsky,2024),因为它很受欢迎且社区广泛采用。 DROID 平台使用 Franka Panda 7-DoF 机械臂和 Robotiq 2F-85 平行爪夹具,在不同的现实环境中执行桌面操纵任务。 DROID 数据集包含 76k 轨迹、350 小时的交互数据、86 个任务和 564 个场景,为现实世界的机器人策略学习提供了巨大的规模和广泛的任务多样性。以 360×640 的高分辨率摄取 DROID,应用社区提供的空闲帧过滤和故障演示去除,并在训练期间使用随机图像增强。
如下讨论支持 Cosmos 3 端到端生命周期的集成基础设施架构。如图 11 所示,该平台整合四大核心支柱:

数据工程:摄取原始多模态数据,并将其转换为 WebDataset 格式的精选数据集,从而针对可扩展的分布式训练进行优化。
大规模训练:通过高效的并行化策略、优化的数据加载、快速检查点保存以及集合通信原语,最大化 NVIDIA GPU 集群的利用率。
模型服务:支持针对生成式和推理式工作负载的高效、低延迟部署与推理执行。
基准测试与验证:提供统一的评估框架,用于衡量模型在各种任务中的能力,并支持自动化的回归追踪与系统性的模型对比。
1. 数据基础设施
Cosmos 3 的训练语料库源自数百亿个涵盖多种模态、领域和任务的候选图像与视频数据。在此规模下进行操作,需要一套能够同时实现以下功能的数据基础设施:(1) 通过大规模分布式处理将原始多模态数据转换为可直接用于训练的样本;(2) 支持基于嵌入(embedding)的检索、聚类及去重;(3) 支持交互式的数据集可视化、检查与调试。为满足这些需求,开发 SILA(Scalable Infrastructure for Large-scale data processing and Annotation,即用于大规模数据处理与标注的可扩展基础设施)。这是一个可扩展的多模态数据基础设施平台,将存储、元数据管理、分布式处理、语义检索和数据集可视化功能整合到一个统一且可扩展的框架中,用于大规模数据的筛选与管理。
SILA 的设计核心在于将流水线逻辑与基础设施底层机制清晰分离。研究人员只需定义带有类型标注的处理阶段(指定每个阶段所需的输入列及产生的输出),平台便会自动处理数据集分片、分布式执行、容错、检查点保存、元数据更新及资产注册等底层任务。这种抽象设计使得引入新的数据源、基础模型及处理阶段(如过滤、生成描述/captioning、生成嵌入、评分和打标)变得简单直观,研究人员无需具备分布式系统开发的专业知识。最终,该平台实现数据筛选流程与研究进度的同步演进:随着模型、质量标准及训练策略的调整,新的信号可以被增量式地添加、重新计算或替换。
2. 训练基础设施
Cosmos 3 采用专为扩展多模态基础模型训练而构建的定制基础设施平台。这一统一的技术栈协调“推理器”(Reasoner)和“生成器”(Generator)训练的全生命周期。该生命周期涵盖从原始多模态样本的摄取、训练计算到持久化检查点(checkpoint)保存的各个环节,并围绕下文所述的阶段进行组织。
• 数据加载器(Data loader)。数据加载器负责摄取具有任意原生分辨率和长宽比的多模态样本(包括图像、视频、动作、音频和文本)。它执行实时数据增强(如调整大小、空间裁剪、色彩抖动和视频时间轴子采样),对文本条件进行token化(tokenization),并将变长样本打包成批次(batch)。为了掩盖 I/O 和预处理延迟,加载器在并行工作进程中异步运行,并通过锁页内存(pinned-memory)暂存缓冲区将批次预取到设备上。
• 分布式训练。训练过程结合混合分片数据并行(HSDP)和上下文并行(CP)技术,实现并行化。这种方法支持扩展至超大规模模型和超长输入序列。HSDP 在每个副本组内对优化器状态、梯度和模型参数进行分片,同时在组间进行复制;CP 则在设备间对序列维度进行分片,从而处理超出单块 GPU 显存容量的海量上下文窗口。这两种策略正交结合,并根据目标模型规模、序列长度和集群拓扑结构进行动态配置,以实现最优性能。
• 训练循环(Training loop)。训练循环采用 TorchTitan(Liang,2024b)的编排模式,执行标准的前向传播、反向传播、优化及学习率调度周期。它原生支持多种优化器(如 AdamW 及其融合变体)、调度器(如带预热的余弦退火、带预热的恒定学习率)以及损失函数(用于推理器文本的交叉熵损失和用于生成器的 EDM 损失)。此外,该流水线集成了实时变分编码器(如 Wan2.2 VAE),能够直接对原始多模态输入进行端到端处理。这种设计省去了离线潜空间特征提取(latent-extraction)阶段,并确保了数据增强、编码和训练过程在不同运行之间保持同步一致。
• 检查点保存。检查点以可配置的频率进行记录,并采用异步且位于关键路径之外的持久化机制,以避免磁盘和网络 I/O 导致训练循环停滞。模型参数、优化器状态以及随机数生成器(RNG)与数据加载器的状态会在设备上进行快照,随后移交给后台写入进程,并在训练不中断的情况下序列化并保存至远程存储。
推理器(Reasoner)和生成器(Generator)均基于这一统一框架进行训练,共享通用的训练器、并行化架构、优化器、学习率调度器、token化器、数据加载器及监控工具。
3. 推理服务基础设施
Cosmos 3 集成多种生产级推理服务框架,以支持广泛的部署场景。Reasoner 模块由 TensorRT-LLM (NVIDIA Corporation, 2026) 和 vLLM (Kwon et al., 2023) 提供支持;这两者均通过分页 KV -缓存管理、连续批处理(continuous batching)和融合注意算子(fused attention kernels),实现了高度优化的自回归解码。Generator 的推理则由 vLLM-Omni(vLLM 针对扩散模型生成任务的多模态扩展版本,Yin et al., 2026)支持,该框架在峰值吞吐量与多租户调度效率之间提供了互补的权衡方案。除了上述生产级后端外,还提供一个基于原生 PyTorch 的参考实现,该实现侧重于代码的可读性与可修改性,既作为推理算法的精确规范,也作为下游适配、研究扩展以及集成至定制应用流水线的起点。
4. 基准测试基础设施
Cosmos 基准测试系统负责管理 Cosmos 模型的评估任务,并存储生成的产出物(artifacts)及评估结果。编排层负责在 Lepton 或 Slurm 集群上调度生成、评分及端点评估任务,并追踪各阶段的执行状态。对于每次运行,系统都会记录元数据,包括模型检查点(checkpoint)、代码版本、选定的基准测试集、生成设置、特定于基准测试的参数以及相关数据集。这些记录共同建立了从每个报告的分数到生成该分数所使用的确切模型权重、输入、参数配置及评估代码之间的完整可追溯性。
该系统支持异构基准测试套件,且无需所有基准测试采用统一的实现方式。基准测试依据多种标准对推理模型生成的视频、音频、动作轨迹及文本响应进行评估,这些标准涵盖视觉保真度、音频质量、视听同步性、对提示词(prompt)及控制指令的遵循程度、动作或轨迹的准确性、任务完成情况、物理合理性以及推理正确性。评估工具既包括与开源库及公开基准测试套件的集成,也包括专为 Cosmos 开发的定制评估器。评分方法多种多样,涵盖基于参考的误差指标、感知与时间一致性度量、视听对齐指标、基于 VLM(视觉语言模型)的评判、人工标注,以及精确匹配或数值答案评估。
对于生成器(Generator)的评估,基准测试过程分为生成和评分两个阶段。生成任务利用 PyTorch 推理流水线或服务框架来运行模型,并将生成的输出写入对象存储。随后的评分任务读取这些存储的产出物,计算单样本指标及汇总指标,并将结果与运行元数据一并记录。这种解耦设计允许在不重新运行生成过程的情况下,利用新的指标或评估器对输出结果进行重新评分。
对于推理器(Reasoner)的评估,采用 VLMEvalKit (Duan et al., 2024) 框架结合 vLLM。这些任务将提示词和多模态输入发送至已部署的模型端点,处理模型响应,并记录基准测试分数及相关元数据。
评估分数和运行元数据存储在关系型数据库中,而生成的产出物则存储在对象存储中。人工评估的标注数据与被评估的产出物及问题集一并存储,汇总后的人工评估结果则与自动化指标同步追踪。基准测试门户通过仪表板、排行榜、针对单个样本的检查工具,以及模型间或检查点间的对比功能,提供对这些记录的访问。
附:Cosmos3-Edge LLM 模型训练
Cosmos3-Edge 采用一个从零开始训练的稠密型 2B 参数主干网络。其训练遵循两阶段的课程学习策略:先进行预训练,随后进行有监督微调。预训练阶段进一步细分为基础预训练和长上下文扩展两个子阶段。整个训练过程均采用 BF16 精度;优化器设置如下。
基础预训练。在基础预训练阶段,利用 Nemotron 预训练语料库中的总计 15T token 数据,以 8,192 token 的序列长度,从零开始训练 2B Edge 主干网络。该阶段包含两个子阶段:首先是在涵盖广泛领域的数据混合集上进行通用预训练,随后是在更高质量的数据混合集上进行持续预训练。训练过程中采用数据混合集热切换(hot-swapped)策略:持续预训练从通用预训练阶段的检查点(checkpoint)恢复,同时保留优化器状态和学习率调度,仅变更数据混合集。用 AdamW 优化器,峰值学习率为 1.2 × 10⁻³,参数设置为 (𝛽1, 𝛽2) = (0.9, 0.95),权重衰减为 0.1,梯度裁剪范数为 1.0。用预热-稳定-衰减(WSD)学习率调度策略,并将数据混合集的切换点与从稳定阶段向衰减阶段的过渡点对齐。该模型与 NVIDIA Nemotron-3 系列模型(NVIDIA, 2025)共用同一个token化器(tokenizer)。
长上下文扩展。在长上下文扩展阶段,将 Cosmos3-Edge 主干网络的上下文窗口扩展至 128K token。尽管扩展后的上下文窗口支持 128K token 的训练序列,但该阶段的主要目标是提升模型在实际部署时 32K token 序列长度下的鲁棒性与质量。在上下文扩展阶段,用 128K 的序列长度进行训练,并将 RoPE 基数(base)提高至 1e8。训练过程中采用 1.2 × 10⁻⁵ 的恒定学习率,且该长上下文阶段的训练数据量为 90B token。针对该阶段的数据混合策略,将预训练阶段的数据混合比例下调至 80%,并将长文档问答(QA)数据作为剩余的 20% 纳入其中。
监督微调。用来自 Nemotron-Cascade-2 (Yang et al., 2026b) 的监督微调(SFT)数据,这些数据涵盖了数学、编程、科学、通用对话、指令遵循、工具使用及代码智体(code-agent)任务等广泛领域。该数据集总计包含约 2600 万个 SFT 样本。将这些样本打包成长度最高达 128K token 的序列,从而生成约 260 万个打包后的训练样本。模型在单一 SFT 阶段进行训练,全局批次大小(global batch size)设为 32。采用 AdamW 优化器,学习率设为 2 × 10⁻⁵,参数 (𝛽1, 𝛽2) 设为 (0.9, 0.98)。实验结果表明,模型能力在约 1.7 个 epoch(对应 14 万个训练步)后达到峰值。
在涵盖推理、科学、指令遵循、长上下文及通用能力等方面的多个文本基准测试集上评估 SFT 模型,包括:HMMT25 Feb(哈佛-麻省理工数学竞赛,2025)、GPQA (Rein et al., 2023)、MMLU-Pro (Wang et al., 2024d)、AA-LCR (Artificial Analysis Team, 2025)、IFBench (Pyatkin et al., 2025a) 以及 Scale AI Multi-Challenge (Sirdeshmukh et al., 2025)。将模型与同等规模的强基线模型 Qwen3.5-2B (Qwen Team, 2026b) 进行了对比。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)