Week 3:分类任务、逻辑回归与深度学习
Abstract
This week, we moved from regression analysis to classification tasks in supervised learning, and learned two classic classification algorithms: probabilistic generative models and logistic regression. We explored their design ideas, mathematical principles and practical characteristics, and compared the applicable scenarios of different models. On this basis, we started to learn the basic knowledge of deep learning. We got familiar with the composition and working mode of fully connected neural networks, mastered the operation logic of forward propagation and back propagation, and understood the function of common activation functions. Meanwhile, we analyzed common difficulties in the training of deep networks.
中文摘要
本周学习从回归分析转向监督学习中的分类任务,研习了概率生成模型与逻辑回归两大经典分类算法,探究其设计思路、数学原理与实际应用特点,对比不同模型的适用场景。在此基础上开启深度学习基础内容的学习,认识全连接神经网络的组成与工作方式,掌握前向传播、反向传播的运行逻辑,理解常用激活函数的作用,同时分析深度网络训练过程中存在的难点问题。
1 学习目标
- 分清分类任务与回归任务的区别,理解分类问题的解决思路,建立分类学习的整体认知。
- 掌握概率生成模型的核心思想,理解贝叶斯定理与高斯模型的运算逻辑,学会模型参数的求解方法。
- 吃透逻辑回归的模型构成、损失计算方式与参数优化过程,理清它和单层神经网络的内在联系。
- 区分生成模型与判别模型的特点,能够结合实际场景判断模型的选用依据。
- 认识全连接神经网络的整体结构,理解神经元的运算规则,明白多层网络实现非线性拟合的原理。
- 熟练掌握前向传播与反向传播的完整流程,理解链式求导在误差传递中的作用,掌握网络参数更新规则。
- 了解 Sigmoid、ReLU 等主流激活函数的特点、优势与不足,学会根据网络层级选择合适的激活函数。
2 学习日志
2.1 分类任务基础认知
回归任务主要用来预测连续的数值结果,而分类任务的目标是把样本划分到对应的离散类别中,日常所见的内容判别、类别筛选等场景,都属于分类问题的应用范畴。
根据类别数量,分类可以分为二分类和多分类,也是后续各类智能应用的底层技术支撑。和回归任务单纯拟合数据趋势不同,分类模型会结合概率思维进行判断,通过计算样本属于每一个类别的可能性,最终确定样本归属。在学习中了解到,当下主流的分类算法可以分为概率生成模型和判别模型两大类型,两种模型的思考角度与实现方式各不相同,也是本周重点钻研的内容。
2.2 概率生成模型
概率生成模型的思考逻辑较为直观,它会先去学习整组数据本身的分布规律,再依托概率公式完成分类判断。这类模型会对样本和标签的联合概率分布进行建模,再借助贝叶斯定理推导得出样本属于某一类别的概率。
贝叶斯定理是这类模型的核心理论支撑,对应的计算公式如下:
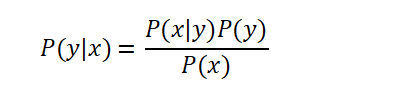
公式中, 代表各类样本在数据集中的占比,也就是类别先验概率; 表示在确定类别后,样本特征呈现出的分布状态; 仅起到归一化的作用,不会改变最终的分类结果,在实际计算中可以省略。
针对特征为连续数值的场景,我们采用多维高斯分布来描述同类样本的特征规律。为了简化计算、减少模型参数,设定所有类别的样本共用一个协方差矩阵,仅均值存在差异,多维高斯分布概率密度公式为:
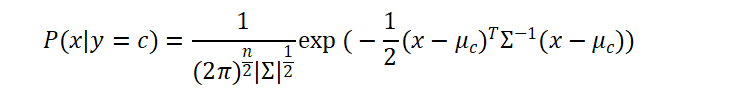
模型训练阶段,我们使用极大似然估计求解所有参数:通过统计样本数量得到类别占比,分别计算每一类样本的均值向量,再结合全部数据求解协方差矩阵。参数训练完成后,将待预测样本代入公式,对比各类别概率大小,即可完成分类。在学习过程中发现,这类模型对数据分布有明确假设,当训练样本数量较少时,模型表现会更加稳定;但如果数据真实分布和预设分布差距较大,分类效果就会大打折扣。
2.3 逻辑回归
逻辑回归是行业内使用率极高的判别式分类算法,和生成模型不同,它不会深究数据整体的分布情况,而是直接聚焦分类本身,对样本属于某一类别的概率进行建模。同时我也了解到,逻辑回归的结构和单层神经网络高度相似,是从传统机器学习过渡到深度学习的重要衔接点。
该模型将线性计算结果输入 Sigmoid 激活函数,把输出数值限制在
之间,以此代表样本为正类的概率,模型表达式如下:
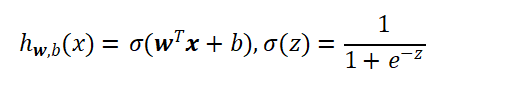
在损失计算环节,分类任务不再使用回归任务中的均方误差。经过学习得知,均方误差容易导致模型训练速度变慢,因此分类场景普遍采用交叉熵损失来衡量预测结果和真实标签之间的偏差。单个样本损失公式:
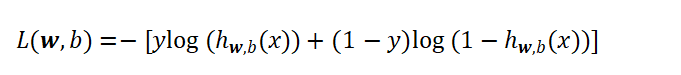
整合全部训练样本后,整体平均损失函数为:
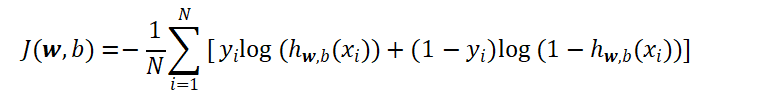
模型优化依旧沿用此前学习的梯度下降算法,通过不断迭代更新权重与偏置参数,让损失值持续降低,参数更新公式:
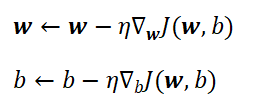
结合 Sigmoid 函数的求导特性,还可以进一步简化梯度的计算过程,提升整体训练效率。
2.4 生成模型与判别模型综合对比
在系统学习两类模型后,我对二者的特点进行了梳理总结。从建模思路来看,生成模型着眼于全局数据分布,会提前设定数据的分布形式;判别模型则聚焦分类边界,只关注最终的判别结果,没有额外的分布假设。
从使用场景来看,当可用的训练数据有限时,生成模型的稳定性更占优势;如果数据集样本充足,判别模型往往能得到更高的分类精度。除此之外,生成模型因为学习了完整的数据分布,还具备生成相似新样本的能力;而判别模型结构简单、训练高效,更适合落地到常规的分类项目中。在实际应用中,可以根据数据规模、任务需求灵活选择对应的模型。
2.5 深度学习:全连接神经网络基础
完成传统分类算法的学习后,本周正式踏入深度学习领域。我从基础的单个神经元入手,逐步理解多层全连接神经网络的运行逻辑,系统学习网络结构、数据传播方式、激活函数以及训练过程中遇到的各类问题。
标准的全连接神经网络主要由输入层、隐藏层和输出层三部分组成。输入层负责接收原始的特征数据;多层隐藏层是网络的核心部分,能够层层提炼、转换特征,挖掘数据里深层次的抽象信息;输出层则根据任务类型,输出最终的预测结果。单纯的线性运算无法拟合复杂的非线性规律,而多层网络搭配激活函数,让模型拥有了强大的非线性表达能力,这也是深度学习相比传统算法的核心优势。
数据在网络中的正向传递过程被称为前向传播,数据会按照层级顺序逐层计算、逐层传递。设定网络第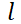 层的权重矩阵为
层的权重矩阵为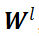 ,偏置向量为
,偏置向量为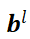 ,线性计算结果为
,线性计算结果为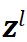 ,激活后输出为
,激活后输出为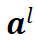 ,具体计算方式为:
,具体计算方式为:
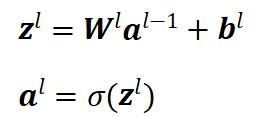
激活函数是为网络引入非线性的关键,本周重点学习了两款应用最广泛的函数。Sigmoid 函数适合用在二分类任务的输出层,取值范围贴合概率输出的需求,但当输入数值极值过大时,容易出现梯度饱和的问题,不利于深层网络训练。ReLU 函数计算简单、运行速度快,还能有效缓解梯度饱和,目前绝大多数网络的隐藏层都会选择它。
想要让网络不断优化、提升精度,就需要依靠反向传播算法完成参数更新。该算法利用微积分里的链式求导法则,把输出层产生的误差反向传递到网络的每一层,依次求解损失函数对各层参数的梯度,再结合梯度下降完成参数迭代。
设网络总层数为L,首先计算输出层误差:
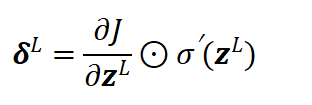
误差逐层向前传递,隐藏层误差计算公
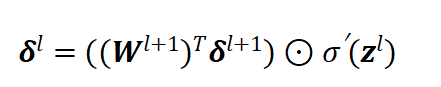
进一步求解参数梯度并完成更新:
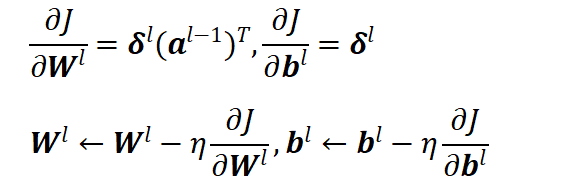
随着网络层数不断增加,训练过程也会出现新的难题。由于链式求导会产生梯度连乘的效果,很容易出现梯度消失和梯度爆炸两种问题:梯度消失会让浅层参数无法有效更新,梯度爆炸则会造成参数剧烈震荡,导致模型无法收敛。结合所学内容,我了解到可以通过更换激活函数、合理初始化权重、梯度裁剪等方式,对这类问题进行缓解。
3 学习成果
- 清晰区分分类任务与回归任务的应用场景和建模目标,熟练掌握概率生成模型、高斯判别模型的原理与计算流程,能够独立完成参数求解与分类预测。
- 充分理解逻辑回归的整体架构、损失计算逻辑与参数优化方式,明白其作为单层神经网络的本质,顺利搭建起传统分类算法与深度学习之间的知识桥梁。
- 能够全面分析生成模型与判别模型的优缺点,结合数据条件和业务需求做出合理的模型选择,具备基础的模型分析与应用能力。
- 熟知全连接神经网络的层级结构与神经元运算逻辑,理解激活函数的核心作用,掌握 Sigmoid、ReLU 函数的特性与使用场景。
- 完整掌握前向传播与反向传播的运行流程,理解链式求导的应用逻辑,熟记相关计算公式与参数更新规则,吃透神经网络的核心训练原理。
- 理解梯度消失、梯度爆炸的形成原因与负面影响,掌握基础的解决办法,对深度网络的训练难点建立了完整认知。
本周总结与后续规划
本周循序渐进完成了分类算法与深度学习两大板块的学习。从基础的分类概念出发,逐步掌握概率生成模型、逻辑回归两类经典算法,同时结合理论与公式理解模型的运行逻辑、优劣特性。之后深入学习全连接神经网络相关知识,弄懂网络结构、数据传播方式、激活函数以及训练中常见的问题,整个学习过程由浅入深,知识点衔接自然。
后续会继续学习深度学习,先学习深度网络的训练优化技巧、正则化方法与各类优化器,再逐步接触卷积神经网络、循环神经网络等主流网络结构,持续丰富深度学习知识储备,不断提升对复杂模型的理解与实践能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)