LangChain4j文档解析以及RAG的实战
Document Loaders 文档读取器
1.1. Document Parser 文档解析器
如果要开发一个知识库系统, 这些资料可能在各种文件中, 比如word、txt、pdf、image、html等等, 所以langchain4j也提供了不同的文档解析器:
TextDocumentParser来自langchain4j模块的TextDocumentParser,它可以解析纯文本格式(e.g. TXT、HTML、MD 等)的文件。ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox,它可以解析 PDF 文件ApachePoiDocumentParser来自langchain4j-document-parser-apache-poi,可以解析 MS Office 文件格式(e.g. DOC、DOCX、PPT、PPTX、XLS、XLSX 等)ApacheTikaDocumentParser来自langchain4j-document-parser-apache-tika模块中,可以自动检测和解析几乎所有现有的文件格式
2. DocumentSplitter 文档拆分器
由于文本读取过来后, 还需要分成一段一段的片段(分块chunk), 分块是为了更好地拆分语义单元,这样在后面可以更精确地进行语义相似性检索,也可以避免LLM的Token限制。
langchain4j也提供了不同的文档拆分器:
|
分词器类型 |
匹配能力 |
适用场景 |
|
DocumentByCharacterSplitter |
无符号分割 |
就是严格根据字数分隔(不推荐,会出现断句) |
|
DocumentByRegexSplitter |
正则表达式分隔 |
根据自定义正则分隔 |
|
DocumentByParagraphSplitter |
删除大段空白内容 |
处理连续换行符(如段落分隔)( |
|
DocumentByLineSplitter |
删除单个换行符周围的空白, 替换一个换行 |
(
|
|
DocumentByWordSplitter |
删除连续的空白字符。 |
|
|
DocumentBySentenceSplitter |
按句子分割 |
该分割器使用Apache OpenNLP 库中的一个类,用于检测文本中的句子边界。它能够识别标点符号(如句号、问号、感叹号等)是否标记着句子的末尾,从而将一个较长的文本字符串分割成多个句子。 |
超市商品价格表
【蔬菜类】
白菜:2.5元/斤
土豆:3元/斤
西红柿:4.5元/斤
黄瓜:4元/斤
胡萝卜:3.5元/斤
茄子:5元/斤
青椒:6元/斤
洋葱:2.8元/斤
【水果类】
苹果:6元/斤
香蕉:4.5元/斤
橙子:7元/斤
葡萄:12元/斤
西瓜:2元/斤(整个)
草莓:20元/盒(300g)
芒果:10元/斤
【肉蛋类】
猪肉:25元/斤
牛肉:45元/斤
鸡肉:15元/斤
鸡蛋:6元/斤(约8-9个)
鸭肉:18元/斤
【粮油类】
大米:5元/斤
面粉:4元/斤
食用油:12元/升
盐:2.5元/袋(500g)
糖:5元/斤(散装)
【饮料类】
矿泉水:2元/瓶(500ml)
可乐:3.5元/罐
果汁:8元/瓶(500ml)
牛奶:5元/盒(250ml)
酸奶:6元/杯
【日用品类】
牙刷:5元/支
牙膏:12元/支(120g)
洗衣粉:10元/袋(500g)
洗发水:35元/瓶(400ml)
纸巾:3元/包(小包)
【常见促销信息】
鸡蛋每周二特价:5元/斤
西瓜买一送一(限周末)
牛奶第二件半价我们这个应该适用于段落分隔
@Test
public void test() {
Document document = ClassPathDocumentLoader.loadDocument("rag/超市.txt", new TextDocumentParser());
DocumentByParagraphSplitter paragraphSplitter = new DocumentByParagraphSplitter(90,//每段最长字数
20);//自然语言最大重叠数,在切分文本时,相邻两个 chunk 之间共享的那部分内容的长度。防止断句
List<TextSegment> segments = paragraphSplitter.split(document);
System.out.println("segments = " + segments);
}看返回值: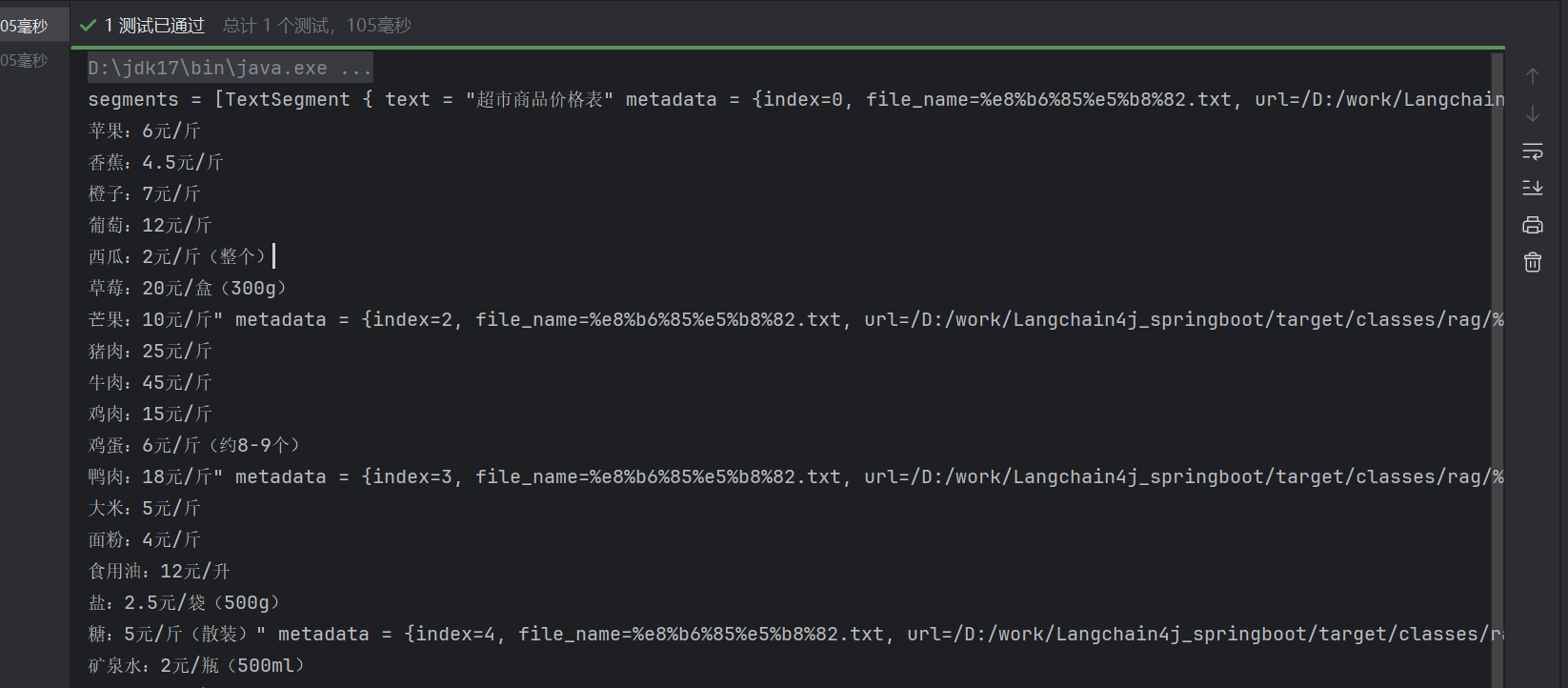
可以看到就是按照段落大段空行划分的。
流程大概是这样的
开始
↓
从分割符列表中按顺序取一个分割符
↓
按当前分割符切分文本
↓
判断:块长度是否 ≤ chunk_size?
├── 是 → 保留该块 → 继续处理下一块
└── 否 → 进入【块合并】逻辑
↓
用上一个分割符重新切分
或暂时保留待进一步切割
↓
判断:分割符列表中还有下一个分割符吗?
├── 是 → 回到开头,取下一种分割符
└── 否 → 结束
然后我没有设置chunk_size
2.1. 分隔经验:
2.1.1. 过细分块的潜在问题
- 语义割裂: 破坏上下文连贯性,影响模型理解 。
- 计算成本增加:分块过细会导致向量嵌入和检索次数增多,增加时间和算力开销。
- 信息冗余与干扰:碎片化的文本块可能引入无关内容,干扰检索结果的质量,降低生成答案的准确性。
2.1.2. 分块过大的弊端
- 信息丢失风险:过大的文本块可能超出嵌入模型的输入限制,导致关键信息未被有效编码。
- 检索精度下降:大块内容可能包含多主题混合,与用户查询的相关性降低,影响模型反馈效果。
接下来对于知识库的分片进行向量化并存储到向量数据库当中
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey()//你设置的api-key
.build();
List<Embedding> embeddingList = embeddingModel.embedAll(segments).content();
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddingList);然后对于文本进行向量化然后去向量数据库中查找
// 生成向量
Response<Embedding> embed = embeddingModel.embed("猪肉多少钱一斤");
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder().queryEmbedding(embed.content()).maxResults(1).build();
// 查询
EmbeddingSearchResult<TextSegment> results = embeddingStore.search(build);
for (EmbeddingMatch<TextSegment> match : results.matches()) {
System.out.println(match.embedded().text() + ",分数为:" + match.score());
}接下来就是对话增强阶段了。
ChatLanguageModel model = QwenChatModel
.builder()
.apiKey()
.modelName("qwen-max")
.build();
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5) // 最相似的5个结果
.minScore(0.1) // 只找相似度在0.6以上的内容
.build();
// 为Assistant动态代理对象 chat ---> 对话内容存储ChatMemory----> 聊天记录ChatMemory取出来 ---->放入到当前对话中
AI assistant = AiServices.builder(AI.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.build();
System.out.println(assistant.chat("肉多少钱一斤"));
}
public interface AI {
String chat(String message);
}
这里EmbeddingStoreContentRetriever实现了ContentRetriever接口。它里面有个retireve方法
public List<Content> retrieve(Query query) {
Embedding embeddedQuery = (Embedding)this.embeddingModel.embed(query.text()).content();
EmbeddingSearchRequest searchRequest = EmbeddingSearchRequest.builder().queryEmbedding(embeddedQuery).maxResults((Integer)this.maxResultsProvider.apply(query)).minScore((Double)this.minScoreProvider.apply(query)).filter((Filter)this.filterProvider.apply(query)).build();
EmbeddingSearchResult<TextSegment> searchResult = this.embeddingStore.search(searchRequest);
return (List)searchResult.matches().stream().map((embeddingMatch) -> Content.from((TextSegment)embeddingMatch.embedded(), Map.of(ContentMetadata.SCORE, embeddingMatch.score(), ContentMetadata.EMBEDDING_ID, embeddingMatch.embeddingId()))).collect(Collectors.toList());
}执行的就是将用户消息向量化然后去向量库进行检索。
利用JDK的动态代理技术,当assistant.chat,就会动态代理生成一个AI对象· 实现了自定义的AI接口然后去执行检索增强。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)