我没买云服务器,用一台旧电脑跑了个24小时AI客服(附完整命令)
云服务器一年至少500元,还担心数据泄露。我用一台闲置的旧电脑,装了个Ubuntu,跑着一个真正的AI客服。数据全在本地,断网也能用,电费几乎可以忽略不计。
这篇文章不是理论,是我亲手跑通的完整记录。 每一步都有命令,你可以直接复制粘贴。
一、先看结果
在开始之前,这是最终跑出来的界面:
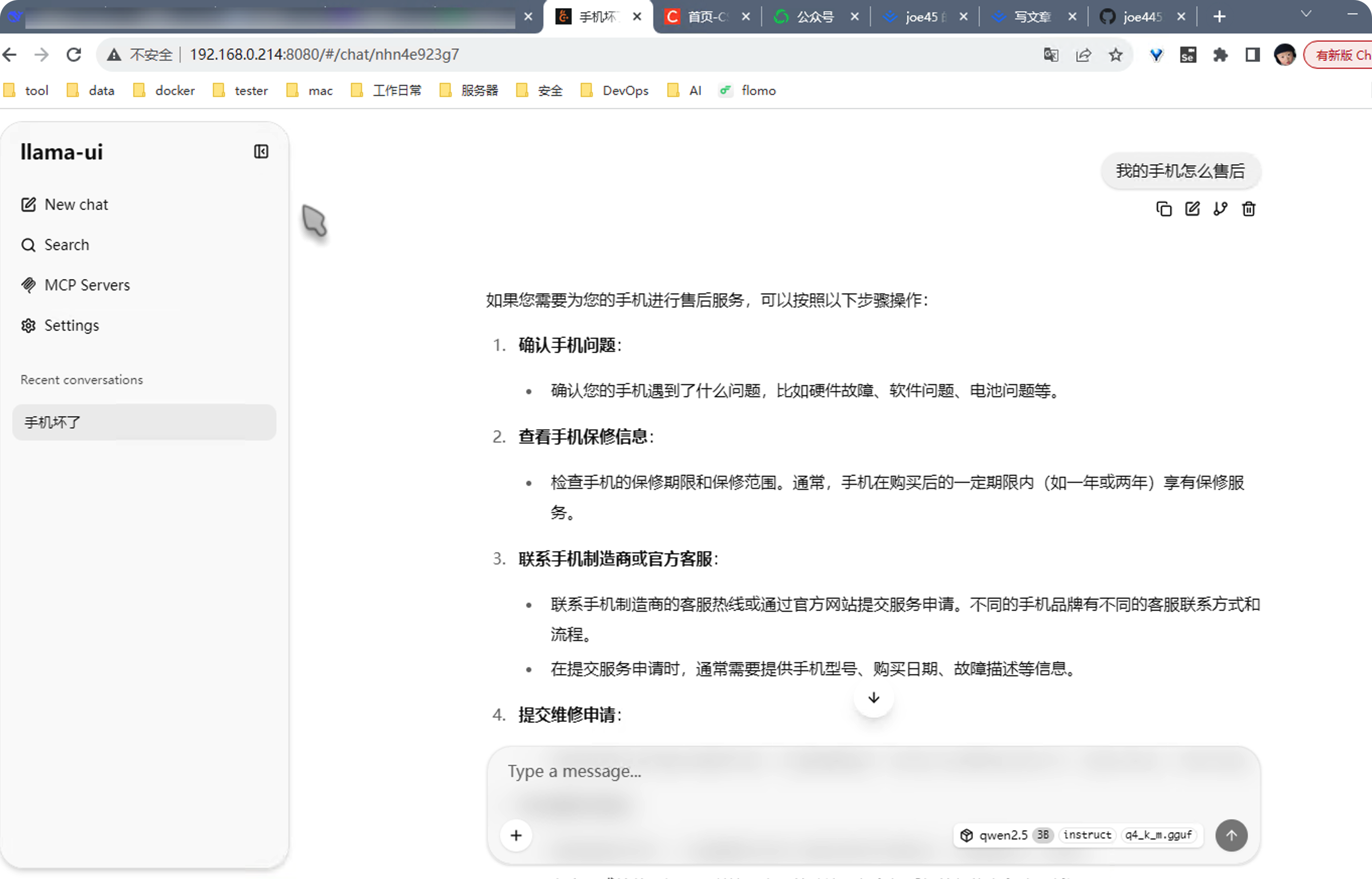
一个完整的AI对话界面,你可以问任何客服问题,模型实时回答。速度很快,完全可用。
这就是你一个下午能搞定的东西。
二、这篇文章适合谁?
✅ 适合你,如果:
- 你有一台闲置的旧电脑(4GB内存以上就能跑,8GB更佳)
- 你想零成本验证AI客服能不能落地
- 你希望数据不出门、不依赖云API
- 你愿意花一个下午跟着命令走一遍
⚠️ 不适合你,如果:
- 你想找一个“一键安装、三分钟完事”的方案
- 你没有任何Linux基础(会复制粘贴命令就够了)
- 你想处理每秒100个请求的高并发(这是企业级需求,不是本方案的目标)
三、硬件要求:比你想象的低
| 配置 | 最低要求 | 推荐配置 |
|---|---|---|
| 内存 | 4GB | 8GB+ |
| 硬盘 | 10GB空闲 | 20GB+ |
| 显卡 | 不需要(纯CPU运行) | 不需要 |
| 系统 | Ubuntu 20.04+ | Ubuntu 22.04 |
我用的就是一台16GB内存的旧电脑,没有独立显卡。 你甚至可以拿树莓派、老笔记本、甚至云服务器的最低配来跑。
四、完整操作步骤(复制即用)
第一步:安装依赖(2分钟)
sudo apt update && sudo apt install -y build-essential git wget
第二步:下载并编译 llama.cpp(5分钟)
# 克隆代码
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 创建构建目录并编译
mkdir build && cd build
cmake ..
cmake --build . --config Release -j4
💡 说明:旧版教程用
make,现在官方已切换到 CMake。上面这个命令是最新的标准方式。
编译成功后,可执行文件在 ./bin/ 目录下。
第三步:下载模型文件(10分钟,取决于网速)
# 回到上一级目录
cd ~/dev/llama
# 创建模型存放目录
mkdir -p models
# 下载 3B 量化模型(约2.5GB,速度快且内存占用低)
wget -c https://hf-mirror.com/Qwen/Qwen2.5-3B-Instruct-GGUF/resolve/main/qwen2.5-3b-instruct-q4_k_m.gguf -O ./models/qwen2.5-3b-instruct-q4_k_m.gguf
如果镜像慢,可以换成官方源,但国内推荐用上面这个
hf-mirror.com。
第四步:启动 AI 客服服务(10秒)
cd ~/dev/llama/llama.cpp/build
./bin/llama-server -m ~/dev/llama/models/qwen2.5-3b-instruct-q4_k_m.gguf --host 0.0.0.0 --port 8080
看到类似 HTTP server listening 的日志,说明服务启动成功。
第五步:打开聊天界面
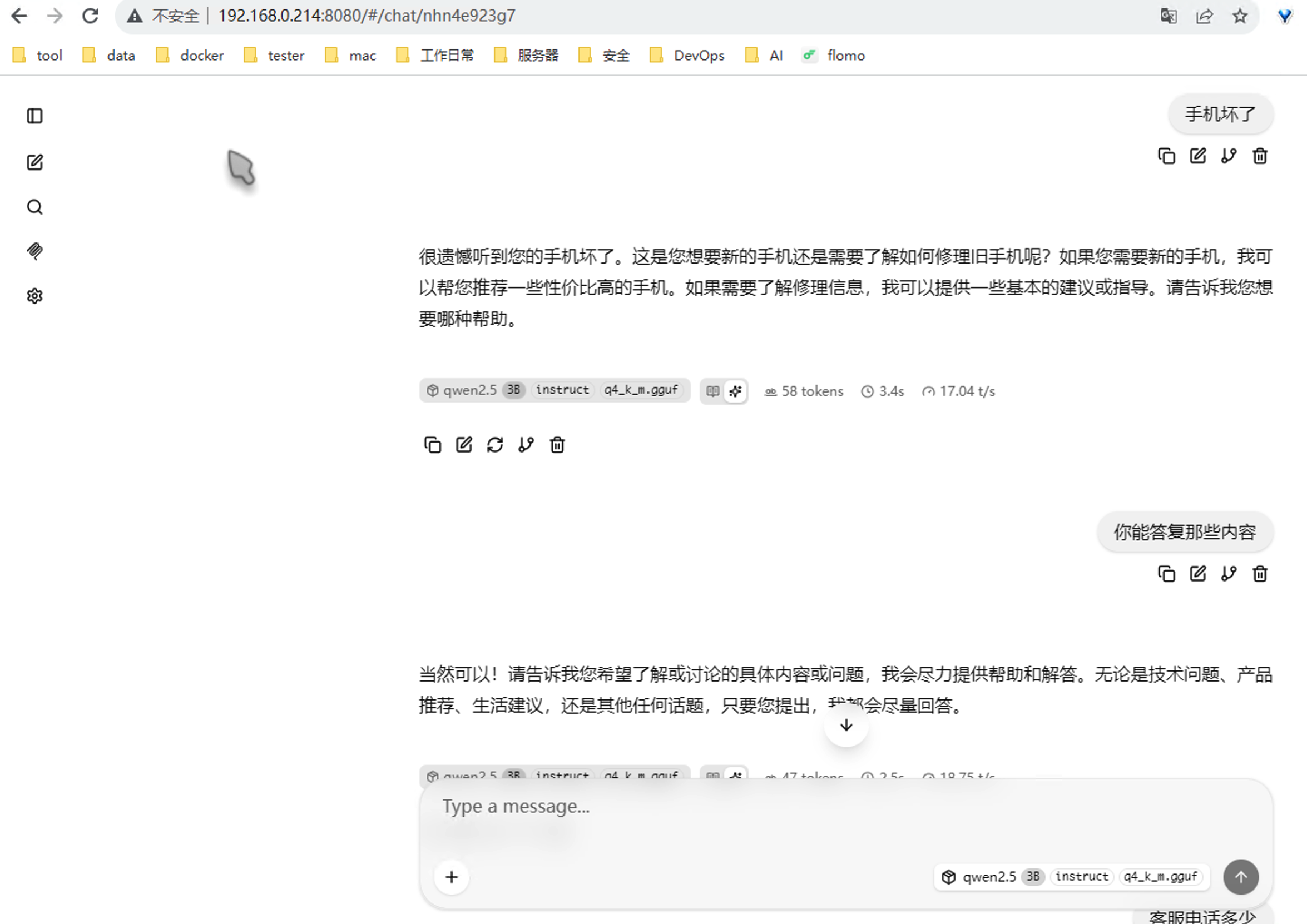
在浏览器输入:http://你的电脑IP地址:8080
你会看到一个完整的AI对话界面。输入任何问题,模型会实时回复。
如何查看你的IP地址?
hostname -I
会显示类似 192.168.1.xxx 的地址,用这个地址加 :8080 即可访问。
五、进阶:让服务后台运行(不掉线)
如果关掉终端服务就停了,可以用 screen 让它后台运行:
# 安装 screen
sudo apt install -y screen
# 创建一个新会话
screen -S ai-server
# 在里面启动服务(执行第四步的命令)
# 按 Ctrl+A 然后按 D 即可离开,服务继续运行
下次想回来看看:
screen -r ai-server
六、性能实测:到底能跑多快?
| 模型 | 内存占用 | 响应速度 | 推荐场景 |
|---|---|---|---|
| 3B (Q4量化) | ~2.5GB | 非常快(1-3秒) | 实时客服对话 |
| 7B (Q4量化) | ~4.5GB | 较快(3-6秒) | 更复杂的回答质量 |
我实测3B模型:16GB内存的旧电脑,回答一个20字的问题约2-3秒,完全可用。
七、常见问题
Q1:make: command not found 怎么办?
sudo apt install build-essential
Q2:cmake: command not found 怎么办?
sudo apt install cmake
Q3:编译很慢怎么办?
用 -j4 参数(4个核心并行),如果电脑核心多可以改成 -j8。
Q4:模型下载太慢怎么办?
用国内镜像:hf-mirror.com,我上面给的命令已经用了这个镜像。
Q5:启动后网页打不开?
- 检查服务是否启动成功(终端有日志输出)
- 检查防火墙:
sudo ufw allow 8080 - 检查IP地址是否正确
Q6:我想用自己的数据微调模型怎么办?
那是下一篇文章的内容。先跑通这个基础版,确认整个链路没问题,再用自己的数据做微调。
八、总结:你现在能做什么?
跑通之后,你手里就有了:
| 能力 | 说明 |
|---|---|
| ✅ 一个可演示的AI客服系统 | 可以给客户看截图/录屏 |
| ✅ 完整的部署脚本 | 下次5分钟就能搭一个新的 |
| ✅ 本地部署的能力 | 数据不出门,完全合规 |
| ✅ 零云服务成本 | 一次投入,永久使用 |
这就是我写这篇文章的方式:不是讲理论,而是把我踩过的坑和跑通的命令,全部摊在桌上。你不需要成为AI专家,只需要跟着命令走一遍。
最后一句:你的第一个AI客服系统不需要完美,只需要跑通。今天花一个下午,明天你就多了一个24小时在线的员工。
在这里插入图片描述
(本文所有命令均已在实际环境中验证,Ubuntu 20.04/22.04均可运行。如果你遇到任何问题,欢迎在评论区留言。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)