R语言分类决策数算法----iris数据集
install.packages("C50")
library(C50) # 加载决策树算法包
# ====================加载并查看数据集 ====================
# iris是R自带的经典鸢尾花数据集,无需额外下载
data(iris)
# 查看数据集基本信息:150个样本,5个变量(4个特征+1个分类标签)
# 特征:花萼长度/宽度、花瓣长度/宽度;标签:3种鸢尾花品种
head(iris) # 查看前6行数据
str(iris) # 查看数据结构(确认特征是数值型,标签是因子型)1、数据集划分
# ==================== 数据划分:训练集(70%) + 测试集(30%) ====================
# 设置随机种子,保证结果可复现(每次运行划分结果一致)
set.seed(123)
# 随机抽样:生成1-150中70%的行索引,用于训练集
train_index <- sample(1:nrow(iris), size = 0.7*nrow(iris))
# 训练集:用于训练决策树模型
train_data <- iris[train_index, ]
# 测试集:用于评估模型预测效果
test_data <- iris[-train_index, ]
# 分离特征和标签(决策树输入格式:特征矩阵 + 标签向量)
# 训练集特征(前4列:所有数值型特征)
train_x <- train_data[, -5]
# 训练集标签(第5列:品种Species)
train_y <- train_data[, 5]
# 测试集特征
test_x <- test_data[, -5]
# 测试集标签(真实标签,用于对比预测结果)
test_y <- test_data[, 5]
2、训练模型C5.0
# ==================== 4. 训练C5.0决策树模型 ====================
# 函数语法:C5.0(特征矩阵, 标签向量)
# 模型会自动学习特征与标签的对应关系,生成决策树规则
tree_model <- C5.0(train_x, train_y)
# 查看决策树模型详情:规则、特征重要性、分类准确率
summary(tree_model) Call:
C5.0.default(x = train_x, y = train_y)
C5.0 [Release 2.07 GPL Edition] Sun Jun 7 09:40:40 2026
-------------------------------
Class specified by attribute `outcome'
Read 105 cases (5 attributes) from undefined.data
Decision tree:
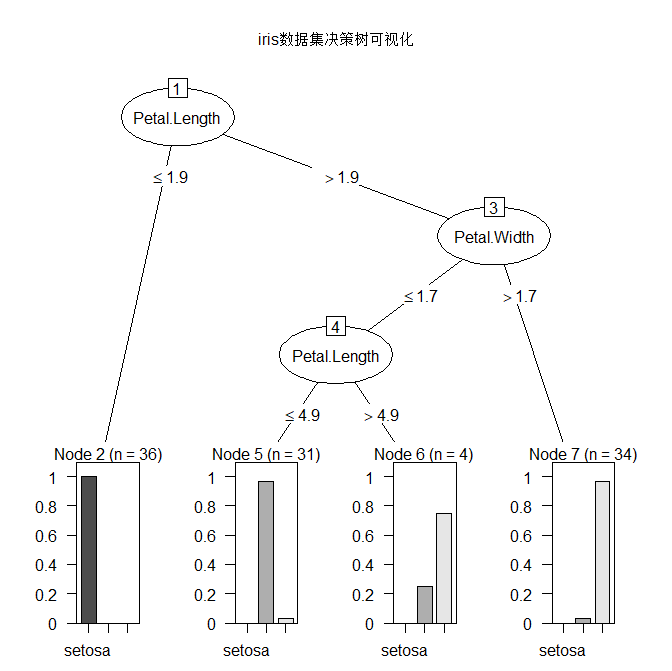
Petal.Length <= 1.9: setosa (36)
Petal.Length > 1.9:
:...Petal.Width > 1.7: virginica (34/1)
Petal.Width <= 1.7:
:...Petal.Length <= 4.9: versicolor (31/1)
Petal.Length > 4.9: virginica (4/1)
Evaluation on training data (105 cases):
Decision Tree
----------------
Size Errors
4 3( 2.9%) <<
(a) (b) (c) <-classified as
---- ---- ----
36 (a): class setosa
30 2 (b): class versicolor
1 36 (c): class virginica
Attribute usage:
100.00% Petal.Length
65.71% Petal.Width
Time: 0.0 secs
3、模型评估
# ==================== 5. 模型预测:用测试集验证效果 ====================
# predict(模型, 新数据):对测试集特征进行品种预测
pred_y <- predict(tree_model, test_x)
# 查看前10个预测结果 vs 真实结果
cat("前10个预测值:", as.character(pred_y[1:10]), "\n")
cat("前10个真实值:", as.character(test_y[1:10]), "\n")
# ==================== 6. 模型评估:计算准确率 ====================
# 准确率 = 预测正确的样本数 / 总测试样本数
accuracy <- sum(pred_y == test_y) / length(test_y)
cat("决策树模型测试集准确率:", round(accuracy*100, 2), "%\n")前10个预测值: setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
前10个真实值: setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa
> # 准确率 = 预测正确的样本数 / 总测试样本数
> accuracy <- sum(pred_y == test_y) / length(test_y)
> cat("决策树模型测试集准确率:", round(accuracy*100, 2), "%\n")
决策树模型测试集准确率: 97.7
4、可视化
# ==================== 7. 可视化决策树(直观查看分类规则) ====================
# 安装可视化包,首次使用安装,后续注释
# install.packages("partykit")
library(partykit)
# 转换模型格式并绘图
plot(as.party(tree_model), main = "iris数据集决策树可视化")
5、决策树rpart算法
# 加载rpart包(决策树)和rpart.plot(可视化)
# install.packages(c("rpart", "rpart.plot"))
library(rpart)
library(rpart.plot)
data(iris)
set.seed(123)
# 数据划分同上
train_index <- sample(1:nrow(iris), 0.7*nrow(iris))
train_data <- iris[train_index, ]
test_data <- iris[-train_index, ]
# 训练rpart决策树:公式格式 Species ~ . (标签~所有特征)
tree_rpart <- rpart(Species ~ ., data = train_data, method = "class")
# 预测+评估
pred_rpart <- predict(tree_rpart, test_data, type = "class")
accuracy_rpart <- sum(pred_rpart == test_data$Species)/nrow(test_data)
cat("rpart决策树准确率:", round(accuracy_rpart*100,2), "%\n")
# 可视化决策树
rpart.plot(tree_rpart, main = "rpart决策树(iris)")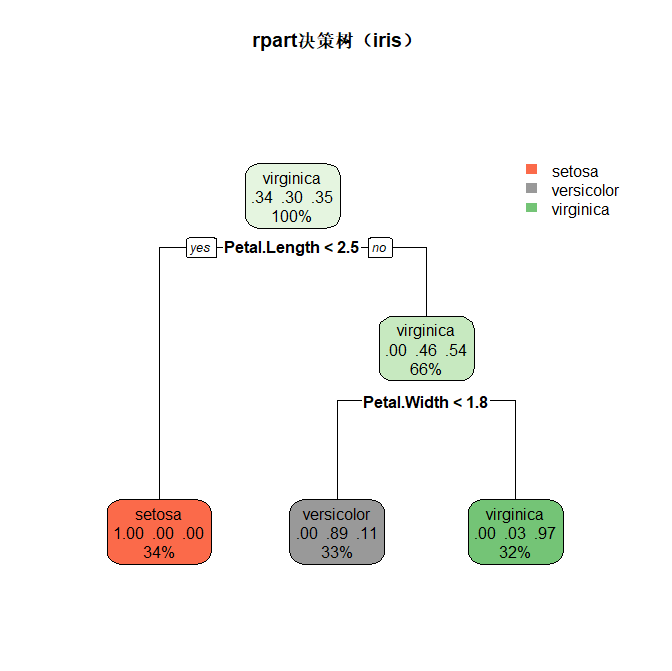

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)