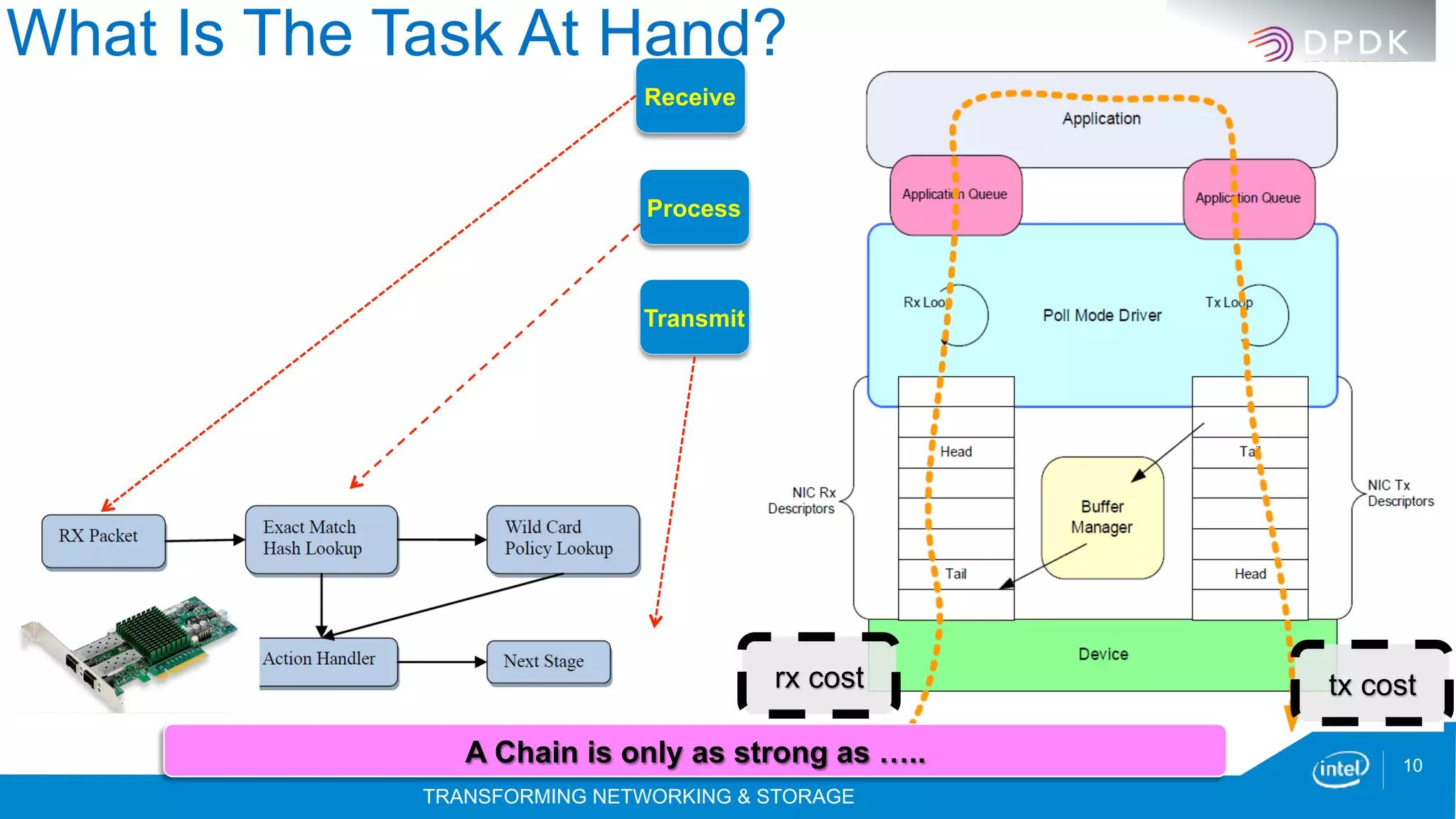
从100Gbps掉到15Gbps:一次高性能网关性能瓶颈的完整定位与架构演进
一、问题现象
我前几年曾经为某运营商设计并落地一套UPF架构。当项目进入集成测试阶段:
硬件配置:
- Intel Xeon Gold 双路CPU
- 2×100G Intel E810网卡
- DPDK 20.11
- Linux Kernel 5.15
系统架构如下:
设计目标:
- 单机100Gbps
- 64字节报文
- 双向转发
实际压测结果:
| 指标 | 目标值 | 实际值 |
|---|---|---|
| Throughput | 100Gbps | 15Gbps |
| PPS | 148Mpps | 22Mpps |
| 丢包率 | 0 | 35% |
最诡异的是:网卡没打满、内存也没打满,但是吞吐量就是上不去。
这类问题在高性能网关开发中极其常见。
二、第一步定位:CPU到底在干什么
首先使用perf采样:
perf top热点函数:
45% rte_ring_enqueue_burst
18% rte_ring_dequeue_burst
12% rte_hash_lookup_bulk
8% rte_pktmbuf_alloc_bulk发现一个奇怪现象:
真正的数据包处理逻辑:
process_gtpu_packet()只占不到10%。
CPU时间主要消耗在:
Ring
Hash
Mbuf这些基础设施上。
说明问题不在业务逻辑。
而在架构设计。
三、Dispatcher成为瓶颈
当前架构:
RX
|
V
+---------------+
| Dispatcher |
+---------------+
/ / / / / /
V V V V V V
Worker WorkerDispatcher负责:
收包
解析TEID
计算Hash
决定Worker
入RingWorker负责:
GTP-U处理
PDR查找
FAR处理
转发看起来很合理。
但问题来了。
假设:
100Gbps
64Byte对应:
148.8 MppsDispatcher必须完成:
148.8M次TEID解析
148.8M次Hash
148.8M次Ring操作实际上Dispatcher已经成为整个系统的单点瓶颈。
架构如下:
RX
|
V
Dispatcher
|
----------------
| | | | | |
V V V V V V
Worker Worker Worker所有流量必须经过Dispatcher。
这是典型的:
串行入口
并行出口架构。
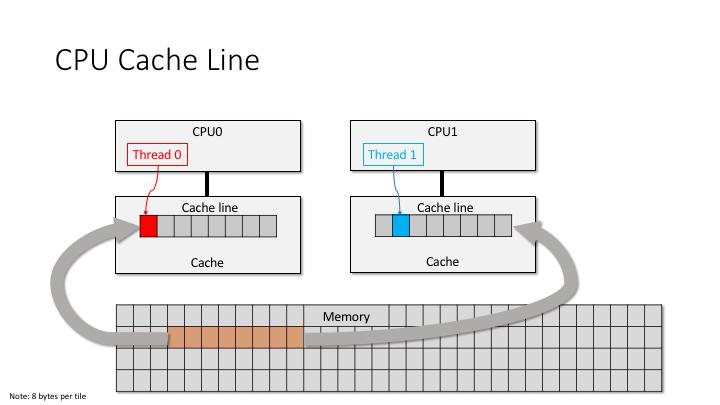
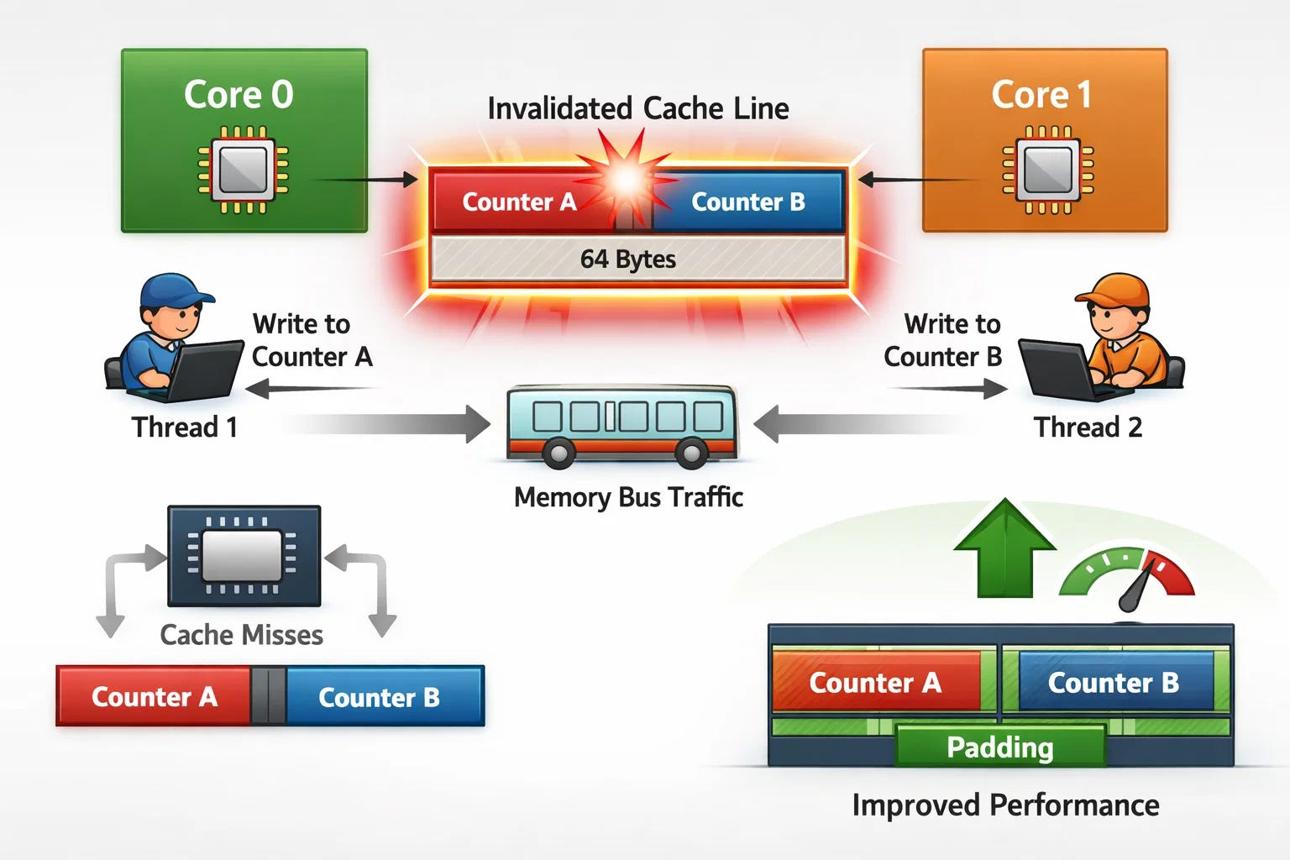
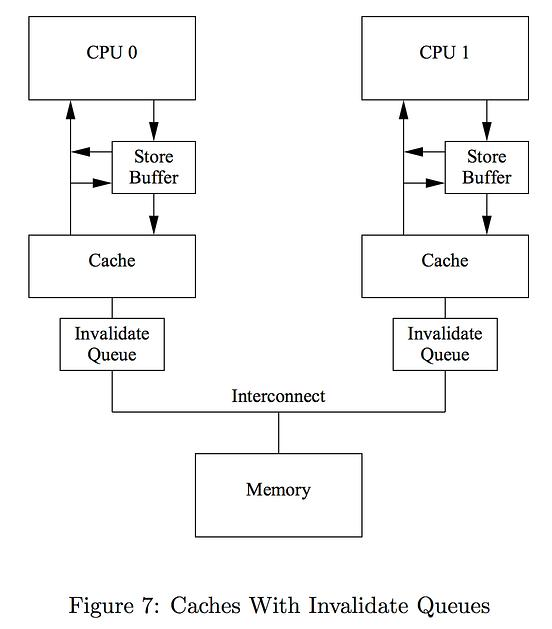
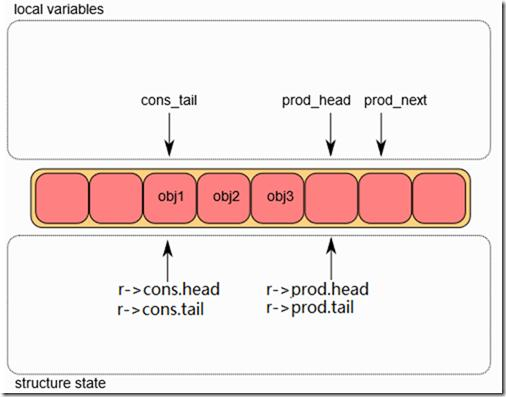
四、缓存一致性风暴出现
进一步观察:
perf c2c结果显示:
rte_ring_prod_tail
rte_ring_cons_head大量Cache Line Bounce。
原因:多个Core同时访问Ring。
例如:
Dispatcher
↓
Worker0
Dispatcher
↓
Worker1
Dispatcher
↓
Worker2Dispatcher不断修改:
prod_tailWorker不断修改:
cons_head导致:
Core0 Cache
↓
Invalidate
↓
Core3 Cache
↓
Invalidate
↓
Core0 Cache形成缓存乒乓。
如下图:
此时CPU利用率看起来不高。
但实际上大量周期浪费在:
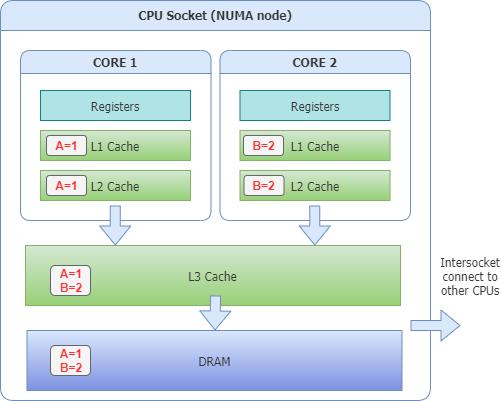
MESI协议同步五、NUMA问题浮出水面
继续检查:
dpdk-proc-info发现:
网卡:
NUMA Node 0
Worker:
NUMA Node 1即:
NIC --> Socket0
Worker --> Socket1每个数据包都发生:
PCIe DMA
↓
Socket0 Memory
↓
QPI/UPI
↓
Socket1 CPU跨NUMA访问。
现代双路服务器:
本地访问:80ns
跨路访问:150~200ns看似只差100ns。
但:
100Mpps情况下:
影响极其巨大。
六、真正的问题:线程模型设计错误
经过分析发现:
系统采用的是:
RX
↓
Dispatcher
↓
Worker
↓
TX四阶段流水线。
这种设计来自传统软件架构思想:
模块解耦
职责分离但在100G数据面场景下:
这是错误的。
因为每经过一个阶段:
都会产生:
Ring切换
Cache失效
Core迁移例如:
RX Core
↓
Worker Core
↓
TX Core数据包生命周期中:
同一个mbuf被多个CPU访问。
缓存命中率急剧下降。
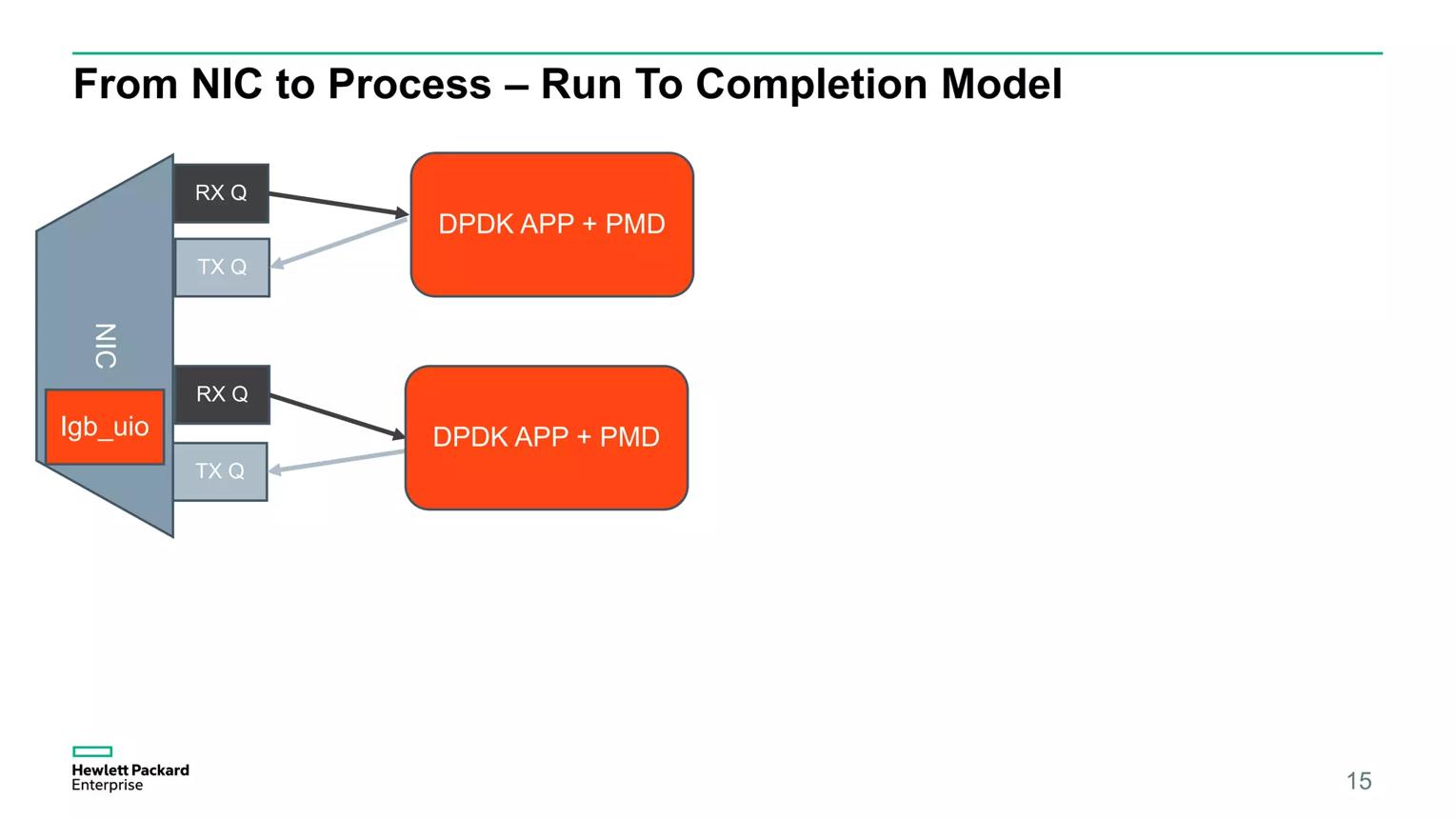
七、现代高性能网关的设计原则
真正高性能的架构:
RX Queue0 → Core0 → TX Queue0
RX Queue1 → Core1 → TX Queue1
RX Queue2 → Core2 → TX Queue2如下:
即:
Run-To-Completion模型。
特点:
一个包只属于一个CPU
RX
处理
转发
TX全部在同一个Core完成。
避免:
Ring
Lock
Cache Bounce八、为什么VPP性能高
VPP采用:
Vector Processing思想。
不是:
1包处理一次而是:
32包
64包
128包一起处理。
例如:
while(nb)
{
prefetch(pkt[i+4]);
process(pkt[i]);
}CPU执行过程:
Load
Load
Load
Load
Compute
Compute
Compute形成流水线。
减少:
Cache Miss
Branch Miss现代CPU最怕:
等待内存而不是计算。
九、重新设计UPF数据面
经过重构后:
采用:
RSS
↓
N3 Worker
↓
F-TEID Hash
↓
PDR/FAR
↓
N6 TX原则:
原则1
Dispatcher只做最轻量工作
解析TEID
计算Worker禁止:
PDR查找
业务逻辑原则2
Session固定归属Worker
TEID % WorkerNum保证:
同一UE
同一CPU避免状态同步。
原则3
NUMA绑定
--socket-mem=4096,4096Worker与网卡同NUMA。
原则4
批处理
rte_eth_rx_burst()每次:
32~64包一起处理。
原则5
避免跨线程Ring
能不用:
rte_ring就不用。
因为:
一次Ring
≈几十到上百CPU Cycle100Mpps下代价巨大。
十、优化结果
优化前:
| 指标 | 数值 |
|---|---|
| PPS | 22M |
| Throughput | 15Gbps |
优化后:
| 指标 | 数值 |
|---|---|
| PPS | 128M |
| Throughput | 86Gbps |
继续优化:
- Hugepage布局
- NUMA亲和
- Prefetch
- SIMD
最终达到:
95~98Gbps接近线速。
十一、高性能网关架构设计的本质
很多开发者认为:
性能 = 算法实际上在100G时代:
真正决定性能的往往不是算法。
而是:
缓存命中率
NUMA访问
线程模型
数据流向一个Hash查找可能只需要:
20ns但一次跨NUMA访问可能需要:
200ns一个业务逻辑可能只占:
10%而线程间Ring切换可能占:
50%因此,高性能网关设计最重要的一条原则是:不要让数据包在CPU之间旅行,而要让CPU拥有数据包。
当系统达到100Gbps甚至200Gbps时,决定性能上限的已经不再是代码是否优雅,而是缓存、NUMA和线程模型是否符合现代CPU架构。真正优秀的数据面设计,往往不是增加更多线程,而是减少数据包在不同线程之间的流动次数,让一次缓存加载产生最大的价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)