R语言KKNN算法
·
# ====================== 1. 安装并加载需要的包 ======================
# 如果没装过,先运行下面这行(只装一次)
# install.packages("kknn")
# install.packages("ggplot2")
# install.packages("caret")
library(kknn) # 加权K近邻算法
library(ggplot2) # 可视化
library(caret) # 数据划分、评估
# ====================== 2. 查看并探索 iris 数据 ======================
data(iris) # 加载经典鸢尾花数据集
str(iris) # 查看数据结构:4个特征 + 1个分类标签Species
head(iris) # 查看前5行
# 查看类别分布(3种花)
table(iris$Species)
# ====================== 3. 数据可视化:观察数据分布 ======================
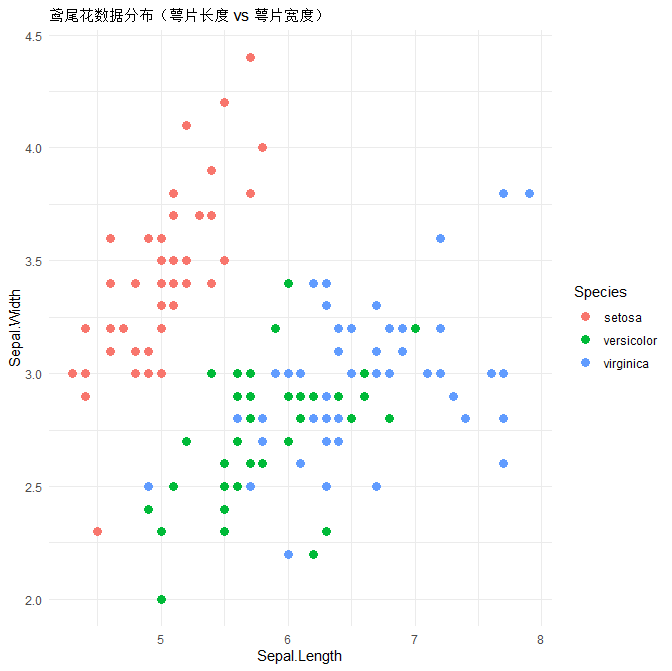
# 用前两个特征画散点图(颜色=品种)
ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Species)) +
geom_point(size = 3) +
ggtitle("鸢尾花数据分布(萼片长度 vs 萼片宽度)") +
theme_minimal()
1、训练模型
# ====================== 4. 划分训练集 / 测试集 ======================
set.seed(123) # 固定随机种子,结果可复现
# 70%训练,30%测试
trainIndex <- createDataPartition(iris$Species, p = 0.7, list = FALSE)
train <- iris[trainIndex, ] # 训练集
test <- iris[-trainIndex, ] # 测试集
# ====================== 5. 使用 kknn 训练加权K近邻模型 ======================
# formula: 品种 ~ . (用所有特征预测品种)
# train = 训练集,test = 测试集
# k = 近邻数(常用5~15)
# kernel = 加权方式("optimal"最优加权)
model_kknn <- kknn(
formula = Species ~ .,
train = train,
test = test,
k = 5, # 选5个近邻
kernel = "optimal" # 加权核函数
)
# 查看模型预测结果
pred <- model_kknn$fitted.values # 模型预测的标签
head(pred) # 前5个预测结果2、模型评估
# ====================== 6. 模型评估:准确率 + 混淆矩阵 ======================
cat("======== 模型准确率 ========\n")
acc <- sum(pred == test$Species) / nrow(test)
cat("测试集准确率 =", round(acc * 100, 2), "%\n\n")
# 混淆矩阵
cat("======== 混淆矩阵 ========\n")
cm <- table(真实=test$Species, 预测=pred)
print(cm)测试集准确率 = 93.33 %
预测
真实 setosa versicolor virginica
setosa 15 0 0
versicolor 0 14 1
virginica 0 2 13
3、可视化预测结果
# ====================== 7. 结果可视化:预测正确 vs 错误 ======================
# 给测试集增加一列:是否预测正确
test$预测结果 <- ifelse(test$Species == pred, "正确", "错误")
# 画图:颜色=真实品种,形状=预测是否正确
ggplot(test, aes(Sepal.Length, Sepal.Width, color = Species, shape = 预测结果)) +
geom_point(size = 4, stroke = 1.2) +
ggtitle("kknn 模型预测结果(三角形=预测错误)") +
scale_shape_manual(values = c(19, 17)) + # 圆形=正确,三角形=错误
theme_minimal()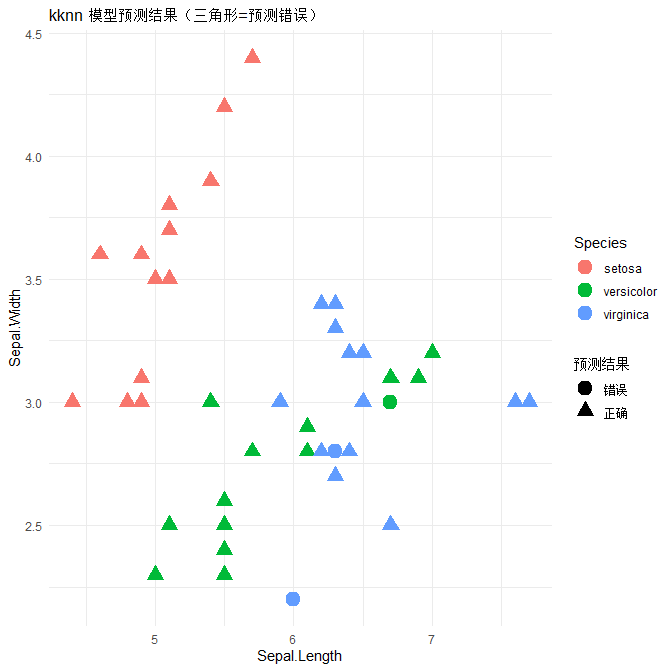
4、自动寻优
# ====================== 8. 寻找最优K值(自动搜索) ======================
# 尝试K=1~30,看哪个准确率最高
k_values <- 1:30
acc_list <- c()
for (k in k_values) {
fit <- kknn(Species ~ ., train, test, k = k, kernel = "optimal")
acc <- sum(fit$fitted.values == test$Species) / nrow(test)
acc_list <- c(acc_list, acc)
}
# 画K值与准确率关系图
ggplot(data.frame(K=k_values, 准确率=acc_list), aes(K, 准确率)) +
geom_line(color="blue", linewidth=1) +
geom_point(size=2) +
ggtitle("不同K值对 kknn 模型准确率的影响") +
theme_minimal()
# 输出最优K
best_k <- k_values[which.max(acc_list)]
cat("\n最优K值 =", best_k, "\n")
cat("最优K下准确率 =", round(max(acc_list)*100,2), "%\n")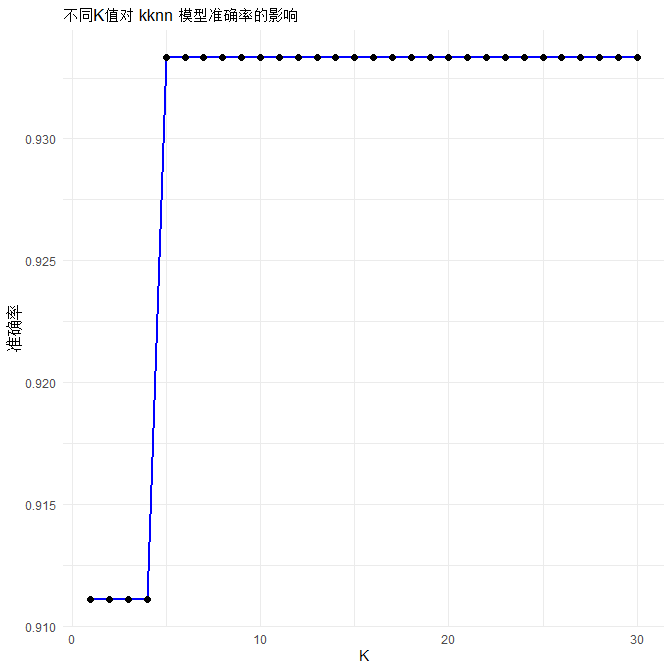
最优K值 = 5
最优K下准确率 = 93.33

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)