用python (fastapi)做项目第一天创建项目结构,数据建表,ORM配置安装,写第一个接口
根据项目结构创建项目

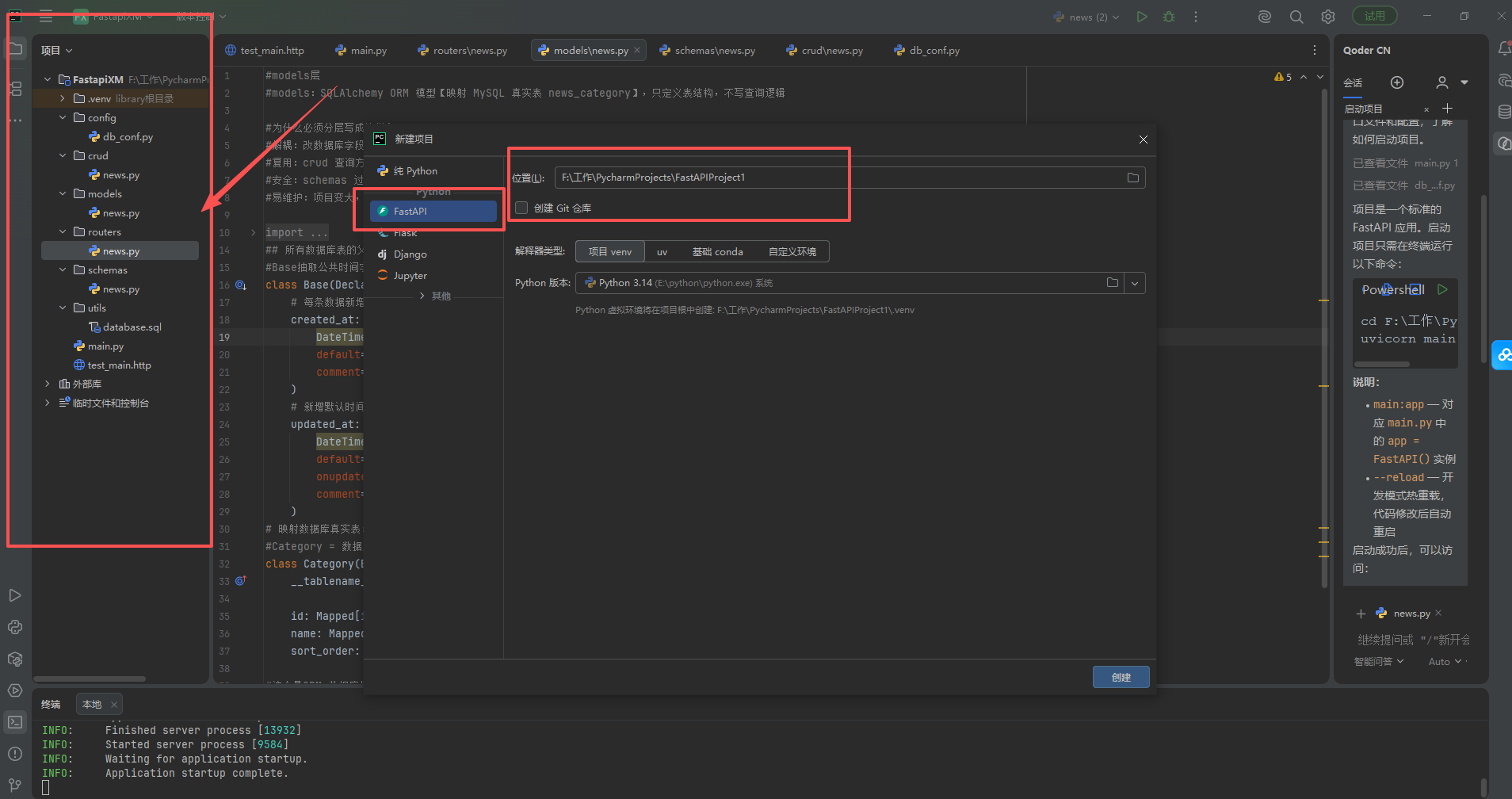
创建模块化路由
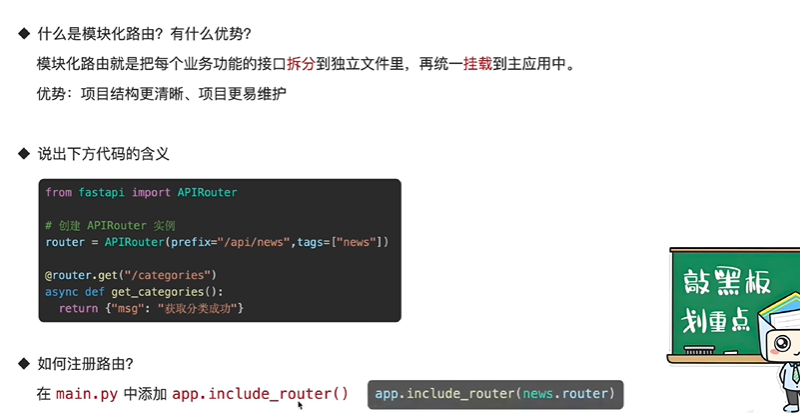
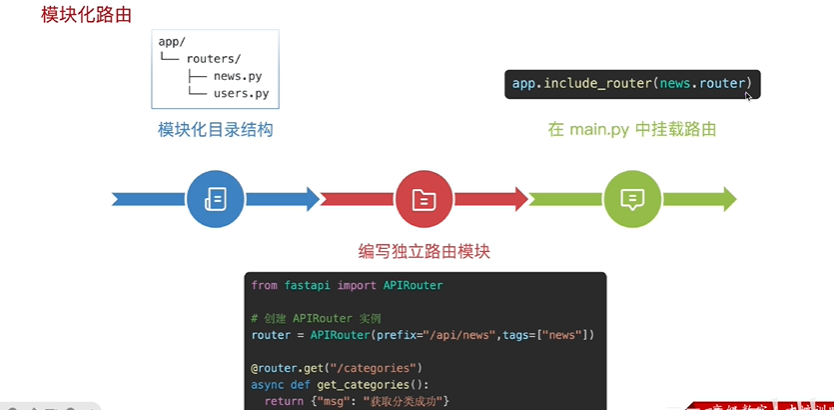
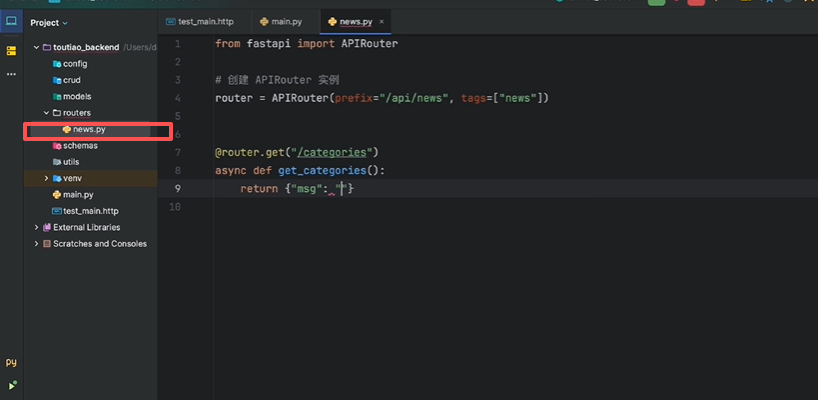
routers/news.py 文件
from fastapi import APIRouter
# 创建 APIRouter 实例
router = APIRouter(prefix="/api/news", tags=["news"])
@router.get("/categories")
async def get_categories():
return {"msg": "Categories fetched"}
挂载路由
在main.py中挂在刚创建的news.py路由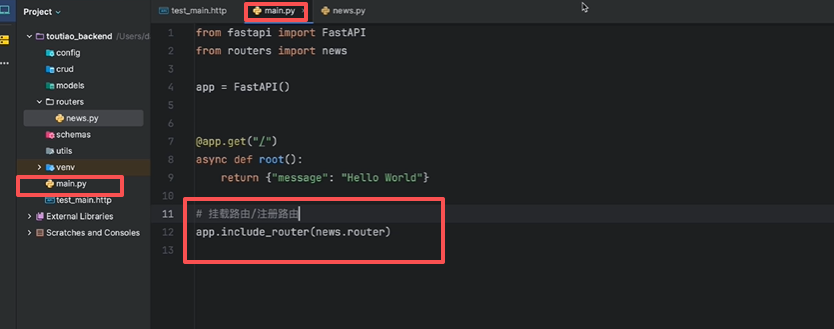
main.py文件代码
from fastapi import FastAPI
from routers import news
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
# 注册路由
app.include_router(news.router)
项目中数据库建表和ORM配置安装
数据库建表
下载本项目建表SQL(自己的项目自己去写SQL建表文件不用下载)
点击下载本项目建表SQL
链接: 提取码: ylda
运行SQL建表
第一种方式在pyCharm中导入Sql文件建表,
链接数据库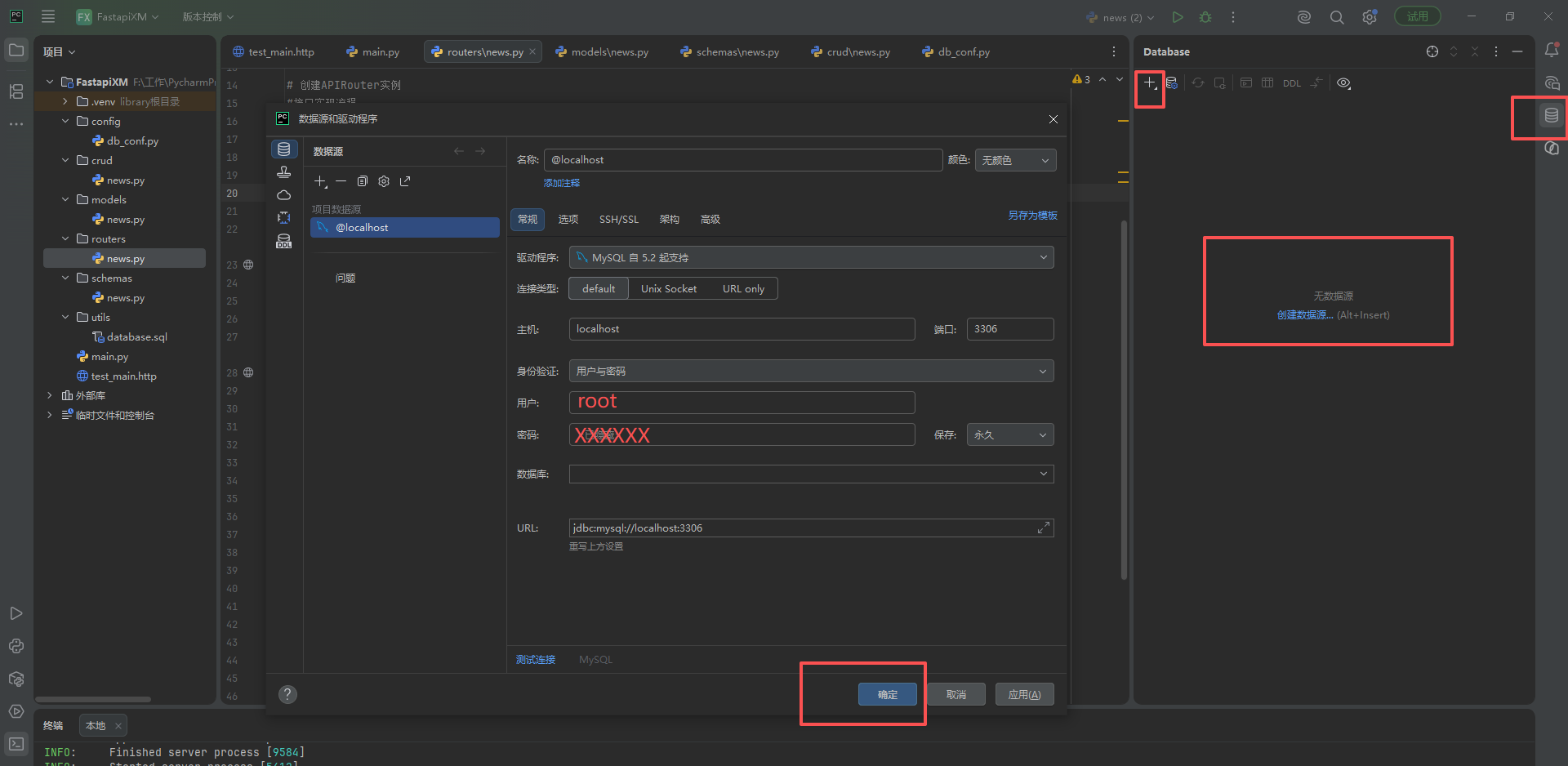
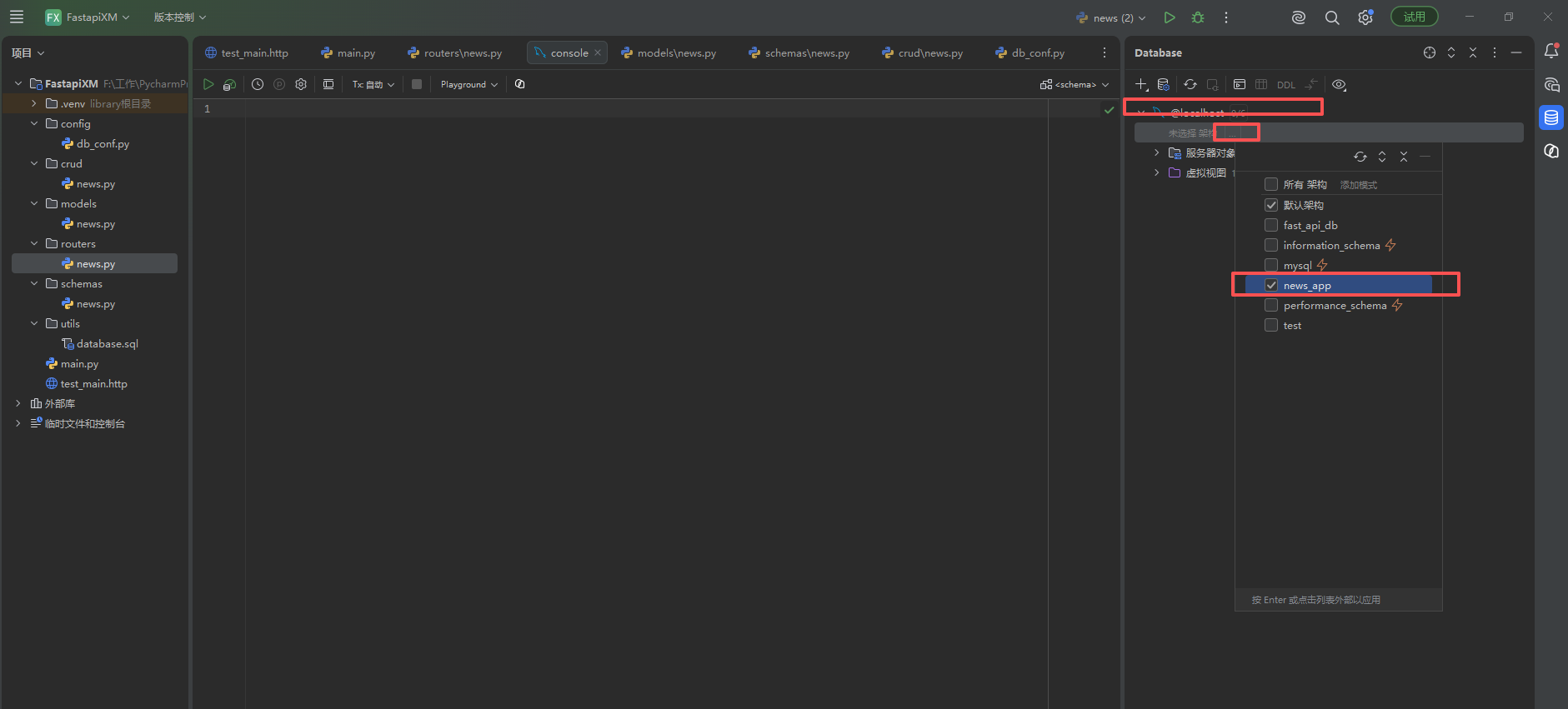
运行SQL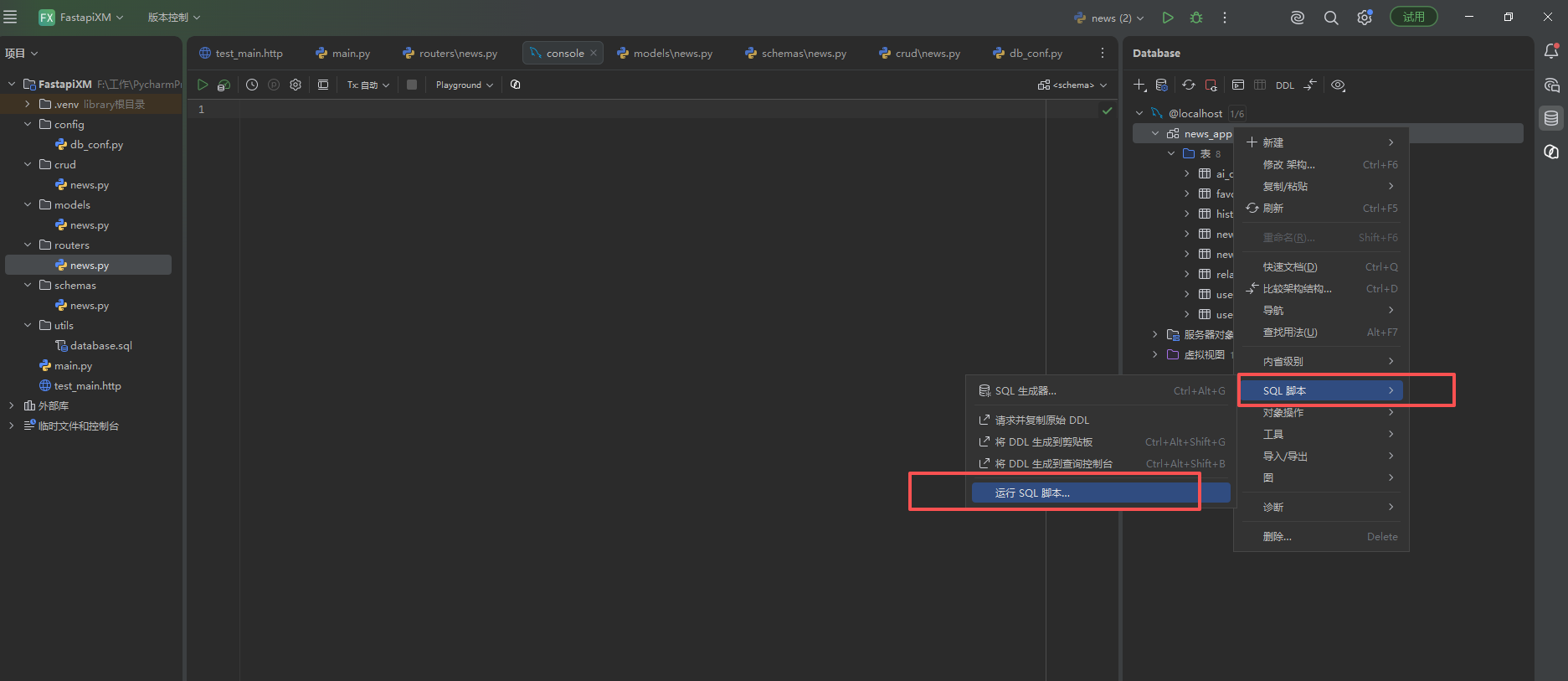
第二种方式在Navicat中导入Sql文件建表,
因为我自己的SQL中写入了建news_app库的语句,所有不用手动在Navicat创建news_app库。直接在MYSQL中运行sqL文件就行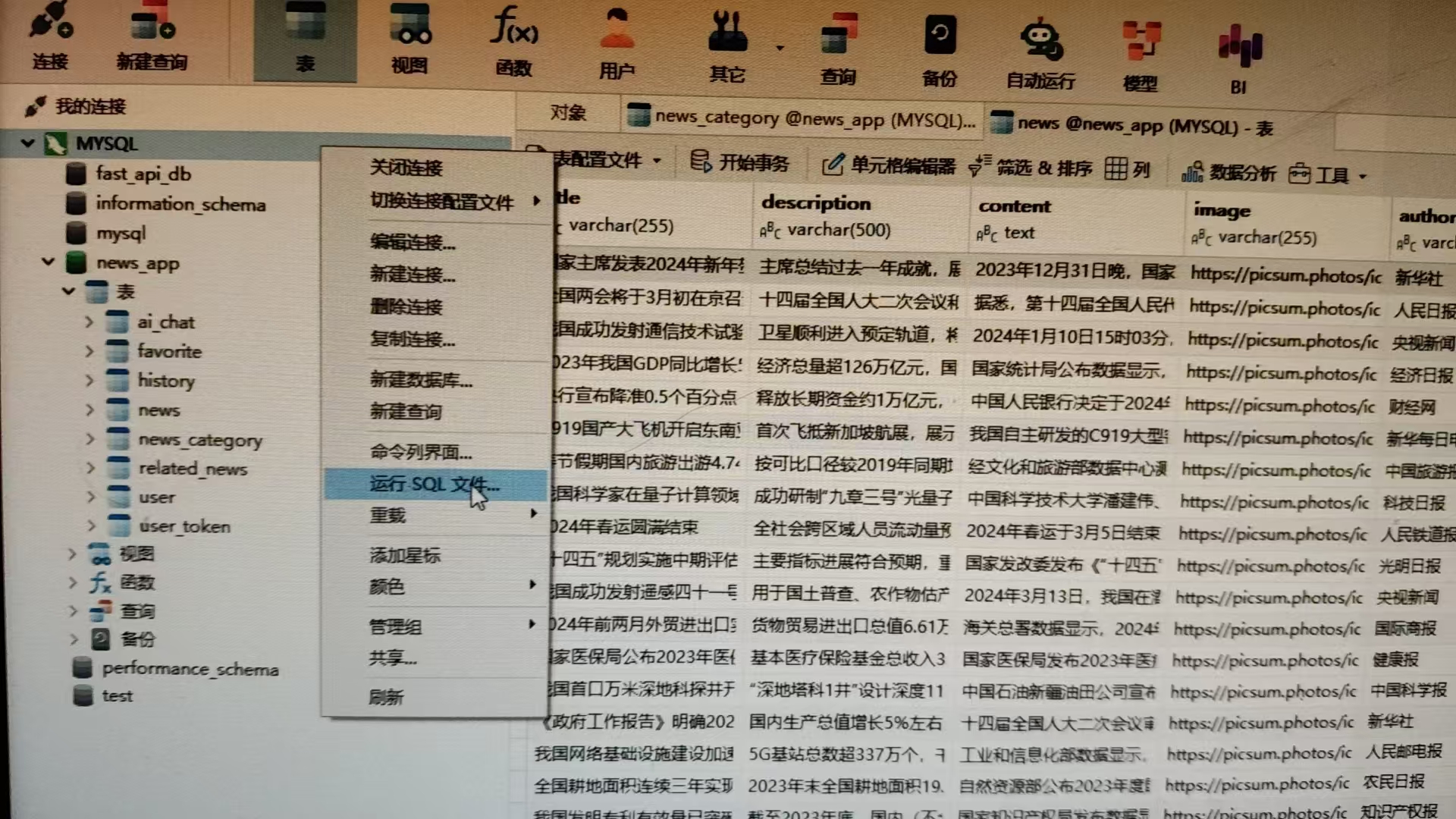
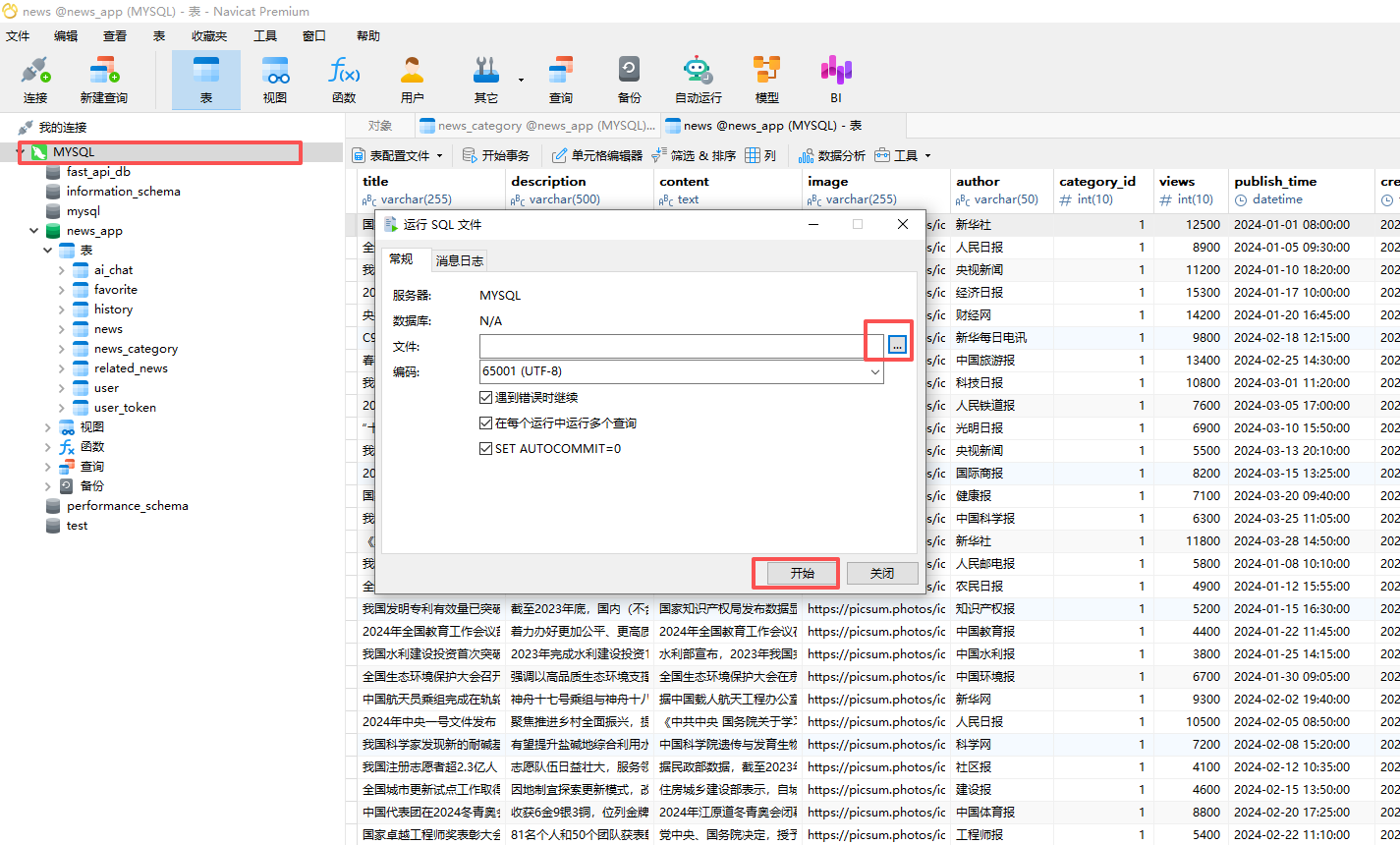
运行完后就创建成功了(让AI写自己项目中的SQL建表文件 。如果运行操作,一般是数据库版本的问题,让AI给你修改成你自己数据库版本的sql语句)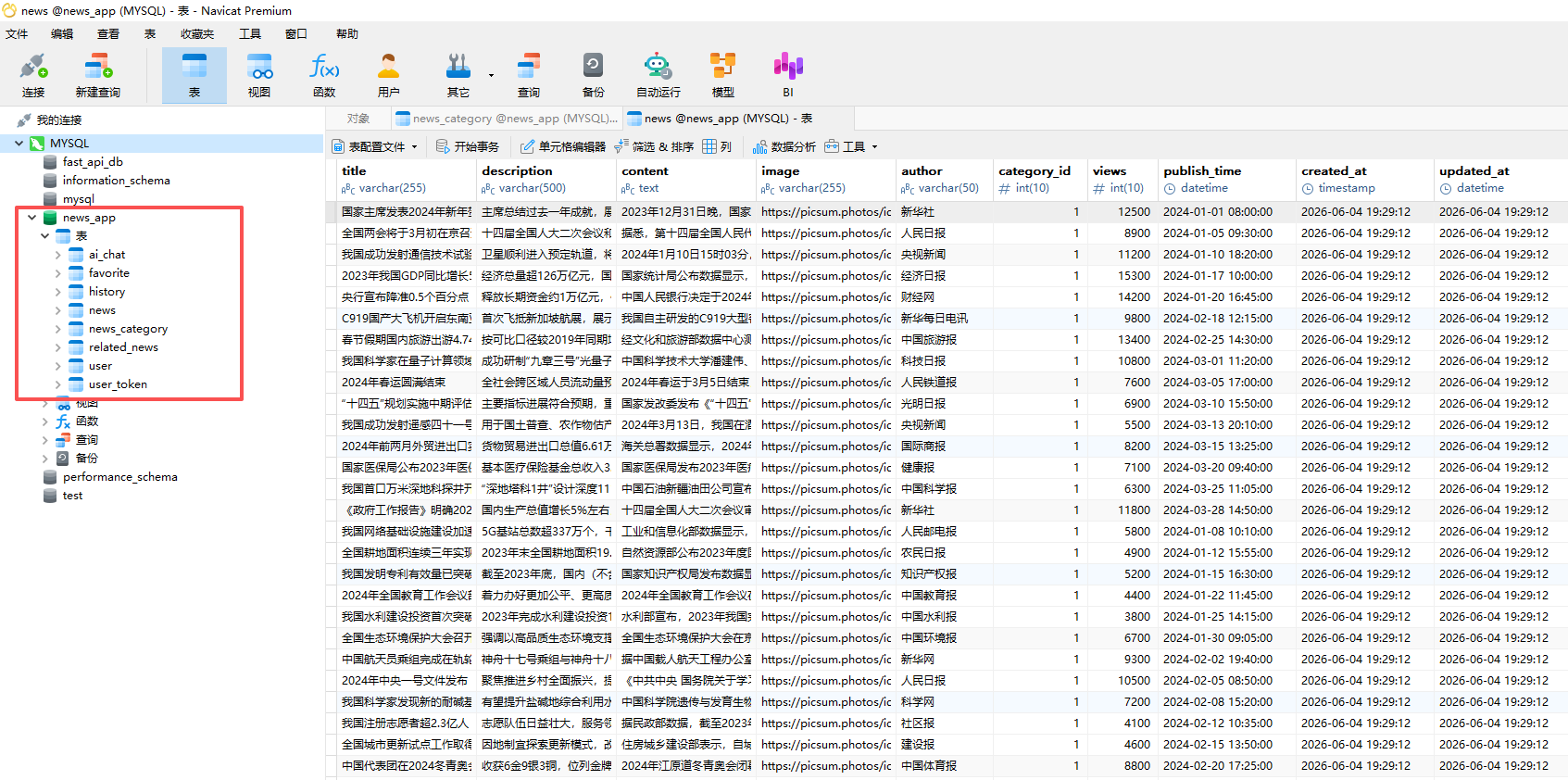
ORM配置安装
项目中安装ORM
加引号或者不加都行,如果不加引号安装报错就用加引号的
pip install sqlalchemy[asyncio] aiomysql
pip install 'sqlalchemy[asyncio]' aiomysql
我的项目一定安装过了
正确的安装成功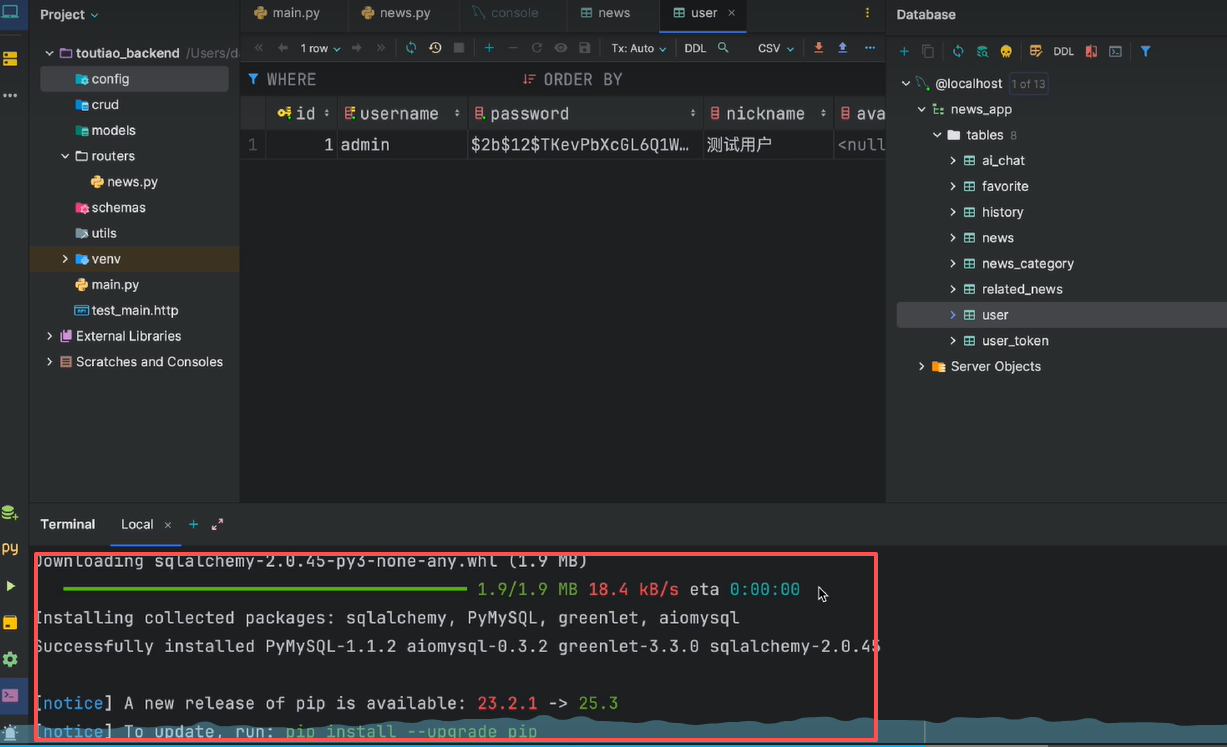
项目配置ORM
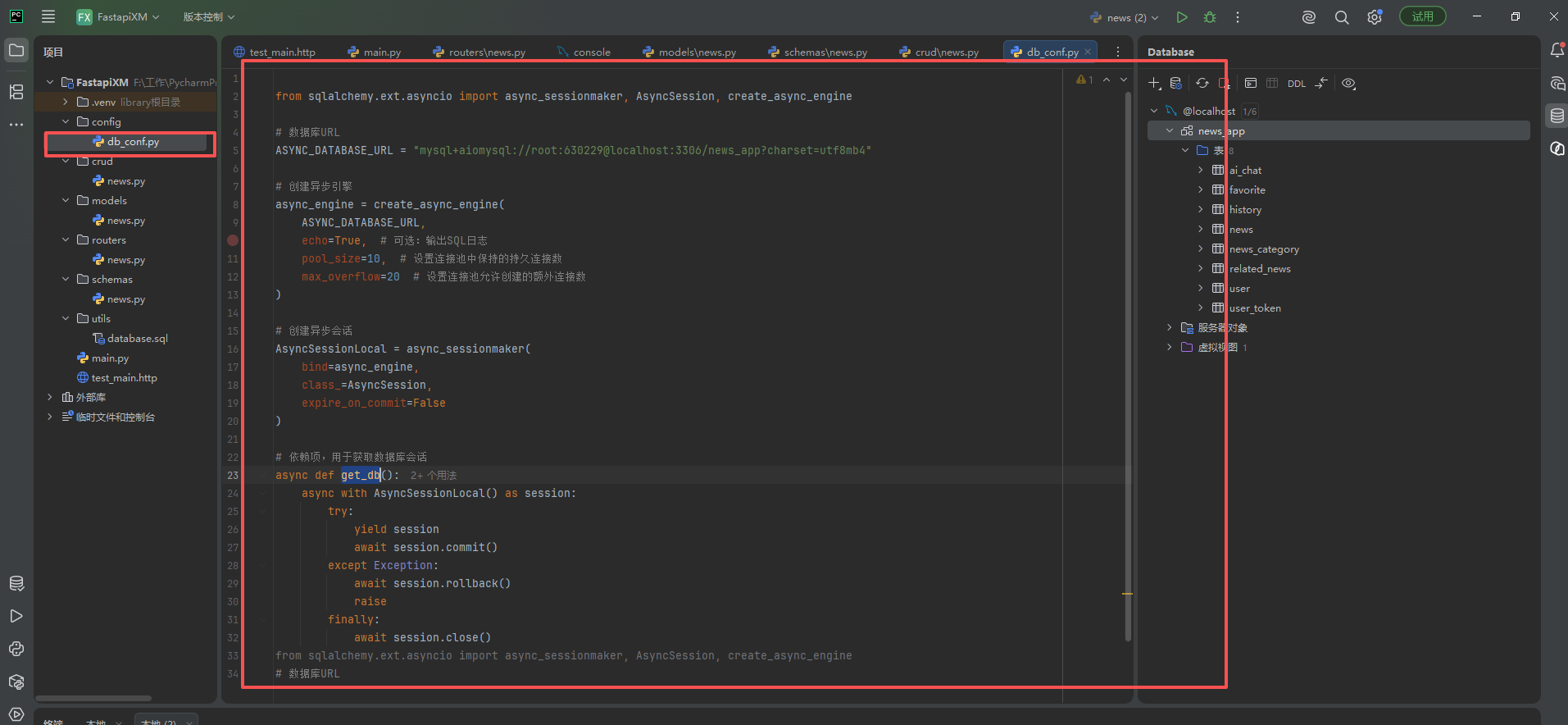
代码如下
ASYNC_DATABASE_URL为数据库url
root:630229 为数据库用户名和密码改成自己的
news_app:为数据库名称改成自己的
from sqlalchemy.ext.asyncio import async_sessionmaker, AsyncSession, create_async_engine
# 数据库URL
ASYNC_DATABASE_URL = "mysql+aiomysql://root:630229@localhost:3306/news_app?charset=utf8mb4"
# 创建异步引擎
async_engine = create_async_engine(
ASYNC_DATABASE_URL,
echo=True, # 可选:输出SQL日志
pool_size=10, # 设置连接池中保持的持久连接数
max_overflow=20 # 设置连接池允许创建的额外连接数
)
# 创建异步会话
AsyncSessionLocal = async_sessionmaker(
bind=async_engine,
class_=AsyncSession,
expire_on_commit=False
)
# 依赖项,用于获取数据库会话
async def get_db():
async with AsyncSessionLocal() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
完成以上操作基本环境和配置就完成了,。接下来咱们一起写第一个接口吧
接口实现流程

咱们写一个新闻分类接口先看接口文档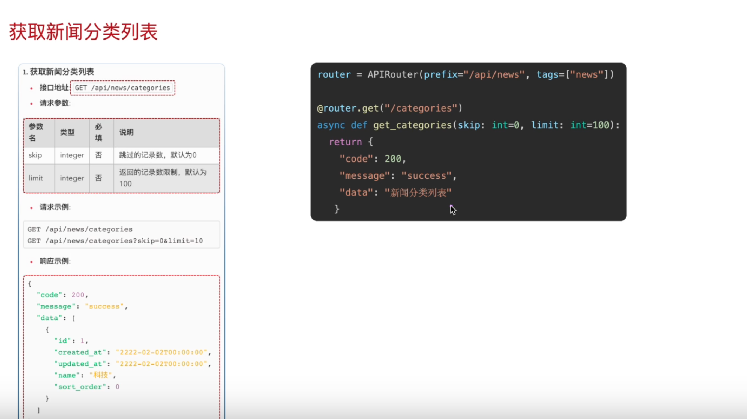
定义路由
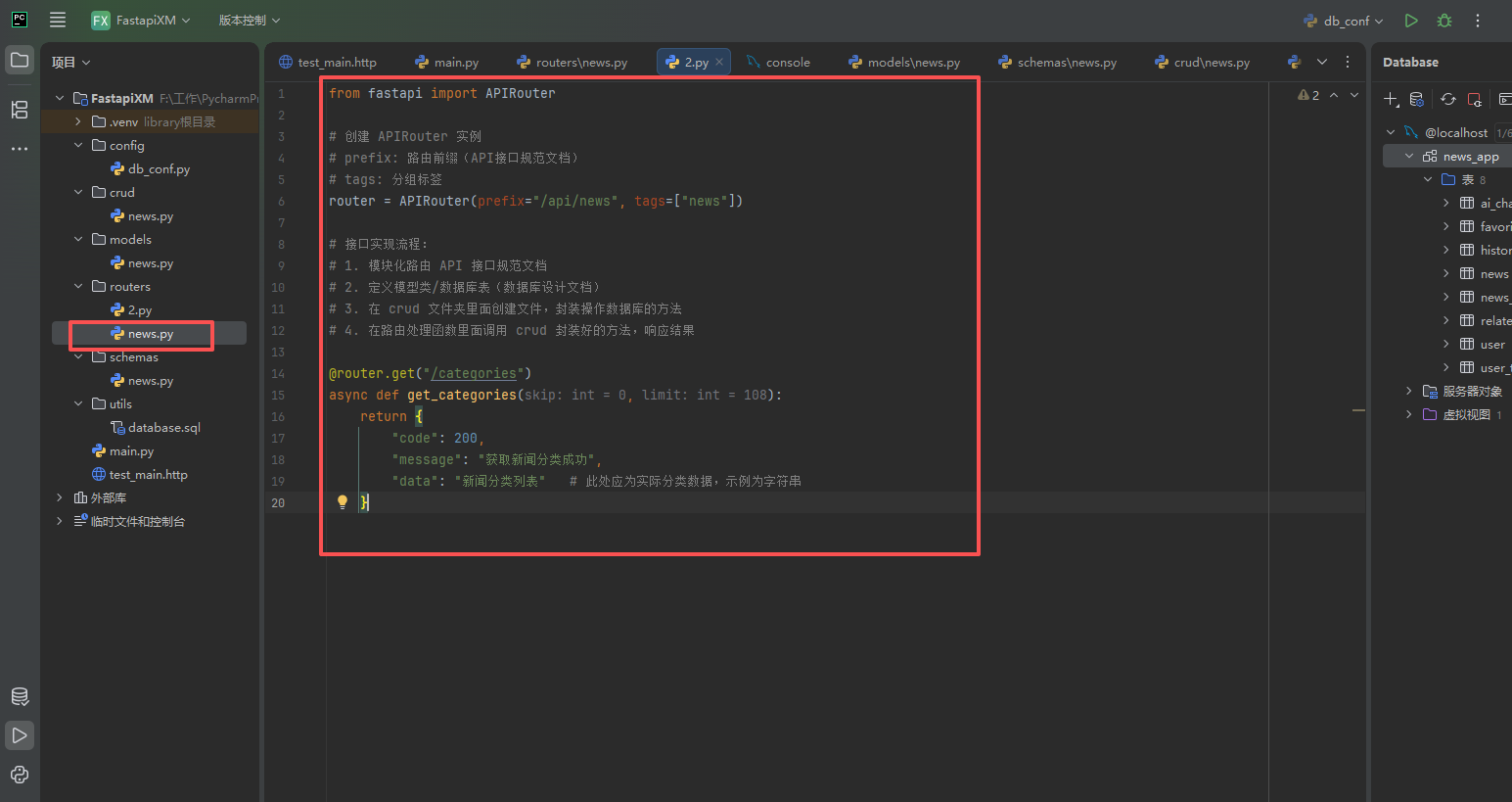
routers/news.py文件
from fastapi import APIRouter
# 创建 APIRouter 实例
# prefix: 路由前缀(API接口规范文档)
# tags: 分组标签
router = APIRouter(prefix="/api/news", tags=["news"])
# 接口实现流程:
# 1. 模块化路由 API 接口规范文档
# 2. 定义模型类/数据库表(数据库设计文档)
# 3. 在 crud 文件夹里面创建文件,封装操作数据库的方法
# 4. 在路由处理函数里面调用 crud 封装好的方法,响应结果
@router.get("/categories")
async def get_categories(skip: int = 0, limit: int = 108):
#先获取数据库里面新闻分类数据 >先定义模型类>封装查询数据的方法
return {
"code": 200,
"message": "获取新闻分类成功",
"data": "新闻分类列表" # 此处应为实际分类数据,示例为字符串
}
定义模型类(模型类必须参考当前数据库的表)一一对应
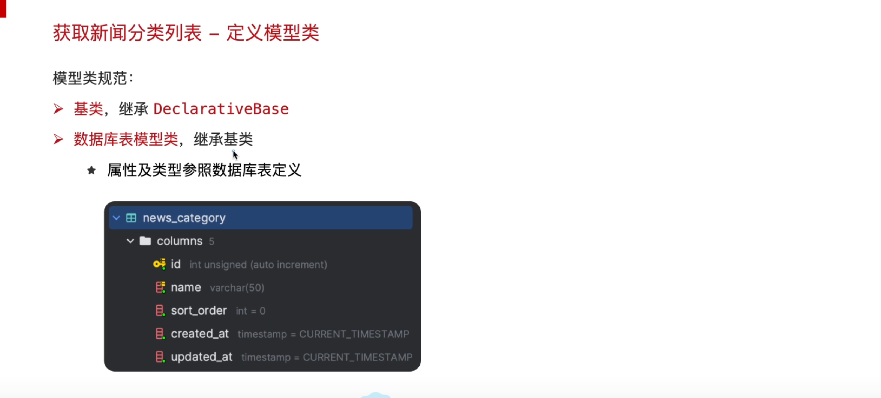
在modes/news.py中创建模型类。注意模型类必须参考数据库表一一对应上
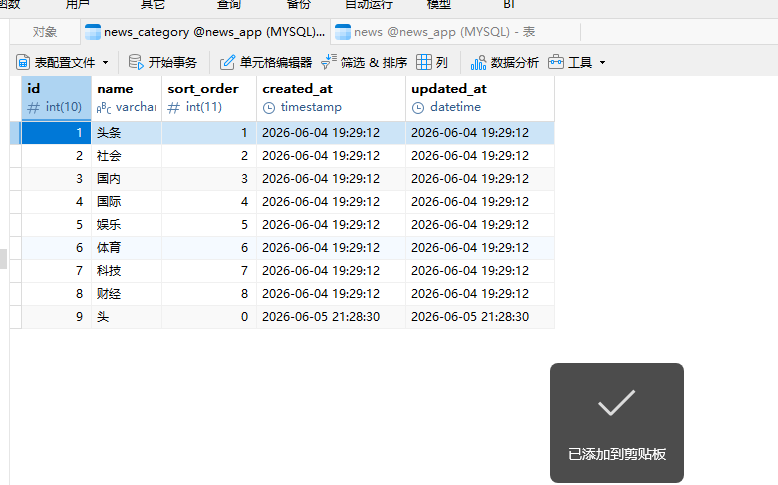
根据表创建模型类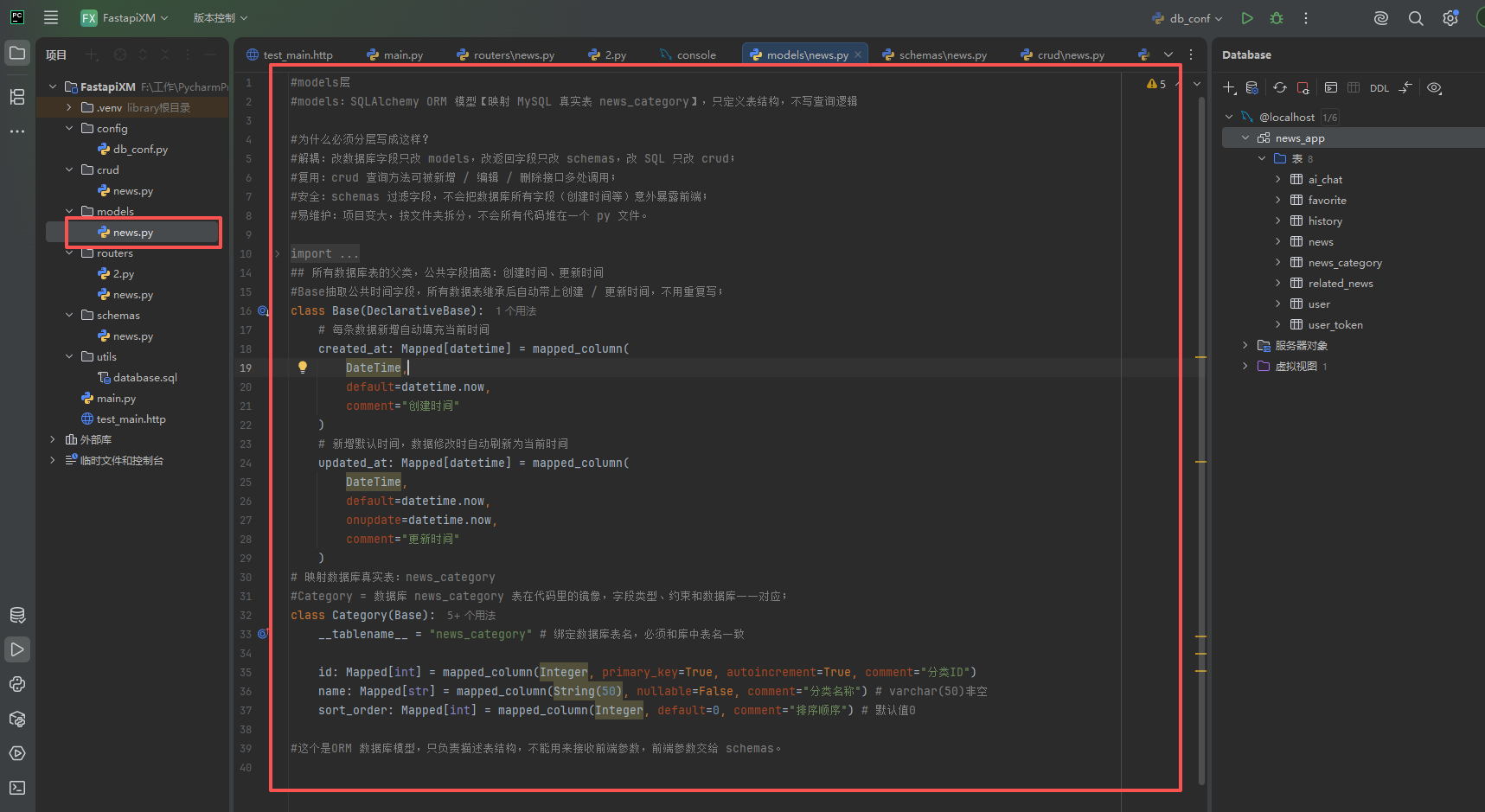
modes/news.py文件代码
#models层
#models:SQLAlchemy ORM 模型【映射 MySQL 真实表 news_category】,只定义表结构,不写查询逻辑
#为什么必须分层写成这样?
#解耦:改数据库字段只改 models,改返回字段只改 schemas,改 SQL 只改 crud;
#复用:crud 查询方法可被新增 / 编辑 / 删除接口多处调用;
#安全:schemas 过滤字段,不会把数据库所有字段(创建时间等)意外暴露前端;
#易维护:项目变大,按文件夹拆分,不会所有代码堆在一个 py 文件。
from datetime import datetime
from sqlalchemy import DateTime, String, Integer
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
## 所有数据库表的父类,公共字段抽离:创建时间、更新时间
#Base抽取公共时间字段,所有数据表继承后自动带上创建 / 更新时间,不用重复写;
class Base(DeclarativeBase):
# 每条数据新增自动填充当前时间
created_at: Mapped[datetime] = mapped_column(
DateTime,
default=datetime.now,
comment="创建时间"
)
# 新增默认时间,数据修改时自动刷新为当前时间
updated_at: Mapped[datetime] = mapped_column(
DateTime,
default=datetime.now,
onupdate=datetime.now,
comment="更新时间"
)
# 映射数据库真实表:news_category
#Category = 数据库 news_category 表在代码里的镜像,字段类型、约束和数据库一一对应;
class Category(Base):
__tablename__ = "news_category" # 绑定数据库表名,必须和库中表名一致
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True, comment="分类ID")
name: Mapped[str] = mapped_column(String(50), nullable=False, comment="分类名称") # varchar(50)非空
sort_order: Mapped[int] = mapped_column(Integer, default=0, comment="排序顺序") # 默认值0
#这个是ORM 数据库模型,只负责描述表结构,不能用来接收前端参数,前端参数交给 schemas。
分装数据库查询方法
crud文件夹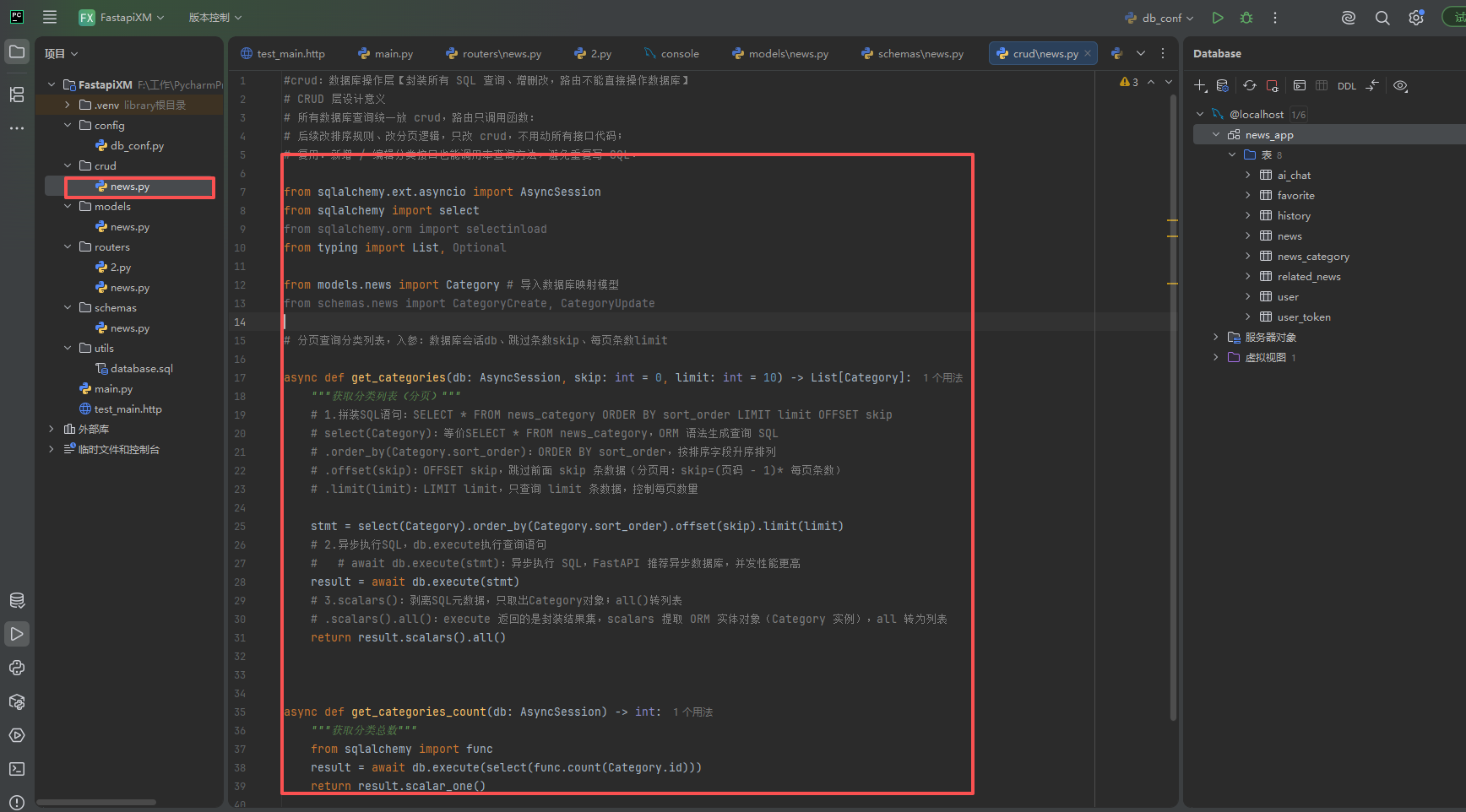
#crud:数据库操作层【封装所有 SQL 查询、增删改,路由不能直接操作数据库】
# CRUD 层设计意义
# 所有数据库查询统一放 crud,路由只调用函数:
# 后续改排序规则、改分页逻辑,只改 crud,不用动所有接口代码;
# 复用:新增 / 编辑分类接口也能调用本查询方法,避免重复写 SQL。
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy import select
from sqlalchemy.orm import selectinload
from typing import List, Optional
from models.news import Category # 导入数据库映射模型
from schemas.news import CategoryCreate, CategoryUpdate
# 分页查询分类列表,入参:数据库会话db、跳过条数skip、每页条数limit
async def get_categories(db: AsyncSession, skip: int = 0, limit: int = 10) -> List[Category]:
"""获取分类列表(分页)"""
# 1.拼装SQL语句:SELECT * FROM news_category ORDER BY sort_order LIMIT limit OFFSET skip
# select(Category):等价SELECT * FROM news_category,ORM 语法生成查询 SQL
# .order_by(Category.sort_order):ORDER BY sort_order,按排序字段升序排列
# .offset(skip):OFFSET skip,跳过前面 skip 条数据(分页用:skip=(页码 - 1)* 每页条数)
# .limit(limit):LIMIT limit,只查询 limit 条数据,控制每页数量
stmt = select(Category).order_by(Category.sort_order).offset(skip).limit(limit)
# 2.异步执行SQL,db.execute执行查询语句
# # await db.execute(stmt):异步执行 SQL,FastAPI 推荐异步数据库,并发性能更高
result = await db.execute(stmt)
# 3.scalars():剥离SQL元数据,只取出Category对象;all()转列表
# .scalars().all():execute 返回的是封装结果集,scalars 提取 ORM 实体对象(Category 实例),all 转为列表
return result.scalars().all()
async def get_categories_count(db: AsyncSession) -> int:
"""获取分类总数"""
from sqlalchemy import func
result = await db.execute(select(func.count(Category.id)))
return result.scalar_one()
在routers/news.py中调用crud中分装的查询方法get_categories()
、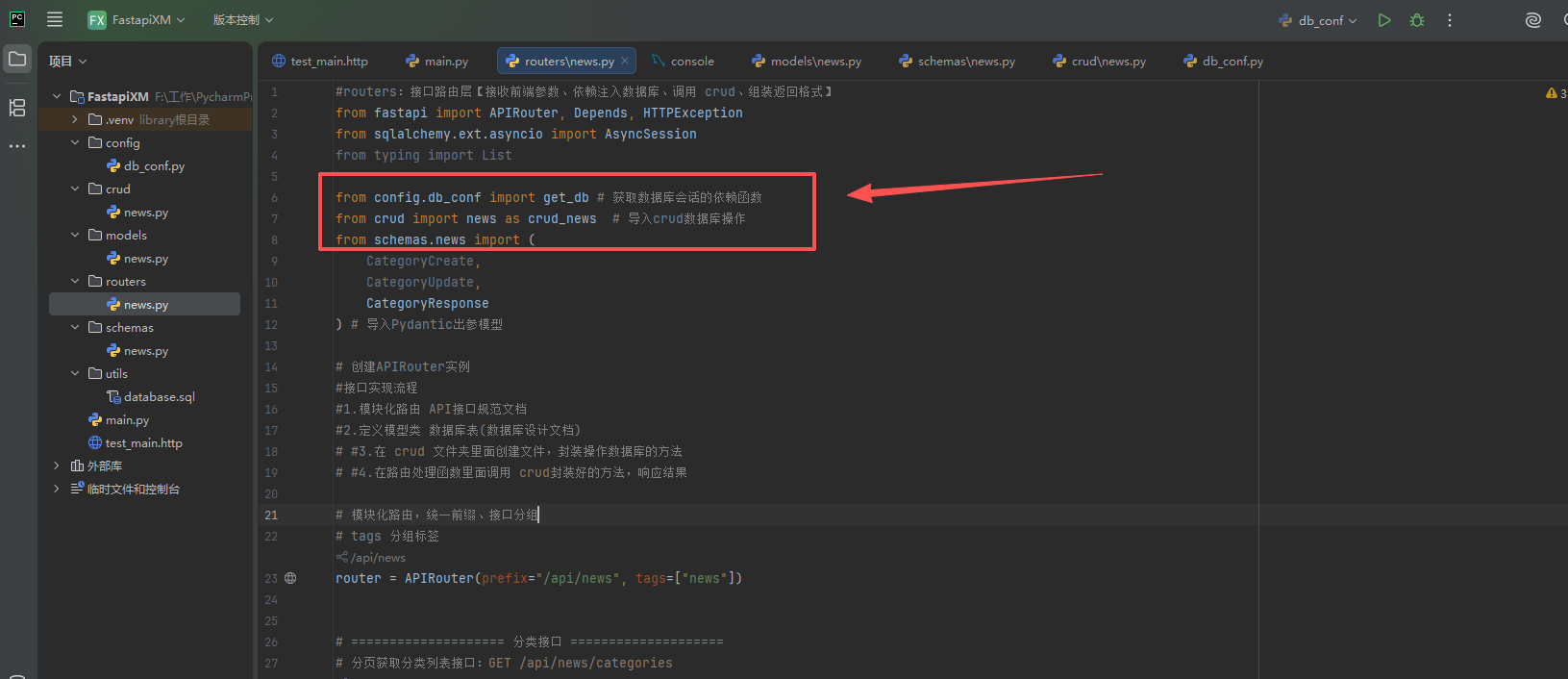
#routers:接口路由层【接收前端参数、依赖注入数据库、调用 crud、组装返回格式】
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.ext.asyncio import AsyncSession
from typing import List
from config.db_conf import get_db # 获取数据库会话的依赖函数
from crud import news as crud_news # 导入crud数据库操作
from schemas.news import (
CategoryCreate,
CategoryUpdate,
CategoryResponse
) # 导入Pydantic出参模型
# 创建APIRouter实例
#接口实现流程
#1.模块化路由 API接口规范文档
#2.定义模型类 数据库表(数据库设计文档)
# #3.在 crud 文件夹里面创建文件,封装操作数据库的方法
# #4.在路由处理函数里面调用 crud封装好的方法,响应结果
# 模块化路由,统一前缀、接口分组
# tags 分组标签
router = APIRouter(prefix="/api/news", tags=["news"])
# ==================== 分类接口 ====================
# 分页获取分类列表接口:GET /api/news/categories
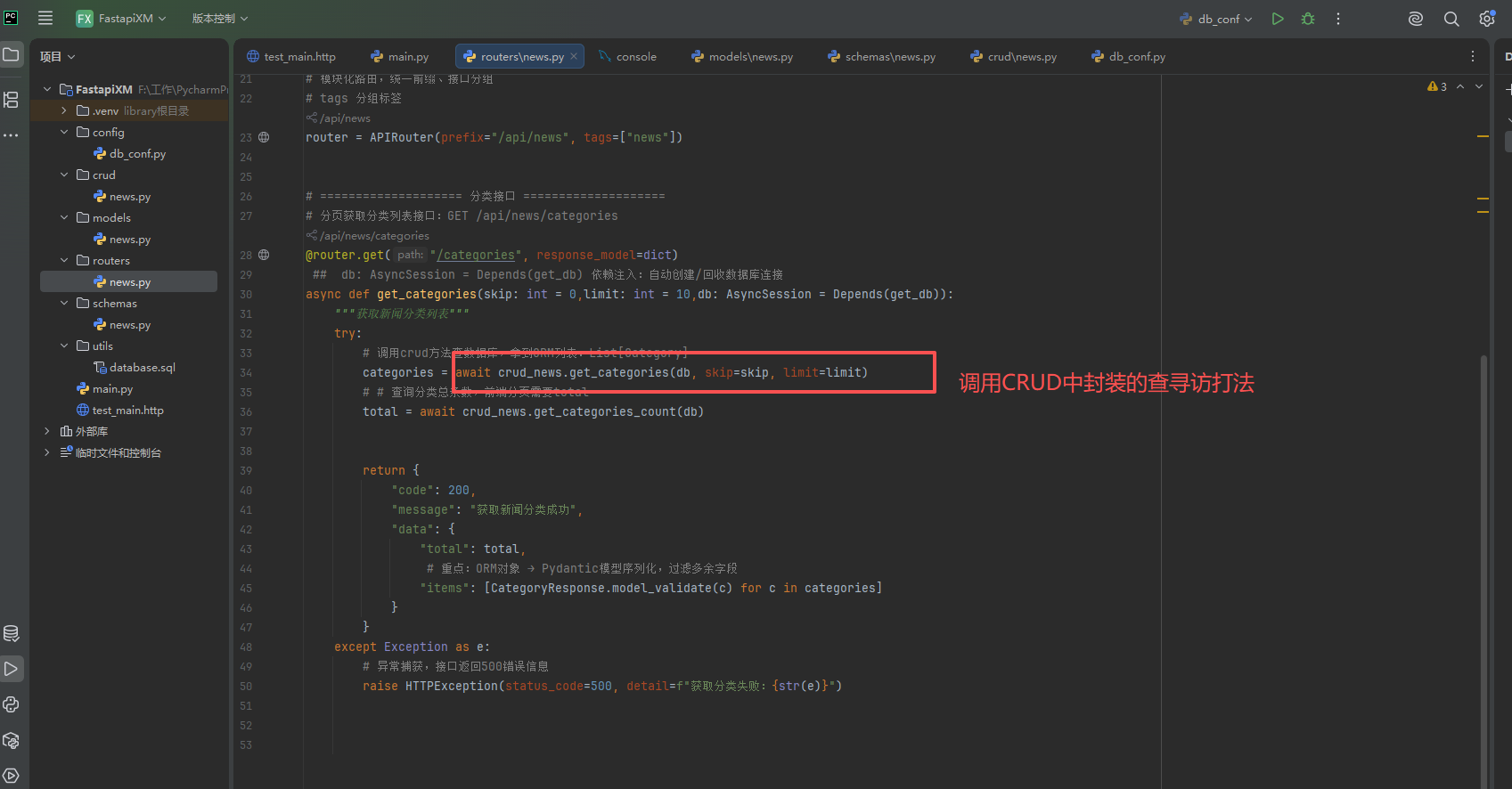
@router.get("/categories", response_model=dict)
## db: AsyncSession = Depends(get_db) 依赖注入:自动创建/回收数据库连接
async def get_categories(skip: int = 0,limit: int = 10,db: AsyncSession = Depends(get_db)):
"""获取新闻分类列表"""
try:
# 调用crud方法查数据库,拿到ORM列表:List[Category]
categories = await crud_news.get_categories(db, skip=skip, limit=limit)
# # 查询分类总条数,前端分页需要total
total = await crud_news.get_categories_count(db)
return {
"code": 200,
"message": "获取新闻分类成功",
"data": {
"total": total,
# 重点:ORM对象 → Pydantic模型序列化,过滤多余字段
"items": [CategoryResponse.model_validate(c) for c in categories]
}
}
except Exception as e:
# 异常捕获,接口返回500错误信息
raise HTTPException(status_code=500, detail=f"获取分类失败:{str(e)}")
测试接口成功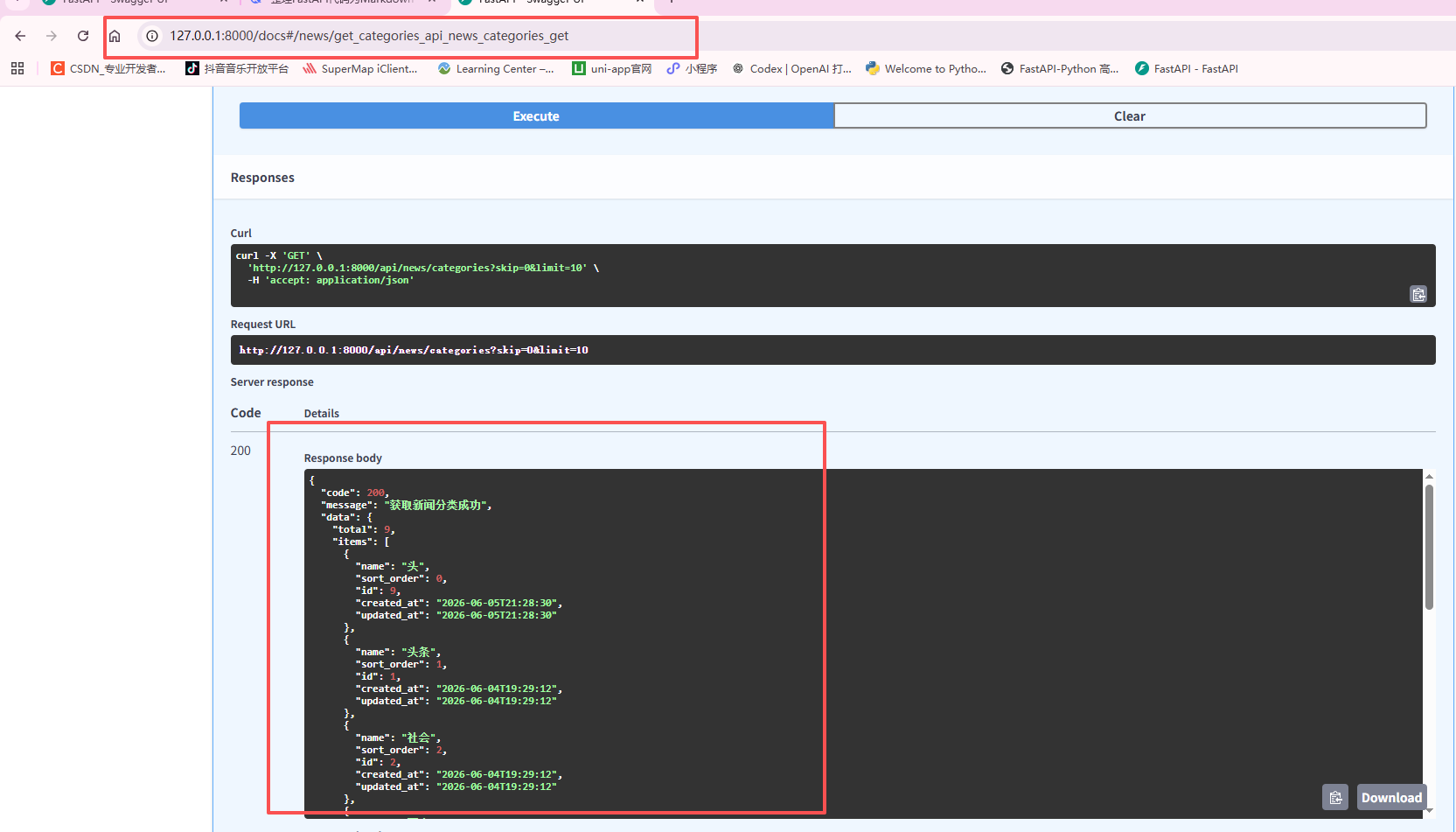
测试前端如果需要调用接口还需要配置跨域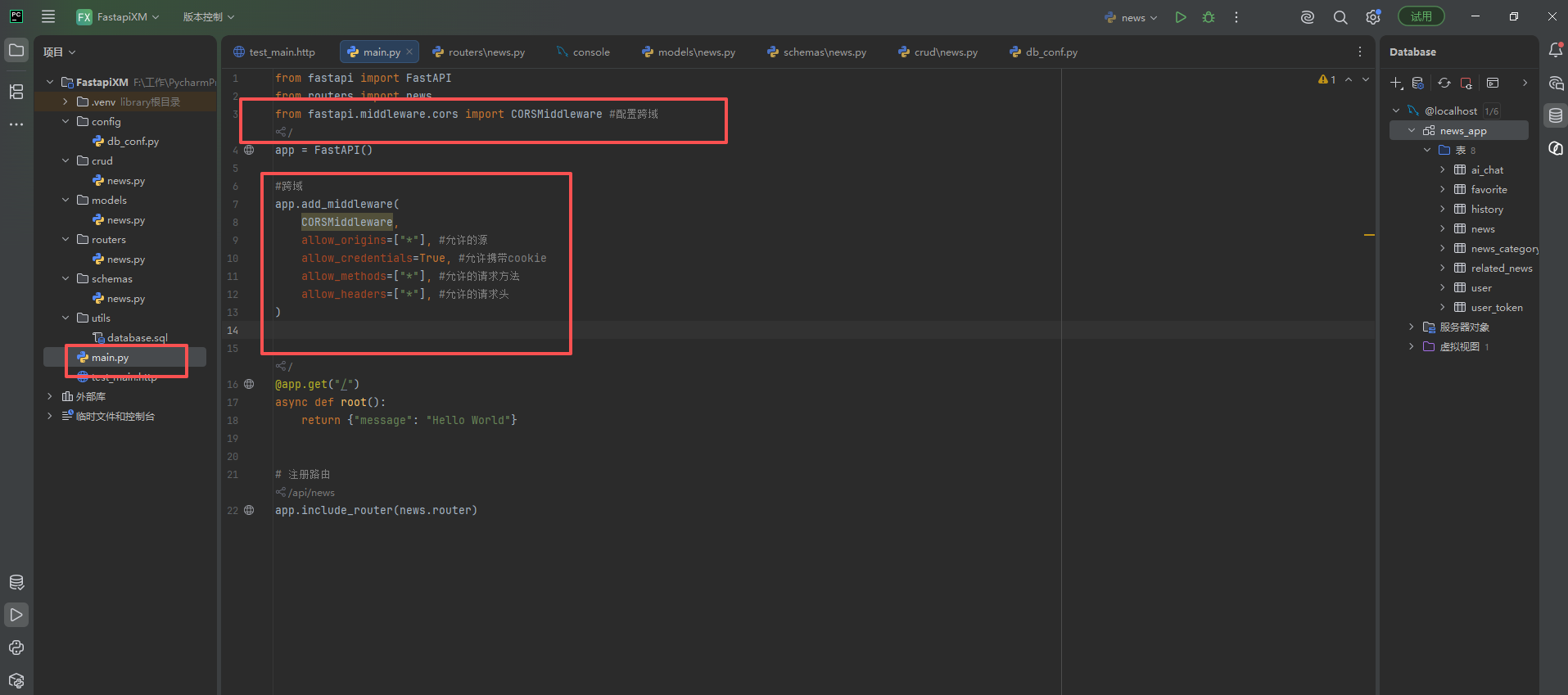
from fastapi import FastAPI
from routers import news
from fastapi.middleware.cors import CORSMiddleware #配置跨域
app = FastAPI()
#跨域
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], #允许的源
allow_credentials=True, #允许携带cookie
allow_methods=["*"], #允许的请求方法
allow_headers=["*"], #允许的请求头
)
@app.get("/")
async def root():
return {"message": "Hello World"}
# 注册路由
app.include_router(news.router)
测试的接口以完成,前端也可以调用成功,今天用FASTAPI写完一个接口,就到这里

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)