rf 强化学习第二章(共五章)
表格型方法就是把智能体学到的东西直接存放到一张表中。有三种:1)对每个状态记录一个状态价值;2)对每个状态动作对记录一个动作价值;3)对每个状态记录最优动作
局限是只能解决状态空间和动作空间都比较小,且是离散值的情况
环境模型包括两个要点:1)状态转移概率 2)奖励函数
强化学习方法分为有模型方法和无模型方法。有模型方法是知道环境模型,无模型方法不知道环境模型,但是不管知不知道,环境机制都是真实存在的。
表格型方法中,主要包括有模型方法和无模型方法,有模型方法包括动态规划,动态规划包括策略迭代和价值迭代,无模型方法包括无模型预测和无模型控制,无模型预测包括蒙特卡洛和时序差分,无模型控制包括SARSA和Q-learning
动态规划:有模型方法
联立方程组的方法的缺点有两个:1)如果状态数,动作数较多,那么变量数和方程数变多。2)最优方程有max操作,没法解方程求解
策略迭代:
第一步是策略评估,计算出当前策略下所有的状态价值;计算方法是迭代法,首先假设所有的状态价值都是0,然后列出状态价值函数的贝尔曼方程,然后不断迭代直到误差小于阈值或达到迭代次数。
为什么迭代可以接近真实的状态价值?
1)有限任务中,终止状态价值为0,然后每一次迭代都得到前一个状态的真实状态价值,并且在以后的迭代中都不会改变
2)无限任务中,由于折扣因子的存在,后一个状态的误差会由于折扣因子压缩变小,所以多次迭代后,最终所有的估计状态价值都会收缩到真实的状态价值
第二步是策略改进,根据状态价值函数和动作价值函数(由于是有模型方法,所以奖励函数和状态转移概率是已知的)找出每个状态下的最优动作,用最优动作改进策略;

等价替换的原因:是因为外层有一个期望符号 Eπ ,它涵盖了对未来动作选择的平均过程。提前把对动作的期望算好,简化了表达式。
在一次策略迭代后,在新的状态价值函数下优化策略,不断重复,直到策略不能被优化。
为什么策略迭代算法有效?
因为总的策略是有限的,而每一次迭代都保证至少不会变差,所以最后一定会停止在某个稳定策略上。
价值迭代:
建立在最优状态价值函数的贝尔曼最优方程上
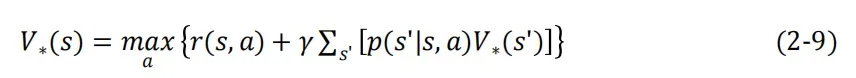
通过迭代法,逼近每个状态的最优状态价值
直到更新前的最优状态价值和更新后的最优状态价值的差值小于阈值则停止。
无模型预测
蒙特卡洛:
在真实环境中多次采样,结果取平均
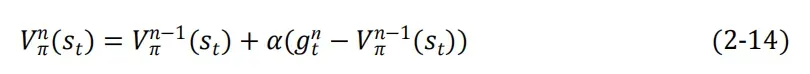 推导过程:
推导过程:
 但是不想保存所有的历史回报值,所以每次重新计算均值,只保存上一次的均值。
但是不想保存所有的历史回报值,所以每次重新计算均值,只保存上一次的均值。
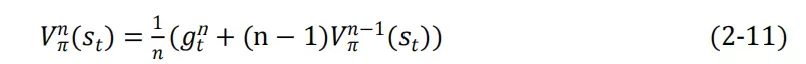 化简:
化简:
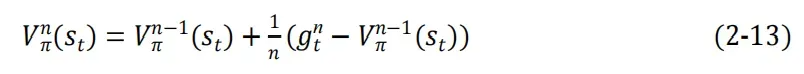
最后把1/n替换成学习率得到公式2-14,之所以要替换,是因为随着n的增长,学习率越来越低,不如用一个固定值
缺点是每次都对一个回合的完整回报值采样,必须是有限任务,必须有终止状态。
时序差分:
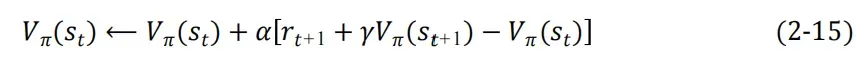
TD error:一步时序差分,计算出走了一步后更新的预估与原始预估之间的误差。
无模型控制:策略不是固定的,而是要不断根据动作价值改进的。
SARSA:
首先将所有元素初始化为0,然后使用以下公式进行更新
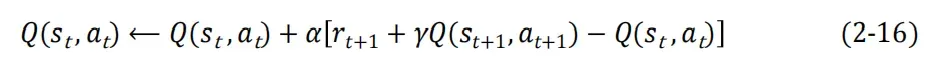
采用 ε − greedy 策略,由于采集数据的策略和评估改进的策略是同一个,所以又叫做同策略算法。
在状态st,根据当前策略Π选择动作at,然后将at输入真实环境得到即时奖励rt+1,下一个状态st+1。
得到st+1后,根据当前策略Π选择下一个动作at+1。
Q-Learning:
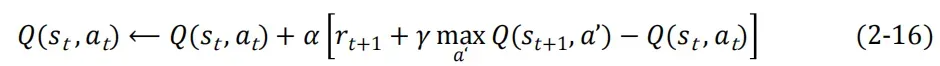
与环境交互采用ε − greedy 策略,但是Q表中动作价值(a')绑定的是贪婪策略,所以又叫做异策略算法。
在状态st,根据当前策略Π选择并执行动作at,随即返回即时奖励rt+1和下一个真实状态st+1。
Q-Learning的关键区别在于:在更新Q(st,at)的价值时,它不需要实际选择或执行at+1,而是在下一状态所有可能动作中,选取Q值最大的那个作为‘目标价值’
Q表是一个二维数组,行代表状态,列代表动作。每一个表中的数字代表:当前状态下如果采取了动作,未来预期能拿到的总回报是多少。
SARSA:到了st+1,真的选了一个动作,只读取这个格子的值,所以学出来的是安全路径,因为它考虑了探索带来的风险。SARSA是不断的采样,不断地更新Q表的过程。
Q-Learning:到了st+1,不真的选下一个动作,而是把st+1这一行的所有格子都看一遍,然后取最大值,所以学出来的是最优路径。Q-Learning是不断的采样,不断地更新Q表的过程。
ε − greedy 策略:
核心逻辑:探索与利用的平衡
- 利用 (Exploitation):相信目前学到的知识,选择当前 Q 值最大(看起来收益最高)的动作。
- 探索 (Exploration):不满足于现状,尝试一些之前没怎么选过的动作,看看会不会有意外惊喜。
ε-greedy 通过一个超参数 ε(epsilon,通常是一个很小的数,比如 0.1)来控制这两者的比例:
- 以 1−ϵ 的概率进行“利用”:查 Q 表,选出价值最高的那个动作(贪婪)。
- 以 ϵ 的概率进行“探索”:完全随机地从所有可能的动作中选一个。
参考视频:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)