给 Qwen3.6 装上 MTP:本地部署、蒸馏、微调一条龙保姆教程
最近 Qwen3.6 和 Unsloth 的组合很值得折腾。
原因不复杂:Qwen3.6 官方模型卡里已经写明 MTP: trained with multi-steps,也就是模型训练阶段就带了 Multi-Token Prediction 能力。Unsloth 又进一步放出了保留 MTP head 的 GGUF 量化版本。于是,本地推理不再只是“量化后勉强跑起来”,而是可以尝试用 MTP 做 speculative decoding,让模型一次先猜多个 token,再由主模型验证。
如果命中率高,解码就会明显快起来。
这篇文章不只讲概念,而是把今天能落地的路线完整拆一遍:
- • 怎么选 Qwen3.6 的 MTP-GGUF 模型;
- • 怎么用 llama.cpp 的 MTP 实验分支跑起来;
- • 怎么判断 MTP 是否真的生效;
- • 怎么做一套自己的蒸馏数据;
- • 怎么用 Unsloth / QLoRA 微调;
- • 最后怎么导出到 GGUF 或 vLLM。
先说边界:llama.cpp 的 MTP 支持目前仍在 PR/实验分支阶段,不是主线稳定功能;命令参数可能随分支更新。本文会给可执行路线,也会把坑写清楚。
- MTP 到底快在哪里
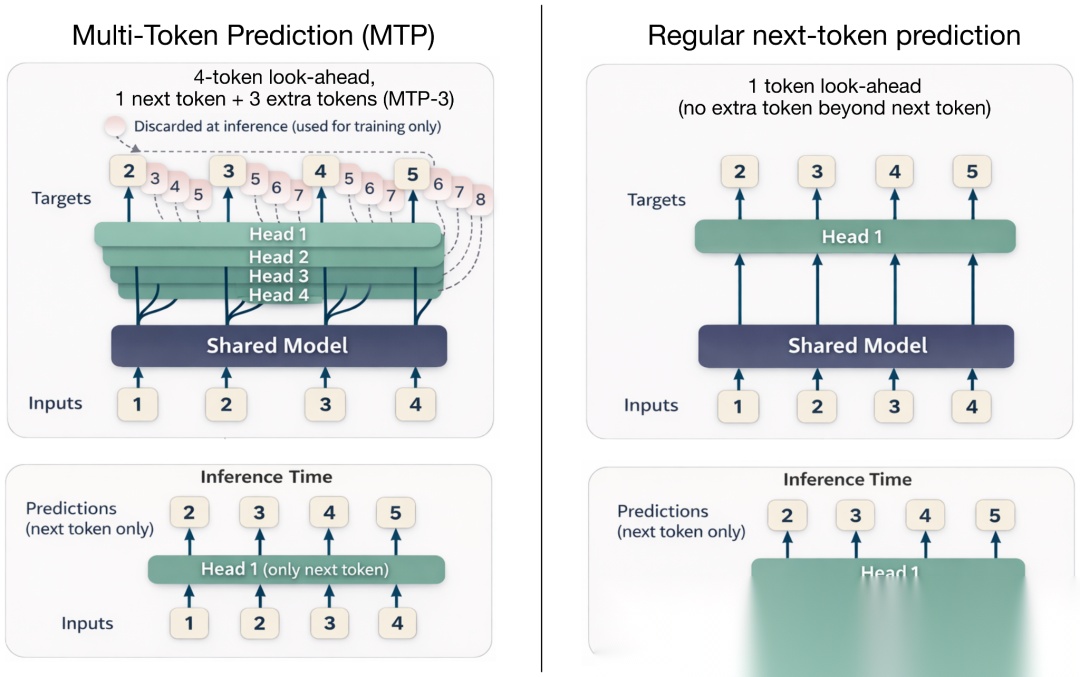
MTP 工作机制
普通自回归模型生成文本时,是一个 token 一个 token 往前走:
第 1 步:预测 token_1第 2 步:预测 token_2第 3 步:预测 token_3...
MTP 的想法是:不要每一步只看一个 token。模型内部的 MTP head 可以先给出几个未来 token 的草稿,比如一次猜 2–3 个,然后主模型验证这些草稿是否成立。
如果草稿被接受,就相当于少走了几轮串行 decode。
可以把它理解成:
MTP head:我猜后面是 A、B、C主模型:A、B 可以,C 不行结果:一次前进 2 个 token,再从 C 的位置重新正常生成
这也是为什么 MTP 更适合“输出很长”的场景,比如:
- • 写代码;
- • 写长文;
- • 多轮聊天;
- • 本地单用户助手;
- • prompt 不太长但生成很多 token 的任务。
但它不是万能加速器。如果你的任务主要慢在超长上下文 prefill,比如 RAG 一次塞几十万 token,再只生成几百 token,MTP 的收益就会下降。
- 先选模型:27B 还是 35B-A3B
这次重点看两个模型:
-
unsloth/Qwen3.6-27B-MTP-GGUF
-
unsloth/Qwen3.6-35B-A3B-MTP-GGUF
Qwen3.6-27B
这是 27B dense 模型,结构更直接。Unsloth 模型卡里列出的常见量化体积大致是:
| 量化 | 体积 |
|---|---|
| UD-IQ2_XXS | 9.57 GB |
| Q3_K_M | 13.8 GB |
| Q4_0 | 16.1 GB |
| Q4_K_M | 17.1 GB |
| UD-Q4_K_XL | 17.9 GB |
| Q5_K_M | 19.8 GB |
| Q6_K | 22.9 GB |
| Q8_0 | 29 GB |
如果你是第一次尝试,建议从 UD-Q4_K_XL 或 Q4_K_M 开始。太低比特能省空间,但质量和速度都要自己测。
Qwen3.6-35B-A3B
这是 35B total / 3B activated 的 MoE 模型。官方模型卡显示它有 256 个 experts,每次激活 8 routed + 1 shared experts,上下文原生 262K tokens。
Unsloth MTP-GGUF 的常见体积:
| 量化 | 体积 |
|---|---|
| UD-IQ1_M | 11.4 GB |
| UD-IQ2_M | 11.9 GB |
| UD-Q2_K_XL | 12.6 GB |
| UD-IQ3_S | 14.1 GB |
| UD-Q3_K_M | 17.1 GB |
| UD-IQ4_XS | 18.2 GB |
| UD-Q4_K_M | 22.7 GB |
| UD-Q4_K_XL | 22.9 GB |
| UD-Q5_K_M | 27.1 GB |
| UD-Q6_K | 30 GB |
| Q8_0 | 37.8 GB |
如果你想在消费级机器上尽量体验高能力模型,35B-A3B 的低/中比特 GGUF 会很有吸引力。但要注意:GGUF 推理能跑,不代表本地微调也轻松。
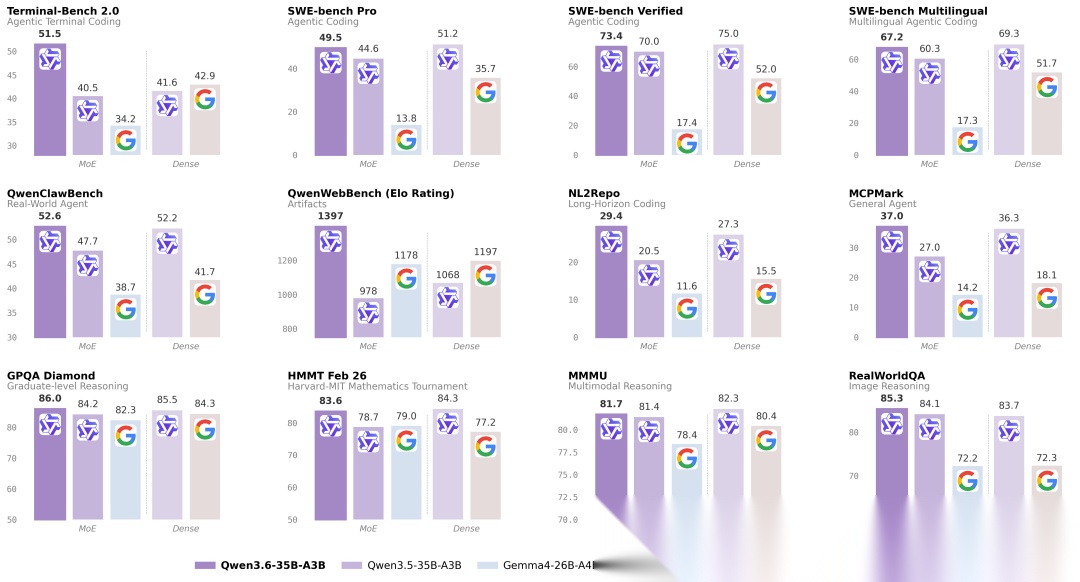
Qwen3.6 35B-A3B Benchmark
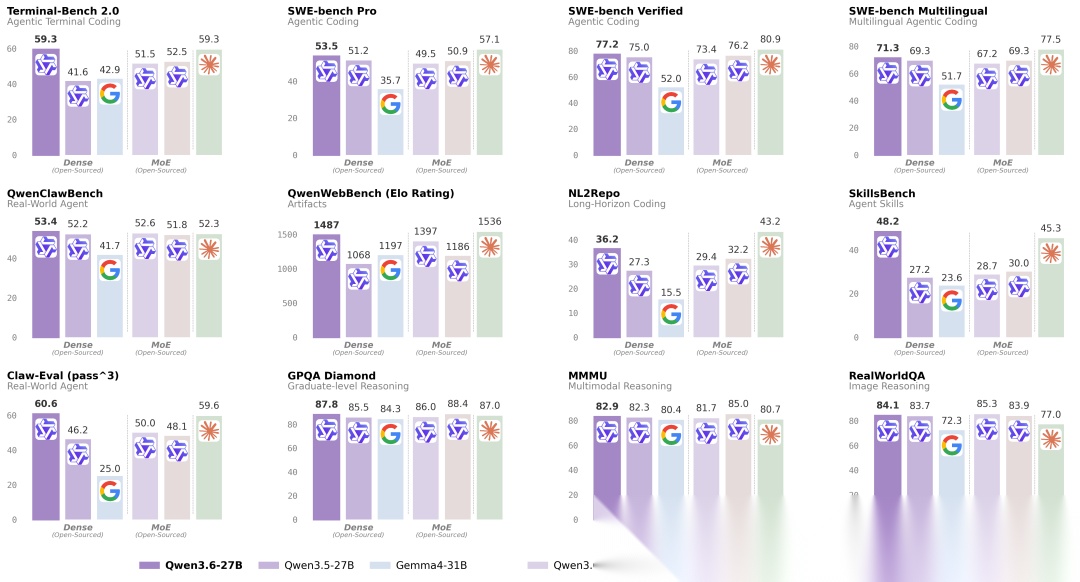
Qwen3.6 27B Benchmark
- 路线图:不要一上来就微调
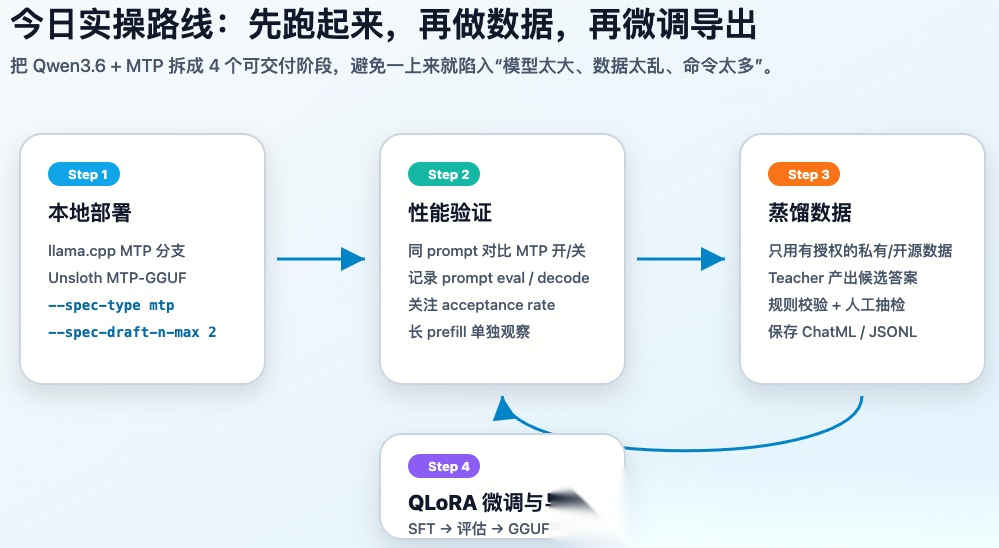
部署蒸馏微调路线
我建议按这个顺序来:
-
- 先用 MTP-GGUF 跑通本地推理。
-
- 用同一个 prompt 对比 MTP 开/关,确认真的加速。
-
- 准备你自己的任务数据,做蒸馏/清洗。
-
- 用 QLoRA 做 SFT 微调。
-
- 导出 LoRA、merged 16bit、GGUF 或 vLLM 服务。
很多人一开始就想“我要微调 35B”。实际更好的做法是:先证明你的任务值得微调,再投入训练成本。
- 本地部署:llama.cpp MTP 实验分支
目前 llama.cpp 的 MTP 支持来自 PR:
- • PR:https://github.com/ggml-org/llama.cpp/pull/22673
- • 分支:https://github.com/am17an/llama.cpp/tree/mtp-clean
这个 PR 还在 Open 状态,所以本文命令按当前模型卡和 PR 讨论整理。后续如果参数改名,以 PR 最新说明为准。
4.1 Linux + NVIDIA 编译
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -ygit clone -b mtp-clean https://github.com/am17an/llama.cpp.gitcmake llama.cpp -B llama.cpp/build \ -DBUILD_SHARED_LIBS=OFF \ -DGGML_CUDA=ONcmake --build llama.cpp/build \ --config Release \ -j \ --clean-first \ --target llama-cli llama-servercp llama.cpp/build/bin/llama-* llama.cpp
如果你是 macOS / CPU / Metal 路线,Unsloth 模型卡提示把 -DGGML_CUDA=ON 改成 -DGGML_CUDA=OFF。不过 Metal 构建细节可能随 llama.cpp 版本变化,最好同时看当前分支的 build 文档。
4.2 跑 Qwen3.6-27B-MTP-GGUF
export LLAMA_CACHE="unsloth/Qwen3.6-27B-MTP-GGUF"./llama.cpp/llama-server \ -hf unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q4_K_XL \ -ngl 99 \ -c 8192 \ -fa on \ -np 1 \ --spec-type mtp \ --spec-draft-n-max 2
启动后,服务默认提供 OpenAI-compatible API。你可以用浏览器访问 WebUI,或者用 OpenAI SDK 调用。
4.3 跑 Qwen3.6-35B-A3B-MTP-GGUF
export LLAMA_CACHE="unsloth/Qwen3.6-35B-A3B-MTP-GGUF"./llama.cpp/llama-server \ -hf unsloth/Qwen3.6-35B-A3B-MTP-GGUF:UD-Q4_K_XL \ -ngl 99 \ -c 8192 \ -fa on \ -np 1 \ --spec-type mtp \ --spec-draft-n-max 2
4.4 如果 mtp 参数报错
PR 讨论里已经出现过参数变化:有用户遇到 unknown speculative type: mtp,随后提示改成:
--spec-type draft-mtp
所以如果你当前分支报错,可以试:
./llama.cpp/llama-server \ -hf unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q4_K_XL \ -ngl 99 \ -c 8192 \ -fa on \ -np 1 \ --spec-type draft-mtp \ --spec-draft-n-max 2
这个现象本身也说明:MTP 支持仍在快速迭代,不要把当前命令当成长期稳定接口。
- 怎么判断 MTP 真的生效
不要只看“感觉变快”。至少看三件事。
5.1 看启动参数
确认 server 命令里有:
--spec-type mtp# 或者新分支里的--spec-type draft-mtp
以及:
--spec-draft-n-max 2
--spec-draft-n-max 控制一次最多草稿几个 token。不是越大越好,draft 越长,接受率可能越低,额外开销也可能上升。模型卡示例常用 2,PR 讨论里很多用户测 2、3、4、7,最佳点跟硬件和任务有关。
5.2 看日志里的 acceptance rate
正常情况下,你应该能在日志里看到类似字段:
draft acceptance rate = 0.79728statistics mtp: #calls..., #gen drafts..., #acc drafts...
acceptance rate 越高,MTP 越有机会加速。但它不是唯一指标,最终还是看 decode tok/s 和 total time。
5.3 同 prompt 对比开关
用同一个 prompt,跑两次:
- • 第一次开启 MTP;
- • 第二次去掉
--spec-type ...; - • 采样参数保持一致;
- • 记录 prompt eval tok/s、decode tok/s、总耗时。
可以直接用本项目里的模板:
assets/benchmark_template.csv
公众号参考文章和 PR 里有一个 RTX 5090 的片段:Qwen3.6-27B Q4_0,同一个 “create a flappy bird clone” prompt,MTP 开启后 decode 从 63.72 tok/s 到 105.47 tok/s,draft acceptance rate 约 79.7%。
这个数字很漂亮,但不要直接照搬成你的机器结果。不同显卡、后端、量化、上下文长度、prompt 类型都会影响最终速度。
- OpenAI-compatible API 调用
启动 llama-server 后,可以用 OpenAI SDK 测:
pip install -U openaiexport OPENAI_BASE_URL="http://localhost:8080/v1"export OPENAI_API_KEY="EMPTY"
Python 示例:
from openai import OpenAIclient = OpenAI()response = client.chat.completions.create( model="Qwen3.6-MTP-GGUF", messages=[ {"role": "user", "content": "写一个最小可运行的贪吃蛇 HTML 游戏。"}, ], temperature=0.6, top_p=0.95, max_tokens=4096,)print(response.choices[0].message.content)
如果你用的是 Qwen 官方推荐参数,可以参考:
- • thinking general:
temperature=1.0, top_p=0.95, top_k=20, presence_penalty=1.5 - • precise coding:
temperature=0.6, top_p=0.95, top_k=20, presence_penalty=0.0 - • non-thinking general:
temperature=0.7, top_p=0.8, top_k=20, presence_penalty=1.5
Qwen3.6 默认会 thinking。官方模型卡也提示,Qwen3.6 不再使用 Qwen3 那种 /think、/nothink 软开关,而是通过 API 参数控制。
- vLLM / SGLang:更适合多卡服务
如果你不是本地单机 GGUF,而是多卡服务器部署,Qwen 官方模型卡给了 vLLM 和 SGLang 的 MTP 命令。
7.1 vLLM MTP
uv pip install vllm --torch-backend=autovllm serve Qwen/Qwen3.6-35B-A3B \ --port 8000 \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
如果你只做文本,想省掉 vision encoder 和多模态 profiling,可以加:
--language-model-only
7.2 SGLang MTP
uv pip install 'sglang[all]'python -m sglang.launch_server \ --model-path Qwen/Qwen3.6-35B-A3B \ --port 8000 \ --tp-size 8 \ --mem-fraction-static 0.8 \ --context-length 262144 \ --reasoning-parser qwen3 \ --speculative-algo NEXTN \ --speculative-num-steps 3 \ --speculative-eagle-topk 1 \ --speculative-num-draft-tokens 4
这条路线适合生产服务和多用户吞吐;本地消费级显卡用户,还是先从 GGUF + llama.cpp 开始更现实。
- Unsloth Studio:如果你想少折腾环境

Qwen3.6 in Unsloth Studio
Unsloth 官方已经写明 Qwen3.6 可以在 Unsloth Studio 中运行和微调。Studio 的价值是:
- • 本地 Web UI;
- • 可以跑模型;
- • 可以准备数据;
- • 可以训练;
- • 更适合先验证工作流。
macOS / Linux / WSL 安装:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows PowerShell:
irm https://unsloth.ai/install.ps1 | iex
启动:
unsloth studio -H 0.0.0.0 -p 8888
Docker:
docker run -d \ -e JUPYTER_PASSWORD="mypassword" \ -p 8888:8888 \ -p 8000:8000 \ -p 2222:22 \ -v $(pwd)/work:/workspace/work \ --gpus all \ unsloth/unsloth
如果你不想从第一天就处理 CUDA、PyTorch、FlashAttention、依赖版本,Studio 会更友好。
- 蒸馏:先把数据做对,再谈训练
这里的“蒸馏”不要理解成复制某个闭源模型的能力。更实用的定义是:
用一个更强或更稳定的 teacher,为你有权使用的任务数据生成更规范、更一致的答案,再经过清洗和抽检,变成 Qwen3.6 的 SFT 数据。
举个例子:你想把 Qwen3.6 微调成“本地部署助手”。那就准备这些任务:
- • llama.cpp 报错排查;
- • vLLM 启动参数解释;
- • GGUF 量化选择;
- • GPU 显存估算;
- • benchmark 日志解读;
- • ChatML 数据格式转换;
- • LoRA 微调排错。
9.1 数据格式用 ChatML JSONL
每一行一个样本:
{"messages":[{"role":"system","content":"你是一个严谨的本地大模型部署助手。"},{"role":"user","content":"如何判断 Qwen3.6 MTP 是否真的开启?"},{"role":"assistant","content":"检查启动参数是否包含 --spec-type mtp 或 draft-mtp,并观察日志中是否出现 draft acceptance rate、statistics mtp 等字段。然后用同一 prompt 对比 MTP 开关下的 decode tok/s 和总耗时。"}]}
9.2 Teacher 生成时加约束
可以用这个 system prompt:
你是一个严谨的 AI 工程资料整理助手。请根据给定问题生成可用于监督微调的高质量答案。要求:1. 不编造不存在的命令或参数。2. 如果某功能仍是实验分支,必须明确标注。3. 命令需要说明适用环境。4. 答案要可操作,不要空泛。5. 输出中文。
9.3 清洗规则
生成后至少做这些过滤:
- • 删除空答案;
- • 删除明显拒答;
- • 删除和问题无关的样本;
- • 删除命令不闭合、JSON 不合法的样本;
- • 删除重复样本;
- • 每个任务类型抽样人工检查。
9.4 一个最小蒸馏脚本思路
下面是伪代码级流程,你可以接本地 llama-server、vLLM 或云端 OpenAI-compatible API:
import jsonfrom openai import OpenAIclient = OpenAI( base_url="http://localhost:8080/v1", api_key="EMPTY",)questions = [ "如何选择 Qwen3.6-27B-MTP-GGUF 的量化版本?", "llama.cpp MTP 的 --spec-draft-n-max 应该设置多少?", "为什么 MTP 对 RAG 长上下文不一定加速?",]system = "你是一个严谨的本地大模型部署助手。答案必须可操作,不要编造。"with open("distill_qwen36_mtp.jsonl", "w", encoding="utf-8") as f: for question in questions: response = client.chat.completions.create( model="teacher-model", messages=[ {"role": "system", "content": system}, {"role": "user", "content": question}, ], temperature=0.3, top_p=0.9, ) answer = response.choices[0].message.content row = { "messages": [ {"role": "system", "content": system}, {"role": "user", "content": question}, {"role": "assistant", "content": answer}, ] } f.write(json.dumps(row, ensure_ascii=False) + "\n")
真正训练前,不要直接把 teacher 输出喂进去。先抽检,尤其是命令和版本号。
- 微调:优先 QLoRA,不要上来全量
Unsloth 文档里很明确:入门优先 LoRA/QLoRA。对 Qwen3.6 这类大模型来说,full fine-tuning 成本非常高;本地消费级机器更现实的是:
- • 本地 GGUF 跑推理;
- • 云端或高显存机器做 QLoRA;
- • 训练后导出 LoRA 或 GGUF;
- • 再回本地部署。
10.1 推荐超参起点
| 参数 | 建议 |
|---|---|
r |
16 或 32 |
lora_alpha |
16/32/64,通常等于 r 或 2r |
lora_dropout |
0 起步,怀疑过拟合时 0.05–0.1 |
learning_rate |
2e-4 快速试;正式可降到 1e-4 / 5e-5 |
num_train_epochs |
1–3 |
per_device_train_batch_size |
1–2 |
gradient_accumulation_steps |
8–16 |
max_seq_length |
2048/4096 起步,长文档再加 |
Unsloth 文档推荐 target modules 覆盖 attention + MLP:
target_modules = [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",]
10.2 训练代码骨架
下面是 SFT 骨架。实际显存需求取决于模型、量化、上下文和 batch;如果 27B/35B-A3B 在本地放不下,就用云端 A100/H100 或先换更小 Qwen 模型验证数据。
from datasets import load_datasetfrom trl import SFTTrainer, SFTConfigfrom unsloth import FastLanguageModelfrom unsloth.chat_templates import get_chat_template, train_on_responses_onlymax_seq_length = 4096model, tokenizer = FastLanguageModel.from_pretrained( model_name="unsloth/Qwen3.6-27B", max_seq_length=max_seq_length, load_in_4bit=True,)tokenizer = get_chat_template( tokenizer, chat_template="qwen3",)model = FastLanguageModel.get_peft_model( model, r=16, target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], lora_alpha=32, lora_dropout=0, bias="none", use_gradient_checkpointing="unsloth", random_state=3407,)dataset = load_dataset("json", data_files="distill_qwen36_mtp.jsonl", split="train")def formatting_prompts_func(examples): texts = [ tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False) for messages in examples["messages"] ] return {"text": texts}dataset = dataset.map(formatting_prompts_func, batched=True)trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset, dataset_text_field="text", max_seq_length=max_seq_length, args=SFTConfig( per_device_train_batch_size=1, gradient_accumulation_steps=16, warmup_steps=10, max_steps=300, learning_rate=1e-4, logging_steps=10, optim="adamw_8bit", weight_decay=0.01, lr_scheduler_type="linear", seed=3407, output_dir="outputs_qwen36_mtp_sft", ),)trainer = train_on_responses_only( trainer, instruction_part="<|im_start|>user\n", response_part="<|im_start|>assistant\n",)trainer.train()
这里有两个关键点:
-
- 训练前必须确认 chat template 和模型匹配;
-
- 建议只训练 assistant response,不要让模型学习用户输入本身。
如果 chat_template="qwen3" 在当前 Unsloth 版本中不可用,就先打印支持列表:
from unsloth.chat_templates import CHAT_TEMPLATESprint(CHAT_TEMPLATES.keys())
然后选择最接近 Qwen ChatML 的模板,或使用 tokenizer 自带 apply_chat_template。
- 保存、导出、部署
训练后先保存 LoRA adapter:
model.save_pretrained("qwen36_mtp_lora")tokenizer.save_pretrained("qwen36_mtp_lora")
如果你要用 vLLM 部署,保存 merged 16bit:
model.save_pretrained_merged( "qwen36_mtp_merged_16bit", tokenizer, save_method="merged_16bit",)
然后:
vllm serve ./qwen36_mtp_merged_16bit
如果你要回到 llama.cpp / Ollama / LM Studio,导出 GGUF:
model.save_pretrained_gguf( "qwen36_mtp_finetuned_gguf", tokenizer, quantization_method="q4_k_m",)
或者推到 Hugging Face:
model.push_to_hub_gguf( "你的用户名/qwen36-mtp-finetuned-gguf", tokenizer, quantization_method="q4_k_m",)
导出后效果变差怎么办
Unsloth 文档里反复强调:最常见原因是 chat template 不一致。
排查顺序:
-
- 训练时用的 template;
-
- 推理时用的 template;
-
- eos token;
-
- 是否多加了 BOS token;
-
- 是否 assistant/user 标记不一致;
-
- 是否把用户输入也训练进 loss 里。
如果导出 GGUF 后出现乱码、无限重复、停不下来,优先查这些。
- 什么时候考虑 GRPO
SFT 能解决“格式、风格、领域问答、流程化输出”。
如果你的任务有明确可验证答案,比如:
- • 数学题最终答案;
- • 代码题单元测试;
- • JSON schema 是否通过;
- • 命令是否符合规则;
- • SQL 是否能执行;
再考虑 GRPO/RLVR。
Unsloth 的 GRPO 文档建议:reward/verifier 要认真设计,数据量太小会不稳定,通常至少准备几百行。学习率也要比 SFT 小,RL 类任务可从 5e-6 起步。
我的建议是:
先 SFT,让模型学会你的任务格式;再 GRPO,让模型在可验证任务上学会更优策略。
不要第一天就上 RL。
- 已知坑点汇总
坑 1:MTP 支持还在实验分支
llama.cpp PR #22673 仍是 Open。你今天看到的是 --spec-type mtp,明天可能变成 draft-mtp。遇到参数报错,先看 PR 最新讨论。
坑 2:-np > 1 暂时不适合
Unsloth 模型卡和 PR 讨论都提到当前 MTP 路线需要单 parallel。启动报错时,显式加:
-np 1# 或--parallel 1
坑 3:多模态先别和 MTP 混用
当前说明里 --mmproj 与 MTP 暂不支持。想跑图像/视频理解,先用 vLLM/SGLang 或普通路线;想跑 MTP,就先做纯文本。
坑 4:长上下文不一定更快
MTP 主要加速 decode。如果你的任务是 200K prompt + 200 token 输出,prefill 才是大头。PR 讨论里也有用户观察到 MTP 路径 prefill 变慢。
坑 5:微调比推理吃资源得多
GGUF 量化推理能在消费级显卡上跑,不代表 27B/35B-A3B QLoRA 微调也能轻松跑。微调前先用小数据、小步数、短上下文验证流程。
- 我的推荐实操配置
如果你今天就想开始,我建议:
入门体验
- • 模型:
unsloth/Qwen3.6-27B-MTP-GGUF:UD-Q4_K_XL - • 后端:llama.cpp MTP 分支
- • context:8192 或 16384
- • MTP:
--spec-draft-n-max 2 - • 任务:代码生成、长文生成
高性价比能力体验
- • 模型:
unsloth/Qwen3.6-35B-A3B-MTP-GGUF:UD-Q4_K_XL - • 后端:llama.cpp MTP 分支
- • context:8192 起步
- • 如果 OOM:降到 3-bit/IQ 量化,或减小 context
数据蒸馏
- • 格式:ChatML JSONL
- • 样本数:100 条起步验证,1000+ 更稳
- • teacher:本地强模型或云端 API
- • 必做:规则过滤 + 人工抽检
微调
- • 方法:QLoRA
- • rank:16 起步
- • lr:
1e-4或2e-4快速验证 - • max_steps:先 60,再 300+
- • 保存:先 LoRA,再 merged,再 GGUF
- 结尾:这次真正值得关注的不是“快”,而是链路完整了
Qwen3.6 + MTP 的意义,不只是某张显卡上多跑了几十 tok/s。
更重要的是,现在这条链路开始完整:
Qwen3.6 官方 MTP 训练 ↓Unsloth 保留 MTP head 的 GGUF ↓llama.cpp MTP speculative decoding ↓本地 OpenAI-compatible API ↓蒸馏数据 ↓QLoRA 微调 ↓GGUF / vLLM / Studio 再部署
如果你只是想尝鲜,今天就跑 MTP-GGUF。
如果你想做自己的本地助手,先别急着微调。先收集 100 条高质量任务,蒸馏成 ChatML,跑一个小步数 QLoRA,看看模型是不是朝你想要的方向变了。
跑通这条闭环,比单次 benchmark 更重要。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献226条内容
已为社区贡献226条内容

所有评论(0)