师妹崩溃:师兄我咋模型路由之后还越用越贵啊!我看完后对她说:你用的方式不对,掉进了缓存的坑了。
前段时间我研究生的师妹跑来问我一些用大模型的事,因为我也是做大模型相关的方向的嘛,说她最近用了一个模型路由工具来优化 API 成本, 结果月底一看账单,不仅没降,反而比之前还高了。
她有点崩溃的问我:“师兄我是按教程配的,我对简单任务走DeepSeek,长上下文走Gemini,复杂推理才走Opus,理论上应该省钱才对啊怎么还更贵了啊?”。她说他找了好久都没有找到问题。
我笑了笑,问了她"你注意过切换模型之后,第一轮响应的速度吗?"
她想了一下,说:“好像确实慢一些……我一直以为是网络波动或者模型加载慢。”
我摇摇头,说那不是网络的问题。然后跟她解释了一下Prompt Cache的原理—— 每次对话都会在API层缓存大量上下文KV状态,模型一切换,缓存就全废了。
她接着说:“所以我每次切回Opus,它都在重新算之前的所有内容?这就费钱了。”
我说对,而且每次重新算都要花几毛钱,切几次就比省下来的钱多了。
很多人跟她一样,以为路由省钱是因为"用了更便宜的模型",却没意识到"来回切换"背后隐藏的缓存重建成本才是真正的大头。
1. 多模型路由是个啥?
Claude Code 火了之后,随之火爆的还有一类工具,就叫做模型路由器(Router)。
网上也开源了很多的工具大家也可以找到,这类工具的核心逻辑是:把 Claude Code 发出的 API 请求拦截,根据任务类型智能转发给不同的模型。
比如:
- 简单补全 → DeepSeek(便宜)
- 长上下文分析 → Gemini 2.5 Pro(便宜且窗口大)
- 复杂推理 → Claude Opus(贵但准)
- 后台任务 → Qwen3-Coder(国产平替)
听起来完美啊,也确实很完美,它就是让各模型各司其职,成本大幅降低。
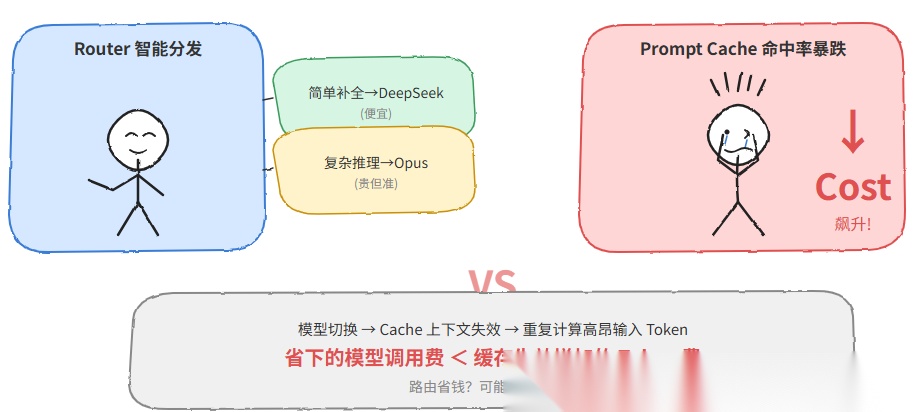
但这里有一个很多人没意识到的隐藏问题:Prompt Cache 缓存命中率会因为模型切换而急剧下降,反而可能让你的成本飙升。
师妹当时的配置就是这样的呢,她以为自己在省钱,实际上每次切回 Opus,之前的缓存全部归零。她后来查了一下 API 日志,发现切 Opus 的第一轮,cache_read_input_tokens 全部是 0——说明缓存完全没有命中。
2. Claude Code 的省钱秘密是什么
在正常使用 Claude Code 时,Anthropic 会自动启用 Prompt Caching(提示词缓存)机制。
Claude Code 的工作方式是这样的:每次对话都会把完整的上下文历史(包括系统提示、文件内容、工具调用记录、对话历史)全部打包发给 API。随着任务推进,这个上下文会越来越长,轻松达到 20万~40万 tokens。
如果没有缓存的话,我们按 Sonnet 4 的定价 来计算的话,一次请求就要1.2。每次请求都不存下来,那确实多次后,贵的离谱了。
但有了Prompt Caching,已经"算过"的前缀 KV 状态会被缓存起来。下次请求如果前缀相同,只需支付 cache read 价格($0.30/MTok,是标准价格的 1/10),而不是重新全量计算。这波就省了不少了。
实测数据:
在典型的 Claude Code 会话中,我们假设使用无缓存和95%的缓存来看。
- 无缓存:400K tokens × 1.20/次请求
- 95% 缓存命中:380K cache read × 3.75 + 10K input × 0.18/次请求
实际成本只有无缓存版本的 15%。 LMCache 的实测数据也印证了这一点:在 92% 的前缀复用率下,2M tokens 的处理成本从 降至1.15,节省约 81%。是不是还是非常的可以…
3. 关键问题:模型切换是如何破坏缓存的?
Prompt Cache 缓存的是什么?
很多人以为缓存就是"存了一段文字"。这就有问题了。Prompt Cache 缓存的是Transformer 推理过程中的注意力层计算出的 KV(Key/Value)状态。这是模型内部的计算状态,与模型的权重和架构强绑定。
这意味着:Opus、Sonnet、Haiku 是完全不同的模型,它们的 KV cache 之间无法互换。
切换模型 = 缓存归零
当你用 Claude Code Router 把请求从 Sonnet 路由到 DeepSeek,再路由回 Sonnet,会发生什么?
第1轮(Sonnet):构建了 200K tokens 的上下文缓存第2轮(DeepSeek):DeepSeek 没有也无法使用 Sonnet 的缓存第3轮(Sonnet):Sonnet 重新看到了 200K tokens 的上下文,但缓存已失效...→ 需要重新 cache write:200K × $3.75/MTok = $0.75
你以为用便宜的 DeepSeek 省了那一轮的钱,实际上之前积累的整个缓存被废掉,下一轮需要重新写入,反而更贵。
Anthropic 官方文档明确指出:
缓存遵循严格的层级结构:工具定义 → 系统提示 → 消息历史。上层变化会使下层缓存全部失效。模型切换属于最根本的变化,会导致全量缓存失效。
官方也验证了这一现象,Claude Code 的官方文档在 /model 命令处有一条提示:
“The picker asks for confirmation when the conversation has prior output, since the next response re-reads the full history without cached context.”
翻译过来就是:切换模型后,下一次响应会以无缓存状态重读全部历史。
4.大缓存杀手:不只是模型切换
模型切换是最严重的一种,但不是唯一的"缓存杀手"。以下的场景都会触发缓存失效:
1. 模型切换(最贵)
如上分析,KV cache 无法跨模型复用,每次切换等于从零开始。。
2. TTL 超时(最常见)
- API 用户默认缓存时间:5 分钟
- Claude Max 用户:1 小时
去接杯水,看个邮件,回来发现缓存已过期,下一次请求重新写入全量上下文。这是最常见的成本暗坑。
3. MCP 工具列表变更
缓存的层级是:工具定义 → 系统提示 → 消息。 工具列表处于最左端,一旦改变,系统提示和所有消息的缓存全部失效。
中途加载一个新的 MCP Server?= 全量重新计算。
有团队的实测报告显示,初始缓存命中率只有 7%,排查发现是工具列表中有一个动态字段在变化——移位后命中率恢复正常。
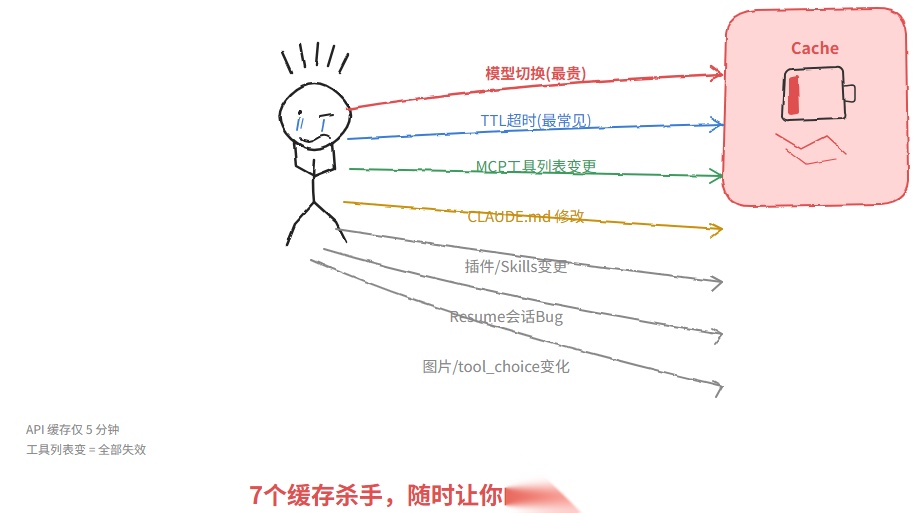
4. CLAUDE.md 修改
CLAUDE.md 是项目记忆文件,属于系统提示层,基于内容寻址。文件改动 = 缓存失配。
5. 插件/Skills 变更
Skills 内容也会注入到上下文中,安装新 Skill 或更新现有 Skill,同样触发缓存失效。
6. Resume 会话中的 Bug
GitHub issue #27048 记录了一个真实 Bug:在 5 分钟 TTL 窗口内 resume 会话时,tool-use 内容(如文件读取结果)无法被缓存复用,导致 cache read 减少、cache write 增加,命中率大幅下降。
7. 图片或 tool_choice 变化
只要请求中图片的存在与否发生变化,或 tool_choice 参数变更,缓存就会失效。
5. 成本对比
假设一个重型 Claude Code 会话,上下文 200K tokens,进行 20 轮对话:
场景 A:稳定使用 Claude Sonnet 4(基准)
| 类型 | tokens | 单价 | 费用 |
|---|---|---|---|
| Cache Read(95%,19轮命中) | 190K × 19 = 3.61M | $0.30/M | $1.08 |
| Cache Write(首次建立) | 200K | $3.75/M | $0.75 |
| 新增 Input(每轮 5K) | 5K × 20 = 100K | $3/M | $0.30 |
| 合计 | ≈ $2.13 |
场景 B1:Sonnet ↔ DeepSeek 来回切换(每 4 轮切换一次,共切 5 次)
这是最贵的模式——每次切回 Sonnet,都需要重建缓存(超过TTL):
| 类型 | 说明 | tokens | 单价 | 费用 |
|---|---|---|---|---|
| DeepSeek 阶段 Input | 无缓存,全量输入(4轮 × 200K) | 800K | $0.50/M | $0.40 |
| 切回 Sonnet 后 Cache Write | 每次切回需重建缓存(切回3次) | 200K × 3 = 600K | $3.75/M | $2.25 |
| Sonnet 阶段 Cache Read | 切回后当轮命中率低,约 50%(每次2轮) | ~600K | $0.30/M | $0.18 |
| 新增 Input(每轮 5K) | 全程 | 5K × 20 = 100K | $3/M | $0.30 |
| 合计 | ≈ $3.13 |
比场景 A 贵约 47%,主要惩罚来自反复的 Cache Write 重建。
场景 B2:单向降级,全程使用 DeepSeek(不切回 Sonnet)
| 类型 | 说明 | tokens | 单价 | 费用 |
|---|---|---|---|---|
| DeepSeek Input | 无缓存机制,全量输入(20轮 × 200K) | 4M | $0.50/M | $2.00 |
| 新增 Input(每轮 5K) | 全程 | 100K | 已含于上 | — |
| 合计 | ≈ $2.00 |
比场景 A 略便宜,但代价是全程没有 Anthropic 缓存加速,每轮都要全量处理 200K tokens,延迟更高,响应更慢。
结论:真正昂贵的不是"用便宜模型",而是"来回切换"导致反复重建缓存。 如果确定某类任务交给第三方模型处理,单向路由是合理的;频繁在 Sonnet 和第三方之间横跳,才是成本最高的模式。
5. 路由没价值?
当然不是。关键是:怎么路由,路由什么任务。
正确的路由姿势:用 Subagent 做路由,而不是切换主对话的模型
Claude Code Router 的最佳实践是:
- 主会话:固定使用一个模型(如 Sonnet),保持长上下文缓存稳定
- 子任务:通过 Subagent 机制派遣给更便宜的模型执行
- Subagent 完成后,只把精简的结果返回主会话
这样主会话的缓存始终有效,子任务的成本也得到控制。
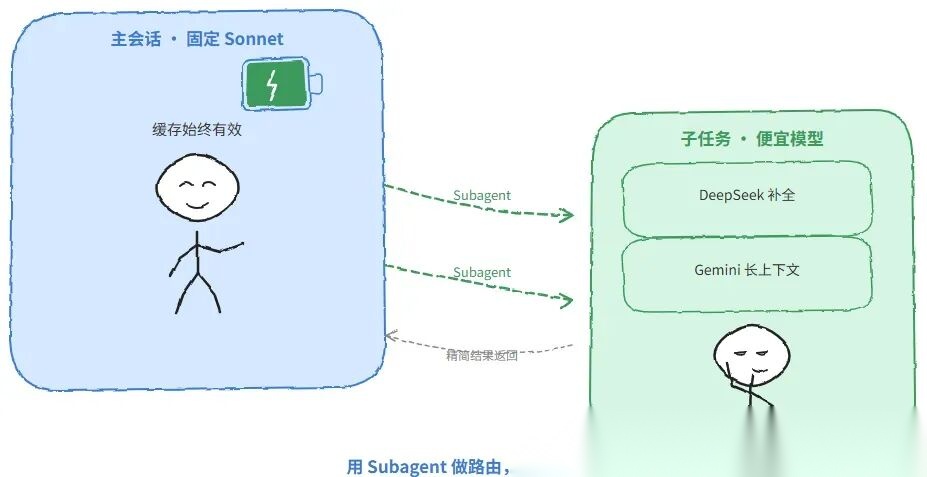
任务边界切换,而不是频繁切换
如果确实需要换模型,选择在任务阶段边界切换(一个完整任务做完之后),并主动 /compact 压缩历史,再开新阶段——相当于主动放弃旧缓存,而不是被动失效。
对"无缓存"模型的任务要算清楚账
路由到 DeepSeek、Gemini 等第三方时,这些模型的缓存机制不同(有些根本没有 Anthropic 式的 Prompt Cache)。此时发送的 200K tokens 全部按原价计费,需要确认省下的模型差价能覆盖重建成本。
6. 实用建议:如何保持高缓存命中率
- 任务开始前确定模型,不要中途换用
ANTHROPIC_MODEL环境变量或/model命令在会话开始前设置,之后不要动。 - 提前配置好所有 MCP Server中途加载 MCP = 工具列表变化 = 全量缓存失效。
- CLAUDE.md 精简且稳定只放长期有效的规则,临时说明写在对话里,不要写进文件。
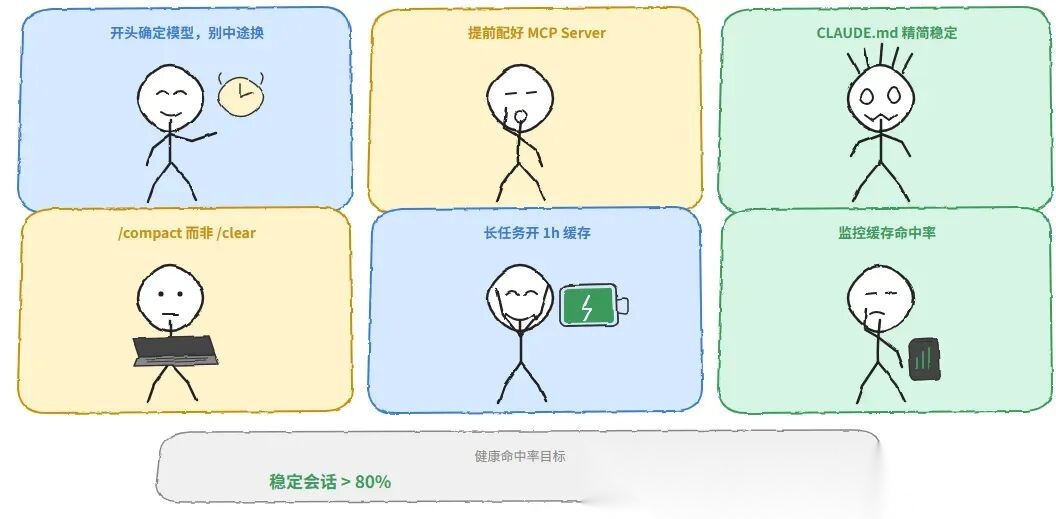
-
定期 /compact 而非 /clear
/compact主动放弃旧缓存,通过瘦身降低未来的写入和读取成本;/clear等于清空重来。 -
长任务开启 1 小时缓存
export ENABLE_PROMPT_CACHING_1H=1适用于通过 API key、Bedrock、Vertex、Foundry 接入的用户——默认 TTL 是 5 分钟,设置这个变量可以切换到 1 小时。
-
监控缓存命中率通过 API 响应中的
cache_read_input_tokens和cache_creation_input_tokens字段,或安装cache-kit插件使用/cache-report命令查看实时命中率。健康的命中率目标:**稳定会话 > 80%,新会话预热后 > 60%**。
6. 总结
| 稳定单模型 | 频繁路由切换 | |
|---|---|---|
| 缓存命中率 | 85%~95% | 10%~40% |
| 每次请求成本 | 约标准价 15% | 约标准价 60%~100% |
| 适合场景 | 长任务、大代码库 | 短任务、无历史上下文 |
| 风险 | TTL 超时 | 每次切换重建缓存 |
核心结论:
用 Claude Code Router 做智能路由是有价值的,但不是"切换得越频繁越省钱"。缓存命中率的损失可能远超模型差价带来的节省。
最优策略是:主会话绑定一个模型,子任务用 Subagent 路由,任务边界才考虑切换。
Claude Code 的缓存机制是一个精密的工程设计。理解它的工作原理,才能真正用好路由策略——而不是用路由器给自己挖了一个成本陷阱。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)