R语言KNN算法
1、导入数据
#mtcars:汽车性能数据集(32 款车,11 个指标)
#任务:用汽车性能特征预测变速箱类型(am:0 = 自动挡,1 = 手动挡)
#算法:KNN 分类(class 包标准 KNN)
#关键:KNN 必须做特征标准化(否则数值大的特征会主导距离)
# ====================== 1. 加载包与数据 ======================
# 安装包(仅第一次)
# install.packages("class") # KNN算法
# install.packages("ggplot2") # 可视化
# install.packages("caret") # 数据划分/评估
library(class)
library(ggplot2)
library(caret)
# 加载mtcars数据
data(mtcars)
df <- mtcars # 重命名方便使用
# 查看数据结构
# 目标:am (0=自动挡, 1=手动挡) —— 分类标签
# 特征:所有其他列(排量、马力、重量等)
str(df)
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...
| 变量名 | 全称 / 中文说明 | 含义 & 单位 |
|---|---|---|
| mpg | Miles/(US) gallon 油耗 | 每加仑汽油行驶的英里数(数值越大越省油) |
| cyl | Number of cylinders 气缸数 | 4/6/8 缸(发动机气缸数量) |
| disp | Displacement 排量 | 发动机排量(立方英寸) |
| hp | Gross horsepower 马力 | 发动机总马力 |
| drat | Rear axle ratio 后轴传动比 | 后轮驱动轴传动比 |
| wt | Weight 车重 | 千磅(1000 lbs) |
| qsec | 1/4 mile time 加速时间 | 1/4 英里直线加速耗时(秒) |
| vs | Engine shape 发动机类型 | 0 = V 型发动机;1 = 直列发动机 |
| am | Transmission 变速箱 | 0 = 自动挡;1 = 手动挡 |
| gear | Number of forward gears 档位 | 前进挡数量(3/4/5 档) |
| carb | Number of carburetors 化油器 | 化油器数量 |
head(df) mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
数据可视化:
# ====================== 数据可视化:特征分布 =====================
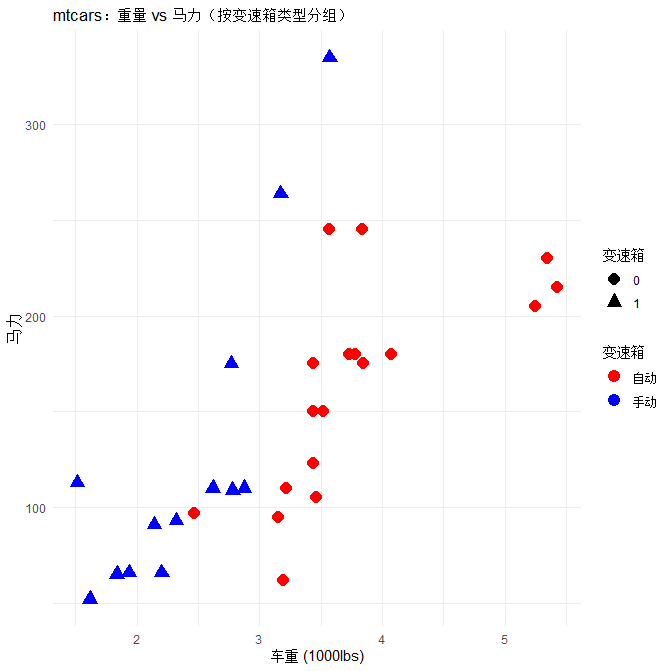
# 用2个关键特征画散点图:重量(wt) + 马力(hp) → 区分变速箱类型
ggplot(df, aes(x=wt, y=hp, color=as.factor(am), shape=as.factor(am))) +
geom_point(size=4) +
labs(title="mtcars:重量 vs 马力(按变速箱类型分组)",
x="车重 (1000lbs)", y="马力", color="变速箱", shape="变速箱") +
scale_color_manual(labels=c("自动","手动"), values=c("red","blue")) +
theme_minimal()
2、数据预处理
# ====================== 数据预处理(KNN 必须做!) ======================
# 1. 分离特征和标签
X <- df[, !names(df) %in% "am"] # 特征:除am外所有列
Y <- as.factor(df$am) # 标签:变速箱类型(转因子)
# 2. 特征标准化 (核心!KNN距离计算依赖标准化)
# 公式:(x - 均值) / 标准差
X_scaled <- scale(X)
# 查看标准化后数据(均值≈0,标准差≈1)
summary(X_scaled)
3、数据集划分4、
# ====================== 划分训练集 / 测试集 (7:3) ======================
set.seed(123) # 固定随机种子,结果可复现
trainIndex <- createDataPartition(Y, p = 0.7, list = FALSE)
# 训练集 / 测试集
train_X <- X_scaled[trainIndex, ] # 标准化特征
test_X <- X_scaled[-trainIndex, ]
train_Y <- Y[trainIndex]
test_Y <- Y[-trainIndex]
# 查看数据量
cat("训练集样本数:", length(train_Y), "\n")
cat("测试集样本数:", length(test_Y), "\n")4、训练模型
# ====================== KNN 模型训练与预测 ======================
# KNN核心函数:knn(训练集, 测试集, 训练标签, K值)
k <- 5 # 初始K=5
knn_pred <- knn(
train = train_X,
test = test_X,
cl = train_Y,
k = k
)
# 查看预测结果
cat("K=5 预测结果:\n")
print(knn_pred)5、模型评估
# ====================== 模型评估:准确率 + 混淆矩阵 ======================
# 混淆矩阵
cm <- table(真实=test_Y, 预测=knn_pred)
cat("\n======== 混淆矩阵 ========\n")
print(cm) 预测
真实 0 1
0 3 2
1 0 3
# 计算准确率
accuracy <- sum(diag(cm)) / sum(cm)
cat("\n测试集准确率 =", round(accuracy * 100, 2), "%\n")
测试集准确率 = 75 %
6、寻找最优K值
# ====================== 7. 最优K值搜索(自动找最佳K) ======================
k_values <- 1:15 # 尝试K=1到15
acc_list <- c()
for (k in k_values) {
pred <- knn(train_X, test_X, train_Y, k=k)
acc <- sum(pred == test_Y) / length(test_Y)
acc_list <- c(acc_list, acc)
}
# 画K值-准确率曲线
k_result <- data.frame(K=k_values, 准确率=acc_list)
ggplot(k_result, aes(x=K, y=准确率)) +
geom_line(color="darkgreen", linewidth=1) +
geom_point(size=2, color="red") +
labs(title="K值对KNN模型准确率的影响", x="K值") +
theme_minimal()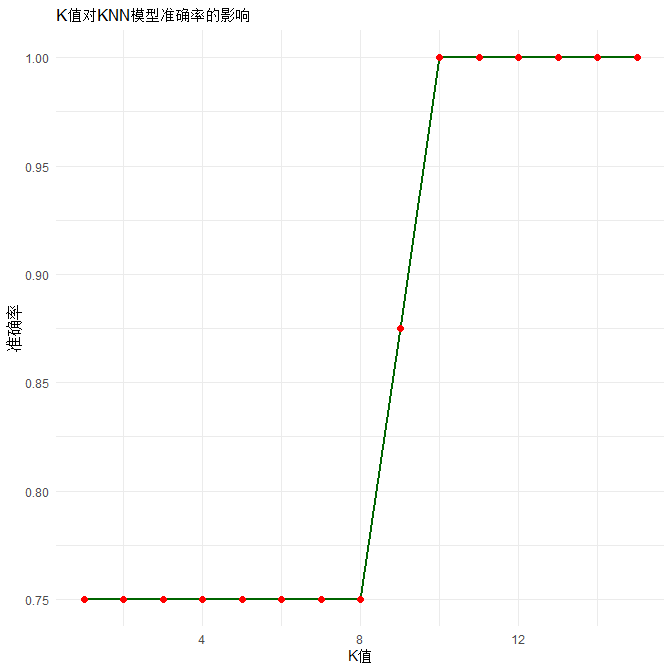
# 输出最优K
best_k <- k_values[which.max(acc_list)]
best_acc <- max(acc_list)
cat("\n最优K值 =", best_k, "\n")
cat("最优K下最高准确率 =", round(best_acc*100,2), "%\n")最优K值 = 10
最优K下最高准确率 = 100 %

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)