腾讯开源了 Agent Memory,让 AI 真正记住你。
腾讯开源了一个项目,两个月拿了 4600+ Star。
做的事非常专一:给 AI Agent 装上长期和短期记忆。
装完之后什么效果?
评测数据摆在这:针对长期记忆,整体准确率从 47.85% 涨到 76.10%,提升将近 60%。
用户事实召回从不到 30% 飙到 79%。
基于短期记忆的加持,长任务中最高节省 61% token。
这个项目叫 TencentDB Agent Memory,腾讯云数据库团队做的,5 月 14 日正式开源的。
来看看在 OpenClaw 和 Hermes 中的效果。
01
AI 记忆到底难在哪
现在,点击开一个 Agent 的新会话,其实都会默认认为它啥都不知道。
你得把相关的上下文或者信息给它说一遍,它才能干好活。
Memory 的目的还是提高我们的效率。
TencentDB Agent Memory 的思路和主流的方案不太一样。
它的思路是符号化短期记忆 + 分层长期记忆。

开源地址:https://github.com/TencentCloud/TencentDB-Agent-Memory
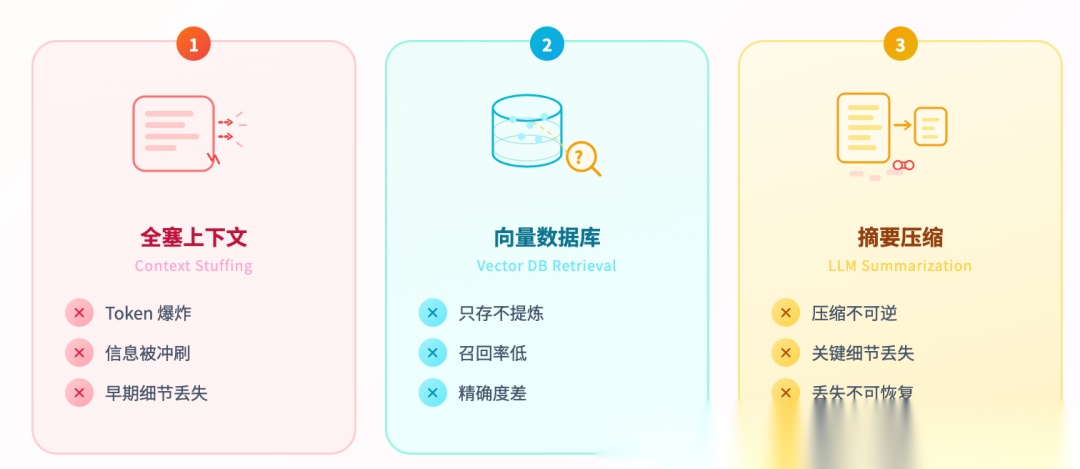
现在主流的解决方案大概有三种,但都有明显短板。
第一种,全塞进上下文窗口。
简单粗暴,但窗口有上限,塞多了 token 直接爆掉。
第二种,用向量数据库做记忆。
比全塞上下文好一些,但问题是只存不提炼,很多对话碎片时召回率低,精确度差。
第三种,让大模型自己做摘要压缩。
但压缩是不可逆的,可能会造成关键细节丢失的问题。
02
腾讯开源项目的核心架构
这个项目最核心的设计,是一个四层渐进式记忆架构。
L0 到 L3,从底到顶,每一层干的事不一样。
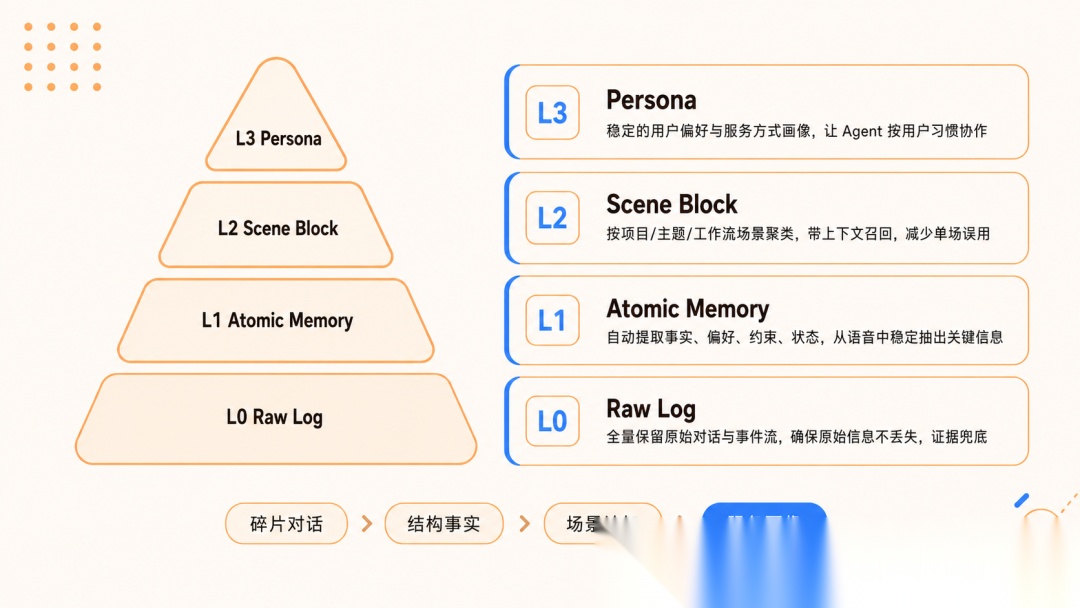
L0:原始对话。
全量保留,一字不落。兜底用,随时可回查。
L1:原子事实。
自动从对话里提取独立的事实节点,比如"我爱吃火锅"、“我后用 NextJS”,打标签存起来。
L2:场景聚类。
相关的原子事实按场景聚合。比如用户系统讨论涉及的所有事实,表结构、权限、接口合成一个场景块,Markdown 格式,人可直接读。
L3:用户画像。
基于下面三层生成稳定的用户画像,沉淀技术偏好、代码风格、常用工具链。
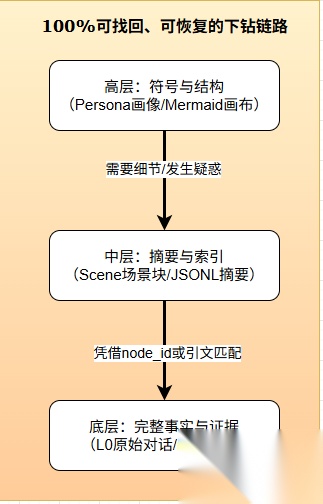
这样既不会因为上下文太长影响推理,也不会丢失关键信息。
而且系统保证从顶层到原始证据有完整的回溯路径。
L3 里说用户偏好 TypeScript,这个结论可以追溯到 L2 某个场景块,场景块里的每条结论又能追溯到 L1 的原子事实,原子事实最终指向 L0 里你说过的那句话。
整条证据链不断裂。
03
短期记忆压缩:巧用 Mermaid 图
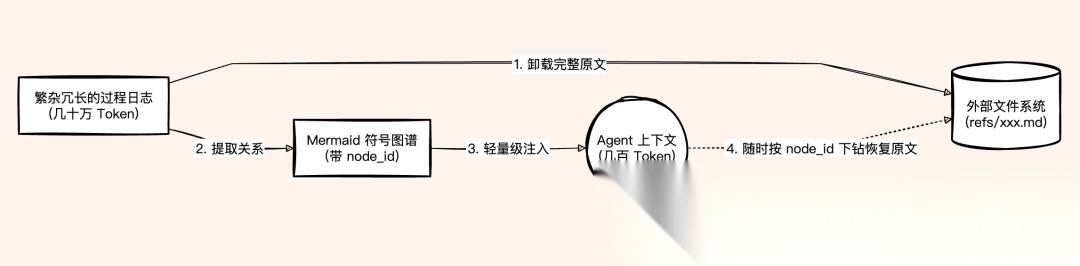
四层架构解决长期记忆,但短期上下文也是烧钱大户。
AI 排查一个 bug 要调用十几次工具,上下文塞满日志。
解法是符号化记忆,把完整日志卸载到外部文件,用 Mermaid 语法画一张紧凑的任务状态图塞进上下文,需要细节时再通过节点 ID 检索。
Mermaid 用极少的 token 把线性摘要列表重组为带状态、依赖关系和可寻址索引的任务拓扑结构图。
让 AI 大模型不靠记住什么标签而是靠从图的拓扑中推理出什么结构来理解任务全貌。
信息密度更高、结构不丢失、细节可逐层找回。
实测 Token 消耗直降超 50%,任务完成率反升 23%。
省了钱,活还干得更好。
语义检索(Embedding)擅长模糊匹配,关键词检索(BM25)擅长精确命中。
两路各自召回候选结果,RRF 融合排序。语义相关的不会漏,精确匹配的也不会丢
04
跑出来的数据
说了这么多设计,来看实际跑出来的数据。
腾讯用 PersonaMem 基准测试做了评测,对比的是原生 OpenClaw 和接入 Agent Memory 之后的 OpenClaw:
| 指标 | 原生 OpenClaw | 接入 Agent Memory |
|---|---|---|
| 总准确率 | 47.85% | 76.10%(+59%) |
| 用户事实召回 | 29.63% | 79.07%(+167%) |
| 偏好跟踪 | 66.67% | 83.45%(+25%) |
| 个性化推荐 | 46.67% | 76.36%(+64%) |
用户事实召回这个指标最夸张,从不到 30% 涨到 79%。意思是以前你跟 AI 说过的十件事,它只能想起三件。
现在能想起八件。
除了 PersonaMem,项目还跑了几个编程相关的基准测试:
WideSearch 成功率 33%→50%,token 砍 61%;
SWE-bench 通过率 58.4%→64.2%,token 省 33%。
WideSearchp 评估信息任务中的搜索、整合与验证能力,SWE-bench 是一个用于评估人工智能模型解决真实世界软件工程问题能力的评测基准
加了记忆不光记住了更多,做任务效率也变高了,省下的 token 都用在干正事上。
05
怎么用
这个项目现在是作为 OpenClaw 的插件发布的,安装非常简单。
一行命令搞定:
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
装完之后默认使用本地 SQLite + sqlite-vec 作为存储后端,零配置,开箱即用。
不需要你单独装数据库,不需要连外部服务,数据全在本地。
如果你想接外部 Embedding 服务来增强语义检索效果,可以在配置文件里指定。
如果你用的是 Hermes Agent 框架,项目也提供了 Docker 一体化镜像。
把 Hermes + Agent Memory 插件 + Gateway 全打包在一个容器里,docker pull 下来就能跑。
支持的模型也很灵活。
新的 1.0.0-beta.1 版本给希望自己开发 Agent Memory 适配层的用户提供了快速开始的方法。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献196条内容
已为社区贡献196条内容

所有评论(0)