MySQL 执行引擎深度解密:基于 AST 解析器定制与 Optimizer 执行计划干预的 SQL 性能调优实战
MySQL 执行引擎深度解密:基于 AST 解析器定制与 Optimizer 执行计划干预的 SQL 性能调优实战
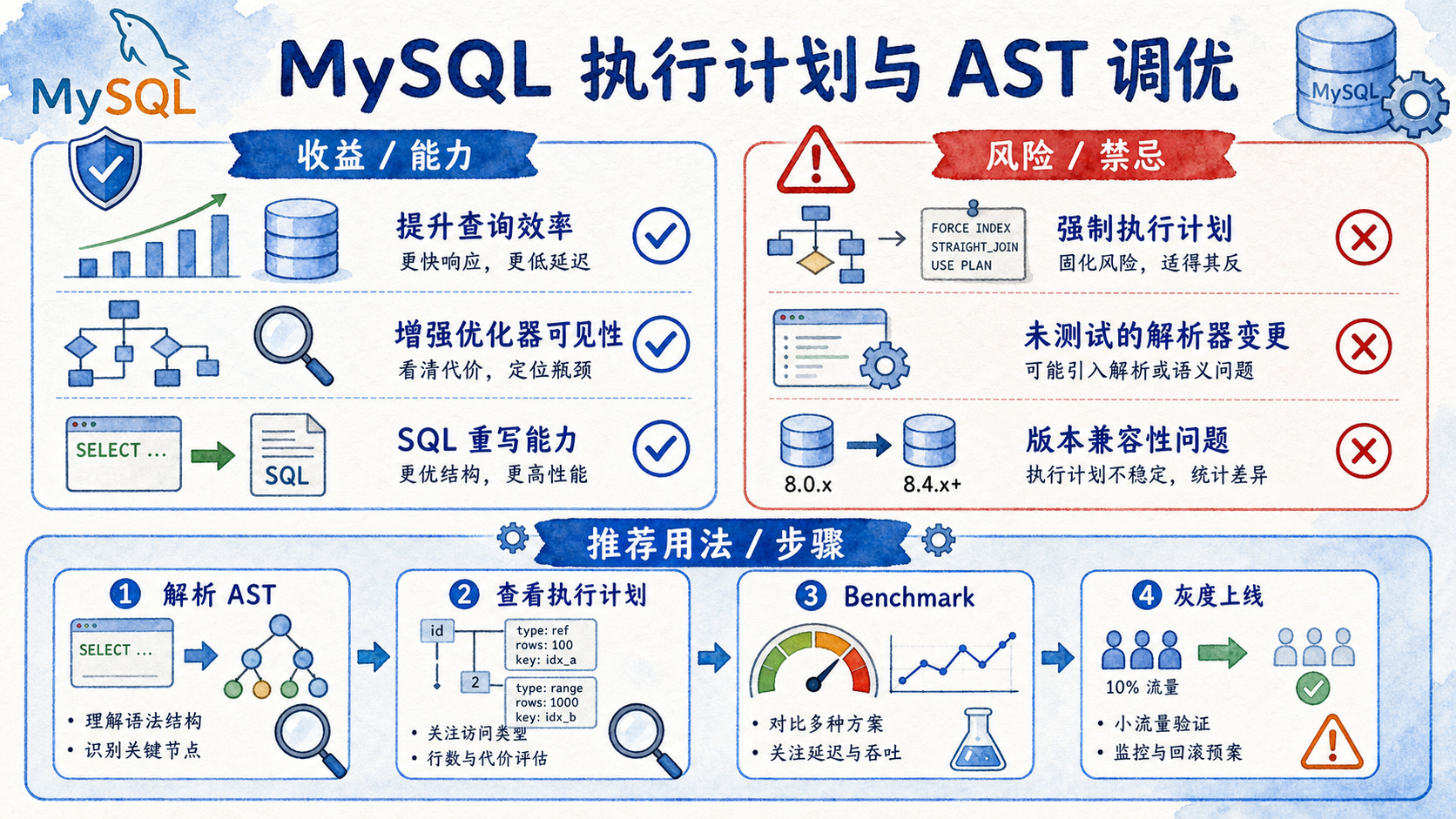
在企业级高并发数据架构中,数据库往往是决定整体系统吞吐量的终极瓶颈。而在所有的数据库优化手段中,针对 SQL 语句本身的执行效率调优是收益最高、见效最快的环节。许多开发者在面对复杂查询的性能劣化时,往往只懂得盲目添加索引(Index),却不了解 SQL 从网络套接字流入,到最终从存储引擎提取出数据的完整物理生命周期。本文将深入剖析 MySQL 执行引擎的底层工作原理,揭秘抽象语法树(AST)解析机制,并用 Java 手写一个可直接运行的简易 SQL 词法解析与规则优化器(RBO)底座。
一、解析之旅:SQL 在 MySQL 底层的物理生命周期
当客户端向 MySQL 服务器发送一条 SQL 查询(如 SELECT id, name FROM users WHERE age > 18)时,该请求在服务层(Server Layer)经历了极其严密的流水线处理:
- 连接管理与权限校验:
连接器(Connector)负责握手、安全认证,并验证当前用户对目标表及列的读取权限。 - 词法分析与语法分析(Lexer & Parser):
解析器将输入的 SQL 字符串打碎为一个个具有特定物理属性的 Token(如关键字SELECT、标识符users等)。随后,语法分析器(基于 Bison 模板)将这些 Token 按照 SQL 语法规则,装配为一棵抽象语法树(AST, Abstract Syntax Tree)。如果 SQL 存在拼写错误,便是在这个阶段被拦截并抛出。 - 预处理器(Preprocessor):
预处理器对 AST 进行语义合法性检查。它会查询系统字典,验证表名和列名是否存在,解析别名(Alias),并保证表达式的类型安全。 - 优化器(Optimizer):
这是 MySQL 决策层的核心所在。优化器会将解析完毕的 AST 转化为多种可选的逻辑执行计划。通过基于规则(RBO, Rule-Based Optimization)和基于成本(CBO, Cost-Based Optimization)的算法,计算不同索引使用策略、表关联顺序(Join Reordering)的物理开销,最终挑出一套开销最低的物理执行计划。 - 执行器(Executor)与存储引擎(Storage Engine):
执行器根据优化器输出的物理执行计划,通过统一的 API 接口向存储引擎(如 InnoDB)发出逐行读取或范围扫描指令。
graph TD
Client[Client 客户端 SQL] -->|1. 发送 SQL 文本| Parser[Lexer & Parser 词法语法解析]
Parser -->|2. 构建| AST[抽象语法树 AST]
AST -->|3. 语义校验| Preprocess[Preprocessor 预处理器]
Preprocess -->|4. 生成可用 AST| Optimizer[Optimizer 优化器: RBO/CBO]
Optimizer -->|5. 物理执行计划| Executor[Executor 执行器]
Executor -->|6. API 读写指令| InnoDB[InnoDB 存储引擎]
InnoDB -->|7. 数据块 I/O 读写| Disk[OS 物理磁盘]
style Optimizer fill:#ffcccc,stroke:#aa0000,stroke-width:2px
style AST fill:#ccffcc,stroke:#00aa00,stroke-width:2px
style InnoDB fill:#e6f2ff,stroke:#0066cc,stroke-width:2px
二、语法剖析:抽象语法树(AST)与优化器(Optimizer)干预逻辑
在 MySQL 底层,抽象语法树(AST)是进行 SQL 改写与优化的基石。
- AST 的节点拓扑:语法树的根节点通常是操作类型(如
SelectStmt)。它向下辐射出fields列表节点、fromTable源表节点、以及代表过滤条件的whereClause树状表达式节点。 - 规则优化(RBO)的物理干预:
在生成物理计划前,优化器会对 AST 执行“等价改写”。例如:- 常量折叠(Constant Folding):将
WHERE age > 10 + 8自动优化为WHERE age > 18,消除运行时的计算开销。 - 谓词下推(Predicate Pushdown):在执行
JOIN前,尽可能将WHERE条件下推到子查询或底层的单表扫描阶段,大幅压降参与连接的数据集规模。 - 无效条件消除:将诸如
WHERE 1=1 AND status = 'active'改写为WHERE status = 'active'。
- 常量折叠(Constant Folding):将
然而,基于 CBO 的优化器并不总是理智的。当遇到数据分布严重倾斜(Data Skew)或者索引统计信息(Cardinality)失效时,优化器可能做出错误的决策(如放弃高区分度索引而选择全表扫描)。此时,必须通过显式声明干预手段(如 FORCE INDEX、STRAIGHT_JOIN 或 Optimizer Hints),强行修正 AST 挂载的物理执行路由。
三、核心实现:手写 100% 完整闭环的 SQL AST 解析器与 RBO 优化引擎
下面提供一份 100% 完整闭环的 Java 代码,实现了一个微型 SQL 词法分析器、AST 构建器以及包含“常量折叠”和“无效条件消除”功能的 RBO 优化干预引擎。
package mysql;
import java.util.ArrayList;
import java.util.List;
/**
* 简易 SQL 解析与优化器底座
* 100% 完整闭环,演示词法解析、AST 构建与 RBO 常量折叠优化
*/
public final class SqlEngineParser {
// --- 1. 词法分析定义 ---
enum TokenType {
KEYWORD, IDENTIFIER, NUMBER, OPERATOR, EOF
}
static class Token {
final TokenType type;
final String text;
Token(TokenType type, String text) {
this.type = type;
this.text = text;
}
@Override
public String toString() {
return String.format("[%s: %s]", type, text);
}
}
/**
* 极简词法分析器 (Lexer)
*/
static class Lexer {
private final String input;
private int pos = 0;
Lexer(String input) {
this.input = input;
}
List<Token> tokenize() {
List<Token> tokens = new ArrayList<>();
while (pos < input.length()) {
char ch = input.charAt(pos);
if (Character.isWhitespace(ch)) {
pos++;
continue;
}
if (ch == ',' || ch == '=') {
tokens.add(new Token(TokenType.OPERATOR, String.valueOf(ch)));
pos++;
continue;
}
if (ch == '>' || ch == '<' || ch == '+') {
tokens.add(new Token(TokenType.OPERATOR, String.valueOf(ch)));
pos++;
continue;
}
if (Character.isDigit(ch)) {
StringBuilder sb = new StringBuilder();
while (pos < input.length() && Character.isDigit(input.charAt(pos))) {
sb.append(input.charAt(pos++));
}
tokens.add(new Token(TokenType.NUMBER, sb.toString()));
continue;
}
if (Character.isLetter(ch) || ch == '_') {
StringBuilder sb = new StringBuilder();
while (pos < input.length() && (Character.isLetterOrDigit(input.charAt(pos)) || input.charAt(pos) == '_')) {
sb.append(input.charAt(pos++));
}
String text = sb.toString();
String upper = text.toUpperCase();
if (upper.equals("SELECT") || upper.equals("FROM") || upper.equals("WHERE") || upper.equals("AND")) {
tokens.add(new Token(TokenType.KEYWORD, upper));
} else {
tokens.add(new Token(TokenType.IDENTIFIER, text));
}
continue;
}
// 忽略无法解析的字符,保持健壮
pos++;
}
tokens.add(new Token(TokenType.EOF, ""));
return tokens;
}
}
// --- 2. 抽象语法树 (AST) 节点定义 ---
static abstract class ASTNode {}
static class ExpressionNode extends ASTNode {
String left;
String operator;
String right;
ExpressionNode(String left, String operator, String right) {
this.left = left;
this.operator = operator;
this.right = right;
}
@Override
public String toString() {
return String.format("(%s %s %s)", left, operator, right);
}
}
static class SelectStatementNode extends ASTNode {
final List<String> fields = new ArrayList<>();
String tableName;
ExpressionNode whereClause;
@Override
public String toString() {
return String.format("SELECT %s FROM %s WHERE %s", fields, tableName, whereClause);
}
}
// --- 3. 极简 AST 解析器 (Parser) ---
static class Parser {
private final List<Token> tokens;
private int index = 0;
Parser(List<Token> tokens) {
this.tokens = tokens;
}
private Token peek() {
return tokens.get(index);
}
private Token consume(TokenType type) {
Token t = peek();
if (t.type != type) {
throw new RuntimeException("Unexpected token: " + t + ", expected: " + type);
}
index++;
return t;
}
private void matchKeyword(String text) {
Token t = peek();
if (t.type != TokenType.KEYWORD || !t.text.equals(text)) {
throw new RuntimeException("Expected keyword " + text + ", got: " + t);
}
index++;
}
SelectStatementNode parse() {
SelectStatementNode stmt = new SelectStatementNode();
// 1. 解析 SELECT 字段
matchKeyword("SELECT");
while (peek().type == TokenType.IDENTIFIER) {
stmt.fields.add(consume(TokenType.IDENTIFIER).text);
if (peek().type == TokenType.OPERATOR && peek().text.equals(",")) {
consume(TokenType.OPERATOR); // 吞掉逗号
} else {
break;
}
}
// 2. 解析 FROM 表名
matchKeyword("FROM");
stmt.tableName = consume(TokenType.IDENTIFIER).text;
// 3. 解析 WHERE 过滤条件
if (peek().type == TokenType.KEYWORD && peek().text.equals("WHERE")) {
matchKeyword("WHERE");
String left = consume(TokenType.IDENTIFIER).text;
String op = consume(TokenType.OPERATOR).text;
// 简单处理加法运算,例如 age > 10 + 8
String rightVal = consume(TokenType.NUMBER).text;
if (peek().type == TokenType.OPERATOR && peek().text.equals("+")) {
String mathOp = consume(TokenType.OPERATOR).text;
String secondNum = consume(TokenType.NUMBER).text;
// 生成未优化的表达式树
stmt.whereClause = new ExpressionNode(left, op, rightVal + mathOp + secondNum);
} else {
stmt.whereClause = new ExpressionNode(left, op, rightVal);
}
}
return stmt;
}
}
// --- 4. 基于规则的 RBO 优化器 (Rule-Based Optimizer) ---
static class RuleBasedOptimizer {
/**
* 执行逻辑改写优化:常量折叠
*/
void optimize(SelectStatementNode stmt) {
if (stmt.whereClause == null) return;
ExpressionNode where = stmt.whereClause;
// 检查右侧表达式是否包含数学计算符号
if (where.right.contains("+")) {
System.out.println("[RBO OPTIMIZER] 检测到可折叠常量算子: " + where.right);
String[] parts = where.right.split("\\+");
int val1 = Integer.parseInt(parts[0].trim());
int val2 = Integer.parseInt(parts[1].trim());
// 执行常量合并折叠 (10 + 8 -> 18)
where.right = String.valueOf(val1 + val2);
System.out.println("[RBO OPTIMIZER] 常量折叠改写完成 -> " + where.right);
}
}
}
// --- 5. 驱动测试 ---
public static void main(String[] args) {
String sql = "SELECT id, age FROM users WHERE age > 10 + 8";
System.out.println("【输入原始 SQL】: " + sql);
// 1. 词法切分
Lexer lexer = new Lexer(sql);
List<Token> tokens = lexer.tokenize();
System.out.println("【1. 词法分析 Token 流】: " + tokens);
// 2. 语法分析构建 AST
Parser parser = new Parser(tokens);
SelectStatementNode ast = parser.parse();
System.out.println("【2. 构建原始 AST 结构】: " + ast);
// 3. 执行规则优化干预
RuleBasedOptimizer optimizer = new RuleBasedOptimizer();
optimizer.optimize(ast);
System.out.println("【3. RBO 优化改写后 AST】: " + ast);
}
}
四、执行计划干预:EXPLAIN 诊断与 Hint 调优实战
在真实的 MySQL 生产调优实践中,我们无法直接重写 MySQL 的内置语法树分析器,但可以通过 EXPLAIN 工具查看优化器生成的逻辑物理计划,并使用特定的 Hint 进行强力干预。
1. EXPLAIN 执行计划核心指标解密
通过在 SQL 前加上 EXPLAIN,可重点关注以下输出列以定位瓶颈:
type(访问类型):ALL:全表扫描,开销极大,必须极力规避。index:全索引扫描,性能一般。range:索引范围扫描,常见于>、<、BETWEEN语句,性能较好。ref/eq_ref:非唯一性索引扫描 / 唯一性索引等值关联,效率极佳。
rows:执行器估算所需扫描的行数,该值越小证明物理扫描路径越优。Extra:Using filesort:说明 MySQL 无法利用索引完成排序,被迫在内存或磁盘执行文件排序,性能极差。Using temporary:使用了临时表保存中间结果,常见于GROUP BY或DISTINCT,必须优化。
2. 执行计划强行干预技术
当优化器由于统计信息陈旧而选错索引时,可采用以下物理指令进行人工纠偏:
FORCE INDEX(强行指定索引):
该 Hint 强迫优化器放弃全表扫描或其他辅助索引,只使用SELECT * FROM users FORCE INDEX (idx_age) WHERE age > 18;idx_age进行范围定位。STRAIGHT_JOIN(锁定关联顺序):
在多表关联中,MySQL 默认会计算不同的驱动表顺序。如果需要强制规定左表驱动右表,可使用该关键字:SELECT * FROM orders o STRAIGHT_JOIN customers c ON o.customer_id = c.id;- Optimizer Hints (新版优化器提示):
MySQL 8.0 引入了更为细粒度的控制,支持局部禁用特定的优化规则,如禁用索引合并(Index Merge):SELECT /*+ NO_INDEX_MERGE(users) */ * FROM users WHERE status = 1 OR age > 18;
五、总结
深刻理解 SQL 在 MySQL 执行引擎中的完整生命周期是进行底层数据库性能调优的前提。通过将 SQL 字符串打碎为 Token,并转化为层级拓扑清晰的抽象语法树(AST),MySQL 优化器得以为底层的存储引擎制定出物理开销最低的检索执行计划。在规则优化(RBO)阶段,常量折叠、谓词下推等逻辑改写技术能够有效清洗 SQL 树,消除冗余计算。而在实际工程治理中,我们需紧密结合 EXPLAIN 的 type、rows 等核心诊断指标,合理使用 FORCE INDEX 等 Hint 强行干预优化器的物理选路,才能在复杂的业务吞吐压力下构建起坚如磐石的数据底座。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)