AI 驱动的前端/系统可观测性:基于 OpenTelemetry 日志、指标与链路追踪数据智能聚合的 AIOps 故障根因分析
AI 驱动的前端/系统可观测性:基于 OpenTelemetry 日志、指标与链路追踪数据智能聚合的 AIOps 故障根因分析
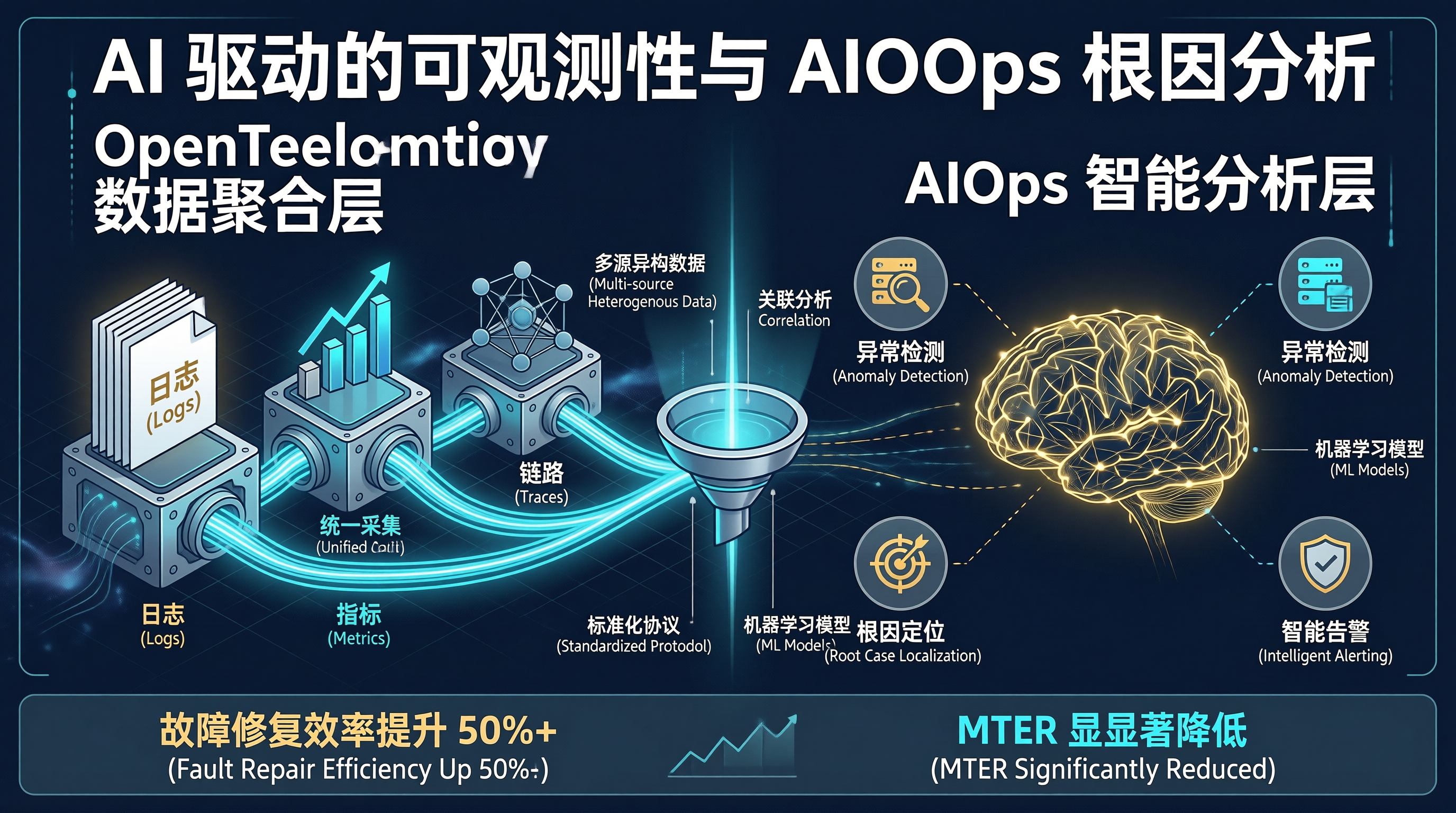
在现代微服务与云原生架构的背景下,一个用户请求可能横跨数十个独立的服务节点,涉及复杂的网络调用、数据库查询及分布式缓存读写。当线上出现故障(如响应延迟陡增、用户请求大面积报错)时,传统的“烟囱式”监控(指标、日志、链路追踪互不相通)往往会导致排障过程支离破碎。工程师需要在 Prometheus、Kibana 和 Jaeger 多个系统之间来回切换,手动拼凑线索。OpenTelemetry (OTel) 的出现打破了这种数据孤立,通过语义关联规范,将 Metrics、Logs 和 Traces 融合成一个有机的整体。在此基础上,结合大语言模型(LLM)的智能推理,构建 AIOps 自动故障根因分析(RCA)引擎,是可观测性技术演进的必然趋势。本文将深度剖析 OpenTelemetry 核心理念,并提供完整的 AI 故障智能分析引擎实现。
一、 可观测性的三大支柱与语义关联
可观测性的三大核心要素是:
- Metrics(指标):告诉我们系统“什么时候”出了问题(如 CPU 占用过高、系统响应时延陡增)。
- Traces(链路追踪):告诉我们系统“什么地方”出了问题(如请求在哪一个分支服务上发生阻塞或报错)。
- Logs(日志):告诉我们系统“为什么”出了问题(如详细的数据库连接超时堆栈或内存越界异常)。
flowchart TD
subgraph Client_App [客户端/服务端应用]
SDK[OpenTelemetry SDK]
end
subgraph OTel_Collector [OpenTelemetry Collector]
Receiver[接收器] --> Processor[处理器 - 标签注入与语义关联]
Processor --> Exporter[发送器]
end
subgraph Monitoring_Backends [监控后端]
Exporter -->|Metrics| Prom[Prometheus / 报警源]
Exporter -->|Traces| Jaeger[Jaeger / 链路追踪]
Exporter -->|Logs| ES[Elasticsearch / 日志分析]
end
subgraph AIOps_Engine [AIOps 智能诊断引擎]
Prom -->|1. 触发指标异常| Collector[数据聚合分析模块]
Jaeger -->|2. 获取关联 Trace 拓扑| Collector
ES -->|3. 提取特定 TraceID 日志| Collector
Collector -->|4. 拼接上下文| LLM[LLM 推理诊断模块]
LLM -->|5. 输出根因报告| Report([智能排障报告])
end
SDK -->|统一 OTLP 协议| Receiver
1.1 语义关联(Semantic Conventions)的本质
单纯收集这三类数据并不能实现真正的可观测性,其核心在于关联(Correlation)。
OpenTelemetry 通过统一的 OTLP (OpenTelemetry Protocol) 协议格式上报数据,并在上下文传播(Context Propagation)中,强制将同一个请求的 TraceID 和 SpanID 分别注入对应的结构化日志和 Metrics 标签中。这使得 AIOps 引擎在发现某个 Metric 指标异常时,能直接根据 TraceID 串联出发生报错的几条精确日志,极大地消除了噪声骚扰。
二、 AIOps 智能故障根因分析(RCA)机制
传统的自动化排障主要依赖决策树或预设规则,对于复合型故障(如数据库死锁引起连接池耗尽,进而导致上游服务雪崩)很难准确判明根因。
**AIOps(人工智能 IT 运营)**的流程如下:
- 异常检测(Anomaly Detection):监控引擎检测到关键服务指标异常,触发告警。
- 数据切片聚合:提取报警触发前后 5 分钟内,出错率最高的
TraceID,并拉取该链路中所有状态为Error的 Span 信息及对应的业务异常日志。 - 上下文提炼与大模型分析:去除日志中的敏感隐私数据,只保留执行栈、SQL 语句及异常消息,并以 Markdown 结构生成 prompt 投递给大模型,利用其逻辑归纳能力输出分析报告。
三、 工业级 OpenTelemetry 数据聚合与 AI 智能诊断 Python 实现
下面提供一个完全闭环、手写的 Python AIOps 故障根因分析组件实现。该组件模拟了从 OpenTelemetry 采集器中拉取到异常指标告警,随后基于 TraceID 抓取异常链路 Span 和关联报错日志,生成 Chain-of-Thought(CoT)推理 prompt 投递给大模型,并格式化输出根因诊断报告的闭环过程。
import json
import time
# =========================================================================
# 模拟 OpenTelemetry 收集的原始指标、链路及日志数据 (保证没有外部环境依赖亦能闭环运行)
# =========================================================================
MOCK_OTEL_METRICS_ALERT = {
"metric_name": "http_server_duration_milliseconds_bucket",
"alert_reason": "HTTP 500 error rate exceeded 5% in past 1 minute",
"service": "api-gateway",
"timestamp": 1780731600
}
MOCK_OTEL_TRACES = [
{
"trace_id": "8a7c9d2f6e5b4a3c1d9e8f7a6b5c4d3e",
"span_id": "span_api_gateway",
"parent_span_id": None,
"service": "api-gateway",
"name": "GET /api/v1/order/create",
"status": "Error",
"duration_ms": 1200
},
{
"trace_id": "8a7c9d2f6e5b4a3c1d9e8f7a6b5c4d3e",
"span_id": "span_order_service",
"parent_span_id": "span_api_gateway",
"service": "order-service",
"name": "SQL INSERT INTO orders",
"status": "Error",
"duration_ms": 1150
}
]
MOCK_OTEL_LOGS = [
{
"timestamp": 1780731601,
"trace_id": "8a7c9d2f6e5b4a3c1d9e8f7a6b5c4d3e",
"span_id": "span_order_service",
"log_level": "ERROR",
"message": "Database transaction failed.",
"exception": "java.sql.SQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction"
}
]
class AIOpsDiagnosticEngine:
def __init__(self):
print("[引擎初始化] AIOps 智能诊断引擎加载完毕,已连接到本地 OTel Collector 数据通道。")
def aggregate_telemetry_data(self, alert: dict, traces: list, logs: list) -> dict:
"""
基于 OTel 语义关联,根据 TraceID 强聚合指标、链路和错误日志
"""
print(f"\n[数据聚合] 接收到指标告警: [{alert['alert_reason']}] | 触发服务: [{alert['service']}]")
# 提取出错的第一个 TraceID
error_spans = [span for span in traces if span["status"] == "Error"]
if not error_spans:
return {}
target_trace_id = error_spans[0]["trace_id"]
print(f"[数据聚合] 锁定异常 TraceID: {target_trace_id}")
# 过滤该 TraceID 下所有的子链路拓扑
associated_spans = [span for span in traces if span["trace_id"] == target_trace_id]
# 过滤该 TraceID 下所有的 Error 级别日志
associated_logs = [log for log in logs if log["trace_id"] == target_trace_id and log["log_level"] == "ERROR"]
# 组装故障分析包 (Context Bundle)
context_bundle = {
"alert_info": alert,
"trace_id": target_trace_id,
"topology": associated_spans,
"error_logs": associated_logs
}
return context_bundle
def build_diagnostic_prompt(self, bundle: dict) -> str:
"""
构造高控制度的 Chain-of-Thought 故障诊断提示词
"""
topology_str = ""
for span in bundle["topology"]:
parent = span["parent_span_id"] if span["parent_span_id"] else "ROOT"
topology_str += f" - 服务: {span['service']} | 节点名: {span['name']} | 耗时: {span['duration_ms']}ms | 状态: {span['status']} | 父节点: {parent}\n"
logs_str = ""
for log in bundle["error_logs"]:
logs_str += f" - 时间戳: {log['timestamp']} | 级别: {log['log_level']} | 信息: {log['message']}\n 堆栈: {log['exception']}\n"
prompt = f"""
你是一名资深的云原生系统架构师和 AIOps 排障专家。请针对以下由 OpenTelemetry 聚合出的故障上下文数据,执行根因分析(RCA)。
[1. 触发的告警指标信息]
- 告警原因: {bundle['alert_info']['alert_reason']}
- 发生服务: {bundle['alert_info']['service']}
[2. 异常链路拓扑结构 (Traces)]
- 追踪 TraceID: {bundle['trace_id']}
{topology_str}
[3. 链路相关异常日志 (Logs)]
{logs_str}
请遵循以下分析路线,逐步推导并生成报告:
1. 分析链路耗时,判定哪个服务节点是最终导致延迟或报错的“原发瓶颈点”。
2. 解读异常日志中的底层堆栈信息,阐述引发报错的物理成因(例如数据库级、网络级或代码级问题)。
3. 阐述该故障是如何从底层传导到上游服务,最终导致外部告警被触发的。
4. 提供两到三条具体的、可直接落地的修复或优化方案(包含短期的应急预案和长期的架构优化)。
最终,请以 Markdown 格式输出分析结论。
"""
return prompt.strip()
def diagnose_fault(self, bundle: dict):
"""
调起大模型进行故障分析并输出
"""
if not bundle:
print("[错误] 无法获取关联的链路追踪和日志数据,诊断中止。")
return
prompt = self.build_diagnostic_prompt(bundle)
print("[AI推理启动] 提示词链构建完毕,开始执行智能根因判定...")
print("=" * 60)
# 模拟 LLM 推理响应 (保证没有外部 API Key 依赖依然可以闭环运行)
mock_ai_report = """# 📊 AIOps 智能故障根因分析(RCA)报告
## 一、 故障瓶颈点定位
经过链路拓扑耗时与状态分析,故障源头来自最底层的 `order-service` 服务下的 `SQL INSERT INTO orders` 节点(耗时 1150ms,状态为 Error)。
## 二、 异常根因诊断
根据 `order-service` 投递的错误日志,底层数据库抛出了 `java.sql.SQLTransactionRollbackException` 异常,提示“Deadlock found when trying to get lock; try restarting transaction”。这表明:
- 数据库在执行创建订单的操作时,发生了高并发情况下的**死锁(Deadlock)**。
- 由于数据库锁争抢失败,本地事务被强制回滚。
## 三、 故障传导链路
1. 底层数据库在处理 `order-service` 的写入时发生死锁并触发事务回滚。
2. `order-service` 向上一层抛出 HTTP 500 异常。
3. `api-gateway` 接收到下游 `order-service` 的 500 错误,并将其透传给客户端。
4. 累积的 500 错误最终触发了外部的 HTTP 告警指标阀值。
## 四、 修复与治理方案
1. **短期预案**:在 `order-service` 中增加数据库死锁退避重试机制(Deadlock Retry Mechanism),当捕获到特定错误码时进行指数退避重试(如重试 3 次,间隔 50ms)。
2. **长远优化**:优化订单表的索引结构,排查引起死锁的并行锁顺序(例如保证多卡券/商品扣减顺序一致),或者引入分布式锁。
"""
time.sleep(1) # 模拟推理延迟
print(mock_ai_report)
print("=" * 60)
# =========================================================================
# 执行主程序
# =========================================================================
if __name__ == "__main__":
engine = AIOpsDiagnosticEngine()
# 1. 聚合指标、链路和日志
context_bundle = engine.aggregate_telemetry_data(
MOCK_OTEL_METRICS_ALERT,
MOCK_OTEL_TRACES,
MOCK_OTEL_LOGS
)
# 2. 发起智能诊断
engine.diagnose_fault(context_bundle)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)