R语言线性回归
head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
| 变量名 | 中文说明 | 单位 | 含义 |
|---|---|---|---|
| Sepal.Length | 花萼长度 | cm | 花朵外层萼片的长度 |
| Sepal.Width | 花萼宽度 | cm | 花朵外层萼片的宽度 |
| Petal.Length | 花瓣长度 | cm | 花朵内层花瓣的长度 |
| Petal.Width | 花瓣宽度 | cm | 花朵内层花瓣的宽度 |
| Species | 品种 | - | 鸢尾花分类(因子型) |
3 个品种(Species)取值
setosa:山鸢尾versicolor:变色鸢尾virginica:维吉尼亚鸢尾
1、简单线性回归(1 个自变量)
用花瓣宽度 (Petal.Width) 预测 花瓣长度 (Petal.Length)
# 构建线性回归模型:y ~ x
simple_model <- lm(Petal.Length ~ Petal.Width, data = iris)
# 查看模型结果(核心输出)
summary(simple_model)Call:
lm(formula = Petal.Length ~ Petal.Width, data = iris)
Residuals:
Min 1Q Median 3Q Max
-1.33542 -0.30347 -0.02955 0.25776 1.39453
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.08356 0.07297 14.85 <2e-16 ***
Petal.Width 2.22994 0.05140 43.39 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4782 on 148 degrees of freedom
Multiple R-squared: 0.9271, Adjusted R-squared: 0.9266
F-statistic: 1882 on 1 and 148 DF, p-value: < 2.2e-16
模型结果:
- Call:模型公式
- Residuals:残差(预测值与真实值的差值)统计量
- Coefficients(核心系数):
Intercept:截距项Petal.Width:自变量系数(代表花瓣宽度每增加 1,花瓣长度平均增加 X)Pr(>|t|):p 值(<0.05 表示变量显著)
- R-squared:决定系数(越接近 1,模型拟合效果越好)
- p-value:模型整体显著性(<0.05 表示模型有效)
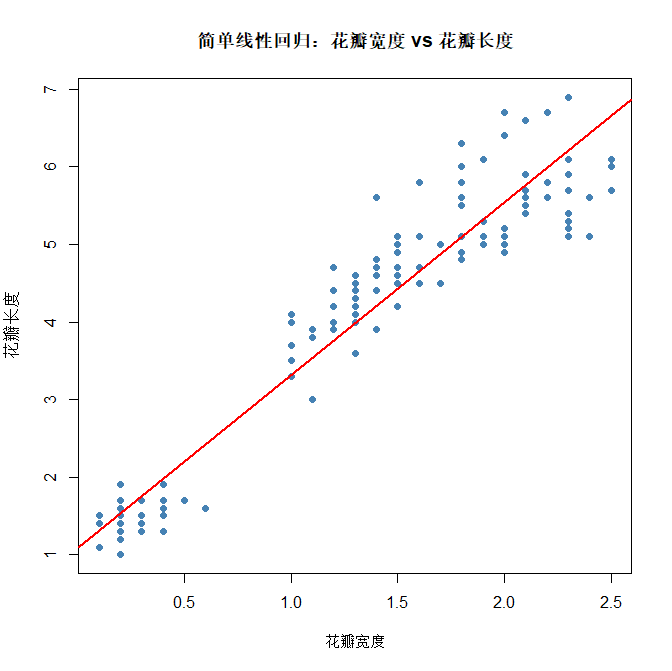
# 绘制原始数据散点图
plot(iris$Petal.Width, iris$Petal.Length,
main = "简单线性回归:花瓣宽度 vs 花瓣长度",
xlab = "花瓣宽度",
ylab = "花瓣长度",
pch = 16,
col = "steelblue")
# 添加回归拟合线
abline(simple_model, col = "red", lwd = 2)
2、多元线性回归(多个自变量)
用花萼长度、花萼宽度、花瓣宽度 共同预测 花瓣长度:
# 构建多元线性回归模型:y ~ x1 + x2 + x3
multi_model <- lm(Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width, data = iris)
# 查看模型详细结果
summary(multi_model)Call:
lm(formula = Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width,
data = iris)
Residuals:
Min 1Q Median 3Q Max
-0.99333 -0.17656 -0.01004 0.18558 1.06909
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.26271 0.29741 -0.883 0.379
Sepal.Length 0.72914 0.05832 12.502 <2e-16 ***
Sepal.Width -0.64601 0.06850 -9.431 <2e-16 ***
Petal.Width 1.44679 0.06761 21.399 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.319 on 146 degrees of freedom
Multiple R-squared: 0.968, Adjusted R-squared: 0.9674
F-statistic: 1473 on 3 and 146 DF, p-value: < 2.2e-16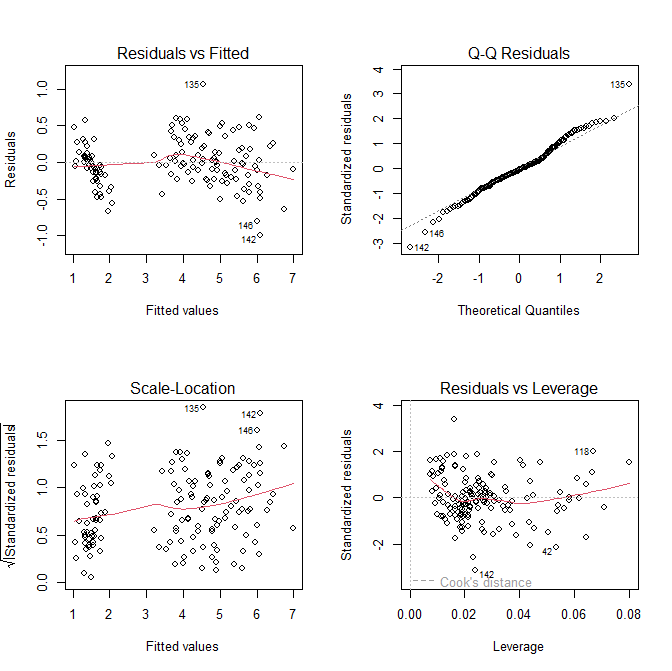
第 1 张图:Residuals vs Fitted(残差 vs 拟合值)
看是否真的存在线性关系 + 方差是否均匀
- 中间红线要尽量水平 → 满足线性关系
- 点要随机均匀分布在红线上下 → 没有规律
- 不能出现漏斗形、曲线形
第 2 张图:Normal Q-Q(正态 Q-Q 图)
看残差是否符合正态分布(回归模型的重要假设)
- 点要紧紧贴在对角线上
- 两头稍微偏离没关系,中间必须贴紧
第 3 张图:Scale-Location(标准差拟合图)
检验方差齐性(误差大小是否均匀)
- 红线要水平
- 点不要出现越来越散开 / 越来越集中的漏斗形状
第 4 张图:Residuals vs Leverage(残差 vs 杠杆值)
找异常点 / 强影响点
- 绝大多数点要落在中间区域
- 没有点超出右侧虚线(Cook 距离)
- 就算有点偏,只要没超出虚线就没事
3、预测
new_data <- data.frame(
Sepal.Length = c(5.1, 6.2),
Sepal.Width = c(3.5, 2.9),
Petal.Width = c(0.2, 1.3)
)
pred_vals <- predict(multi_model, new_data) 1 2
1.484210 4.265343
可以看到:
第1朵:花萼长5.1,花萼宽3.5,花瓣宽0.2,预测的花瓣长度是1.48
第2朵:花萼长6.2,花萼宽2.9,花瓣宽1.3,预测的花瓣长度是4.27
# 绘制真实数据散点图 + 预测点(红色星星)
plot(iris$Petal.Width, iris$Petal.Length,
main = "鸢尾花花瓣宽度 vs 长度(含预测点)",
xlab = "花瓣宽度", ylab = "花瓣长度",
pch = 16, col = "steelblue", cex = 1.2)
# 画回归直线
abline(lm(Petal.Length ~ Petal.Width, data=iris), col = "red", lwd=2)
# 把你的两个预测点标成红色大星星
points(new_data$Petal.Width, pred_vals,
col = "red", pch = 8, cex = 3, lwd=3)
# 给点加文字
text(new_data$Petal.Width, pred_vals,
labels = round(pred_vals, 2),
pos = 3, col = "red", cex = 1.5)
# 加图例
legend("topleft",
legend = c("真实数据", "回归直线", "预测点"),
pch = c(16, NA, 8),
lty = c(NA, 1, NA),
col = c("steelblue", "red", "red"),
lwd = 2)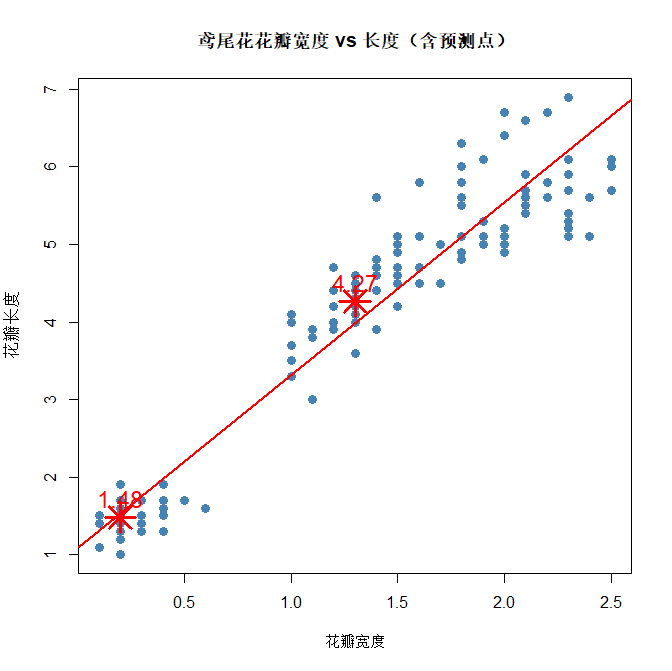

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)