Codex 开始讲工作流后,AI 办公提效也该从 Prompt 升级到流程设计
OpenAI 最近把 Codex 放进“every role, tool, and workflow”这个语境里讨论,这个信号值得开发者和技术运营关注。它说明 AI 工具正在从“单个能力”进入“流程连接”:不是只帮你生成一段代码、一段文案或一个分析结论,而是要连接团队已有工具、上下文和交付材料。
这对办公场景尤其重要。
很多人说 AI 办公提效,其实还停留在聊天式用法:
```text
帮我整理一下这些信息。
帮我写一个汇报。
帮我分析一下用户反馈。
帮我把这个需求分类。
```
这种用法能省一点时间,但它很难稳定复用。
今天你问得详细,结果还不错;明天换一个同事问,输出格式就变了;后天数据源多一点,AI 又开始漏字段;再过一周,没人知道之前那版 Prompt 为什么这样写。
所以,AI 办公提效真正要升级的,不是把 Prompt 写得更长,而是把任务做成流程。
在 CSDN 语境下,可以把它理解成一个轻量级 Pipeline:
```text
原始材料
↓
任务识别
↓
Prompt 模板
↓
结构化输出
↓
人工审核
↓
沉淀到业务系统
↓
日志与回滚
```
这篇不讨论“哪个 AI 办公工具最好”,而是讨论一个更工程化的问题:
如何把 AI 办公任务设计成可复用、可审计、可回滚的工作流?
## 一、为什么办公任务不能只靠“临时问 AI”
很多办公任务看起来简单,但真正接入流程后会变复杂。
比如产品运营每天收到各种信息:
- App 内用户反馈;
- 客服转来的问题;
- 社群里的吐槽;
- 销售记录的客户需求;
- 竞品页面变化;
- 线上活动数据异常。
你让 AI “整理一下”,它当然能整理。
但工程上会遇到几个问题:
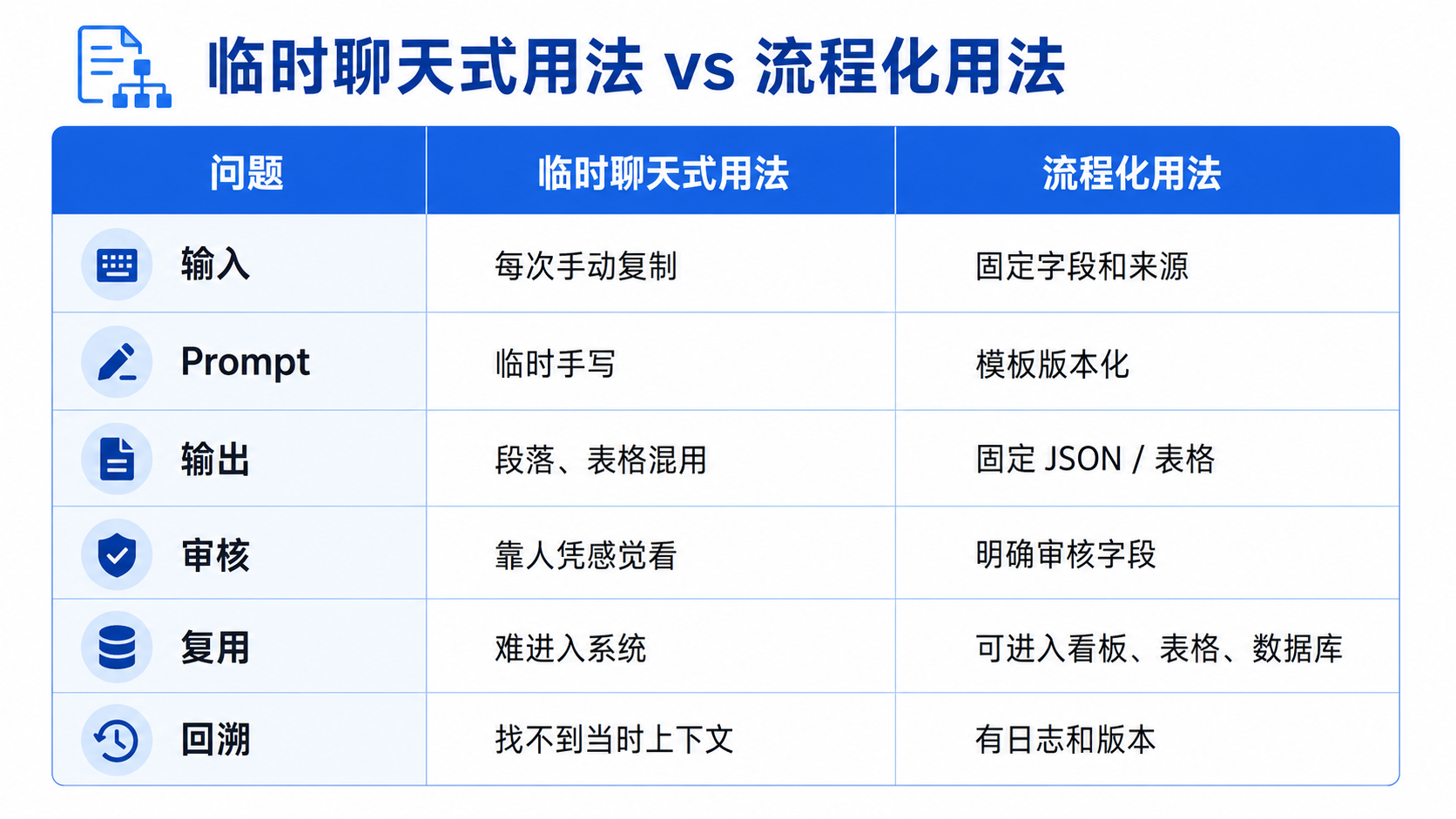
如果你的目标只是偶尔省几分钟,临时聊天没问题。
但如果你要让团队每天都用,临时聊天就不够了。
## 二、选一个具体场景:产品运营日报线索初筛
为了避免泛泛而谈,我们选一个具体场景:产品运营日报线索初筛。
假设一个产品运营团队每天要从用户反馈、客服记录和活动数据里提取“需要关注的线索”。这些线索可能包括:
- 某个功能频繁被投诉;
- 某个页面转化异常;
- 用户对价格或权益理解有偏差;
- 某个新功能被夸,但使用门槛偏高;
- 某类问题需要产品、客服、技术一起看。
这个任务不适合完全交给 AI 决策,但很适合让 AI 做第一轮结构化初筛。
### 输入示例
```json
{
"date": "2026-06-06",
"source": "daily_operation_notes",
"items": [
{
"channel": "customer_service",
"content": "今天有 18 个用户问为什么新功能入口找不到,其中 7 个用户截图显示仍在旧版本页面。"
},
{
"channel": "community",
"content": "社群里有用户说新模板挺好用,但不知道适合哪些场景。"
},
{
"channel": "event_data",
"content": "活动页点击率正常,但提交转化比昨天低 23%。"
}
]
}
```
你希望 AI 输出的不是一段“总结”,而是结构化线索:
```json
{
"date": "2026-06-06",
"signals": [
{
"signal_type": "feature_access_issue",
"summary": "部分用户找不到新功能入口",
"evidence": "18 个用户咨询,其中 7 个截图显示旧版本页面",
"priority": "high",
"suggested_owner": "product, customer_service",
"needs_human_review": true
}
]
}
```
这样输出后,才有机会进入后续系统,比如飞书表格、Notion 数据库、内部看板或运营日报。
## 三、Prompt 模板:把“整理一下”改成“按字段抽取”
错误写法通常是:
```text
帮我整理今天的运营信息,看看有什么值得关注的问题。
```
它的问题是:输出不稳定、字段不固定、审核困难。
更适合流程化办公的 Prompt 应该这样写:
```text
你是一个产品运营线索初筛助手。
任务:
从输入的运营记录中抽取“需要团队关注的线索”。
线索包括:
1. 高频用户问题
2. 功能入口或使用障碍
3. 数据异常
4. 用户理解偏差
5. 需要跨部门处理的问题
要求:
1. 不要编造输入中不存在的信息。
2. 每条线索必须引用 evidence。
3. 不要给最终决策,只给建议优先级。
4. 如果信息不足,请标记 uncertain。
5. 输出必须是 JSON,不要输出 Markdown。
输出字段:
{
"date": "string",
"signals": [
{
"signal_type": "string",
"summary": "string",
"evidence": "string",
"priority": "low | medium | high | uncertain",
"suggested_owner": "string",
"needs_human_review": true
}
],
"uncertain": []
}
```
注意这里的关键点:
1. 它不是让 AI “发挥”;
2. 它要求 AI 引用 evidence;
3. 它明确 AI 不做最终决策;
4. 它强制 JSON 输出;
5. 它保留人工审核节点。
这就是办公提效从“会问问题”到“会设计流程”的区别。
## 四、用 JSON Schema 固定输出,减少后续处理成本
如果你要把 AI 输出接入系统,就不能只靠肉眼看格式。
可以给它定义一个 Schema,再做校验。
下面是一个简化版 JSON Schema:
```json
{
"type": "object",
"required": ["date", "signals", "uncertain"],
"properties": {
"date": {
"type": "string"
},
"signals": {
"type": "array",
"items": {
"type": "object",
"required": [
"signal_type",
"summary",
"evidence",
"priority",
"suggested_owner",
"needs_human_review"
],
"properties": {
"signal_type": { "type": "string" },
"summary": { "type": "string" },
"evidence": { "type": "string" },
"priority": {
"type": "string",
"enum": ["low", "medium", "high", "uncertain"]
},
"suggested_owner": { "type": "string" },
"needs_human_review": { "type": "boolean" }
}
}
},
"uncertain": {
"type": "array"
}
}
}
```
配合 Python,可以简单做一次结构校验:
```python
import json
from jsonschema import validate, ValidationError
schema = {
"type": "object",
"required": ["date", "signals", "uncertain"],
"properties": {
"date": {"type": "string"},
"signals": {
"type": "array",
"items": {
"type": "object",
"required": [
"signal_type",
"summary",
"evidence",
"priority",
"suggested_owner",
"needs_human_review"
],
"properties": {
"signal_type": {"type": "string"},
"summary": {"type": "string"},
"evidence": {"type": "string"},
"priority": {
"type": "string",
"enum": ["low", "medium", "high", "uncertain"]
},
"suggested_owner": {"type": "string"},
"needs_human_review": {"type": "boolean"}
}
}
},
"uncertain": {"type": "array"}
}
}
ai_result = {
"date": "2026-06-06",
"signals": [
{
"signal_type": "feature_access_issue",
"summary": "部分用户找不到新功能入口",
"evidence": "18 个用户咨询,其中 7 个截图显示旧版本页面",
"priority": "high",
"suggested_owner": "product, customer_service",
"needs_human_review": True
}
],
"uncertain": []
}
try:
validate(instance=ai_result, schema=schema)
print("结构校验通过,可以进入人工审核")
except ValidationError as e:
print("结构校验失败:", e.message)
```
### 输出示例
```text
结构校验通过,可以进入人工审核
```
这样做的意义不是“炫技”,而是减少办公自动化里的隐性成本。
如果 AI 输出格式乱,后续同事就要手工改;如果字段固定,结果就能进入数据库、看板或审核表。
## 五、增加“人工审核字段”,不要让 AI 直接替团队下结论
办公场景里,最容易犯的错误是让 AI 给最终结论。
比如:
```text
这个问题是不是很严重?
这个需求要不要排期?
这个活动是不是失败了?
这个用户反馈是不是代表多数人?
```
这些问题可以让 AI 辅助分析,但不应该直接由 AI 拍板。
更稳妥的设计是:让 AI 输出建议,但必须留下人工审核字段。
```json
{
"signal_type": "conversion_drop",
"summary": "活动页提交转化较昨日下降 23%",
"evidence": "活动页点击率正常,但提交转化比昨天低 23%",
"priority": "medium",
"suggested_owner": "operation, data",
"needs_human_review": true,
"human_review_result": null
}
```
等人工审核后,再补充:
```json
{
"human_review_result": {
"status": "confirmed",
"reviewer": "operation_lead",
"comment": "需要排查表单加载速度和用户来源变化",
"next_action": "create_follow_up_task"
}
}
```
这一步的价值是:
AI 可以加速发现问题,但最终责任仍然在团队流程里。
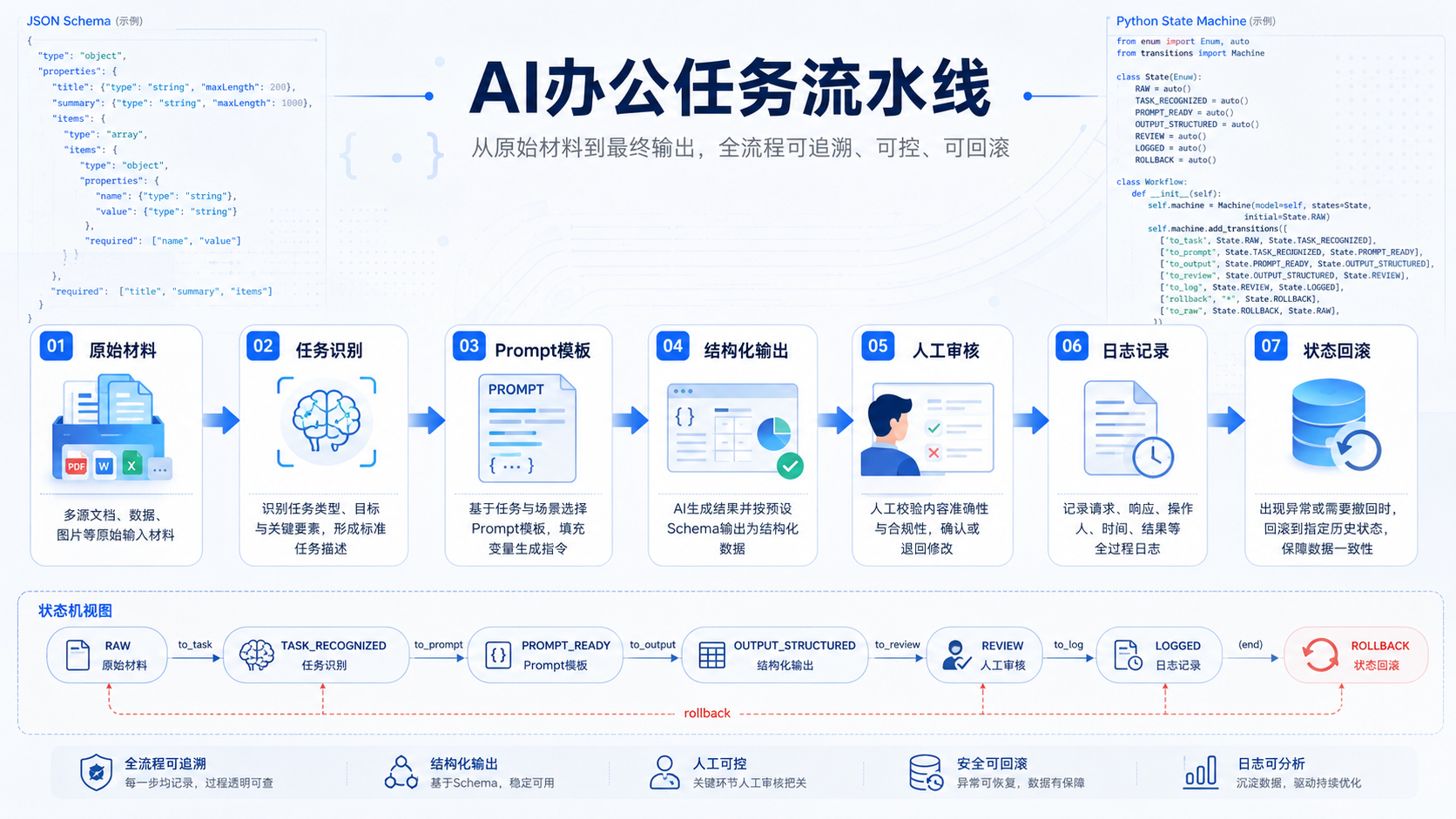
## 六、日志设计:办公流程也需要可审计
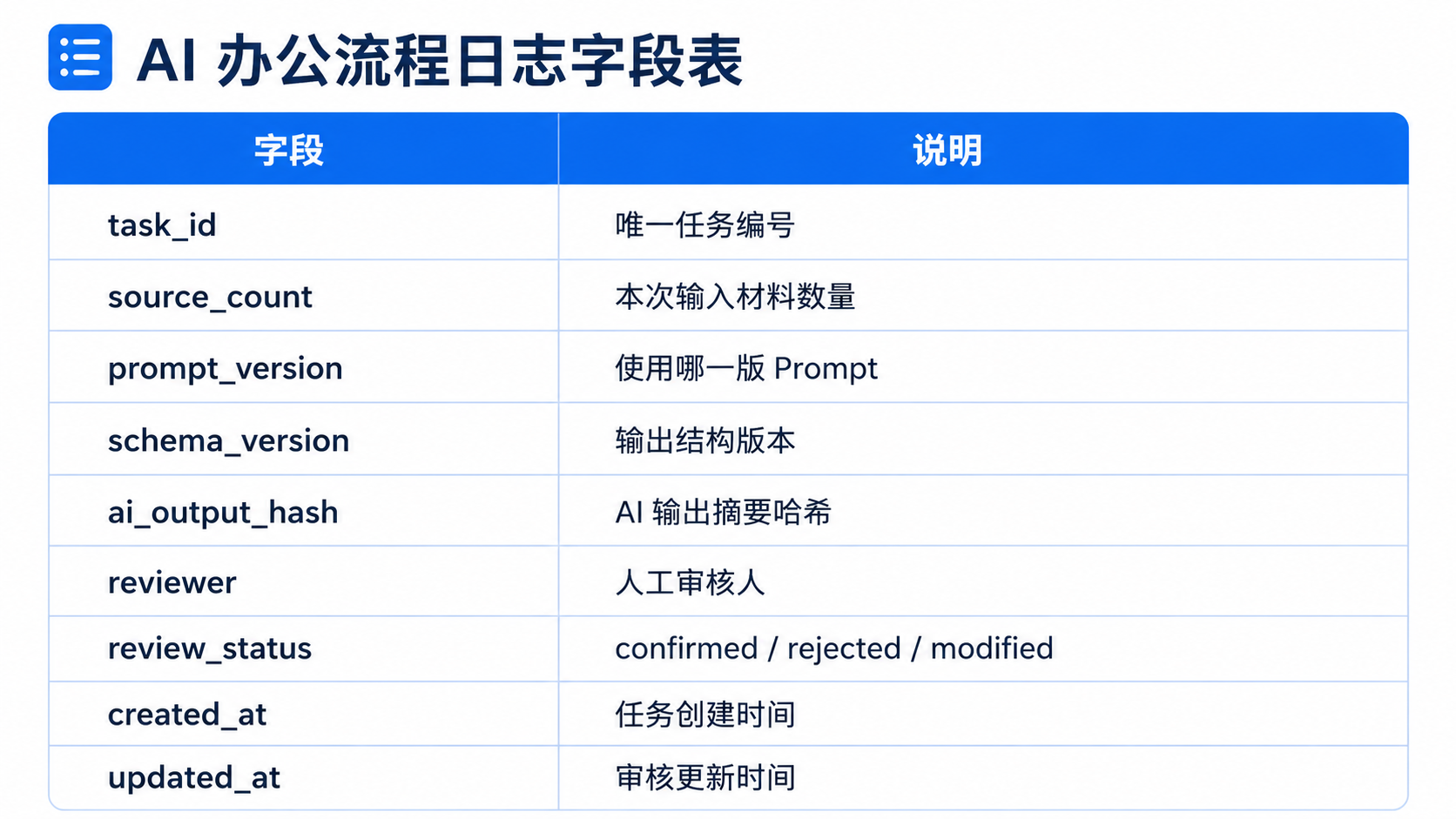
如果 AI 每天参与日报线索初筛,你至少要记录:
这样可以解决几个实际问题:
1. 哪版 Prompt 误报最多?
2. 哪类输入最容易让 AI 漏掉信息?
3. 哪个审核人经常修改 AI 结论?
4. 某次日报为什么把一个问题升级为高优先级?
5. 后续复盘时能不能找到当时的输入和输出?
一个简化日志示例:
```json
{
"task_id": "ops_signal_20260606_001",
"source_count": 3,
"prompt_version": "ops_signal_v1.0",
"schema_version": "ops_signal_schema_v1",
"ai_output_hash": "sha256:ab12cd34",
"reviewer": "operation_lead",
"review_status": "modified",
"created_at": "2026-06-06T10:00:00+08:00",
"updated_at": "2026-06-06T10:25:00+08:00"
}
```
办公提效不是只看“生成快不快”。
当 AI 进入团队流程后,你还要看它是否可追踪、可复盘、可优化。
## 七、回滚机制:AI 输出错了,怎么撤回?
很多团队设计 AI 流程时,只想到了“怎么生成”,没想到“怎么撤回”。
但办公场景一定会遇到错误:
- AI 把用户情绪当成事实;
- AI 把少量反馈当成普遍问题;
- AI 错分任务负责人;
- AI 漏掉高风险信息;
- AI 输出格式通过了,但业务含义错了。
所以流程里要有回滚机制。
可以用一个简单状态机管理:
```text
draft → ai_processed → human_reviewed → published
↓
rejected
↓
revised
```
对应伪代码:
```python
VALID_TRANSITIONS = {
"draft": ["ai_processed"],
"ai_processed": ["human_reviewed", "rejected"],
"rejected": ["revised"],
"revised": ["ai_processed"],
"human_reviewed": ["published"],
"published": []
}
def can_transition(current_status, next_status):
return next_status in VALID_TRANSITIONS.get(current_status, [])
print(can_transition("ai_processed", "published")) # False
print(can_transition("ai_processed", "human_reviewed")) # True
```
### 输出示例
```text
False
True
```
这里的重点是:
AI 处理后的内容不能直接 published。
必须经过 human_reviewed。
这类状态机虽然简单,但能有效防止 AI 输出直接进入最终交付。
## 八、传统办公 vs AI 流程化办公
很多人理解 AI 办公提效,只理解成“让 AI 帮我写”。
但流程化办公更像是把 AI 放进一个固定节点。
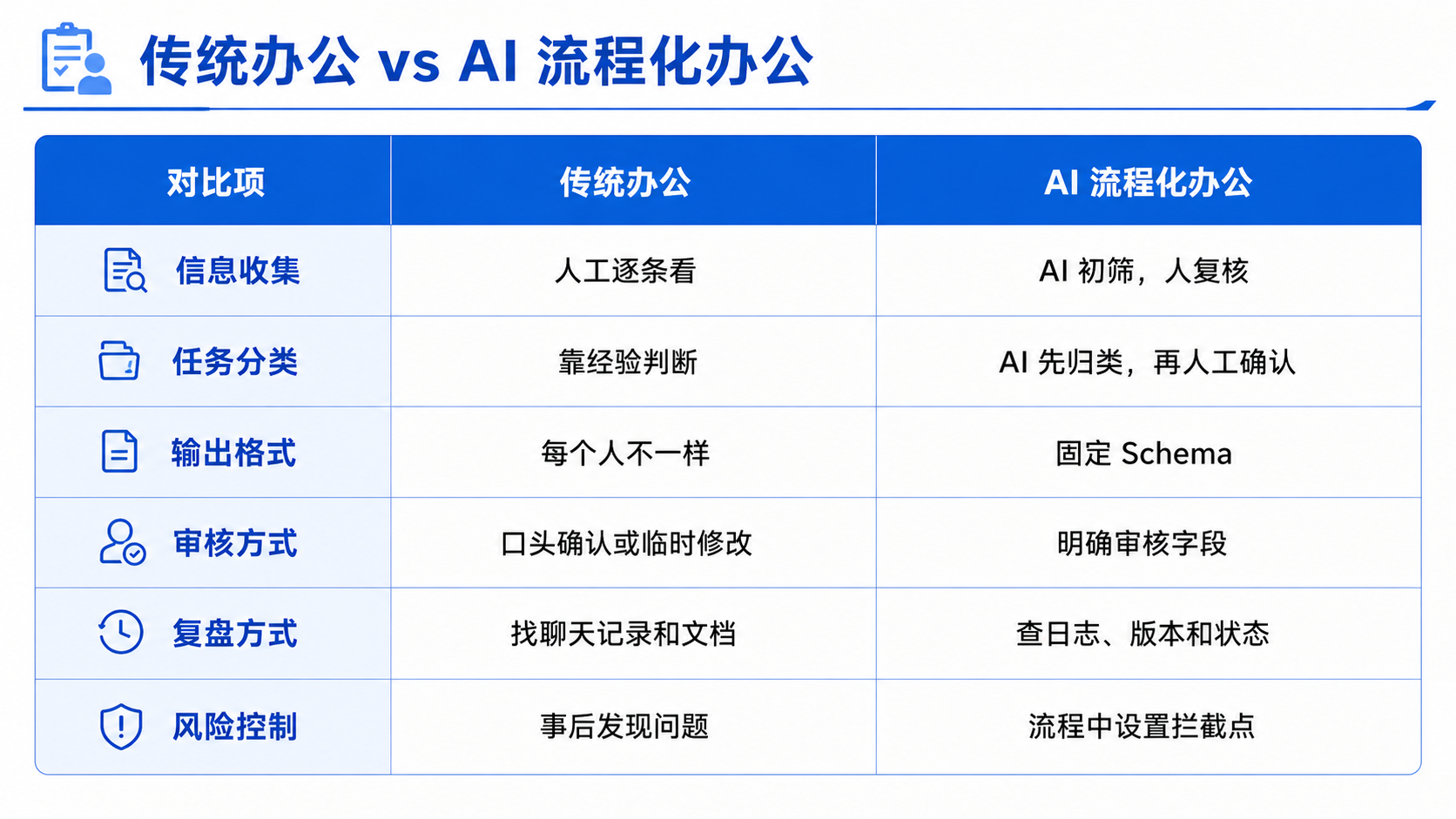
真正提高效率的,不是让 AI 多生成,而是让它减少混乱。
## 九、工程边界:哪些办公任务不适合直接自动化?
即使 AI 越来越强,也不是所有办公任务都适合自动化。
建议分成三类:
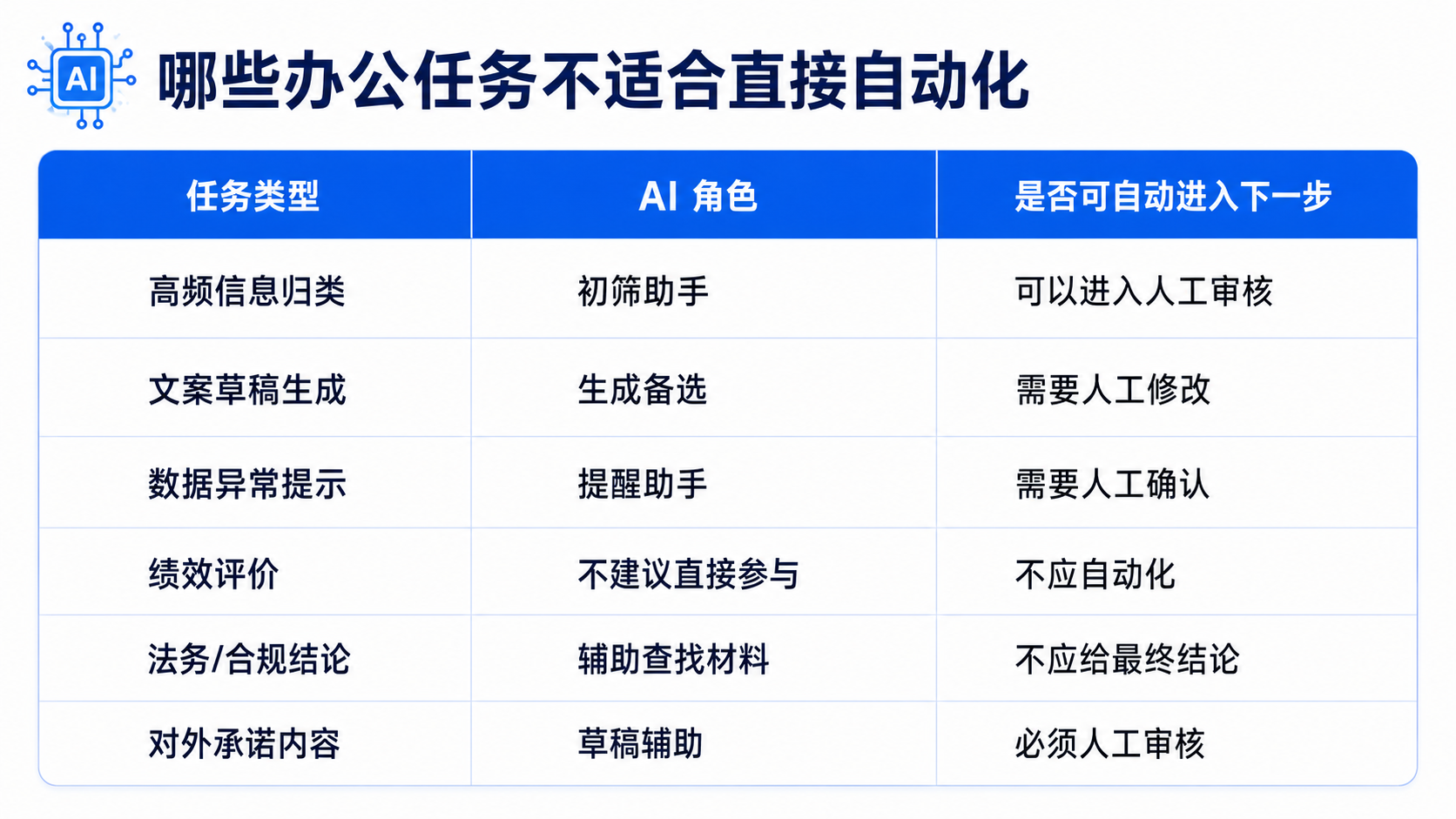
办公场景同样如此。
如果你让 AI 直接改表、发通知、同步客户、发布内容,就必须提前定义权限和审批节点。
## 十、一个最小可用的 AI 办公流程模板
如果你想在团队里落地,可以从下面这个最小流程开始:
```text
Step 1:选择一个高频但低风险的办公任务
Step 2:整理输入字段
Step 3:写 Prompt 模板
Step 4:定义 JSON 输出结构
Step 5:增加 Schema 校验
Step 6:加入人工审核字段
Step 7:记录日志
Step 8:设置状态机,禁止 AI 直接发布
Step 9:试运行一周
Step 10:统计误报、漏报和人工修改率
```
评估指标可以这样设计:
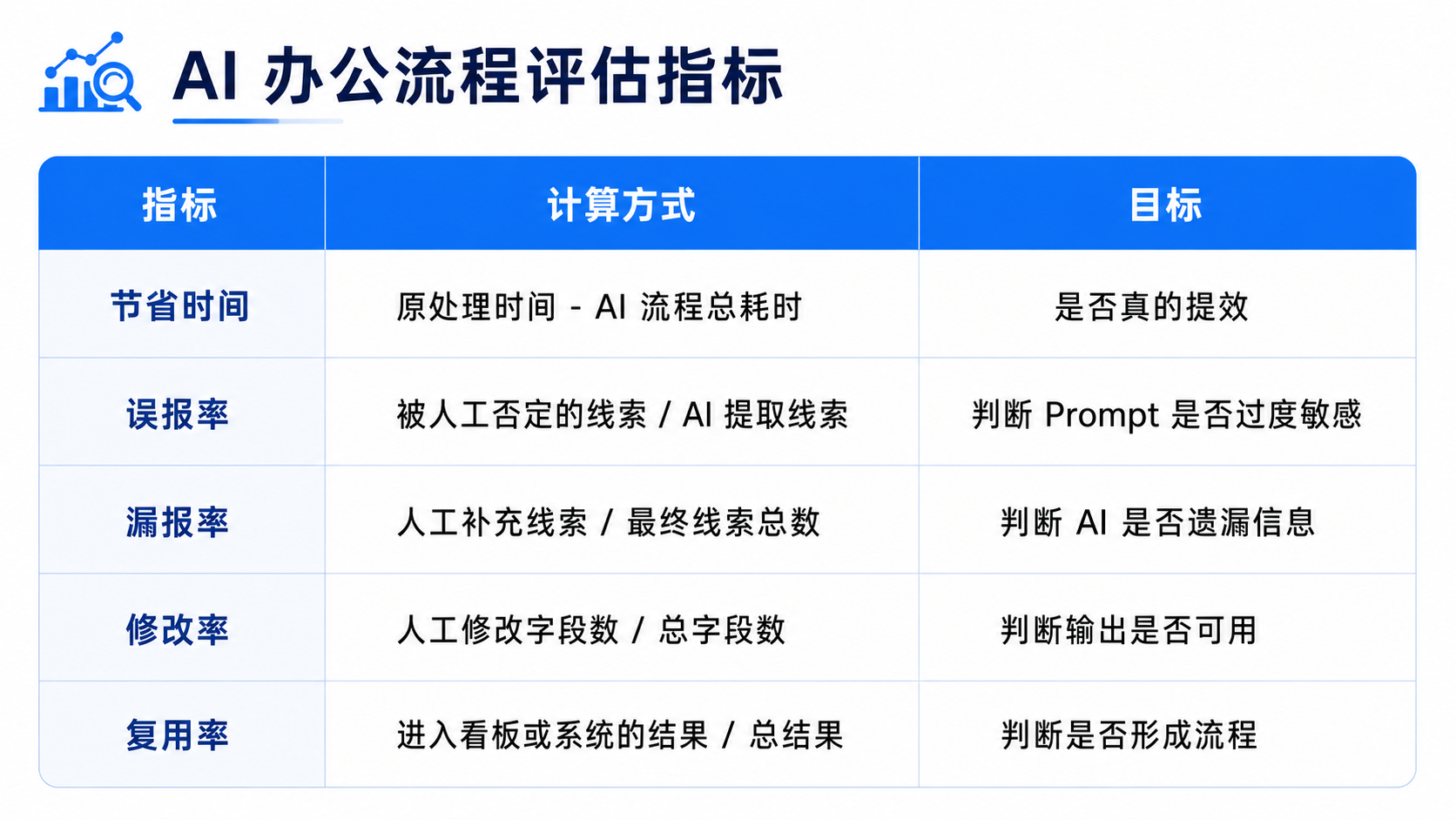
如果只看“AI 生成了多少字”,这个流程大概率会跑偏。
如果看时间、误报、漏报、修改率和复用率,才能知道它有没有真实价值。
## 结论:AI 办公提效的下一步,不是更多 Prompt,而是更稳的流程
Codex 被放进角色、工具和工作流语境后,一个明显趋势是:AI 工具正在从单点能力,走向流程连接。
对开发者和技术运营来说,这意味着办公提效不能只停留在“我会问 AI”。
更重要的是:
```text
任务能否结构化?
输出能否复用?
审核能否保留?
日志能否追踪?
错误能否回滚?
权限是否受控?
```
只要这些问题没解决,AI 生成得再快,也很难真正进入团队流程。
反过来,如果你把输入、Prompt、Schema、审核、日志、状态机都设计好,哪怕只是一个很小的办公任务,也能跑出稳定价值。
如果你正在做 GPT办公提效,或者希望把 AI 用在日常资料整理、运营线索初筛、内容草稿和团队协作里,可以把 gpt0424.com 当作办公场景和流程设计的参考入口。重点不是一上来追求“全自动”,而是先找到一个高频、低风险、可复核的任务,把流程跑通。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)