【无标题】
EarthGPT 论文技术博客(内嵌全套原文公式,沿用你既定01~06目录结构)
01 论文信息
论文标题:EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain
预印本来源:arXiv:2401.16822
开源仓库:https://github.com/wivizhang/EarthGPT
研究定位:面向光学/SAR/红外多源遥感影像的通用多模态大模型,单模型统一实现遥感分类、图像描述、VQA、水平/旋转框目标检测五大任务,配套自研百万级遥感多模态指令数据集MMRS-1M。
02 论文主要贡献
- 模型架构创新:提出三段式EarthGPT流水线,基于LLaMA2基座,设计CNN+ViT双骨干视觉增强编码器,以轻量化偏置微调实现多传感器遥感域适配,一套模型兼容全遥感下游任务。
- 数据集工程:构建MMRS-1M百万遥感图文指令数据集,整合34套公开遥感数据源,覆盖光学、SAR、红外三类成像数据,补齐遥感多模态指令数据短板。
- 两阶段微调范式:先依托LAION/COCO通用图文做跨模态预对齐,再基于MMRS-1M做遥感指令微调;仅解冻少量参数,在极低训练开销下实现遥感零样本SOTA效果。
- 全面实测验证:在分类、VQA、图像Caption、开集检测、旋转目标检测五大类遥感基准数据集开展对比,全面优于LLaVA、Qwen-VL等通用多模态模型与传统遥感专项算法。
- 落地拓展:模型具备链式推理纠错能力,可依靠目标计数结果修正漏检目标,支撑国土监测、灾害解译等交互式遥感智能应用。

03 论文创新点
3.1 任务适配性理论分析
现存行业痛点
- 传统遥感算法为单任务定制模型,分类、检测、问答需要独立网络,部署冗余;
- 现有遥感专用多模态模型(GeoChat、RS-GPT)仅适配可见光光学影像,无法处理SAR、红外异源遥感数据;
- LLaVA、Qwen-VL等通用多模态大模型基于自然图像预训练,遥感地物尺度、成像机理、纹理分布差异大,零样本遥感推理精度极低;
- 缺少大规模多模态遥感指令数据集,无法高效完成大模型域微调。
EarthGPT适配理论
从特征提取、跨模态对齐、指令微调三层逐级缩小自然图像与多源遥感数据的域偏移:
- 视觉层:ViT全局语义+CNN多尺度细节融合,弥补遥感地物大小跨度大、细节碎片化问题;
- 跨模态层:仅开放注意力层与归一化层训练,在通用图文空间完成图文语义绑定;
- 微调层:轻量化Bias+Linear参数微调,在保留基座LLM语言能力的前提下适配遥感专属语义。
3.2 极简架构设计
整体三阶段模块化设计,冻结LLaMA2主干绝大部分权重,无大规模重训练:
- 视觉增强模块:DINOv2-ViT + CLIP-ConvNeXt双骨干全程冻结,仅训练后续投影层;
- 跨模态对齐模块:仅解冻Transformer中Self-Attention与RMSNorm,FFN、主体Transformer权重冻结;
- 遥感指令微调模块:全量冻结原始LLM权重,仅新增少量Bias与Linear可学习参数,微调参数量不足总参数5%,轻量化易部署。
3.3 大规模实验验证

- 多模态数据源全覆盖:光学、SAR、红外三类遥感影像,覆盖分类、检测、VQA、图像描述、视觉定位全任务数据集;
- 多基线横向对比:三类对照组——传统遥感专用CNN算法、通用开源多模态大模型、现有遥感领域MLLM;
- 双评测场景:监督训练+零样本开集评测,在CLRS、NaSC-TG2零样本分类数据集领先基线20%以上;
- 消融实验闭环:双骨干消融、微调策略消融、数据集组分消融,逐项验证各模块有效性,搭配案例可视化验证链式纠错推理能力。
04 方法
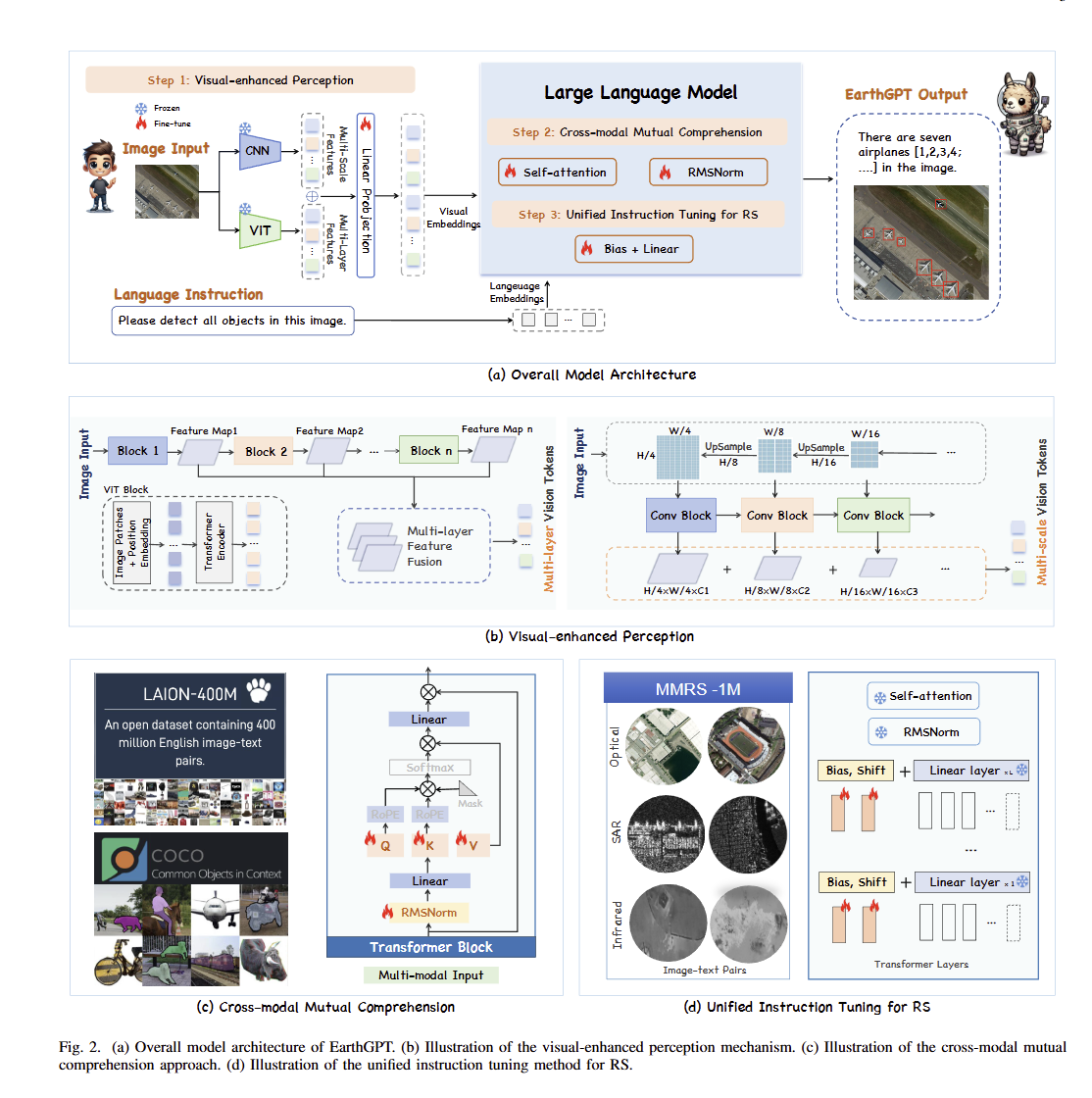
4.1 整体架构
输入遥感图像+自然语言指令,经三模块处理,以自然文本形式输出分类、坐标、描述等结果。
4.2 视觉增强感知(论文式1~7)
4.2.1 详细流程
ViT多层特征提取
Va1=ViTBlock1(I)(1)V_{a}^{1}=ViTBlock_{1}(I)\tag{1}Va1=ViTBlock1(I)(1)
Vai=ViTBlocki(Vai−1),i=2,...,n(2)V_{a}^{i}=ViTBlock_{i}\left(V_{a}^{i-1}\right), i=2, ..., n\tag{2}Vai=ViTBlocki(Vai−1),i=2,...,n(2)
Va=Concat[Va1,Va2,...Van](3)V_{a}=Concat\left[ V_{a}^{1}, V_{a}^{2}, ... V_{a}^{n}\right] \tag{3}Va=Concat[Va1,Va2,...Van](3)
公式释义
III:原始遥感输入图像;ViTBlockiViTBlock_iViTBlocki:第iii层ViT编码器;VaiV_a^iVai:第iii层输出特征;VaV_aVa:多层特征拼接后的全局粗粒度语义特征,负责捕获遥感全局场景信息。
CNN多尺度特征提取
Vb1=ConvBlock1(I1)(4)V_{b}^{1}=ConvBlock_{1}\left(I_{1}\right)\tag{4}Vb1=ConvBlock1(I1)(4)
Vbi=ConvBlocki(Vbi−1),i=2,...,m(5)V_{b}^{i}=ConvBlock_{i}\left(V_{b}^{i-1}\right), i=2, ..., m\tag{5}Vbi=ConvBlocki(Vbi−1),i=2,...,m(5)
Vb=Concat[Vb1,Vb2,...Vbm](6)V_{b}= Concat \left[V_{b}^{1}, V_{b}^{2}, ... V_{b}^{m}\right]\tag{6}Vb=Concat[Vb1,Vb2,...Vbm](6)
公式释义
I1I_1I1:缩放后的多尺度图像;ConvBlockiConvBlock_iConvBlocki:卷积模块;VbiV_b^iVbi:单尺度卷积特征;VbV_bVb:多尺度特征拼接,提取地物边缘、纹理等细粒度细节。
特征融合投影
Vp=Projection(Concat(Va,Vb))(7)V_{p}=Projection\left(Concat\left(V_{a}, V_{b}\right)\right) \tag{7}Vp=Projection(Concat(Va,Vb))(7)
公式释义
将ViT全局特征VaV_aVa、CNN细节特征VbV_bVb拼接,通过可学习Projection投影层统一特征维度,生成最终视觉Token VpV_pVp。ViT、CNN预训练权重全程冻结,仅训练投影层参数。
4.2.2 关键细节
ViT擅长全局场景语义,CNN擅长局部细碎地物,二者互补适配遥感尺度多变特点。
4.3 跨模态互理解(论文式8~14)
4.3.1 详细流程
图文Token拼接
X=Concat[Vp1,Vp2,...,VpNv⏞visualtokensVp,Lp1,Lp2,...,LpNl⏟languagetokensLp](8)\mathcal{X}=Concat[\overbrace{V_{p}^{1}, V_{p}^{2}, ..., V_{p}^{N_{v}}}^{visual tokens V_{p}}, \underbrace{L_{p}^{1}, L_{p}^{2}, ..., L_{p}^{N_{l}}}_{language tokens L_{p}}] \tag{8}X=Concat[Vp1,Vp2,...,VpNv
visualtokensVp,languagetokensLp
Lp1,Lp2,...,LpNl](8)
公式释义
NvN_vNv:视觉token数量,NlN_lNl:文本指令token数量;X\mathcal{X}X:拼接完成的多模态输入序列,送入Transformer。
QKV计算
Q(x)=Wqx+bq(9)Q(x)=W_{q} x+b_{q}\tag{9}Q(x)=Wqx+bq(9)
K(x)=Wkx+bk(10)K(x)=W_{k} x+b_{k}\tag{10}K(x)=Wkx+bk(10)
V(x)=Wvx+bv(11)V(x)=W_{v} x+b_{v}\tag{11}V(x)=Wvx+bv(11)
公式释义
Wq,Wk,Wv、bq,bk,bvW_q,W_k,W_v、b_q,b_k,b_vWq,Wk,Wv、bq,bk,bv分别为Q/K/V对应的权重与偏置,本阶段仅更新该部分参数,其余主干权重冻结。
RMSNorm归一化
y=xMean(x2)+ε∗γ,Mean(x2)=1N∑i=1Nxi2y=\frac{x}{\sqrt{Mean\left(x^{2}\right)}+\varepsilon} * \gamma,\quad Mean(x^2)=\frac{1}{N} \sum_{i=1}^{N} x_{i}^{2}y=Mean(x2)+εx∗γ,Mean(x2)=N1i=1∑Nxi2
公式释义
xxx为输入特征,γ\gammaγ是可学习缩放系数,ε\varepsilonε防止分母为0;RMSNorm层参数同步参与训练。
训练损失函数
L=−∑i=1NvllogP(wi∣(w1,w2...wi−1;θ)(14)\mathcal{L}=-\sum_{i=1}^{N_{v l}} log P\left(w_{i} |\left(w_{1}, w_{2} ... w_{i-1} ; \theta\right)\right.\tag{14}L=−i=1∑NvllogP(wi∣(w1,w2...wi−1;θ)(14)
公式释义
标准自回归交叉熵损失;NvlN_{vl}Nvl是多模态序列总长,θ\thetaθ代表模型可训练参数;依靠LAION、COCO通用图文数据完成图文语义对齐。
4.3.2 关键细节
仅解冻自注意力与RMSNorm,FFN全冻结,在保留LLM原生语言能力前提下实现跨模态对齐。
4.4 统一遥感指令微调(论文式15、16)
y(x)=α⋅(Wx+β)(15)y(x)=\alpha \cdot (Wx+\beta ) \tag{15}y(x)=α⋅(Wx+β)(15)
α∼N(μ,σ2),β=Init(0)(16)\alpha \sim \mathcal{N}\left(\mu, \sigma^{2}\right), \beta=Init(0) \tag{16}α∼N(μ,σ2),β=Init(0)(16)
公式释义
WWW:LLaMA原始线性层权重全程冻结;α\alphaα为高斯分布初始化缩放系数,β\betaβ初始值设为0;仅α、β\alpha、\betaα、β两个参数参与MMRS-1M数据集微调,用式(14)作为微调损失。
4.4.2 关键细节
只新增微量参数,算力开销极低,在不破坏预训练语言知识的前提下适配遥感领域特征。
05 实验分析
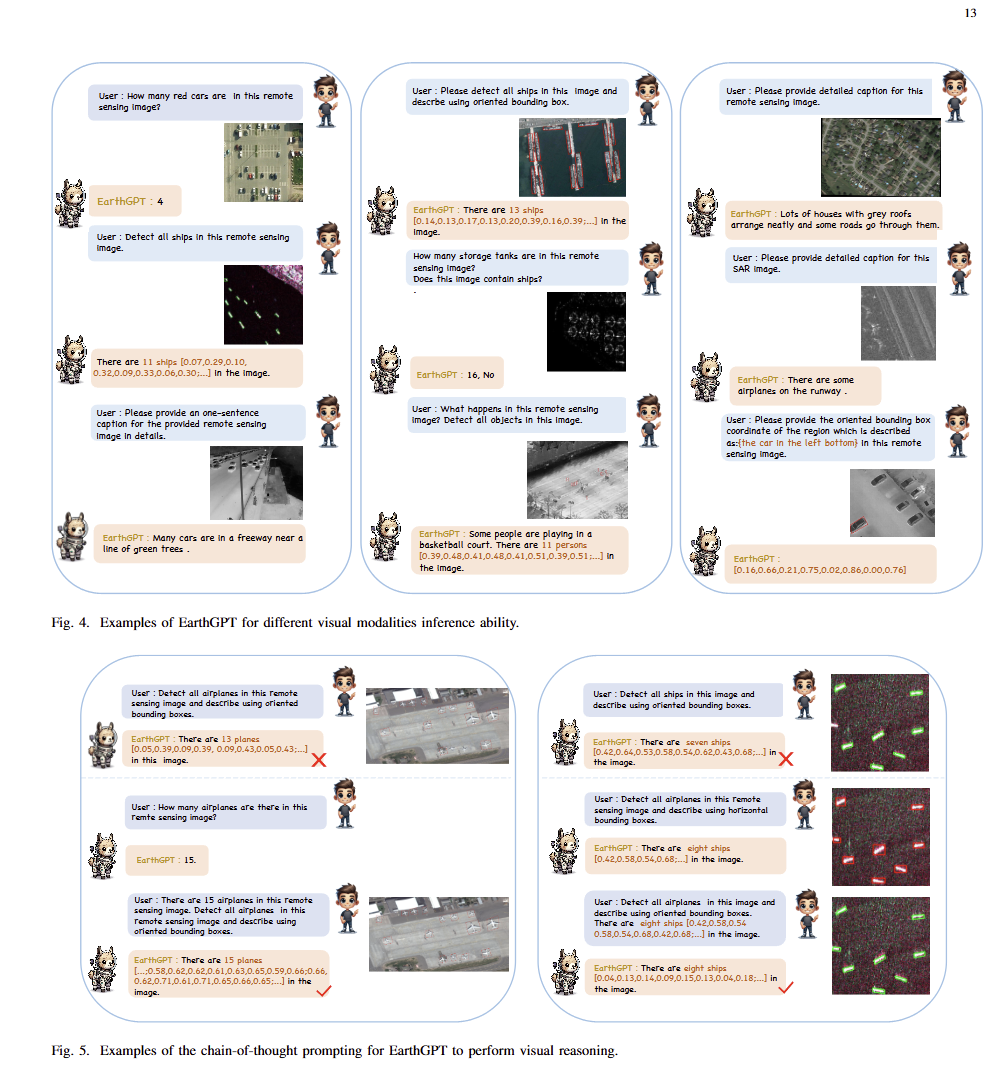
5.1 遥感图像分类(核心验证)
监督设置NWPU-RESISC45:EarthGPT超越ResNet、ConvNeXt等专项分类网络;零样本CLRS/NaSC-TG2数据集,对比LLaVA、Qwen-VL精度提升20%+,开集泛化性能显著领先。
5.2 Caption/VQA/目标检测
- 图像描述:NWPU-Captions数据集BLEU、CIDEr指标优于遥感专用图文生成模型;
- VQA:CRSVQA、RSVQA-HR监督+零样本双场景全面超越基线;
- 水平/旋转框检测:DIOR、MAR20数据集开集检测指标优于GroundingDINO,旋转检测逼近OBB专项算法。
5.3 多传感器跨域泛化
统一输入光学、SAR舰船、红外人车影像,模型可同步完成目标计数、框选标注、自然语言描述,解决过往模型单模态使用限制。
5.4 消融实验
- 双骨干消融:单独ViT/CNN精度低于融合方案,验证粗细特征融合必要性;
- 微调方案消融:全参数微调>偏置微调>全冻结,Bias+Linear微调在精度与算力间最优;
- 数据集消融:补充SAR/红外数据后模型跨模态性能明显上涨,验证MMRS-1M异源数据价值。
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表任何平台或机构立场。
如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)