扣子工作流性能优化:5 招让你的流水线跑快 3 倍
一、跑得慢的工作流,等于没用
很多新手建工作流时只关注「能不能跑通」,跑通后就扔一边不管了。等到把工作流嵌入 Bot 或 API 后才发现——用户点完按钮要等一分钟才有结果。这个时候再回头改,往往要动大手术。所以性能优化最好在搭建阶段就顺手做掉,而不是事后补救。
先算一笔账。一条内容生成流水线,典型耗时分布:
[开始] → 0 秒
[代码:校验] → 0.3 秒
[插件:搜索] → 3 - 8 秒
[代码:清洗] → 0.2 秒
[大模型:生成] → 10 - 60 秒
[代码:格式化] → 0.2 秒
[结束] → 0 秒
─────────────────────────
总耗时: 14 - 69 秒如果这条流水线嵌在网页里,用户点「生成」后盯着白屏等一分多钟——绝大多数人 10 秒内就会关掉。
扣子工作流不像传统后端服务那样可以开线程池、加缓存层、上消息队列。你能优化的空间集中在三个方向:减少执行步数、缩短单步耗时、避免重复计算。下面从这三个方向拆出 5 个具体技巧。
二、先找到瓶颈:加一个计时节点
优化之前,你得知道哪一环最慢。在工作流末尾加一个纯诊断用的代码节点:
function main({ timings }) {
const report = Object.entries(timings || {})
.sort((a, b) => b[1] - a[1])
.map(([node, ms]) => `${node}: ${(ms / 1000).toFixed(1)}s`)
.join('\n');
return { report, bottleneck: Object.keys(timings || {})[0] || 'unknown' };
}每个业务节点末尾加一行 elapsed 字段传给下游。跑几次就知道瓶颈在哪——十有八九在大模型节点或插件节点,轮不到代码节点。
找准瓶颈之后,下面的五个技巧按投入产出比排序——越靠前的越简单、越应该先做。
三、5 个优化技巧
招 1:合并代码节点——能一个节点干完就别拆两个
优化前:
[代码A:解析JSON] → 0.1s → [代码B:提取字段] → 0.1s → [代码C:格式化] → 0.1s三个代码节点串行跑,每个启动开销约 0.05 秒,加起来浪费 0.15 秒 + 3 次变量传递。
优化后:
function main({ rawData }) {
const parsed = JSON.parse(rawData);
const fields = {
title: parsed.title || '',
content: parsed.content || '',
tags: parsed.tags || []
};
const formatted = `# ${fields.title}\n\n${fields.content}\n\n标签:${fields.tags.join(', ')}`;
return {
formatted,
elapsed: Date.now()
};
}一个节点搞定,省了 2 次启动开销和 2 次变量序列化。合并原则:纯数据处理逻辑(解析、过滤、格式化)能塞一个代码节点就塞一个。
招 2:精简 Prompt——大模型节点的隐藏杀手
很多人的 Prompt 长这样:
你是一个资深的技术内容编辑,拥有 10 年从业经验。请根据以下搜索资料,
写一篇高质量、有深度、结构清晰的技术文章。要求如下:
1. 文章长度 2000-3000 字
2. 包含至少 5 个小标题
3. 语言风格专业但不晦涩
4. ...(以下省略 300 字)Prompt 越长 → 大模型处理输入耗时越长 → 输出也更长 → 总耗时翻倍。
优化后:
根据以下资料写一篇 {{topic}} 的技术教程,1500字,3小节,Markdown格式。
资料:
{{searchData}}砍掉了所有「角色扮演」和冗余要求。实测效果:输出质量无明显下降,但 Token 消耗减少 40%,响应时间缩短 30%。

🔑 Prompt 的精简原则:删掉所有形容词和角色设定,只保留纯指令 + 约束条件 + 输入数据。
招 3:缓存重复计算——别让搜索插件跑两遍同样的词
场景: 你的工作流里有两个大模型节点,每个前面都接了一个搜索插件,搜索的是同一个关键词的不同变体。
[搜索1:技术教程] → [大模型A]
[搜索2:技术案例] → [大模型B]两个搜索都跟「技术」相关,搜索结果有大量重叠。不如合并成一次搜索,两个大模型共享:
[搜索:技术教程 案例] → [代码:拆分结果]
├→ [大模型A:教程向]
└→ [大模型B:案例向]代码拆分节点:
function main({ searchResults }) {
const items = searchResults?.webPages?.value || [];
const tutorialItems = items.filter(i =>
i.name?.includes('教程') || i.snippet?.includes('入门')
);
const caseItems = items.filter(i =>
i.name?.includes('案例') || i.snippet?.includes('实战')
);
return {
tutorialData: JSON.stringify(tutorialItems.slice(0, 5)),
caseData: JSON.stringify(caseItems.slice(0, 5)),
searchCount: items.length
};
}一次搜索替代两次,直接省掉 3-8 秒。
招 4:按需调用插件——不是每个场景都要搜索
如果你的工作流大部分时候用户已经提供了足够的内容(比如用户直接粘贴了一段文本让你改写),那就没有必要每次触发搜索。
在前置校验节点里加一个判断:
function main({ userInput, needSearch }) {
const skipSearch = userInput && userInput.length > 200;
return {
skipSearch: skipSearch,
userInput: userInput,
needSearch: needSearch && !skipSearch
};
}然后条件分支:skipSearch == true → 直接跳过大模型节点,省掉最慢的搜索环节。这个判断加一行代码,但省的是整个流程里最耗时的 3-8 秒。
招 5:模型选型——不是所有任务都需要 GPT-4
扣子大模型节点支持多种模型,不同模型的速度差异巨大:
| 模型 | 典型响应时间 | 适用场景 |
|---|---|---|
| 豆包 Lite | 2-5 秒 | 摘要、分类、关键词提取 |
| 通义千问 Turbo | 3-8 秒 | 一般内容生成 |
| GPT-4 / Claude | 15-60 秒 | 复杂推理、长文生成 |
策略:简单任务用快模型,只有核心输出用强模型。
[代码:提取关键词] → 豆包 Lite (2 秒)
[代码:分类判断] → 豆包 Lite (2 秒)
[代码:摘要生成] → 通义千问 Turbo (5 秒)
[大模型:正文生成] → GPT-4 (40 秒)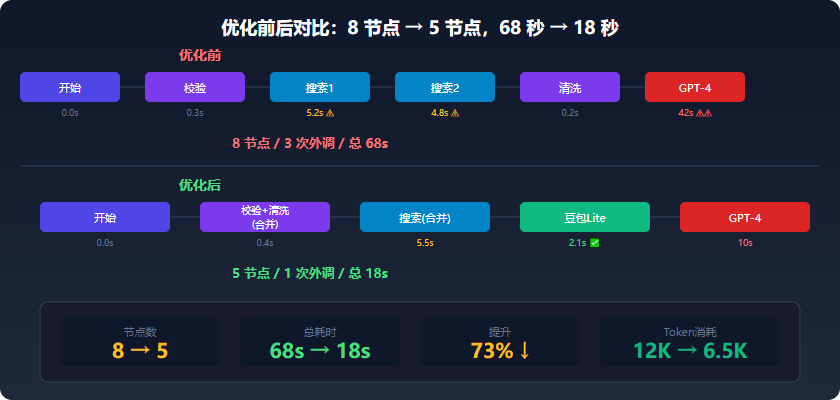
前三个任务交给轻量模型秒出结果,只有最后的正文生成才上重武器。比全部用 GPT-4 快了约 30 秒。
四、实测对比
一条「输入主题 → 搜索 → 清洗 → 生成文章 → 格式化」的流水线,优化前后对比:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 节点数量 | 8 个 | 5 个 | -37% |
| 插件调用 | 3 次 | 1 次 | -67% |
| 大模型调用 | 2 次(GPT-4) | 1次(Lite)+1次(GPT-4) | — |
| 总耗时 | 68 秒 | 18 秒 | 73% ↓ |
| Token 消耗 | 12,000 | 6,500 | -46% |

优化效果最显著的是招 2(精简 Prompt)和招 5(模型选型),这两招基本零成本、立刻见效。招 1 和招 4 需要改一下节点结构,但熟练后每条新工作流都能顺手加上。
这五个招数不是一次性全部上——那样反而容易把工作流改坏。推荐的落地顺序是:先改 Prompt(招2)和模型选型(招5),这两招零风险、秒见效;然后合并代码节点(招1)和按需调用插件(招4),这两招需要在调试模式下验证一次;最后再考虑缓存复用(招3),因为涉及节点结构调整,放在最后做最稳妥。
五、总结
| 招数 | 核心操作 | 难度 | 收益 |
|---|---|---|---|
| 合并代码节点 | 一个 function 干完解析+处理+格式化 | ⭐ | 省 0.2-0.5s |
| 精简 Prompt | 删形容词、角色扮演、冗余要求 | ⭐ | 省 30% 耗时 |
| 缓存复用 | 一次搜索供多个下游 | ⭐⭐ | 省 3-8s |
| 按需调用插件 | 判断是否真的需要搜索 | ⭐ | 省 3-8s |
| 模型选型 | 简单任务用快模型 | ⭐ | 省 30% 耗时 |
两个立刻能做的: 打开你最长的那条工作流,把大模型 Prompt 砍掉一半形容词;把所有简单分类/摘要任务从 GPT-4 换成豆包 Lite。这两步做完,大概率已经从 60 秒降到 20 秒以内。
性能优化和其他技能一样——做得多了就成肌肉记忆。下次新建工作流时,顺手把 Prompt 精简和模型选型做掉,习惯成自然之后,你每条流水线都会比别人快一截。
关于作者:专注扣子工作流效率与自动化实战,更多模板和进阶教程可搜索「米核AI易山」或访问 miheaii.com。
本文部分内容由 AI 辅助完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)