StatsPAI:交叠 DID 方法太多,到底怎么选?
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 林芷涵 (首都经济贸易大学)
邮箱: zhihan_lin0211@163.com
- 分类:倍分法 DID
- Title: StatsPAI:交叠 DID 方法太多,到底怎么选?
- Keywords: 双重差分法,交叠 DID,渐进 DID, Staggered DID, 交错 DID, 异质性处理效应,因果推断,Bacon 分解, Callaway-Sant'Anna 方法,Sun-Abraham 方法,Borusyak-Jaravel-Spiess 方法,平行趋势假设,稳健估计量,csdid, drdid, StatsPAI 包
导读
交叠 DID 已经成为政策评估中的常见场景:不同地区、企业或个人并不是在同一年受到政策影响,而是分批进入处理状态。问题在于,传统双向固定效应模型在处理效应存在异质性时,可能把早处理组、晚处理组和已处理组放在一起做不合适的比较,进而产生难以解释的加权结果。
本文不试图完整综述所有交叠 DID 文献,而是围绕一个更实际的问题展开:实证研究中到底应该如何选择估计方法?文章先说明 Bacon 分解、Callaway-Sant'Anna、Sun-Abraham、Borusyak-Jaravel-Spiess 和 de Chaisemartin-D'Haultfœuille 方法分别适合什么场景,再以 Python 工具包 StatsPAI 为例,展示一套从数据诊断、主估计、动态效应到结果报告的最小可复现流程。
1. 交叠 DID 不能只报告 TWFE 的结果
DID 的基本想法并不复杂:如果某项政策只影响一部分样本,那么可以比较处理组和对照组在政策前后的变化差异。麻烦出现在更常见的多期场景中:政策不是一次性覆盖所有处理组,而是分批实施。
例如:
- 某项环保政策在 2013 年先覆盖第一批城市,2015 年覆盖第二批城市,2017 年覆盖第三批城市;
- 某项产业政策分年度扩围,不同企业进入政策名单的年份不同;
- 某项金融改革先在试点地区推行,随后逐步扩展到其他地区。
这类数据结构通常被称为 交叠 DID (staggered DID),也常被称为交错 DID、渐进 DID 或多时点 DID。设 EiEi 表示个体 ii 首次接受处理的时间,处理变量可以写为:
Dit=1{t≥Ei}Dit=1{t≥Ei}
其中,Dit=1Dit=1 表示个体 ii 在 tt 期已经处于处理状态。若不同个体的 EiEi 不同,就形成交叠处理时点。
传统 TWFE 模型通常写为:
Yit=αi+λt+βDit+εitYit=αi+λt+βDit+εit
其中,αiαi 是个体固定效应,λtλt 是时间固定效应,ββ 被解释为平均处理效应。这个模型的问题在于,它隐含了较强的处理效应同质性假设。如果不同批次处理组的政策效应不同,或者政策效应随处理后时间逐渐变化,那么一个单一的 ββ 往往无法清楚回答研究问题。
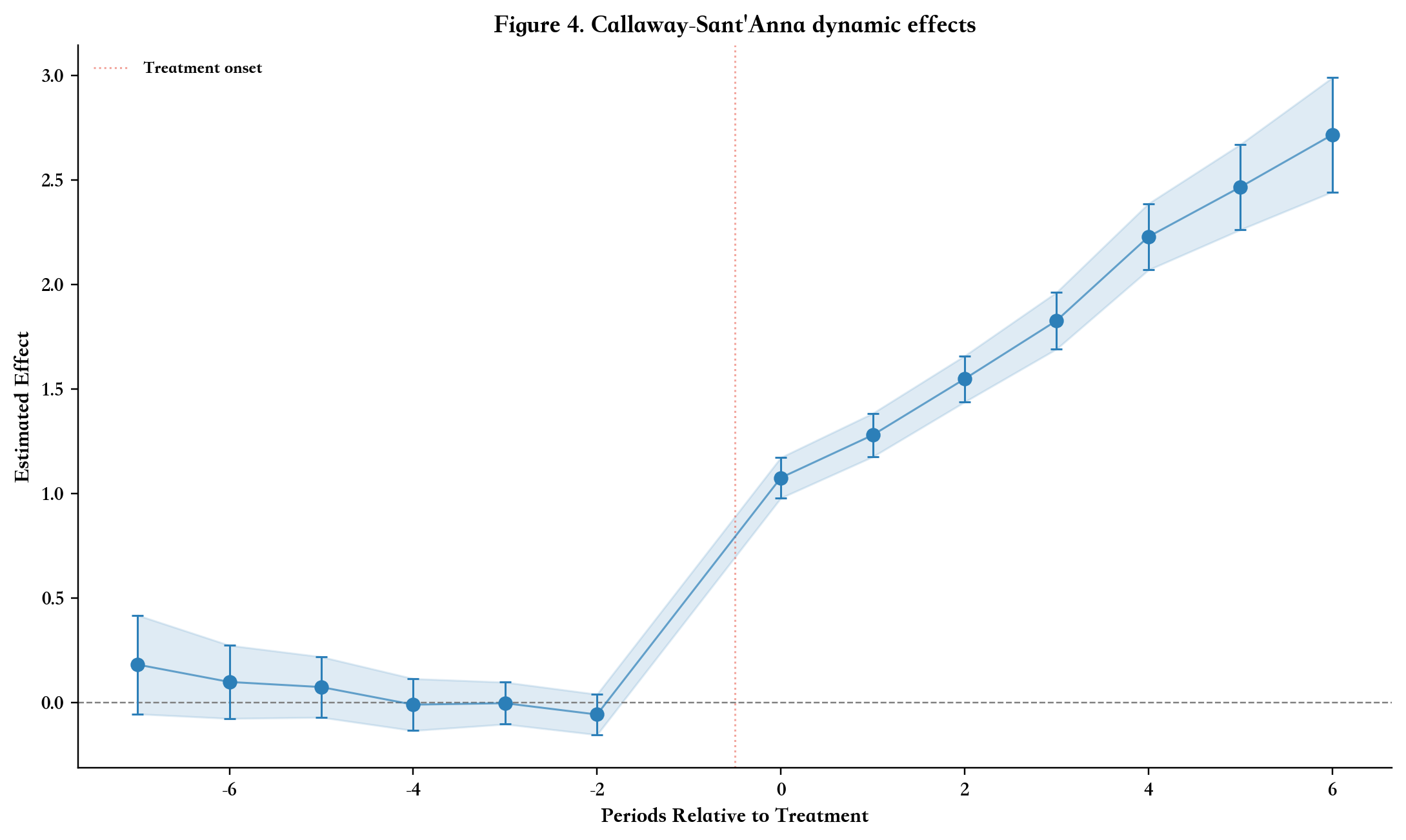
图 1:交叠 DID 数据结构与 TWFE 比较逻辑
Goodman-Bacon (2021) 的分解结果说明,交叠处理时点下的 TWFE 估计量可以理解为许多 2×2 DID 比较的加权平均:
β^TWFE=∑kwkβ^k2×2β^TWFE=k∑wkβ^k2×2
其中,β^k2×2β^k2×2 表示某一个局部 2×2 DID 比较,wkwk 表示对应权重。问题不在于「分解」本身,而在于某些比较并不符合直觉。例如,较晚接受处理的组在早期可以作为对照组;但较早接受处理的组在后期已经受到政策影响,若再被用作较晚处理组的对照,就会形成所谓的 forbidden comparison。
因此,在交叠 DID 中,TWFE 可以作为一个参照结果,但不宜机械地作为唯一主估计。实证论文通常还需要说明:对照组来自哪里,估计对象是什么,处理效应是否允许随组别和时间变化。
2. 先看数据结构,再选估计方法
方法选择不应从「哪个估计量更流行」开始,而应从数据结构和研究目标开始。交叠 DID 至少要先回答五个问题:
- 处理是否为吸收状态,即一旦处理后是否持续处理?
- 样本中是否存在从未处理组 (never-treated group)?
- 是否可以使用尚未处理组 (not-yet-treated group) 作为对照?
- 研究重点是总体平均效应,还是动态事件研究效应?
- 是否需要控制协变量,且希望使用双重稳健估计?
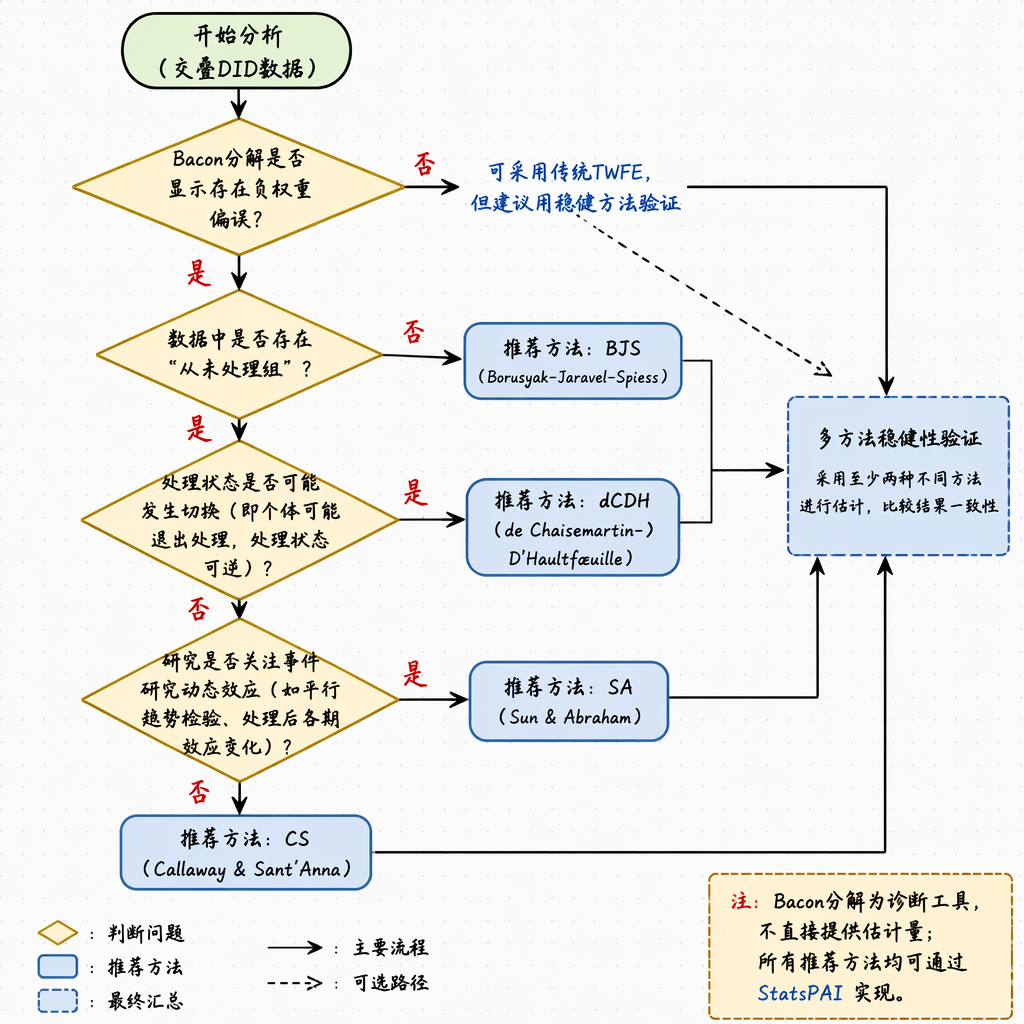
图 2:交叠 DID 方法选择决策树
更实用的选择逻辑可以概括为下表。
| 研究者面对的问题 | 更合适的起点 | 解释 |
|---|---|---|
| 只是想知道 TWFE 是否可能有问题 | Bacon 分解 | 诊断 TWFE 中不同 2×2 比较的来源和权重结构 |
| 希望估计总体平均处理效应 | CS 或 BJS | 二者都允许处理效应异质性,适合作为主估计或稳健性估计 |
| 希望画事件研究图 | SA、CS 动态聚合或 BJS 动态估计 | 不要直接使用传统 TWFE leads and lags |
| 样本中有从未处理组 | CS、SA、BJS 均可考虑 | never-treated 通常是更直观的对照组 |
| 样本中没有从未处理组 | CS 使用 not-yet-treated,或考虑 BJS | 需要检查后期是否仍有足够未处理观测 |
| 处理状态可能反复切换 | dCDH / did_multiplegt | 传统 CS、SA、BJS 通常默认处理状态吸收 |
| 担心平行趋势只是近似成立 | Rambachan-Roth / HonestDID | 用敏感性分析替代「一检验通过就放心」的做法 |
这个表的含义不是让研究者每篇论文都跑所有方法,而是强调估计量要服务于研究设计。若政策确实是分批进入、处理后持续生效、且研究目标是平均处理效应,那么 CS 或 BJS 可以作为自然起点;若论文重点是政策效果的动态变化,则需要重点报告事件时间上的处理效应曲线;若政策有退出、撤销或反复进入,则应考虑允许处理状态切换的方法。
3. 几类方法分别解决什么问题?
3.1 Bacon 分解:先诊断 TWFE 比较结构
Bacon 分解不是一个新的主估计量,而是一个诊断工具。它告诉我们,TWFE 的结果由哪些局部 DID 比较构成,以及每类比较占多大权重。
在交叠 DID 中,比较大致包括三类:
- 早处理组 vs 从未处理组;
- 晚处理组 vs 从未处理组;
- 早处理组 vs 晚处理组,或晚处理组 vs 已处理组。
第三类比较最容易出问题。因为已经处理过的组不再是干净的反事实。如果政策效应具有动态变化,或者早晚处理组效应大小不同,这类比较会污染 TWFE 系数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)