Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
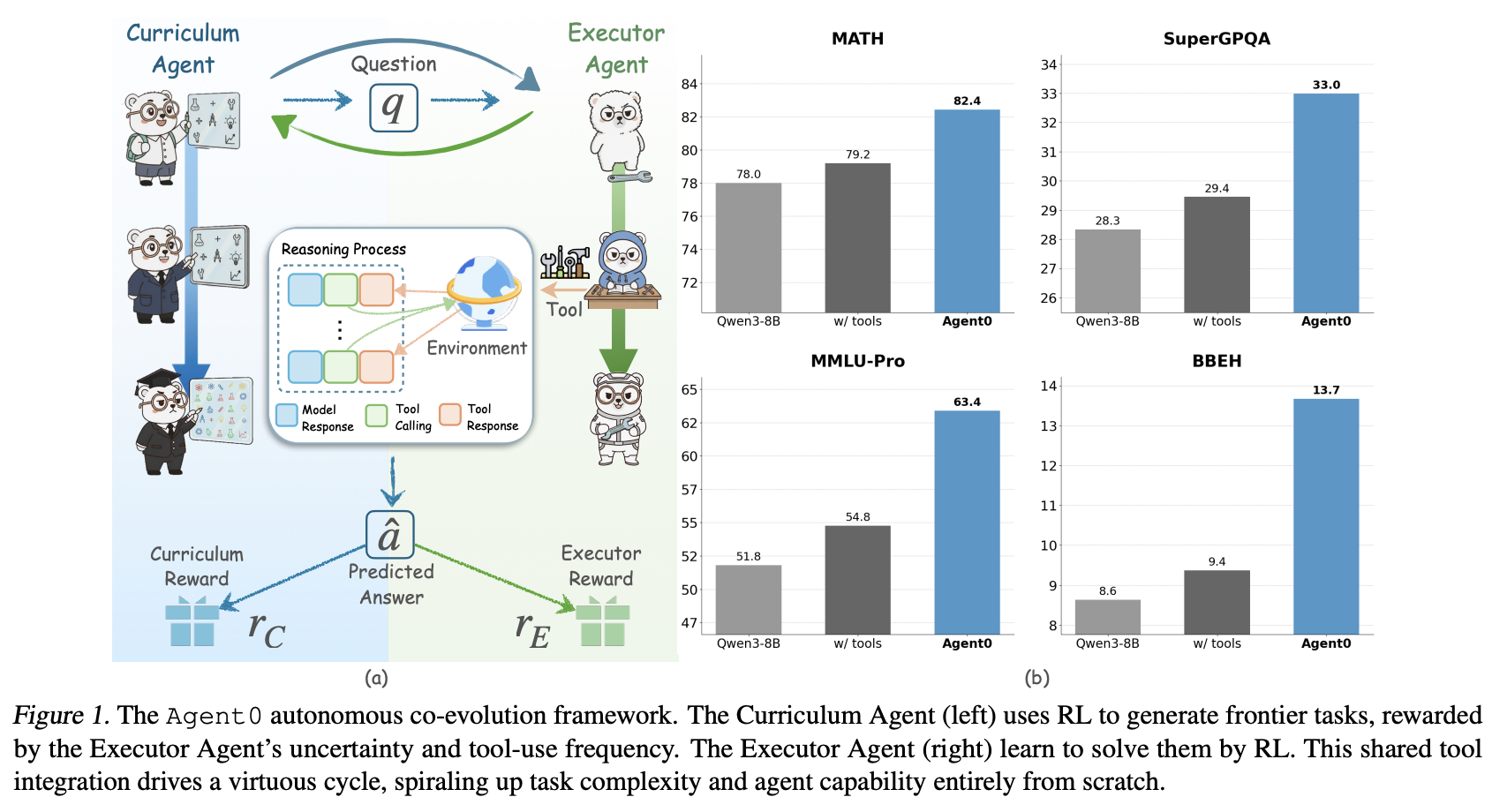
大语言模型(LLM)智能体通常使用强化学习(RL)进行训练,但由于依赖人工整理的数据,其可扩展性受到限制,并将人工智能束缚于人类知识。现有的自进化框架提供了一种替代方案,但通常受限于模型的固有能力和单轮交互,阻碍了涉及工具使用或动态推理的复杂课程的开发。我们提出了 Agent0,这是一个完全自主的框架,它通过多步协同进化和无缝工具集成,在无需外部数据的情况下进化出高性能智能体。Agent0 在两个基于同一基础 LLM 初始化的智能体之间建立了一种共生竞争:一个课程智能体提出难度不断增加的前沿任务,一个执行智能体学习解决这些任务。我们集成了外部工具来增强执行智能体的解题能力;这种提升反过来又促使课程智能体构建更复杂、更依赖工具的任务。通过这种迭代过程,Agent0 建立了一个自我强化的循环,持续生成高质量的课程。实证研究表明,Agent0 显著提升了推理能力,在数学推理方面比 Qwen3-8B-Base 模型提高了18%,在一般推理基准测试中提高了 24%。代码可在 https://github.com/aiming-lab/Agent0 获取。
1.介绍
大语言模型(LLM)智能体在处理需要与环境进行广泛交互的复杂、长周期问题方面展现出了卓越的能力,例如深度研究和智能体编码。为了优化这些复杂的多步骤交互并突破硬编码工作流程的限制,强化学习(RL)已成为一种主要的训练范式,并在复杂的推理任务上取得了显著进展。然而,无论是基于人类反馈的强化学习(RLHF)还是基于可验证奖励的强化学习(RLVR),这些方法的有效性都严重依赖于海量、高质量的人工整理数据集。这种依赖性不仅造成了严重的扩展性瓶颈(耗时、耗力且成本高昂),而且从根本上限制了人工智能的潜力,使其受限于人类的知识水平和标注速度。
为了摆脱对人类数据的依赖,自进化框架应运而生,成为一种极具前景的替代方案。它通过使模型能够自主生成训练数据,提供了一条可扩展的路径。然而,尽管自进化框架潜力巨大,但现有的自博弈或自挑战方法仍面临诸多限制。首先,其能力受限于模型固有的知识和推理能力,导致生成的任务很少能超越模型当前的复杂度,从而造成学习停滞。其次,这些框架通常仅进行单轮交互,无法捕捉现实世界问题的动态性和情境依赖性。这种双重限制不仅限制了自生成课程的复杂性,更重要的是,它阻碍了模型掌握需要复杂工具使用或多步骤推理的关键技能。
为了应对这些挑战,如图 1 所示,我们引入了 Agent0,这是一个完全自主的框架,旨在从零开始引导智能体的演化。Agent0 完全消除了对任何外部数据或人工标注的依赖,开创性地将工具集成与多轮协同演化相结合。该框架的实现始于一个基础的 LLM,我们从中初始化两个功能不同的智能体:执行智能体和课程智能体。这两个智能体通过共生竞争进行协同演化:课程智能体使用强化学习 (RL) 进行训练,以提出能够精准挑战执行智能体当前能力的前沿任务,并将执行智能体的不确定性(即在多个答案中的自洽性)及其工具使用频率作为奖励信号。与此同时,执行智能体也通过强化学习进行训练,以成功解决这些任务,它在由冻结的课程智能体生成的一组经过筛选的挑战性问题上进行优化,并使用从其自身多数投票中获得的伪标签。为执行者配备工具可以增强其问题解决能力,进而促使配备工具的课程 Agent 生成更复杂、基于工具的课程。这形成了一个良性循环,推动 Agent 能力和课程复杂性同步螺旋式提升。此外,我们将此范式扩展到支持多轮交互,从而能够生成更贴近真实世界问题解决过程、更具情境性的对话式任务。
本文的主要贡献在于 Agent0,这是一个全新的框架,它能够通过工具增强推理,从零开始自主演化 LLM 智能体,而无需依赖任何外部数据。在涵盖数学和通用推理的十个基准测试中,实证结果表明,Agent0 实现了显著的、与模型无关的能力提升,数学推理性能提升了18%,通用推理性能提升了24%。此外,我们的分析证实,这种提升源于我们提出的协同演化循环:课程智能体学习生成日益复杂的任务,从而形成执行 Agent 能力提升的良性循环。
2.Preliminaries
LLM as a Policy Agent。我们将 LLM 建模为一个智能体,该智能体由策略 πθπ_θπθ 表示,参数为 θθθ。给定提示 xxx,智能体自回归地生成响应 y∼πθ(⋅∣x)y ∼ π_θ(·|x)y∼πθ(⋅∣x)。强化学习的一般目标是优化 θθθ 以最大化预期奖赏 J(θ)=Ex∼D,y∼πθ(⋅∣x)[R(y∣x)]J(θ) = \mathbb E_{x∼D,y∼π_θ(·|x)}[R(y|x)]J(θ)=Ex∼D,y∼πθ(⋅∣x)[R(y∣x)]。
Group Relative Policy Optimization (GRPO)。GRPO 是一种强化学习方法,它通过使用组内相对奖励来避免训练 critic。对于每个提示 xxx,模型采样 GGG 个响应 {y1,...,yG}\{y_1, ..., y_G\}{y1,...,yG},并对这些响应进行评分以获得奖赏 {r1,...,rG}\{r_1, ..., r_G\}{r1,...,rG}。GRPO 使用 z-score 计算归一化优势 A^i=ri−mean({rj}j=1G)std({rj}j=1G)+ϵnorm\hat A_i = \frac{r_i − mean(\{r_j\}^G_{j=1})}{std(\{r_j\}^G_{j=1}) + ϵ_{norm}}A^i=std({rj}j=1G)+ϵnormri−mean({rj}j=1G),其中 ϵnormϵ_{norm}ϵnorm 是一个用于数值稳定性的较小常数。然后,通过最小化以下 PPO 风格的截断损失函数来更新策略:
LGRPO(θ)=−1G∑i=1Gmin(πθ(xi)πθold(xi)A^i,clip(πθ(xi)πθold(xi),1−ϵ,1+ϵ)A^i)+βKL(πθ∣∣πθold),(1)\mathcal L_{GRPO}(\theta)=-\frac{1}{G}\sum^G_{i=1}min\left (\frac{\pi_{\theta}(x_i)}{\pi_{\theta_{old}}(x_i)}\hat A_i,clip(\frac{\pi_{\theta}(x_i)}{\pi_{\theta_{old}}(x_i)},1-ϵ,1+ϵ)\hat A_i\right )+\beta KL(\pi_{\theta}||\pi_{\theta_{old}}),\tag{1}LGRPO(θ)=−G1i=1∑Gmin(πθold(xi)πθ(xi)A^i,clip(πθold(xi)πθ(xi),1−ϵ,1+ϵ)A^i)+βKL(πθ∣∣πθold),(1)
其中 πθ(xi)πθold(xi)\frac{π_θ(x_i)}{π_{θ_{old}}(x_i)}πθold(xi)πθ(xi) 表示当前策略 πθπ_θπθ 与上一次迭代的参考策略 πθoldπ_{θ_{old}}πθold 之间的重要性采样比率。A^i\hat A_iA^i 是归一化优势,ϵϵϵ 和 βββ 是超参数。KL 散度项用作正则化惩罚项,以稳定训练过程。
3.The Agent0 Framework
3.1 Framework Overview
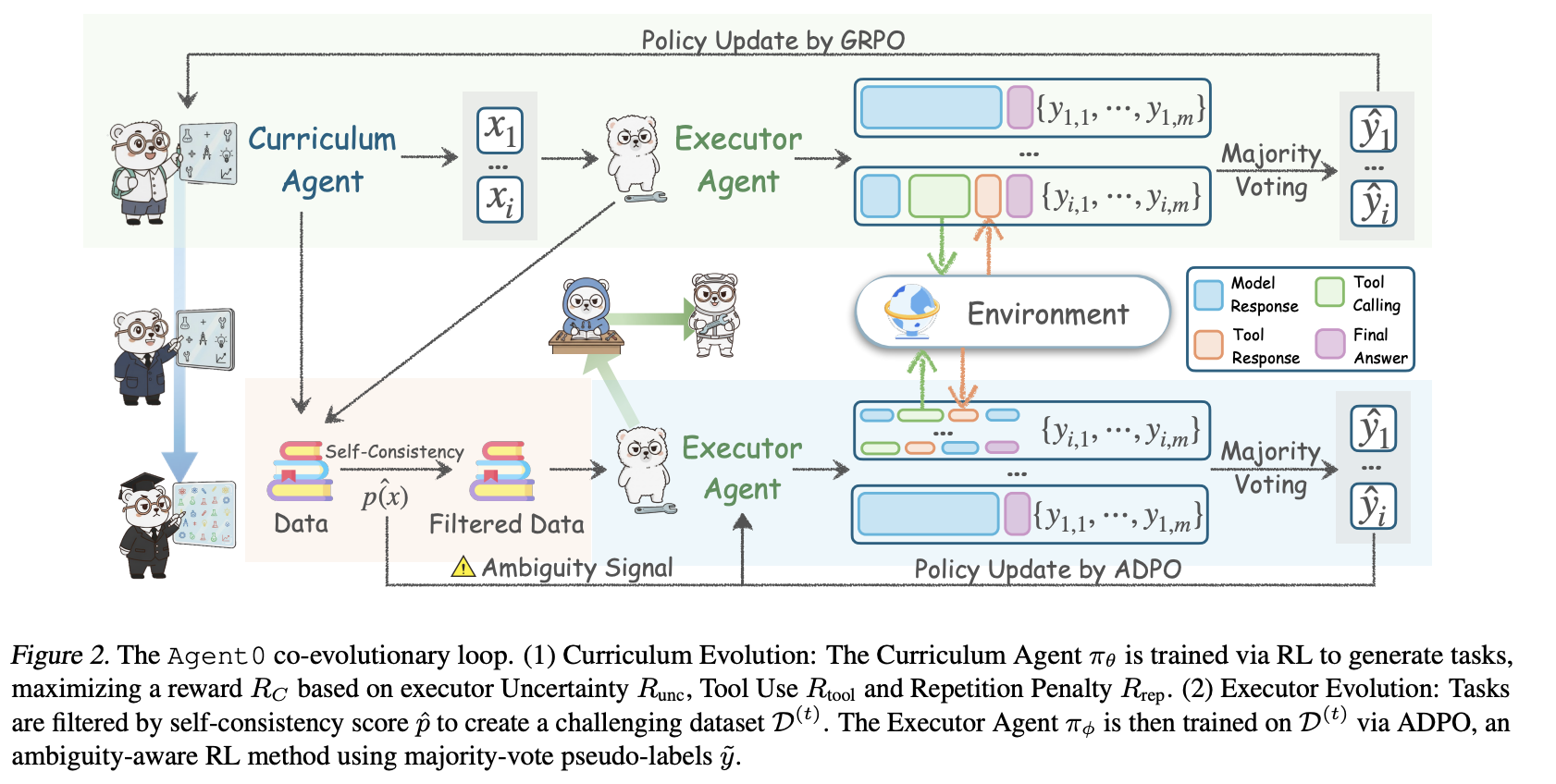
Agent0 是一个完全自主的迭代式协同进化框架,旨在增强 LLM 智能体的能力,而无需依赖任何人工标注数据。该框架的核心是两个功能不同的智能体,它们均基于同一个基础 LLM 模型 πbaseπ_{base}πbase 初始化:(1)Curriculum Agent (πθπ_θπθ) 旨在生成对当前执行智能体而言具有适当挑战性的前沿任务;(2) Executor Agent (πϕπ_ϕπϕ) 旨在解决课程智能体提出的日益复杂的任务。
如图 2 所示,这两个 Agent 通过共生竞争的过程进行迭代共同演化。该过程的每次迭代 ttt 分为两个阶段:
Curriculum Evolution。我们使用强化学习训练 Curriculum Agent πθπ_θπθ,使其专门生成挑战当前 Executor Agent πϕ(t−1)π^{(t−1)}_ϕπϕ(t−1) 的任务。
Executor Evolution。我们使用冻结的 Curriculum Agent πθ(t)π^{(t)}_θπθ(t) 生成任务池,从中筛选出具有挑战性的数据集 D(t)\mathcal D^{(t)}D(t)。然后,我们使用强化学习在该数据集上训练 Executor Agent πϕπ_ϕπϕ,使其演化为 πϕ(t)π^{(t)}_ϕπϕ(t)。
代码解释器工具的集成形成了一个良性循环: Executor Agent 的问题解决能力因该工具而得到增强,反过来又促使配备该工具的 Curriculum Agent 生成更复杂、基于工具的课程。此外,该框架支持多轮交互,使 Curriculum Agent 能够生成上下文丰富的对话式任务,从而更好地反映现实世界的问题解决过程。

3.2 Curriculum Agent Training
Curriculum Agent πθπ_θπθ 的目标是生成一个提示 xxx,使复合奖赏信号 RCR_CRC 最大化。该奖赏信号旨在量化当前 Executor Agent πϕπ_ϕπϕ 执行任务 xxx 的难度。我们使用第 2 节中描述的 GRPO 算法来优化 πθπ_θπθ。
对于由 πθπ_θπθ 生成的每个任务 xix_ixi,我们通过从当前执行器 πϕπ_ϕπϕ 中采样 kkk 个响应 {yj}j=1k\{y_j\}^k_{j=1}{yj}j=1k 来计算其奖赏。复合奖励 RCR_CRC 由两个关键部分组成:
Uncertainty Reward。该奖赏机制激励 Curriculum Agent 生成执行器认为令人困惑或不确定的任务。我们使用执行器的自洽性 p^(x;πϕ)\hat p(x; π_ϕ)p^(x;πϕ) 作为不确定性的代理指标。p^\hat pp^ 定义为 kkk 个响应中投票支持最多答案 y~\tilde yy~ 的比例。奖励函数旨在当 p^=0.5\hat p = 0.5p^=0.5 时达到最大值,此时执行器的不确定性最高:
Runc(x;πϕ)=1−2∣p^(x;πϕ)−0.5∣(2)R_{unc}(x;\pi_ϕ)=1-2|\hat p(x;\pi_ϕ)-0.5|\tag{2}Runc(x;πϕ)=1−2∣p^(x;πϕ)−0.5∣(2)
该函数会对太容易(p^→1\hat p → 1p^→1)或太难(p^→0\hat p → 0p^→0)的任务进行惩罚。
Tool Use Reward。为了驱动良性循环,我们必须明确奖励那些促使执行器使用其工具的任务。我们根据工具调用次数定义 RtoolR_{tool}Rtool,这些调用次数由工具响应标记(即 ‘‘‘output‘‘‘output‘‘‘output)标识,该标记位于完整的预测 y=πϕ(x)y = π_ϕ(x)y=πϕ(x) 中。令 Ntool(y)N_{tool}(y)Ntool(y) 为 yyy 中这些标记的总数。然后,奖赏被计算为一个加权上限值:
Rtool(x;πϕ)=γ⋅min(Ntool(y),C)(3)R_{tool}(x;\pi_{ϕ})=\gamma\cdot min(N_{tool}(y),C)\tag{3}Rtool(x;πϕ)=γ⋅min(Ntool(y),C)(3)
其中 γγγ 是奖赏分数的缩放超参数,CCC 是奖赏调用次数的上限,以防止奖赏过度或虚假的工具使用。
Repetition Penalty。为了鼓励训练批次 XXX 内的多样性,我们引入重复惩罚 RrepR_{rep}Rrep。首先,我们使用相似性度量(例如 BLEU 分数)计算生成任务之间的成对距离:dij=1−BLEU(xi,xj)d_{ij} = 1 − BLEU(x_i, x_j)dij=1−BLEU(xi,xj)。然后,将任务分组到簇 C={C1,...,CK}\mathcal C = \{C_1, ..., C_K\}C={C1,...,CK} 中,其中 dij<τBLEUd_{ij} < τ_{BLEU}dij<τBLEU。任务 xix_ixi 属于簇 CkC_kCk 的惩罚与其在簇中的相对大小成正比:
Rrep(xi)=λrep∣Ck∣B,(4)R_{rep}(x_i)=\lambda_{rep}\frac{|C_k|}{B},\tag{4}Rrep(xi)=λrepB∣Ck∣,(4)
其中 BBB 为批次大小,λrepλ_{rep}λrep 为缩放因子。
Composite Reward。最终奖赏结合了这些信号,减去重复惩罚,并通过格式检查 RformatR_{format}Rformat 进行控制。
RC(xi)=Rformat(xi)⋅max(0,(λuncRunc+λtoolRtool)−Rrep(xi))(5)R_C(x_i)=R_{format}(x_i)\cdot max(0, (\lambda_{unc}R_{unc}+\lambda_{tool}R_{tool})-R_{rep}(x_i))\tag{5}RC(xi)=Rformat(xi)⋅max(0,(λuncRunc+λtoolRtool)−Rrep(xi))(5)
其中 λuncλ_{unc}λunc、λtoolλ_{tool}λtool 和 λrepλ_{rep}λrep 是超参数。我们将此 RCR_CRC 用作 GRPO 损失中的奖励 rir_iri。
3.3 Executor Agent Training
Executor Agent πϕπ_ϕπϕ 的目标是最大化其解决 Curriculum Agent πθπ_θπθ 生成的任务的成功率。此阶段的训练也基于 GRPO。
3.3.1 DATASET CURATION AND TRAJECTORY GENERATION
Challenging Dataset Construction。 Curriculum Agent πθ(t)π^{(t)}_θπθ(t) 训练完成后,我们将其冻结。我们用它来生成一个包含大量候选任务的池 XpoolX_{pool}Xpool。对于池中的每个任务 xxx,我们使用当前执行器 πϕ(t−1)π^{(t−1)}_ϕπϕ(t−1) 抽取 kkk 个响应样本,并计算其自洽性 p^(x)\hat p(x)p^(x)。自洽性计算为投票支持多数答案 y~\tilde yy~ 的响应比例:
p^(x)=1k∑i=1kI(oi=y~),y~=argmaxy∑i=1kI(oi=y),(6)\hat p(x)=\frac{1}{k}\sum^k_{i=1}\mathbb I(o_i=\tilde y),\quad \tilde y=\mathop{argmax}\limits_{y}\sum^k_{i=1}\mathbb I(o_i=y),\tag{6}p^(x)=k1i=1∑kI(oi=y~),y~=yargmaxi=1∑kI(oi=y),(6)
其中 I\mathbb II 为指示函数。为了构建高效的训练课程,我们筛选出位于能力前沿的任务。因此,我们只保留那些自洽性得分落在信息区间内的任务:
Dt={x∈Xpool∣∣p^(x;πϕ(t−1))−0.5∣≤δ},(7)\mathcal D^{t}=\left \{x\in X_{pool}| \big |\hat p(x;\pi^{(t-1)}_{ϕ})-0.5 \big |\le δ\right \},\tag{7}Dt={x∈Xpool∣ p^(x;πϕ(t−1))−0.5 ≤δ},(7)
其中 δδδ 是控制课程难度的阈值。这一筛选步骤确保 πϕπ_ϕπϕ 只接受难度适中的任务训练。
Multi-Turn Rollout。我们将标准的单轮生成过程替换为多步骤、工具集成的滚动过程。在此过程中,kkk 条轨迹中的每一条都是通过策略 πϕ(t−1)π^{(t−1)}_ϕπϕ(t−1) 首先生成文本推理 t1t_1t1 而生成的。当策略发出工具调用触发器(即“python…”标签)时,生成过程暂停。然后,代码 c1c_1c1 在沙箱中执行,并返回执行结果或错误 f1f_1f1。此反馈 f1f_1f1 前面加上类似“output…”的简单前缀,并反馈给策略。策略随后根据历史记录和新的反馈 [t1 ⊕ c1 ⊕ f1 ⊕ …] 继续生成。此迭代过程重复进行,直到策略生成最终答案 ooo(即在 {boxed...} 标签中),从而生成完整的混合推理轨迹。这种动态的、交错的反馈机制使智能体能够迭代地改进其推理并纠正错误,从而模拟自我纠正的“aha moment”。
Pseudo-Label Advantage。在生成 kkk 条完整轨迹并确定其 kkk 个最终答案 {oi}i=1k\{o_i\}^k_{i=1}{oi}i=1k 后,我们使用先前确定的多数答案 y~\tilde yy~ 作为伪标签。然后,我们根据每条轨迹的答案 oio_ioi 是否与该伪标签匹配,为其分配一个最终奖赏 Ri=I(oi=y~)R_i = \mathbb I(o_i = \tilde y)Ri=I(oi=y~)。该结果奖励 RiR_iRi 用于计算整个多步轨迹 iii 的优势 AiA_iAi。
3.3.2 AMBIGUITY-DYNAMIC POLICY OPTIMIZATION
标准 GRPO 对所有训练样本一视同仁。然而,在我们的自进化模型中,我们依赖多数投票来生成伪标签,这引入了两个关键问题:标签噪声和对模糊任务的探索受限。为了解决这些问题,我们提出了 Ambiguity-Dynamic Policy Optimization (ADPO),它包含两个关键改进,这两个改进的灵感来源于数据的模糊信号 p^(x)\hat p(x)p^(x)。
Ambiguity-Aware Advantage Scaling。第一个问题是,对于高歧义性任务(低 p^(x)\hat p(x)p^(x)),主答案容易出错。直接使用标准 GRPO 算法优化这些噪声标签可能会强化错误的推理。为了防止过拟合潜在的不准确伪标签,我们对归一化优势 A^i\hat A_iA^i 进行缩放。我们定义缩放因子 s(x)=f(p^(x))s(x) = f(\hat p(x))s(x)=f(p^(x)),其中 f 是自洽性的递增函数。优势被修改为 A~i(x)=A^i⋅s(x)\tilde A_i(x) = \hat A_i· s(x)A~i(x)=A^i⋅s(x)。这按比例降低了来自不可靠、低一致性样本的训练信号的权重。
Ambiguity-Modulated Trust Regions。第二个问题与标准近端策略优化算法施加的严格约束有关。虽然静态裁剪(例如 ϵϵϵ)旨在确保稳定性,但它却造成了学习的不对称障碍。如图 3 所示,实证分析表明,上限裁剪主要由低概率 token 触发。这表明标准机制不成比例地“钳制”了不太可能出现的 token 的增长,有效地抑制了新推理路径的出现。这种限制对于高歧义性任务(低 p^(x)\hat p(x)p^(x))尤其不利,因为正确的推理通常位于当前策略分布的尾部,需要进行大量更新才能显现出来。为了解决这一瓶颈,ADPO 动态地调节了信赖域。我们将上限裁剪 ϵhigh(x)ϵ_{high}(x)ϵhigh(x) 定义为 p^(x)\hat p(x)p^(x) 的递减函数。这有效地放宽了对模糊输入的限制,允许更大的梯度步长来提升潜在的低概率解,同时保持对置信样本的严格限制以保持稳定性。
通过最小化 ADPO 目标来更新 Executor Agent :
LADPO(θ)=Ex∼D(t)[−1G∑i=1Gmin(ri(θ)A~i(x),clip(ri(θ),1−ϵlow,1+ϵhigh(x))A~i(x))],(8)\mathcal{L}_{\mathrm{ADPO}}(\theta)= \mathbb{E}_{x \sim \mathcal{D}^{(t)}} \left[ -\frac{1}{G}\sum_{i=1}^{G} \min\left( r_i(\theta)\tilde{A}_i(x), \operatorname{clip}\left( r_i(\theta), 1-\epsilon_{\mathrm{low}}, 1+\epsilon_{\mathrm{high}}(x) \right)\tilde{A}_i(x) \right) \right], \tag{8}LADPO(θ)=Ex∼D(t)[−G1i=1∑Gmin(ri(θ)A~i(x),clip(ri(θ),1−ϵlow,1+ϵhigh(x))A~i(x))],(8)
其中,ri(θ)r_i(\theta)ri(θ) 是重要性采样比率,A~i(x)\tilde{A}_i(x)A~i(x) 是歧义缩放优势,ϵhigh(x)\epsilon_{\mathrm{high}}(x)ϵhigh(x) 是与 p^(x)\hat{p}(x)p^(x) 成反比关系的动态上界。
4.Experiments
4.1 Experimental Setup

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)