AI for Auto-Research: Roadmap & User Guide 翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
人工智能辅助研究正跨越一个重要的门槛:全自动系统现在只需 15 美元即可生成研究论文,而长周期智能体只需极少的人工干预即可执行实验、撰写论文初稿并模拟评论。然而,这种生产力的飞跃也暴露出一个更深层次的诚信问题:在科学压力下,即使是最先进的长周期智能体仍然会捏造结果、忽略隐藏的错误,并且无法可靠地判断创新性。本文研究了截至2026年4月的发展情况,并对人工智能在整个研究生命周期中的作用进行了端到端的分析,该生命周期分为四个认识论阶段:1.Creation(构思、文献综述、编码和实验、表格和图表);2. Writing(论文撰写);3. Validation(同行评审、反驳和修改);4. Dissemination(海报、幻灯片、视频、社交媒体、项目页面和交互式智能体)。我们发现,在可靠的辅助和不可靠的自主之间存在一条清晰且阶段相关的界限:人工智能在结构化、基于检索和工具辅助的任务中表现出色,但在真正新颖的想法、研究级实验和科学判断方面仍然脆弱。生成的想法在实施后往往会退化,研究代码远远落后于模式匹配基准,端到端的自主系统尚未始终达到主流应用场景的验收标准。我们进一步表明,更高的自动化程度可能会掩盖而非消除故障模式,因此,由人主导的协作才是最可靠的部署范式。最后,我们提供了一套结构化的分类体系、基准测试套件和工具清单、跨阶段设计原则以及面向实践者的指南,相关资源维护在我们的项目页面上。
1.Introduction


人工智能辅助研究正跨越一个重要的门槛。大语言模型(LLM)及其智能扩展不再局限于局部写作或编码支持;它们正开始贯穿整个研究生命周期。近期的一些系统展现了这一转变的规模:AI Scientist 生成完整的科研论文,每篇成本约为 15 美元;FARS 连续运行 228 小时,消耗了 114 亿个 token,生成了 100 篇论文,平均每 2.3 小时一篇;ARIS 报告称,其一夜之间运行了 20 多个 GPU 实验,剔除了不成立的论断,并通过迭代审查和修改将草稿评分从 5.0 提高到 7.5。这些系统预示着一种新的范式:人工智能正从辅助单个研究任务转向协调多阶段工作流程,这些工作流程包括生成想法、检索文献、执行实验、撰写论文草稿、模拟评论以及准备传播材料。
这一快速进展也暴露了该领域的核心矛盾。人工智能系统越来越能够生成类似研究成果的产物,但在验证这些产物是否具有新颖性、真实性、可执行性和科学意义方面,其可靠性仍然很低。(1)生成的想法可能看起来很有前景,但在实施后却会减弱;(2)生成的代码可能在执行错误算法的情况下运行;(3)流畅的文稿可能掩盖未经证实的论断;(4)自动评审可能条理清晰,但却过于宽容或容易被操纵;(5)反驳可能承诺修改但最终并未兑现;(6)传播材料可能过度简化研究结果。因此,核心挑战不再是人工智能能否生成研究的形式,而是它能否保留研究的实质:证据、判断、来源和问责制。
生命周期视角对于理解这一挑战至关重要。研究并非一系列独立任务的集合:想法转化为实验,实验转化为论断,论断转化为论文,审稿转化为修改,论文最终形成面向公众的摘要。早期引入的错误可能会在后续阶段被放大,尤其是在人工智能系统生成看似合理的输出却不保留证据或来源的情况下。尽管研究 Agent、写作助手、科学编码工具、自动审稿人、反驳系统和 Paper2X 应用等涌现迅速,但该领域仍然缺乏对人工智能自动研究在整个学术生命周期中的统一分析。缺乏这样的视角,就难以确定人工智能在哪些方面能够可靠地提供帮助,在哪些方面存在系统性缺陷,以及哪些部署模式具有科学可信度。
本文对截至2026年4月的发展趋势进行了调研,首次对人工智能自主研究在完整的学术研究生命周期中进行了端到端的分析。我们将该领域划分为四个认识论阶段和八个步骤:1. Creation,涵盖构思、文献综述、编码与实验以及表格和图表;2. Writing,涵盖论文撰写;3. Validation,涵盖同行评审、反驳与修改;4. Dissemination,涵盖海报、幻灯片、视频、社交媒体、项目页面和交互式论文 Agent。这种结构遵循研究的时间顺序,同时明确阐述了每个阶段引入的独特人工智能能力、风险和验证要求。
我们的分析得出五项核心发现。首先,当任务结构化、有理有据且可外部验证时,人工智能的能力最强;但对于需要创新性、隐含领域知识、长远推理或科学判断的开放式研究任务,其能力会急剧下降。其次,人工智能的成果生成速度始终快于验证速度:在各个阶段,人工智能生成看似合理的输出的速度往往快于其证明这些输出正确性、真实性或意义的速度。第三,最可靠的部署模式是人为协作而非完全自主:人工智能可以减少检索、撰写、编码、可视化、评审支持和传播等环节的机械摩擦,但研究人员必须保留对判断、解释、实验设计、论证和问责的责任。第四,有效的系统越来越依赖于结合探索、基于工具的执行和验证的分层架构,这表明编排、溯源和反馈设计与模型规模同等重要。第五,人工智能在研究中的应用正逐渐成为一个治理问题,而不是一个检测问题:随着人工智能辅助变得常规化,关键问题是信息披露、归属、责任以及科学诚信是否得到维护。
这项工作对新兴的人工智能自动研究领域做出了三项贡献:
- 我们提供了一套统一的 AI 自动研究分类体系,分为四个阶段和八个步骤,涵盖了写作和编码等成熟领域,以及反驳、科学可视化和研究成果传播等未充分探索的领域。
- 我们综合了整个生命周期中的工具、基准和方法论系列,展示了系统如何从基于提示的辅助演变为检索增强型、智能型、微调型和混合型工作流程。
- 我们确定了跨领域能力边界和未决挑战,包括阶段边界忠实性、科学判断、可重复性、引用来源、治理、跨领域概括和认知所有权。
本文余下部分组织如下:第 2 节介绍生命周期框架、方法论系列、文献收集范围和发展时间表;第 3 节至第 6 节按时间顺序构建人工智能辅助研究的四个阶段路线图;第 7 节总结端到端系统、评估范式、跨领域见解和未解决的挑战;第 8 节总结全文。
2.Preliminaries
随着人工智能辅助研究工具从孤立的单一阶段(例如写作或编码辅助工具)扩展到多阶段辅助系统,使用单一术语对该领域进行比较变得越来越困难。现有系统不仅在技术设计上存在差异,而且在它们所针对的研究阶段、自主程度以及引入的科学风险方面也存在差异。
为了支持统一的分析,我们首先建立了四个基础要素:(i)组织本次综述的高级学术研究生命周期框架(第 2.1 节),(ii)在每个阶段反复出现的方法论系列(第 2.2 节),(iii)我们文献收集的范围和方法(第 2.3 节),以及(iv)关键发展的简要时间线(第 2.4 节)。
2.1 Research Lifecycle
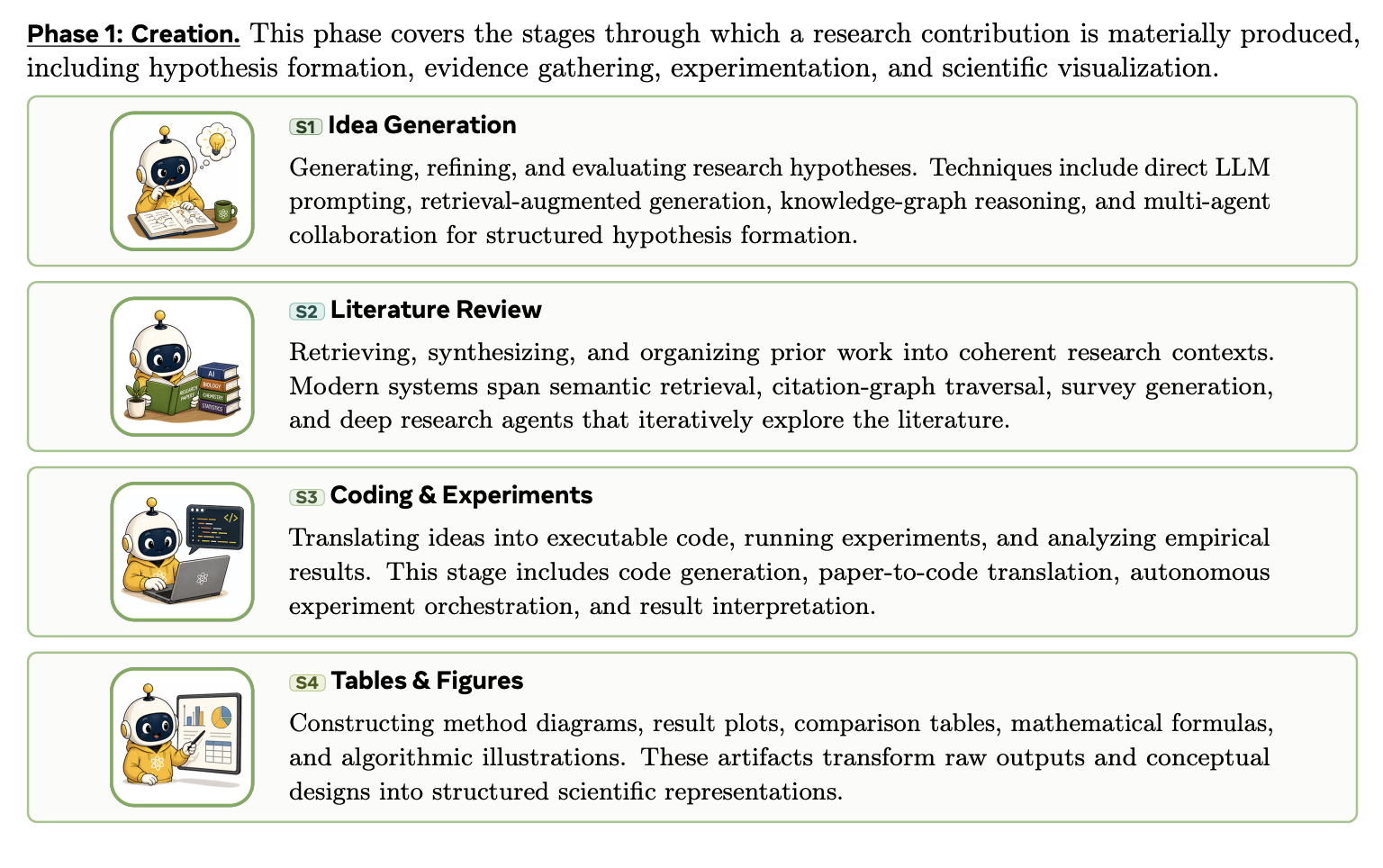

我们将科研生命周期定义为八个相互关联的步骤,共分为四个阶段。每个阶段又包含若干步骤,这些步骤在科学知识的生产、验证和传播中发挥着共同的作用。
Phase 1: Creation。该阶段涵盖了研究成果的物质产生过程,包括假设形成、证据收集、实验和科学可视化。
Phase 2: Writing。这一阶段将“Creation”的成果整理成正式的学术手稿,以便交流和接受外部审查。
Phase 3: Validation。这一阶段涵盖了研究界对稿件进行审查、批评和反复改进的各个阶段。
Phase 4: Dissemination。此阶段将手稿及其辅助材料转换为更广泛的研究和公众受众可以访问的格式。
尽管按时间顺序呈现,但生命周期并非严格线性。第三阶段(验证)的审稿人意见可能需要返回第一阶段(创建)进行额外实验,而第四阶段(传播)的传播成果可能会暴露出歧义或错误,从而触发第二阶段(撰写)的修改。这些反馈循环是研究实践的核心,对于人工智能辅助的工作流程尤为重要,因为如果不进行明确的检查,错误可能会在各个阶段之间传播。
这四个阶段的划分反映了研究的功能结构。证据和成果在 P1 Creation 阶段产生,在 P2 Writing 阶段整理成文稿,在 P3 Validation 阶段接受外部审查,并在 P4 Dissemination 阶段向更广泛的受众传达。
我们将 Writing 与 Creation 分开,因为稿件构建不仅仅是一个格式调整步骤:它是一个修辞和论证组织过程,所需的 AI 能力与生成代码、实验或图表所需的 AI 能力截然不同。我们将“同行评审”和“反驳”归入 Validation 阶段,因为它们共同构成了面向社群的机制,通过该机制,各种主张可以受到质疑、辩护和修正。最后,我们将 Dissemination 视为一个完整的阶段,因为海报、幻灯片、视频、项目页面和社交媒体摘要等日益成为重要的知识载体,它们对内容的真实性和可信度有着自身的要求。
2.2 Methodological Families
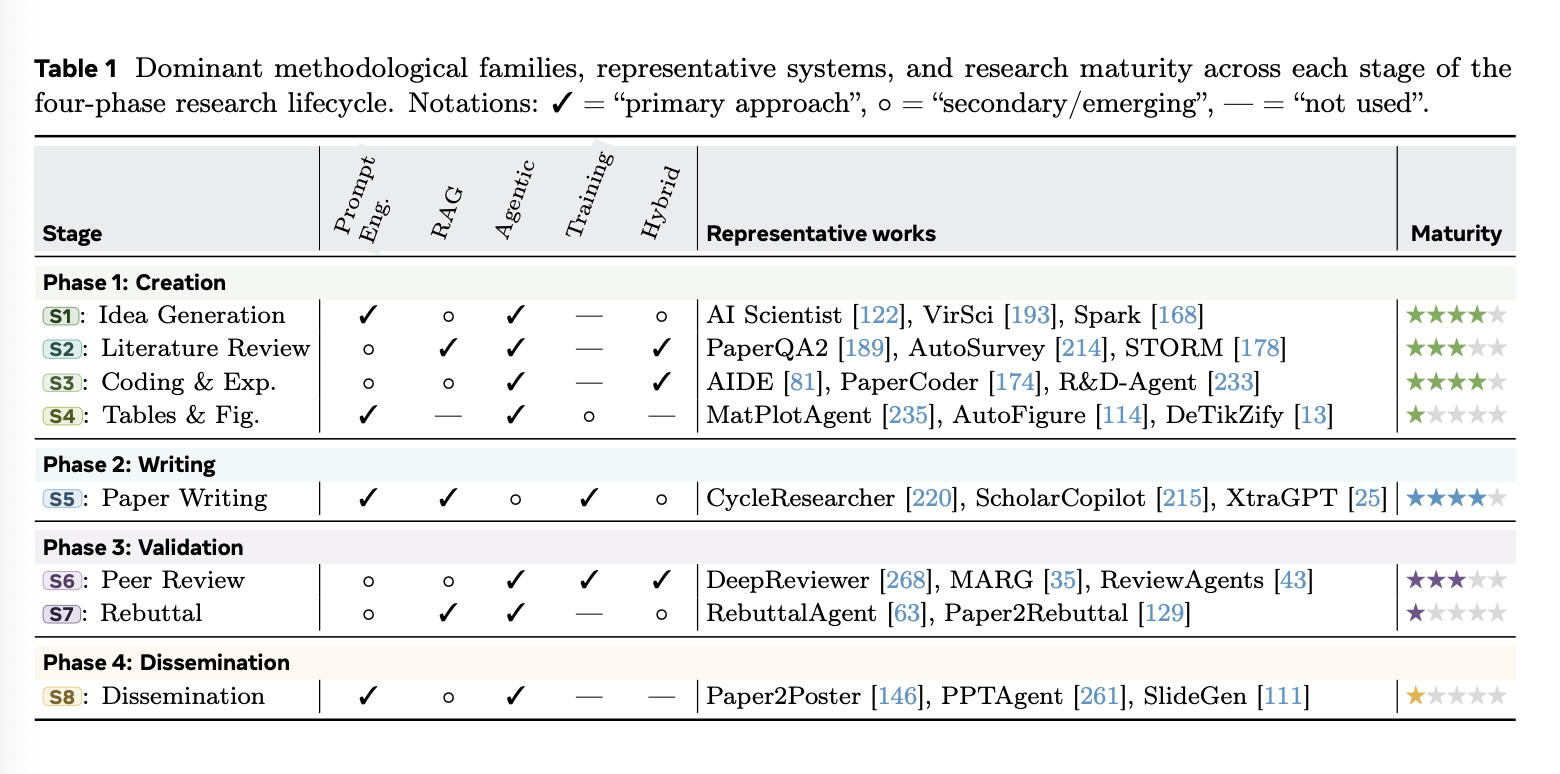
在整个研究生命周期中,人工智能辅助研究系统会重复使用少量的方法模式。我们将其归纳为五大类:1. 提示工程;2. 检索增强生成(RAG);3. 训练无关的智能体方法;4. 基于训练的方法;以及5. 混合方法。这些类别并非互斥或严格按时间顺序排列;相反,它们描述了当前系统如何引出、构建、专业化和协调 LLM 行为。许多实际系统会结合其中几种方法,例如使用提示进行分解,使用 RAG 进行构建,使用工具进行执行,以及使用训练模块进行评分或排序。
Prompt engineering。提示工程为将 LLM 应用于研究任务提供了最简便的界面。它包括直接提示、逻辑推理、角色分配、结构化模板、基于评分标准的指导以及输出限制。由于无需额外训练,它仍然广泛用于头脑风暴、编辑、审稿草稿、反驳提纲撰写和社交媒体内容生成等轻量级任务,但它对提示措辞较为敏感,且通常缺乏持久的稳定性。
Retrieval-augmented generation (RAG)。检索增强生成(RAG)将模型输出与外部资源联系起来,包括论文语料库、引用图谱、代码库、基准测试记录和实验日志。它对于文献综述、引用支持、证据核查、反驳生成以及需要注明来源的阶段尤为重要。RAG 通过在推理阶段向模型提供证据来减少模型的“幻觉”,但并不能保证所选资源的正确性、版本一致性或真实性。
Training-free agentic methods。训练无关的智能体方法通过规划、工具使用、记忆、自我反思和迭代执行等功能扩展了 LLM,从而实现无需更新模型参数的多步骤工作流程。这些方法对于深度文献探索、代码调试、实验编排、审稿回复规划以及 Paper2X 工作流程至关重要。它们的优势在于流程编排,而主要风险在于检索、工具使用或自我反思失败时可能出现的错误传播。
Training-based methods。基于训练的方法针对特定阶段的分布(例如同行评审、科学论文、代码库、引用上下文、反驳记录或基准测试轨迹)定制模型。这些方法包括有监督微调、指令微调、偏好优化、强化学习和领域特定自适应。它们可以提高一致性、格式遵循度、领域词汇量和任务特定判断能力,但严重依赖数据质量,并且可能过度拟合于狭窄的基准测试或测试环境分布。
Hybrid approaches。混合方法将多种方式组合成集成的研究系统,例如将 RAG 与智能体规划相结合、微调特定领域的子模块,或将基于提示的控制器嵌入到更大的工作流中。混合系统日益普及,因为研究工作流需要生成和基础、自主性和验证,以及具有阶段特定专业化的灵活推理。
表 1 将这些方法论系列映射到八个生命周期阶段,使用主要和次要标记来指示近期系统中常见的设计模式。
2.3 Scope & Literature Collection
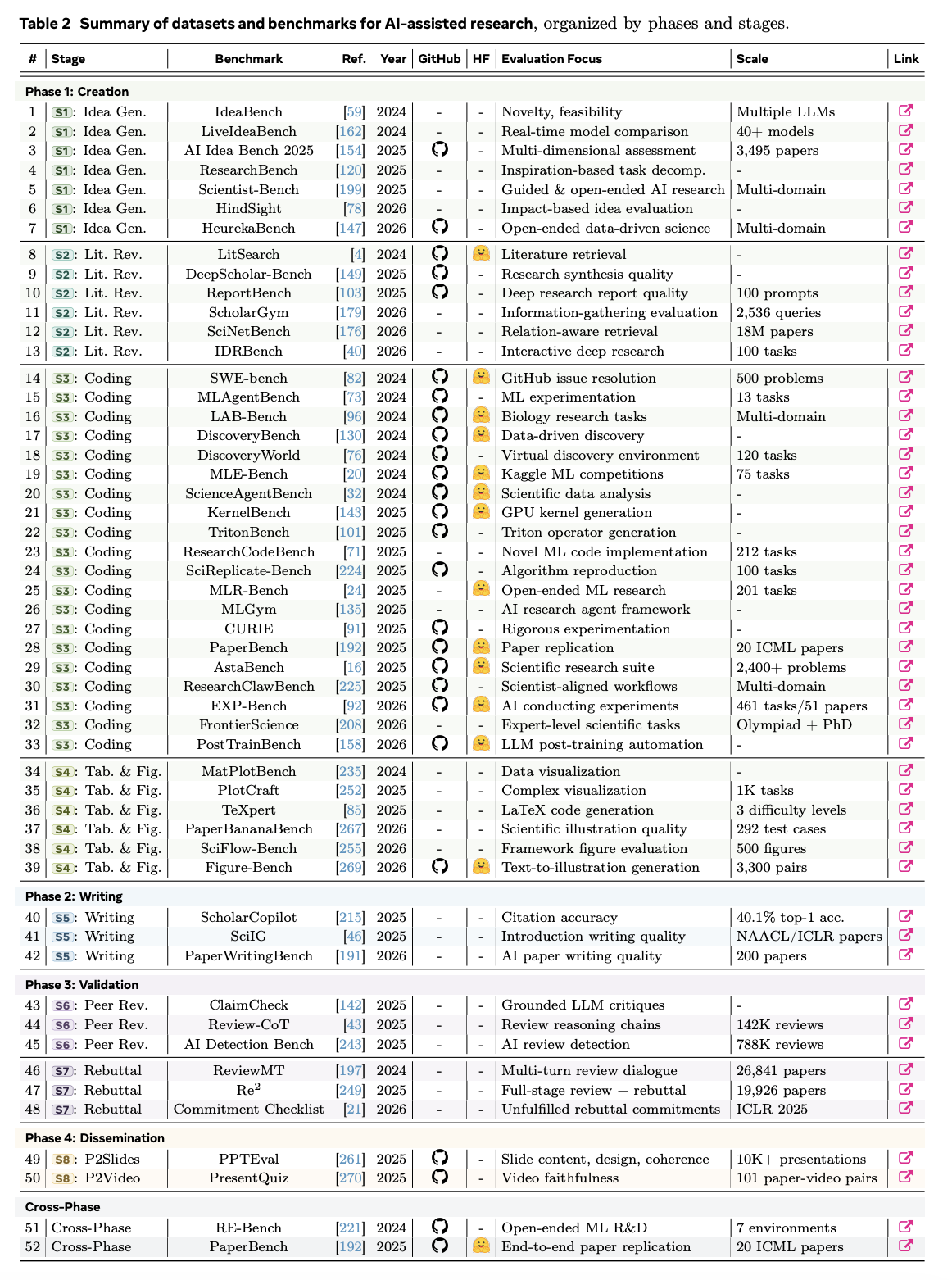
本综述聚焦于支持人类主导的学术研究的人工智能工具、方法和基准测试,重点关注计算机科学和机器学习领域。我们涵盖了 2023 年至 2026 年初期间发表或公开发布的成果,同时也会参考早期基础方法中定义的、具有普遍适用的技术范式。跨学科系统若展现出与研究生命周期相关的能力,例如自主实验、文献综合、科学编码或基于证据的写作,也会被纳入调查范围。我们排除了与研究工作流程没有明确关联的通用 LLM,以及缺乏足够技术或评估信息的封闭系统。
为构建本综述语料库,我们结合了三种互补的收集策略:
- 系统性关键词检索,在 Google Scholar、Semantic Scholar、arXiv 和 DBLP 中使用与 AI 辅助研究、自动化研究智能体、文献综述、科学编码、论文写作、同行评审、 rebuttal 生成以及研究传播相关的查询词。
- 滚雪球式引用追踪,从各研究生命周期阶段的代表性种子论文出发,既向后追溯基础性工作,也向前追踪近期系统和基准。
- 社区与代码仓库监测,包括开源项目、精选阅读列表以及基准排行榜,用以记录尚未被正式出版物覆盖的新兴工具。
一篇论文、一个系统或一个基准只有在同时满足以下三个标准时才会被纳入:(i)其至少针对第 2.1 节中定义的研究生命周期的一个阶段;(ii)其可通过出版物、预印本、开源代码仓库、基准页面或技术报告公开获取;(iii)其提供了足够的方法论或评估细节,以支持批判性分析。当同一系统存在多个版本时,我们优先考虑最新版本或技术上最完整的版本,同时在早期版本具有重要历史里程碑意义时予以注明。
最终形成的语料库覆盖了生命周期的全部四个阶段,但分布并不均衡。大多数已有文档记录的系统集中在 P1(创建) 阶段,尤其是文献综述、编码和实验自动化;其次是 P2(写作)、P3(验证) 和 P4(传播)。这种不平衡既反映了研究成熟度,也反映了出版可获得性:创建阶段的工具更常被基准评测并开源,而面向传播的工具往往具有商业化、工作流特定性,或通过较不标准化的标准进行评估。跨阶段的基准格局总结见表 2。
2.4 Development Timeline
AI 辅助研究的发展可以理解为:从特定阶段辅助向多阶段研究自动化的转变。2024 年以前,大多数系统主要面向孤立的研究任务,例如文献检索、科学问答、代码生成,或特定领域的实验规划。早期演示系统,包括 Coscientist,表明基于 LLM 的智能体能够在受约束的实验室环境中规划并执行科学工作流;而 AlphaFold 3 等领域基础模型则展示了 AI 系统改造专门化科学发现的更广泛潜力。
2024 年,该领域开始从孤立工具转向端到端研究智能体。The AI Scientist 早期展示了一条自动化流程,覆盖想法生成、实验执行、论文写作以及评审式评估。大致在同一时期,通用编码智能体、检索增强型文献系统以及科学推理基准迅速成熟,使得更系统地评估研究生命周期中的各个组成部分成为可能。这一转变标志着研究重点发生了重要变化:AI 系统不再仅被视为局部任务的助手,而是越来越多地被视为多步骤研究工作流的编排者。
到 2025 年及 2026 年初,该领域进入了快速专门化和基准化阶段。几乎在研究生命周期的每个阶段,都出现了专门系统,包括文献综合、论文到代码转换、自主实验编排、手稿写作、同行评审、rebuttal 支持、图表生成以及研究传播。例如,OpenScholar 推进了检索增强型科学综合,AI Scientist v2 探索了更强形式的端到端自动化研究,而 FARS 展示了大规模自主论文生成。与此同时,先前探索不足的阶段也开始受到专门关注,包括 rebuttal 写作(例如 RebuttalAgent)和科学可视化(例如 AutoFigure-Edit)。
这些发展表明,该领域的瓶颈不再仅仅在于模型能力本身,还在于贯穿完整研究生命周期的编排、评估、可靠性和治理。
3.Phase 1: Creation
这一阶段涵盖了研究成果实际产生的各个步骤:产生想法(S1)、将其置于先前工作中(S2)、产生经验或分析证据(S3)以及构建方法和结果的可视化表示(S4)。这些步骤共同回答了两个基本问题:贡献是什么?以及有什么证据支持它?
在四个阶段中,Creation 阶段目前拥有最丰富的工具生态系统和最广泛的基准测试覆盖范围,但其成熟度仍不均衡。“S1”(构思)阶段已吸引了大量工具的开发,但仍存在构思与执行脱节的问题,即看似新颖的想法在实施后往往会失去效力。“S2”(文献阅读)阶段正通过检索增强和智能体合成技术快速发展,但引用准确性、覆盖完整性和多篇论文关联推理仍然是难题。“S3”(编码与实验)阶段已发展到代码生成、论文到代码的转换以及自主实验编排,但在真正新颖的研究代码上,性能仍然急剧下降。“S4”(表格和图表)阶段尽管在日常研究实践中至关重要,但其发展仍然相对滞后。下文将依次讨论这四个阶段。
3.1 Idea Generation
Idea Generation 是研究生命周期的起点,在此阶段,候选假设、研究问题和实验方向被提出并完善。现有方法包括直接引导创意生成、外部启发式创意生成、多主体协作以及对创意的新颖性、可行性、多样性和后续影响进行专门评估。所有这些方法都面临着一个共同的挑战:LLM 虽然能够产生看似新颖且动机充分的想法,但往往难以产生在执行后仍然可行、独特且具有影响力的想法。
表 3(附录)提供了构思系统的完整清单。
3.1.1 LLM Internal Knowledge-Based Generation
最简单的 AI 辅助创意生成方式是直接向 LLM 输入研究领域、问题描述或文献背景。Si et al. [183] 通过一项涉及 100 多名自然语言处理研究人员的大规模人类研究建立了一个有影响力的基准,研究发现 LLM 生成的想法在新颖性方面显著高于人类的想法(p < 0.05)。这一结果表明 LLM 具有表面层面的生成能力,但也引出了一个该阶段的核心问题:表面上的新颖性是否等同于可执行且具有影响力的研究。
后续研究探索了三种强化直接生成的方法。首先,iterative refinement 利用反馈循环来提高想法的针对性并减少浅层创新。ResearchAgent 结合了学术图谱反馈来改进生成的想法;SciMON 通过迭代地将候选想法与先前的工作进行比较,来缓解直接 LLM 提示导致浅层贡献的倾向;Chain of Ideas 将文献组织成渐进式推理链,其性能优于简单的提示基线。
其次,学习到的质量信号引入了明确的评分或优化目标。Spark 将检索增强生成与基于 60 万条 OpenReview 评论训练的评判模型相结合,以评估创造力;DeepInnovator 在“下一个创意预测”范式下训练了一个 14B 模型,并在创意构思任务中取得了 80% 至 94% 的胜率,优于前沿模型;Goel et al. [52] 使用从现有论文中提取的评分标准来优化 AI 合作科学家计划,其中 70% 的情况下,人类专家更倾向于使用强化学习优化的计划。
第三,自适应测试时计算将推理工作量视为一种可控资源。IRIS 在人机协作的创意平台中使用蒙特卡洛树搜索(MCTS)来分配搜索资源,以适应创意的融合;而 FlowPIE 则通过流程引导的文献探索在测试时演化科学创意。
最近一项以创造力为中心的综述将这些方法进一步细分为知识增强、提示引导、推理时缩放、多智能体协作和参数自适应。
3.1.2 External Signal-Driven Generation
直接使用 LLM 生成受限于模型的参数知识,以及其倾向于产生看似合理但缺乏依据的观点。外部信号驱动方法通过将构思锚定于结构化知识、检索到的文献或时间性研究趋势来克服这一局限性。三种信号来源尤为常见,它们分别从不同的角度为构思提供依据:关系结构、文本证据和时间机遇。
知识图谱为假设的形成提供了关系结构。SciAgents 对科学知识图谱进行多智能体推理,而 MOOSE-Chem 将化学假设的生成分解为灵感检索、假设构建和排序,并从 51 篇高影响力论文中重新发现了假设。MOOSE-Chem2 将这一方向扩展到更细粒度、可实验操作的假设。论文检索将想法建立在非结构化文献之上。SciPIP 提出与检索到的论文相关的想法,而 IdeaSynth 将想法的各个方面表示为交互式画布上的节点,以便进行基于文献的改进;在一项包含 20 名参与者的用户研究中,IdeaSynth 鼓励用户探索比仅使用 LLM 的基线更多的替代方案。趋势分析着眼于研究机会的时间维度。Nova 使用迭代规划和搜索来识别具有更高多样性的新兴研究方向。这些方法共同表明,外部基础不仅仅是一个辅助特征,而是将产生的想法与研究前沿联系起来的关键机制。
3.1.3 Multi-Agent Collaborative Generation
多智能体创意系统旨在通过模拟科研社群互动(例如角色分工、批判、修改和辩论)来提升创意质量。VirSci 构建了一个虚拟科学社群,其中多个 LLM 智能体参与结构化讨论,其创新性得分高于单智能体 AI Scientist 基线系统(5.24 对 4.94)。分析表明,智能体多样性和讨论结构至关重要,最佳配置为 8 名成员参与 5 轮讨论,且成员多样性为 50%。
然而,多智能体扩展并非总是有益的。SIGDIAL 2025 的一项研究发现,三轮评论-修改通常就足够了,而更多的轮次收益会递减。其他系统则探索了除讨论之外更丰富的协作机制:Gu et al. [57] 通过跨领域组合想法来研究组合创造力,而 Deep Ideation 设计了能够通过结构化图探索来导航科学概念网络的智能体。
然而,最近的证据也指出了一个更深层次的局限性:“人工蜂巢思维”研究报告称,LLM 生成的想法往往聚集在思想空间的狭窄区域,这表明多样性崩溃可能是当前模型的结构属性,而不是简单地通过增加更多 Agent 就能解决的问题。
3.1.4 Assessment: Novelty and Feasibility
评估产生的想法并非易事,因为优秀的科研想法必须同时满足多个标准:新颖性、可行性、清晰度、重要性和最终影响。早期基准可以量化其中的部分要素,但核心问题在于,一个想法在实施、测试并与先前的工作进行比较后,是否仍然具有价值。
IdeaBench 使用涵盖八个研究领域的 2374 篇有影响力的论文来评估创意生成能力,而 LiveIdeaBench 则使用涵盖 22 个领域的 1180 个关键词提示来探究科学创造力。两者都表明,通用基准测试无法很好地预测科学创造力,而以推理为中心的模型通常表现更佳。ResearchBench 通过基于灵感的任务分解扩展了评估范围,而 AI Idea Bench 2025 则将评估范围扩大到涵盖两个评估维度的 3495 篇论文。
这些基准测试中反复出现的一个模式是表面上的新颖性与实际可行性之间的差距。IdeaBench 报告称,许多 LLM 在新颖性方面的得分高于 0.6,但在可行性方面的得分低于 0.5,这表明产生听起来合情合理的想法仍然比产生可以执行和验证的想法更容易。HindSight 通过引入基于时间分割和影响的评估方法,进一步凸显了这一问题,结果表明,LLM 作为评判者可能会高估那些听起来新颖但最终无法转化为有影响力的工作的想法。这一发现表明,当前的评估方案可能奖励的是表面上的新颖性,而不是真正的研究潜力,这强调了基于执行且具有时间稳健性的评估方法的必要性。
3.1.5 Findings and Observations

3.2 Literature Review
文献阅读通过检索相关文献、综合证据并将现有发现组织成一个连贯的理论框架,将研究锚定在已有知识之上。与构思阶段相比,这一阶段更具基础性,也更容易被外部验证,使其成为人工智能辅助研究中发展最快的领域之一。现有系统已经从语义论文检索发展到基于引用的综合分析和长期深度研究 Agent。然而,仍然存在两个核心局限:系统虽然能够越来越有效地检索和总结单篇论文,但在忠实引用、覆盖完整性和多篇论文关联推理方面仍然面临挑战。
表 4(附录)提供了文献阅读系统的完整清单。
3.2.1 Literature Retrieval
检索是人工智能辅助文献阅读的基础:后续的每一项综合分析都取决于系统能否从包含数千万条记录的科学语料库中找到合适的论文。现有方法可分为三种模式。语义检索是基线方法,它利用密集表示和基于 LLM 的问题理解,超越了关键词匹配的局域化检索。LitLLM 将 LLM 与学术数据库集成,实现密集检索;而PaperQA2 在此基础上增加了引用验证功能,并在科学文献检索方面表现出色。
基于引用图的增强检索方法在嵌入之外增加了结构信号。这些方法不再将论文视为孤立的文档,而是利用引用链接、论文关系和图遍历来提升上下文覆盖率。OpenResearcher 将 RAG 与图遍历相结合,以加速文献探索。Agentic multi-step retrieval 进一步将检索从一次性排序问题转变为迭代搜索过程。PaSa 部署了一个 LLM 智能体,该智能体发出后续查询并优化候选集,从而模拟人类研究人员探索陌生主题的方式。除了这些方法之外,还出现了专门用于评估检索质量的基准测试:LitSearch 侧重于检索精度,而 CiteME 则专注于引用准确性。总而言之,这些努力表明,找到相关论文变得越来越容易,但确保检索到的论文得到忠实利用仍然是一个难题。
3.2.2 Survey and Related Work Generation
Synthesis 将检索到的论文转化为结构化的叙述。这标志着研究方向从以检索为导向、优化论文排名和覆盖范围的系统,转向以生成为导向、必须识别主题、比较方法、揭示矛盾并阐明研究空白的系统。该子领域经历了多种日益结构化的设计发展。
Single-pass systems 证实了自动综述生成的可行性。AutoSurvey 证明,LLM 可以端到端地生成质量尚可的综述,而 SurveyX 则提高了内容质量,并在某些方面接近了人类专家的水平。随后,结构感知系统将大纲规划从格式化步骤提升为核心的综合产物。STORM 引入了多视角提问来构建全面的主题大纲,而 SurveyForge 则从人工编写的综述中学习大纲启发式方法,并结合记忆驱动的内容生成,在大纲质量方面优于 AutoSurvey。
Multi-agent decomposition 将检索、验证、组织和叙述性写作分解为专门的子任务。LiRA 和 Agentic AutoSurvey 为不同的角色配备了专用智能体,而 IterSurvey 将大纲生成视为一个带有稳定性检查的迭代规划问题。InteractiveSurvey 进一步引入了用户自定义功能,允许研究人员通过交互式界面改进参考文献分类和大纲结构。
Citation- and editor-aware systems 完善了文献合成与写作环境之间的闭环。SurveyG 构建了一个三层引用图(基础/发展/前沿),并采用分层遍历;Citegeist 在 arXiv 语料库上构建了一个动态的 RAG 流水线;CiteLLM 将无幻觉的参考文献发现功能直接嵌入到 LaTeX 编辑器中。GPT Researcher、PaperQA 和 ChatPaper 等开源系统进一步表明,文献合成工具的应用已超越了受控的研究原型,并日益普及。然而,引用准确性仍然是一个瓶颈:ScholarCopilot 报告的 top-1 引用准确率仅为 40.1%,这表明生成看似合理的相关工作文本仍然比为每个论点找到正确的来源更容易。
3.2.3 Deep Research Agents
深度研究 Agent 与单次检索综述生成系统不同,它将文献探索视为一个迭代的、智能体驱动的过程。给定一个开放式查询,它们会规划子查询,检索并阅读文献,更新其内部状态,并持续进行,直到能够生成一份具有足够置信度的报告。这种循环使得深度研究 Agent 更接近于长期信息检索的工作流程,而非单一的检索模型。
Commercial systems 已将这种范式推广应用于广泛的信息综合。OpenAI Deep Research、Google Deep Research、Perplexity 和 Elicit 都支持多源检索和报告生成,但它们在延迟、引用格式、交互性和目标用例方面有所不同。开源的文献专用系统将这种范式应用于科学研究。发表于《自然》杂志的 OpenScholar 是一款检索增强型语言模型,它搜索大规模开放获取的科学语料库,并在科学文献基准测试中优于 PaperQA2 和 Perplexity Pro。阿里巴巴的同义深度研究 是一款智能体 LLM,专门用于长期深度信息检索,并在深度研究基准测试中取得了优异的成绩。
Training-era approaches 旨在解决限制长期研究智能体的数据和优化瓶颈。O-Researcher 将多智能体蒸馏与智能体强化学习相结合,以提升基准测试性能;而 OpenResearcher 则通过构建基于大型文档集的离线轨迹合成流程来解决轨迹数据瓶颈问题。这些合成轨迹为训练研究智能体提供了长期工具使用方面的指导。针对特定领域的变体对于专门的合成任务仍然至关重要:CHIME 提供了基于 LLM 的科学研究分层组织;发表于《自然机器智能》的 ASReview 使用基于主动学习的筛选方法,在保持召回率的同时,减少了系统评价中的人工工作量。总而言之,深度研究智能体涵盖了从轻量级事实查找到长期自主合成的各种功能,但它们越来越趋向于相同的迭代架构:规划、检索、阅读、更新和合成。
3.2.4 Assessment: Retrieval and Synthesis Quality
评估标准已从单纯的检索准确率(“系统是否找到了正确的论文?”)转向更广泛的综合质量(“它是否生成了有用、准确且条理清晰的综述?”)。在输出层面,DeepScholar-Bench 为研究综合建立了涵盖覆盖面、连贯性和事实准确性的专门基准。ReportBench 将这一方向扩展到基于综述风格提示生成的深度研究报告。
在过程层面,ScholarGym 通过将深度研究的信息收集阶段分解为查询规划、工具调用和相关性评估,从而将其分离出来。这是评估系统如何得出答案(而不仅仅是评判最终输出)的早期步骤。基准测试也开始探索文献能力的结构和交互维度。SciNetBench 针对大规模人工智能文献引入了关系感知文献检索 Agent 的基准测试,结果表明关系感知检索的准确率通常仍然较低。IDRBench 通过具有按需用户交互的交互式深度研究任务来解决人机交互维度的问题。
在这些研究中,四个评估维度逐渐清晰:引用准确性,即参考文献是否正确标注并忠实地支持相关论点;覆盖完整性,即综述是否全面涵盖了相关领域且无重大遗漏;叙述连贯性,即综述是否逻辑清晰、主题组织有序且易于阅读;以及事实依据,即论点是否由引用的证据支撑而非臆想。SurveyX 通过将内容质量、结构质量和引用准确性作为独立维度进行评估,体现了这种多维度视角。目前面临的主要挑战是开发能够与专家对综述质量的判断相符,同时又能适应不同领域、平台和写作风格的自动化指标。
3.2.5 Findings and Observations

3.3 Coding and Experiments
这一阶段将研究思路转化为可执行的实现方案,运行实验,并分析实验结果。与文献阅读相比,编码和实验需要人工智能系统与外部环境交互,例如代码库、依赖项、数据集、计算资源、测试套件和评估脚本。现有工作涵盖通用代码生成、论文到代码的转换、实验编排和结果分析。在这些方向上,核心挑战并非 LLM 能否编写合理的代码,而是它们能否生成语义正确的实验实现方案,执行有意义的实验,并可靠地解释实验结果。
表 5(附录)提供了编码和实验系统的完整清单。
3.3.1 Code Generation
通用代码生成已成为当前 LLM 最成熟的功能之一。在评估真实 GitHub 问题解决能力的 SWE-bench Verified 测试中,前沿系统的得分已超过76%。Agent 框架在这一进展中发挥了核心作用。SWE-agent 建立了 agent-computer 接口范式,使 LLM 能够以结构化的方式访问文件、测试和工具调用,而无需依赖非结构化的 shell 交互。OpenHands 将这一方向扩展为一个通用的软件工程 Agent 开放平台,并已成为面向编码的工作流程的通用骨干。
然而,在标准软件基准测试中取得优异成绩并不直接意味着软件已准备好用于研究性编码。SWE-bench Verified 测试因可能存在污染而受到质疑,而更具挑战性的变体测试则暴露出更明显的局限性:在 SWE-bench Pro 和 SWE-EVO 测试中,性能分别下降至 23% 和 25%。这些结果表明,当任务熟悉、框架完善或可进行模式匹配时,标准基准测试可能会高估软件的鲁棒性。在研究环境中,这种差异更为显著,因为研究的目标不仅是修复现有软件,还要实现未明确定义的算法、重现隐含的设计选择并验证科学论断。
3.3.2 Paper-to-Code
论文到代码的转换是一种专门针对研究领域的代码生成方式。它比传统的软件工程更难,因为研究论文通常混合了自然语言描述、公式、伪代码、消融细节和领域约定,同时又隐含地给出了关键的实现选择。PaperCoder 通过一个三阶段的多智能体框架来解决这个问题,该框架用于规划、分析和代码生成,从而将机器学习论文转换为可执行的代码库。
专门的基准测试量化了这一场景的难度。ResearchCodeBench 在 212 个全新的机器学习实现任务上评估了 LLM,其中最佳模型的准确率仅为 37.3%;值得注意的是,58.6% 的错误是语义性的,这意味着生成的代码可以运行,但实现了错误的算法或行为。SciReplicate-Bench 在 36 篇自然语言处理论文的 100 个任务中也报告了类似的 39% 的上限。SciCode 将研究级代码评估扩展到数学、物理和化学领域,而 PaperBench 将 20 篇 ICML 2024 论文分解为可单独评分的子任务,涵盖环境设置、实验执行和结果复现。总而言之,这些基准测试揭示了通用软件问题解决与忠实的研究实现之间存在着巨大的差距。
3.3.3 Experiment Execution and Orchestration
代码可用之后,下一个挑战是如何系统高效地运行实验。实验编排系统为规划运行、修改代码、启动作业、监控结果以及迭代解决失败提供了基础设施。MLAgentBench 用于评估机器学习实验中的语言 Agent;MLR-Copilot 将自主研究分为构思 Agent 和实验 Agent;DS-Agent 旨在构建端到端的数据科学工作流程;AIDE 将机器学习工程视为代码空间中的树搜索。更广泛的评估环境,包括 MLR-Bench、MLE-Bench、MLGym 和 CURIE,为衡量自主实验提供了日益标准化的测试平台。
近期出现的系统推动着这一基础设施向更高吞吐量和闭环研究工作流程发展。R&D-Agent 采用研究者-开发者双 Agent 设计进行机器学习实验,而 Karpathy 的 autore search 则展示了高吞吐量的实验迭代。CodeScientist、Dolphin 和 NovelSeek 等闭环系统试图将假设生成、实现、执行和验证连接起来。EvoScientist 通过报告由自演化研究流程生成的已接收论文,进一步展现了这一方向的雄心。这些系统表明,实验吞吐量和工作流程自动化正在快速提升,但它们的可靠性仍然严重依赖于任务框架、基准测试设计和验证质量。
另一项互补的研究工作将执行过程与搜索和学习信号相结合。AlphaEvolve 通过 LLM 生成的变异和自动评估来改进算法。Si et al. [185] 使用基于执行过程的搜索方法,结合大规模并行 GPU 实验,其性能优于 GRPO 基线模型。SciNav 使用成对树搜索判断来选择有希望的分支,而 Yuksekgonul et al. [245] 则结合测试时训练和强化学习,在数学、GPU 内核优化和计算生物学领域实现持续改进。AutoReproduce 则解决了一个不同但相关的问题:通过从论文谱系中提取隐含知识来复现被引用的实验。
特定领域的系统展示了当环境从纯粹的计算环境转变为科学环境时,编排方式会发生怎样的变化。在化学领域,Coscientist 和 ChemCrow 使用基于 LLM 的工具来支持自主研究工作流程。在生物学领域,AlphaFold 3 将蛋白质结构预测扩展到生物分子复合物,而 CRISPR-GPT、BioPlanner 和 LAB-Bench 则专注于基因编辑设计、方案规划和生物学研究评估。对于系统级优化,KernelBench 和 TritonBench 评估 LLM 是否能够生成高效的 GPU 内核和 Triton 算子。跨领域套件,例如 AstaBench 和 EXP-Bench,将评估范围扩展到多领域科学任务和自主实验执行。
总体而言,执行层发展迅速,尤其是在任务定义明确且反馈自动化的情况下。更棘手的问题是实验规划:决定哪些实验值得运行、运行顺序如何,以及如何解读失败结果。许多现有系统在预设任务池上表现良好,但在选择真正新颖的研究方向时,可靠性却不尽如人意。从这个意义上讲,编码和实验揭示了与 idea 相同的普遍模式:执行能力的提升速度超过了决定执行哪些任务所需的科学判断能力。
3.3.4 Assessment: Code Correctness and Reproducibility
评估编码和实验系统不仅仅是检查生成的代码是否能运行。研究代码必须实现预期的算法,复现已报告的结果,支持有意义的消融实验,并生成可以正确解读的证据。因此,语义正确性和可复现性是核心的评估标准。
多项基准测试揭示了这一解释层的难度。DiscoveryBench 和 ScienceAgentBench 评估了基于实验数据的科学推理能力,结果表明,LLM 在处理复杂结果集的多步骤分析时仍然面临挑战。DiscoveryWorld 提供了一个包含 120 个挑战任务的虚拟环境,供自动化科学发现 Agent 使用。InfiAgent-DABench 对端到端的数据分析工作流程进行基准测试,涵盖数据清洗、统计检验和可视化生成等多个领域。
核心瓶颈在于如何从原始输出转化为可信的结论。现有系统通常可以生成图表、汇总统计数据和局部解释,但在识别具有统计意义的趋势、诊断故障模式、设计有效的消融方案以及将结果综合成连贯的经验论证方面,其可靠性较低。这一局限性尤其重要,因为编码错误和实验误读可能会蔓延到后续的写作和审阅阶段,在这些阶段,精心润色的叙述可能会掩盖薄弱或错误的证据。
3.3.5 Findings and Observations

3.4 Tables and Figures
表格和图表将实验结果、统计摘要、算法和概念设计转化为可发表的研究成果。现有系统涵盖科学图表生成、数据可视化、表格构建、公式生成和算法图示。与编码和实验相比,这一阶段的重点不在于产生新的证据,而在于忠实地呈现证据。在所有这些成果类型中,核心挑战在于视觉合理性和科学正确性之间的差距:人工智能生成的输出可能看起来很专业,但可能包含错误的标签、误导性的布局、无效的数值关系或特定领域的符号错误。
表 6(附录)提供了图表生成系统的完整清单。
3.4.1 Scientific Figure Generation
科学图表的绘制涵盖方法图、架构图、结果图、数据可视化和流程图。标准结果图相对容易绘制,因为它们通常可以基于结构化数据和可执行的绘图代码。相比之下,方法图和框架图则更难绘制,因为它们需要精确的空间组织、正确的信息流、特定领域的符号以及论文特定的视觉规范。
对于方法图和架构图,AutoFigure-Edit 可以根据长篇文本生成可编辑的文本到 SVG 格式的科学插图,使用户能够修改生成的图形,而不是将其视为固定图像。其配套系统 AutoFigure 引入了 FigureBench,用于生成和优化面向出版物的科学插图。PaperBanana 采用多个专用 Agent 进行检索、规划、样式设置、可视化和评估,而 StarVector 则专注于根据文本描述生成可缩放矢量图形。这些系统共同展现了图形构建方式从静态图像生成向可编辑、结构化且支持评估的转变。
对于结果图和数据可视化,MatPlotAgent 使用基于 VLM 的视觉反馈来提升数据可视化质量,而 PlotGen 和 PlotCraft 则研究了不同图表类型和任务难度下的图表生成。CoDA 探索了用于可视化的多智能体协作,ChartGPT 将图表生成分解为一系列顺序推理步骤,以处理抽象的自然语言输入。更新的系统扩展了生成和评估的范围:SciFig 为流程图引入了基于评分标准的评估方法,VisCoder 研究了大规模的基于代码的可视化生成,DiagramAgent 使用专门的智能体针对多种图表类别,而 SciFlow-Bench 通过结构优先分析来评估科学框架图。这些努力表明,标准数据图的处理能力越来越强,而复杂的框架图仍然难以处理,因为它们需要结构一致性,而不仅仅是视觉吸引力。
对于图形编辑和优化,VIS-Shepherd 为基于 LLM 的数据可视化提供建设性反馈,强调批判和修改,而非仅仅直接生成图形。[22] 调查了出版商关于 AI 生成图形的政策,并提出了负责任使用的最佳实践指南。SAIL框架将 LLM 与代码语法分离,使研究人员能够在将实现细节委托给 AI 的同时,保持科学监督。在这些系统中,新兴的设计原则是人工引导的改进:AI 可以加速布局、渲染、样式和可访问性的改进,但研究人员必须验证图形是否忠实地反映了底层方法或数据。
3.4.2 Table Understanding and Generation
表格生成包含两个互补的任务:理解现有表格和创建新表格。在理解方面,Chain-of-Table 通过多步骤表格转换进行表格推理,这反映了许多表格任务需要顺序操作而非单次提取的事实。在生成方面,ArxivDIGESTables 将科学文献合成为结构化的比较表格,ShowTable 引入了协作反思和改进机制,以实现创造性的表格可视化,而 Table2LaTeX-RL 使用强化的多模态语言模型将表格图像转换为 LaTeX 代码。
与标准图形生成相比,表格生成仍不够成熟,因为科学表格必须满足更严格的语义约束。比较表格需要一致的坐标轴、公平的方法分组、完整的引用覆盖以及正确的数值转录。消融实验表格的要求更高,因为它们不仅包含最终结果,还包含实验设计选择。AbGen 使用来自自然语言处理论文的专家标注示例,对消融实验设计中的 LLM 进行了评估,结果显示 LLM 生成的表格方案与人类专家的判断之间存在显著差距。这表明表格生成不仅仅是一个格式问题;它还需要理解哪些比较具有科学意义以及如何组织证据。
3.4.3 Mathematical Formulas and Algorithm Pseudocode
数学公式、TikZ 图和算法伪代码是科学推理的简洁表示,因此它们对微小错误尤为敏感。与普通散文或标准图表不同,这些工具需要同时保证语法和语义的精确性:符号、索引、运算符、箭头或依赖关系的错位都可能改变方法的含义。因此,公式和伪代码的生成不如自然语言润色或标准可视化那样稳健。
近期的系统通过专用数据集、多模态输入和迭代优化来应对这一挑战。AutomaTikZ 引入了大规模 TikZ 数据集 DaTikZ,并表明经过微调的模型在科学矢量图形方面可以超越通用的 LaTeX 模型。DeTikZify 在此基础上,利用多模态输入和基于蒙特卡洛树搜索 (MCTS) 的迭代优化,处理更大的 TikZ 图形数据集。TikZilla 进一步表明,通过有监督微调和强化学习进行领域特定训练,可以使规模较小的开源模型在 TikZ 图形生成方面与规模较大的通用模型相媲美。TeXpert 则凸显了仍然存在的难题:随着 LaTeX 任务变得更加复杂,准确率会急剧下降,尤其是在处理包含合并单元格、嵌套环境和非平凡格式约束的表格时。这些结果强化了表格和图形生成的一般规律:专用训练和迭代优化有所帮助,但当视觉或符号制品承载科学意义时,人工验证仍然必不可少。
3.4.4 Assessment: Visual Fidelity and Scientific Accuracy
表格和图像生成的评估必须同时考察视觉保真度和科学准确性。视觉保真度关注生成物是否可读、审美上协调,并符合出版规范。科学准确性关注生成物是否忠实地表示了底层数据、方法、比较关系,或数学关系。这一区分至关重要:AI 生成的图像可能看起来很专业,但其中却包含箭头未对齐、标签错误、无效的定量关系,或特定领域符号使用错误等问题。
近期基准越来越多地针对这一差距。SciFlow-Bench [255] 使用逆向解析评估来检测结构上不正确但视觉上可信的框架图。FigureBench [269] 评估科学插图生成与优化。PlotCraft [252] 研究图表类型间的迁移,而 SciFig [74] 提供了一个基于评分量表的流水线图评估。TeXpert [85] 评估不同难度级别的 LaTeX 生成,揭示了在困难样例上的显著性能下降。AbGen [260] 将评估扩展到消融实验设计,其中的挑战不仅是格式化表格,还包括选择具有科学意义的比较。
在不同生成物类型中,成熟度仍然不均衡。标准结果图最容易处理,因为它们可以从结构化数据生成,并通过可执行绘图代码进行验证。方法图和框架图仍然更难,因为它们需要空间组织和语义一致性。当表格编码的是比较逻辑或消融设计,而不仅仅是简单格式时,表格也会变得困难。数学公式、TikZ 图和伪代码表现出很大的准确性断崖,因为微小的句法错误就可能改变科学含义。总体而言,这些基准表明,S4 评估正在从基于外观的判断,转向面向结构、语义和任务感知的评估。
3.4.5 Findings and Observations

3.5 Summary and Transition: Creation
四个 Creation 阶段在实践中紧密耦合。S1(Idea Generation,想法生成)产生候选假设,S2(Literature Review,文献综述)将其置于既有工作之中,S3(Coding and Experiments,编码与实验)将其转化为可执行实现和经验证据,而 S4(Tables and Figures,表格与图像)则把所得输出转换为用于交流的视觉化和结构化生成物。贯穿这些阶段的进展呈现出一种一致模式:AI 系统在生成研究生成物方面越来越有效,包括想法、文献摘要、代码、实验、图像和表格;但在验证这些生成物是否新颖、忠实、可执行且具有科学意义方面,它们仍然不够可靠。
这一差距在每个阶段表现不同。在 S1 中,看似合理的新颖性往往会在实现之后减弱。在 S2 中,流畅的综述可能掩盖引用错误或覆盖不完整的问题。在 S3 中,可执行代码仍可能在语义上出错,自动化运行也不能保证实验设计具有意义。在 S4 中,经过润色的视觉生成物可能误表示数据、符号或方法结构。这些失败模式表明,Creation 阶段的自动化在与基础依据、执行反馈、显式验证以及人类科学判断相结合时,才最可信。
Phase 1(Creation,创造)的输出构成了 Phase 2(Writing,写作)的原材料。想法、检索到的文献、经过验证的实验、统计摘要、比较表格和科学图像,必须被组织成一篇连贯的手稿,用以解释贡献、论证其重要性,并使其准备好接受外部审查。因此,我们接下来转向 Writing,在这一阶段,AI 辅助从研究生成转变为将证据组织成学术论证。
4.Phase 2: Writing
本阶段仅包含一个步骤:Paper Writing(S5)。写作之所以单独成阶段,是因为它将第一阶段产生的成果转化为学术论证。这并非仅仅是格式调整:论文必须选择证据、构建论点、将研究成果置于文献语境中、详细解释方法以确保可复现性,并在第三阶段(验证)接受外部审查之前预先考虑可能出现的异议。与侧重于成果产出的第一阶段(Creation)相比,第二阶段(Writing)则更强调修辞组织和证据论证。
这一区别对于人工智能辅助研究至关重要。写作工具是人工智能科研生态系统中应用最广泛的系统之一,涵盖语法纠错、句子润色、章节撰写、引文支持和论文全文生成等功能。与此同时,写作也是伦理上最为敏感的阶段之一,因为作者身份、署名权、信息披露以及辅助和生成之间的界限等问题仍未得到解决。因此,核心挑战并非人工智能能否生成流畅的学术文章,而是它能否保留事实依据、论证深度、引文准确性以及人为责任。
4.1 Paper Writing
人工智能辅助写作已从偶尔的辅助手段发展成为主流的研究实践。大规模语料库分析估计,高达 17.5% 的计算机科学摘要和 13.5% 的生物医学摘要中存在可检测到的人工智能修改痕迹,而研究人员自述的采用率更高:2025 年《自然》杂志的一项调查发现,超过一半的研究人员表示会寻求人工智能写作方面的帮助。尽管这些测量数据并不完美,但它们共同表明了一种明显的转变:人工智能写作辅助如今已融入日常科研工作流程。这使得人工智能辅助写作的质量、透明度和监管变得日益重要。
表 7(附录)提供了人工智能辅助写作系统的完整清单。
4.1.1 Semi-Automated Writing Assistance
半自动写作辅助工具支持稿件工作流程的各个环节,从规划和起草到润色和修改。在规划阶段,系统可以帮助生成标题、提纲、章节结构和引用建议。例如,ScholarCopilot 通过集成引用推荐功能训练 LLM 进行学术写作,这反映了将文本生成与文献基础相结合的工具的更广泛趋势。
在论文撰写过程中,Grammarly、Writefull、Paperpal 等商业工具以及基于 GPT 的编辑器支持段落生成、句子润色、引用插入和风格优化。开源提示模板提供了轻量级的替代方案,而 CoAuthor 则研究人机协作写作工作流程。主流范式正日益从“AI 为你写作”转向“AI 与你共同写作”:AI 负责处理机械或局部操作,例如润色、引用格式设置和初稿撰写,而研究人员则负责创新性、论证、实验结果解释和科学判断。
编辑器集成系统使这种协作更加明确。PaperDebugger 将多智能体系统嵌入 Overleaf,在写作环境中运行审阅者、增强者、评分者和研究员智能体。另一项研究则强调认知参与和透明度。Script&Shift 将人工智能辅助写作构建在源文件转换而非直接文本生成的基础上,旨在保留作者的积极推理。DraftMarks 提供修改强度和人工智能生成内容的视觉痕迹,使读者和审阅者能够更清晰地了解人机协作的写作过程。实证研究进一步表明,有目的的人工智能支持可以在不完全取代认知努力的情况下辅助学生写作。
论文写作后辅助系统侧重于修改、一致性和风格。XtraGPT 提供了一个开源的 LLM 套件,用于指导科学论文的修改;SciIG 使用近期发表的 NAACL 和 ICLR 论文对引言写作进行基准测试;OpenDraft 使用专门的代理程序生成带有引文支持的长篇研究草稿;LimAgents 则整合了 OpenReview 的评论和引文网络来生成研究局限性声明。这些系统共同表明,半自动写作辅助系统只有在增强研究人员的控制力而非取代他们构建、解释和论证论文的智力劳动时,才是最可靠的。
4.1.2 Fully Automated Paper Generation
全自动论文生成试图超越局部辅助,走向端到端的手稿生产。现有系统可以归为三个方向:
第一,端到端研究系统,如 The AI Scientist 和 Agent Laboratory,将完整论文生成作为更广泛的自动化研究流程的一部分。这些系统证明了生成完整、类似论文的产物是可行的,但其输出往往仍受限于论证浅显、实验验证薄弱或新颖性不足。
第二,经过基准测试的论文生成系统旨在接近人类评审标准。CycleResearcher 报告称,其生成论文在 ICLR 评分尺度上达到 5.36,接近但仍低于所报告的已接收论文平均分 5.69。这一差距很重要,因为它表明主要瓶颈不再仅仅是表层流畅性。相反,接近录用门槛的论文往往缺乏使可发表工作区别于貌似合理草稿的论证深度、实验严谨性和对审稿人关注点的预判。
第三,基于评分准则引导的系统和面向特定章节的系统,改进的是手稿的部分内容,而不是从零生成整篇论文。APRES 发现可预测引用次数的评分准则,并据此修改论文;人类专家在 79% 的情况下更偏好修改后的论文。FutureGen 面向“未来工作”章节生成。PaperWritingBench 作为 PaperOrchestra 框架的一部分被提出,提供了一个专门用于自动化论文写作的基准,通过将多智能体系统与逆向工程得到的顶级会议论文进行比较来评估其表现。这些系统表明,自动化写作正变得越来越可衡量,但同时也强调,高质量论文所需要的不只是流畅文本:它们还需要有证据支撑的推理和连贯的科学贡献。
4.1.3 Assessment: Writing Quality and AI Detection
AI 辅助写作的评估涉及两个相关但不同的问题:AI 使用是否能够被检测出来,以及由此产生的手稿在科学上是否足够有力。作为一种治理机制,检测仍然不可靠。当前检测器可能产生不可接受的假阳性,尤其是对于正式的、非母语者撰写的,或经过高度编辑的学术散文而言,这促使主要出版场所从试图检测 AI 使用,转向要求作者声明 AI 使用。水印在受控环境下提供了一条更有原则性的路径,但它需要模型提供方的合作,并且仍然容易受到改写、翻译和后期编辑的影响。
质量评估更重要,但也更困难。优秀的学术写作必须沿多个维度进行评估:事实正确性、引用准确性、论证连贯性、方法完整性、框架的新颖性以及文体适切性。LLM-as-Judge 框架正越来越多地被用于近似完成这一评估的部分内容。CycleReviewer 报告称,在分数预测方面,相对于单个人类审稿人,其 Proxy MAE 降低了 26.89%;而 Stanford Agentic Reviewer 达到的审稿分数相关性与人类评审者之间的一致性相当(ρ = 0.42,而人类 ρ = 0.41)。这些结果表明,自动化评估器可以提供有用的、类似审稿的信号,但不应将其视为专家评估的替代品:分数预测和一致性指标只能部分捕捉事实基础、证据严谨性、新颖性和科学贡献。
因此,AI 写作的核心失效模式并不是语法不通顺的文字,而是缺乏支撑的说服:文本流畅、结构良好、看似有引用,却没有充分建立在证据或科学判断之上。近期研究中观察到的生产力—质量分化进一步放大了这一问题:AI 使用可以提高发表产出,但语言复杂的 AI 辅助论文可能更不容易被接收 [93]。正如第 1 阶段(Creation)中所述,更多的产物生成并不必然意味着更强的研究。
4.1.4 Findings and Observations

4.2 Summary and Transition: Writing
这一阶段将重点从生产研究产物,转向把这些产物组织成学术论证。S5(Paper Writing) 接收第 1 阶段的输出,包括想法、检索到的文献、实验、图表和表格,并将其转化为一篇手稿,说明做了什么、为什么重要,以及证据如何支持相关主张。这一阶段的进展表明,AI 系统在辅助写作流程方面正变得越来越有效,涵盖从规划、起草到润色、引用支持、修订,甚至整篇论文生成。
核心限制在于,流畅的写作可能掩盖薄弱的推理。AI 生成或 AI 辅助的文本可能提升可读性和生产力,却仍未解决更深层的科学要求:主张是否有充分依据,引用是否忠实地支持这些主张,实验是否充分,以及贡献是否以适当的细致程度得到论证。这一限制既出现在半自动化写作辅助中,也出现在全自动论文生成中。前者在保留研究者对框架设定、解释和最终责任的控制时最具可信度;后者在特定场景中正越来越接近可评审的质量,但仍然在论证深度、证据严谨性和对审稿人关注点的预判方面面临困难。
这一阶段的产出是一篇准备接受外部审查的手稿。因此,我们接下来转向第 3 阶段(Validation),在该阶段,手稿通过同行评审进行评估,并通过作者 rebuttal 进行修订。这一转变使 AI 的角色从将证据组织成连贯论证,转向评估该论证是否可靠、公正且得到充分支持。
5.Phase 3: Validation
6.Phase 4: Dissemination

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)