为什么 temperature=0,模型输出依然不完全一致?

很多人会觉得:
temperature 设成 0,结果应该绝对稳定才对。
因为从数学上看,逻辑似乎很简单。
当 temperature 趋近于 0 时,概率分布会迅速向最大值集中,最终接近一个 One-Hot 分布:最高概率的 token 概率接近 1,其余 token 接近 0。
理论上,这时候不再需要随机采样,而是直接选择分数最高的 token,也就是:
谁最大,就选谁。
既然最大值是确定的,那么输出自然也应该是固定的。
但问题在于:
数学世界是理想化的,而模型推理发生在真实硬件上。

大模型真正运行时,底层依赖的是 GPU 的并行计算架构,而不是一台计算器按顺序一步一步算。
GPU 为了追求吞吐量,会把大量运算同时展开。
比如一串数值求和,它往往不是严格按固定顺序相加,而是拆成多个部分并行计算,再汇总结果。
看起来只是执行顺序不同,但这里会引出一个关键问题:浮点数计算并不严格满足结合律。
在数学里:(a+b)+c 与 a+(b+c)结果一定完全一致。
但在计算机里,尤其是 FP16、BF16 这样的半精度计算中,由于精度截断和舍入误差:同样一组数字,不同计算顺序,最后结果可能会出现极小偏差。
这种偏差通常小到几乎无法察觉,但对于大模型来说,有时候已经足够改变最终输出。
因为模型最后预测 token 时,会得到一整个词表的 logits 分数。
而词表规模往往有几万甚至几十万个 token。
很多情况下,Top-1 和 Top-2 的分数差距极其接近。
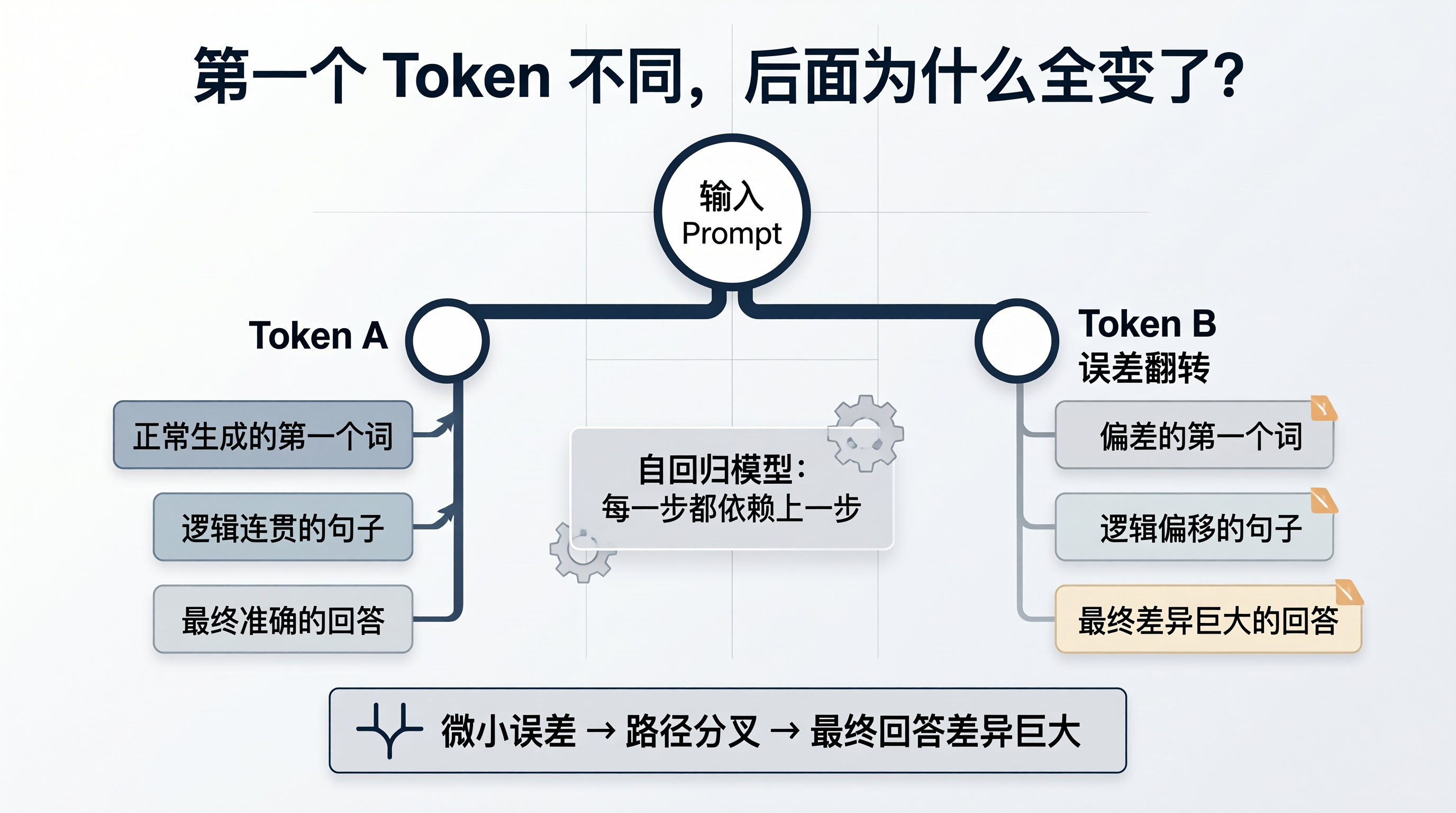
例如:Token A=10.55555,Token B=10.55554。
正常情况下,A 排第一。
但如果因为 GPU 并行计算、低精度累积误差,导致某一步出现微小抖动,使得Token A=10.55553,Token B=10.55556,那么排名就可能直接翻转。
虽然变化微乎其微,但对于自回归模型来说,第一个 token 一旦不同,后续生成路径就会迅速分叉。
于是你看到的现象就是temperature 已经设为 0,输出仍然偶尔不一致。
那该怎么提高稳定性?
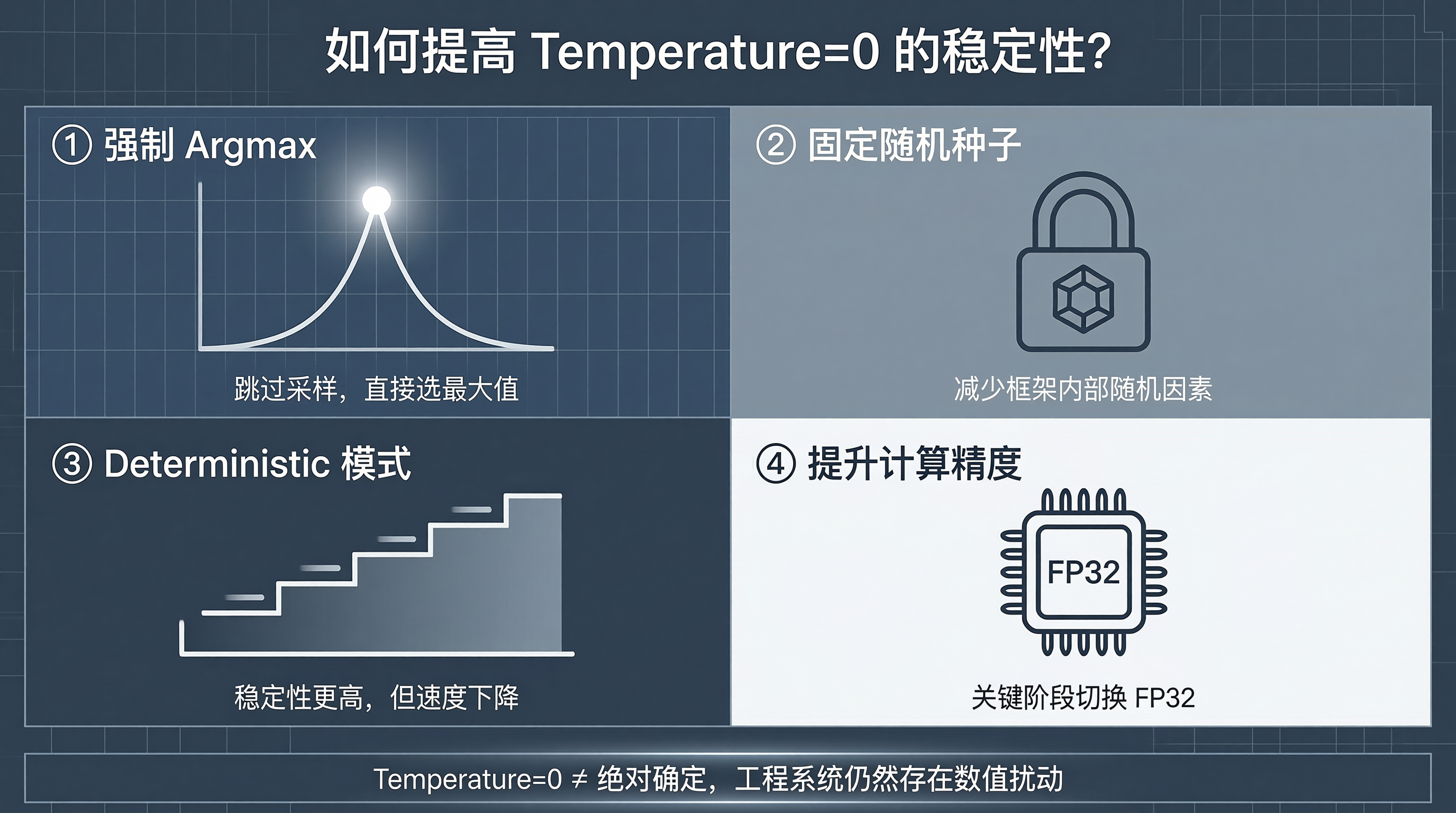
1. 直接使用 Argmax
这是最直接、也最有效的方法。
如果 temperature=0,就不要再经过 sampling 逻辑,而是直接取 logits 最大值。
也就是跳过随机采样,强制选择 Top-1。
这样可以减少一部分实现层面的不确定性。
2. 固定随机种子
一些推理框架内部,可能仍然存在随机逻辑。
例如:
- 某些层没有完全关闭随机机制
- Tie(分数相同)时采用随机选择
- 底层实现依赖随机状态
因此固定 seed,可以显著提高复现能力。
但需要注意,固定 seed ≠ 绝对确定。
因为硬件层面的非确定性依然可能存在。
3. 开启确定性模式(Deterministic Mode)
主流框架通常会提供 deterministic 模式。
本质上就是牺牲一部分性能,换取更稳定的结果。
它会尽量避免某些并行乱序计算方式,优先使用可复现的计算路径。
代价是推理速度可能下降。
所以是否开启,需要看业务更重视性能还是稳定性。
4. 提高计算精度
既然误差来自低精度计算,那么一种思路就是在关键计算阶段提高精度。
例如,中间过程使用 FP16/BF16,最后一层 logits 计算切换到 FP32,这样能减少数值误差带来的排序抖动。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)