4-多目标跟踪的轨迹长尾分布研究(DelvingintotheTrajectoryLong-tailDistributionforMuti-objectTracking)
摘要
多目标跟踪(MOT)是计算机视觉中的一个关键领域, 具有广泛的实际实现。目前的研究主要集中在跟踪算法的开发和后处理技术的增强上。然而,关于跟踪数据 本身的性质,一直缺乏彻底的检查。在这项研究中,我们对跟踪数据的分布模式进行了探索,并在现有的MOT 数据集中发现了一个明显的长尾分布问题。我们注意到 不同行人的轨迹长度分布存在显著的不平衡,我们将这 种现象称为“行人轨迹长尾分布”。为了应对这一挑战, 我们引入了一种定制策略,旨在减轻这种倾斜分布的影 响。具体来说,我们提出了两种数据增强策略,包括静止 相机视图数据增强(SVA)和动态相机视图数据增强 (DVA),它们针对视点状态和用于重id的Group Softmax (GS)模块而设计。SVA是回溯和预测尾类行人轨迹,DVA 是利用扩散模型改变场景背景。GS将行人划分为不相 关的组,对每组分别执行softmax操作。我们提出的策略 可以集成到众多现有的跟踪系统中,大量的实验验证了 我们的方法在减少长尾分布对多目标跟踪性能的影响 方 面 的 有 效 性 。
本工作的主要贡献如下:
1. 我们第一个发现了多目标跟踪中的长尾分布问题, 并指出这个问题是由于不同行人的帧数不平衡造成的。
2. 从信息增强的角度出发,提出了SVA和DVA两种数据增强策略。SVA用于回溯和预测尾类行人轨迹,DVA用于改变场景背景。另外,从模块改进的角度对GS模块进行了设计。GS将不同身份的行人划分为不相关的组,对每组分别执行softmax操作。
3. 我们将该方法应用于两种SOTA联合检测与跟踪算法,并在MOTChallenge数据集上进行了评估。评估结果显示了稳健的性能改进,作为对我们方法有效性的令人信服的验证。
1、代码和数据集
1.1 论文代码:
https://github.com/chensi-jia/ Trajectory-Long-tail-Distribution-for-MOT
1.2 数据集
数据集:我们在四个公共MOT基准上进行了广泛的实验, 即 MOT15 [27], MOT16 [34], MOT17[34] 和 MOT20 [12]。其中,MOT15包含22个序列,其中11个用于训练, 11个用于测试,共11286帧。MOT16包含14个序列,7 个用于训练,7个用于测试,共11235帧。与MOT16相 比,MOT17增加了DPM、SDP、Faster-RCNN三种检测 器的检测边界盒。MOT20包含8个在拥挤场景中捕获的 序列,4个用于训练,另外4个用于测试,其中包括 13410帧。在一些帧中,同时包含200多个行人。
评估指标:为了进行评估,我们使用CLEAR指标[4],包 括多目标跟踪精度(MOTA), IDF1分数(IDF1),高阶跟 踪精度(HOTA),大多数跟踪率(MT),大多数丢失率 (ML)和身份转换(IDS)。MOTA、IDF1和HOTA是三个 重要的综合指标。MOTA关注的是检测性能,IDF1关 注的是关联性能。与它们相比,HOTA平衡了检测性能 和关联性能。
2、要解决的问题
长尾分布数据集有一个共同的问题:在长尾分布数 据上训练的网络往往会导致对与流行的头类相关的学习特征的偏向,而忽略了这些特征。在代表性较少的尾部类中。目前,改善长尾分布的问题可以分为三个方面:类别重新平衡、信息增强和模块改进。在摄像头采集到的图像数据中,有些人在图像中停留的时间较长,有些人在图像中移动的比较匆忙。 由于数据本身的原因,网络会对匆匆走过的人的特征学习较少。对于目前多目标跟踪器的重id分支,大多将重id作为分类问题,使用softmax模块计算分类概率。 但是,softmax模块有一个巨大的缺陷:权值大的类权重变大,权值小的类权重变小,这将加剧长尾分布数据 上的长尾分布效应。因此,为了改善这个问题,我们从两个关键的角度提出我们的解决方案:信息增强和模块改进。
多目标跟踪。我们回顾了三种主要的多目标跟踪框架: 检测跟踪,联合检测与跟踪以及基于变压器的跟踪。 检测跟踪主要由两个主要部分组成。在检测阶段,建立检测器来定位感兴趣的对象。在关联阶段,早期的方法使用运动预测器来预测下一帧中物体的位置,并依靠位置信息跨连续帧将物体关联起 来。联合检测与跟踪,一个统一的网络同时产生检测结果和相应的被检测对象的外观特征。随后,使用关联方法在连续帧之间链接对象。基于变压器的跟踪使用变压器将检测查询与从前一帧预测中派生的查询结合起来,以检测和跟踪当前帧中的对象。这种方法消除了对后处理 步骤的需要,实现了端到端的多目标跟踪。
3、提出的创新点
从信息增强的角度出发,我们根据摄像机的运动状态,将摄像机数据分为静止摄像机视图数据和动态摄像机视图数据两类。对于静止相机视图数据,我们提出了静止相机视图数据增强(SVA)策略,该策略包括回溯延续和预测延续两种技术。将回溯延拓应用于训练序列数据中间帧的尾部类行人,而对训练序列数据最后一帧的尾部类行人采用预测延拓。这种策略可以促进网络对尾类行人轨迹的学习。针对动态摄像机视图数据,提出了动态相机视图数据增强(DVA)策略。该策略利用扩散模型对场景背景进行风格变换,提高了网络对行人区域特征的关注程度。
在模块增强方面,我们设计了Group Softmax (GS) 模块。GS算法将训练样本数量相近的行人分组在一起, 然后分别计算每组的softmax和交叉熵损失,避免了头部类权重对尾部类的显著抑制,提高了网络提取尾部类外观特征的能力。
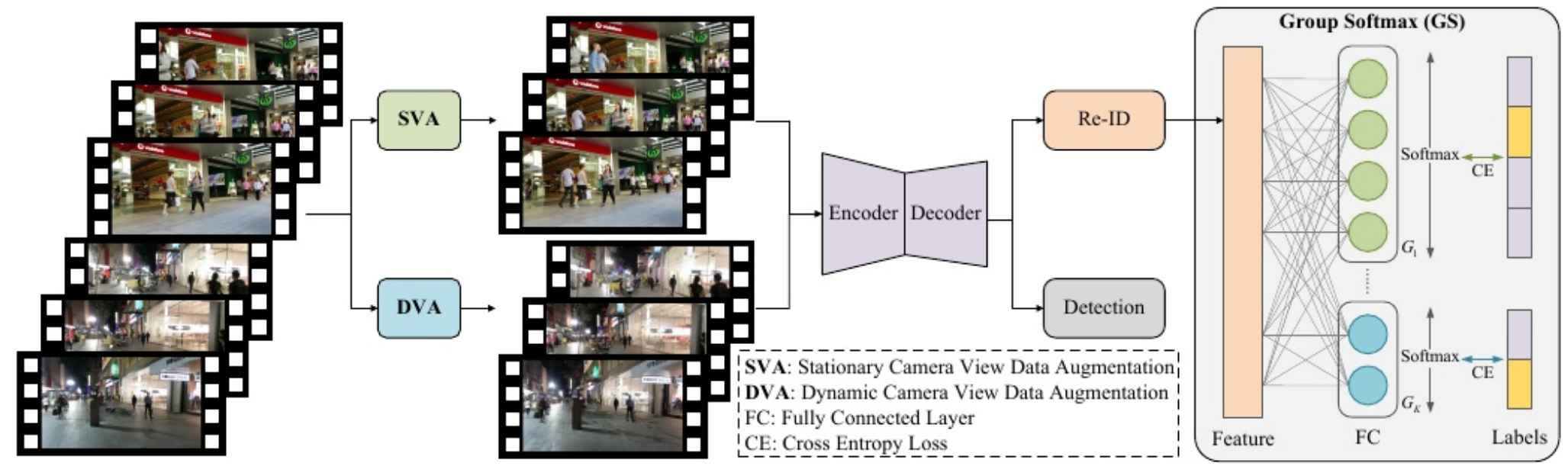
图2。我们战略的整体流水线。我们的策略包括三个模块:(1)SVA:回溯和预测尾部类别的行人轨迹。(2) DVA:利用扩散模型改变场景背景。(3) GS: 将不同身份的行人划分为不相关的组,分别对每组进行softmax操作。
3.1 概述
在这项工作中,我们选择了联合检测与跟踪框架的多目标跟踪算法来执行我们的策略,如图2所示。 从数据角度出发,我们提出了两种定制的数据增强方法,分别是针对视点状态设计的静止相机视图数据增强(Stationary Camera View data augmentation, SVA) 和动态相机视图数据增强(Dynamic Camera View data augmentation, DVA),用于模拟尾类行人的运动轨迹并改变背景样式。此外,我们从解决关联中使用的相似性度量Re-ID开始,并提出Group Softmax (GS)模块来提高尾部类行人的外观识别性能。
3.2 相机视图数据增强
我们针对静止摄像机和动态摄像机采集的数据 开发了定制化的数据增强方法。 具体而言,我们定义了如Eq.(1)所示的类别划分 计算公式。然后,我们使用Eq.(1)将数据集中每个序 列中的行人类别划分为头类和尾类。
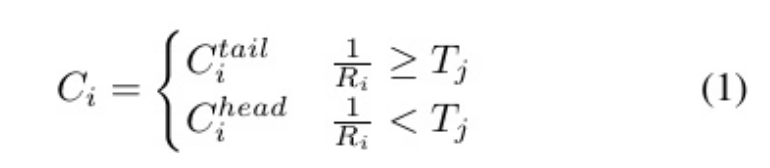
其中表示类别 i 所属的类别,
表示类别 i 的数量与 j 序列中所有类别的数量之比,
表示j序列中用于确定类别是否为尾部的类阈值。
3.2.1 静止相机视图数据增强
对于固定相机捕获的多目标跟踪数据,目前有常用的数据增强方法,如图像颜色变换、图像混合和图像裁剪。虽然这些方法可以应用,但它们并不是专门针对多目标跟踪任务而设计的,缺乏针对跟踪目标的定制设计。
因此,我们提出了一种针对该问题的静止相机视图数据增强(SVA)策略对固定摄像机捕获的数据进行多目标跟踪,重点关注尾部类行人的数量增强。SVA策略包括回溯延拓和预测延拓,如图3所示。回溯延续是在原始轨迹结 束后的后续帧中加入反向的原始轨迹,应用于训练 序列数据中间帧中尾部类的行人。预测延续是将利用原始轨迹的位置信息预测的未来轨迹添加到原始 轨迹开始时的前一帧中,用于训练序列数据最后一 帧中的尾部类行人。
回溯延续。对于一个总共帧的训练视频,如果尾部类的行人轨迹在第m帧出现,在第n帧消失,则 满足条件n <
,我们采用分段任意模型(Segment Anything Model, SAM)算法,从第m帧到第n帧分割出现在帧中的行人图像区域,然后将这些图像区域以相反的顺序叠加到第n帧之后的帧上。回溯延拓 可以表述为:
![]()
其中表示训练数据中第k个行人在第j帧的回溯图 像位置,
表示训练数据中第k个行人在第i帧的图 像位置,
为训练数据中回溯延续截止帧,其值 为
和(2n−m)的最小值。
预测延续。对于一个总共帧的训练视频,如果尾类的行人轨迹出现在最后一帧,我们将从第m帧 到
-th帧出现的行人的x和y图像坐标输入到卡尔曼滤波器中,以预测行人随后的x和y图像坐标;同时确保预测的图像坐标落在图像尺寸范围内。在该行人轨迹中,我们随机选择能见度不小于能见度阈值
的行人,其中0≤
≤1,使用SAM算法对行人进行分割。根据从预测图像坐标中随机选择的预测x和y图像坐标,将分割后的图像区域叠加在行人轨迹出现前的帧上。预测延拓可以表述为:
![]()
其中表示卡尔曼滤波器预测训练数据中第k个行人在第j帧的图像位置,R()表示随机选择图像位置的 thefunction;
表示卡尔曼滤波器利用训练数据中 第i个行人从第m帧到
的图像坐标预测的图像位 置,Pik表示训练数据中第k个行人在第i帧的图像位 置。
是在训练数据集中应用预测延拓的起始帧, 其值为1和(2m−
)的最大值。
3.2.2 动态相机视图数据增强
由于动态相机捕获的数据具有显著的场景和主体尺寸变化的特点,传统的数据增强方法难以适应这些变化。
为了解决这个问题,我们提出了动态相机视图数据增强(DVA)策略,如图4所示。该策略包括四个主要步骤:图像分割、图像补绘、图像扩散和图像合并。该策略针对动态摄像机视角的输入,首先使用图像分割算法SAM[26]对序列导出的输入图像中的行人进行分离,得到去除行人的图像、带有行人遮挡的图像和仅包含行人区域的图像。接下来, 应用图像补绘算法Navier-Stokes[5]对去除了行人的 图像进行修复,生成修复后的图像。在此之后,使用稳定扩散[36]对修复后的图像进行处理,得到扩散 图像。最后,将前面分割步骤得到的带有行人蒙版的图像和只包含行人区域的图像与扩散图像合并, 生成输出图像。
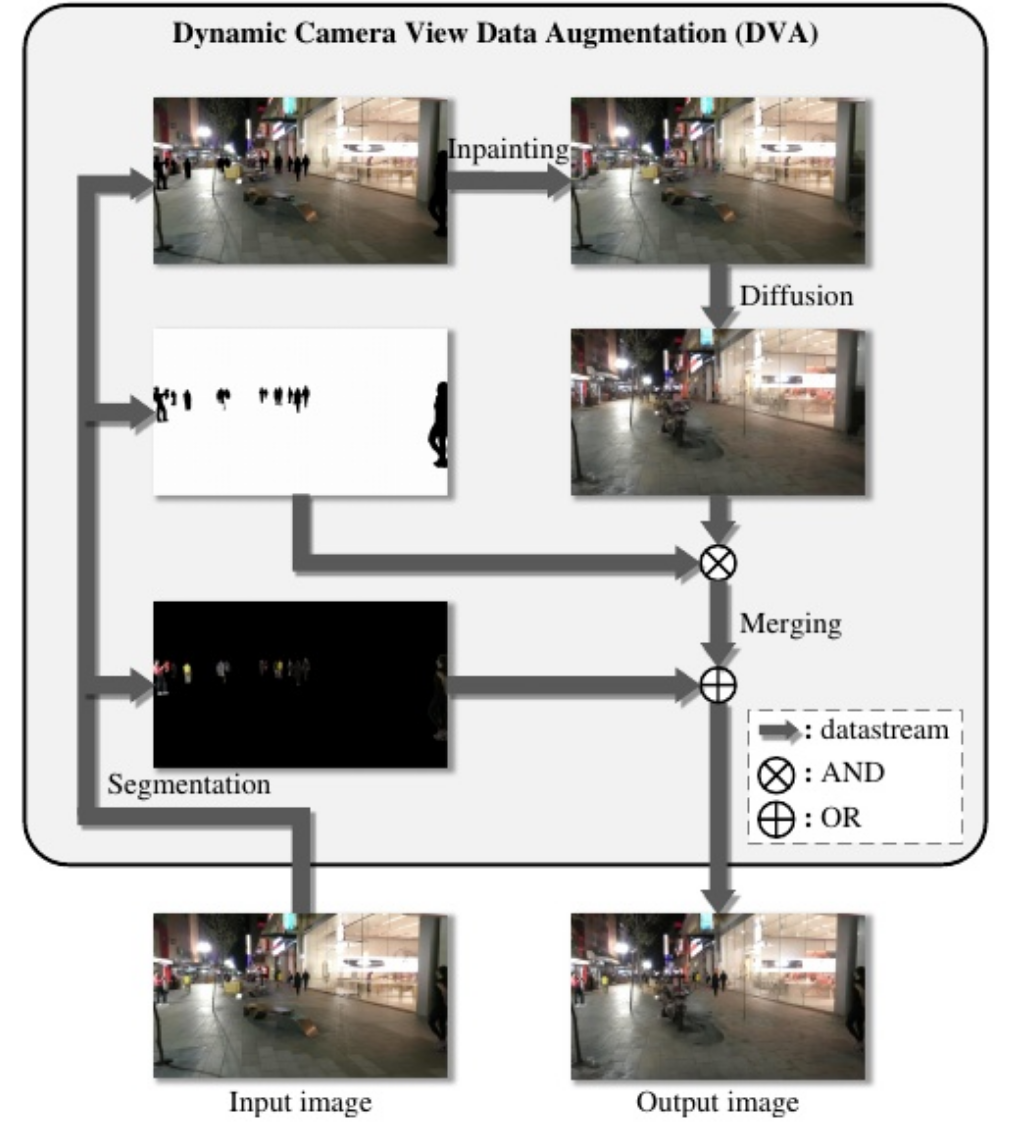
图4.动态摄像机视图数据增强(DVA)的说明。
图像分割。考虑到多目标跟踪数据集提供了边界框注释,但缺乏行人的掩码标签,我们利用图像及其相应的行人边界框标签作为SAM在图像中分割行人的输入。
Image Inpainting。在本文中,用于图像补绘的算法是 基于Navier-Stokes方程[5]。该算法旨在从待修补区域的边缘开始修复图像,沿等高线传播图像平滑度,在所有信息传播完毕后获得修复后的图像。
图像扩散。稳定扩散是潜扩散模型(Latent Diffusion Model, LDM)的一种,潜扩散模型是一类能够生成新图像的去噪扩散概率模型。原则上,稳定扩散可以 模拟条件分布。这可以通过输入文本、语义映射或其他图像到图像转换任务信息来控制条件去噪自编码器来实现。在本文中,我们利用输入图像通过调整提示和增强系数来生成新图像。
图像合并。我们在带有行人掩模的图像和扩散图像之间进行位与运算,有效地将扩散图像中对应原始行人区域的像素值设置为0,同时保持行人区域外区域的像素值不变。这就得到了后处理后的漫反射图像。然后, 我们在后处理的扩散图像和只包含行人的图像之间执 行逐位或操作。实际上,这个操作涉及到将扩散图像中对应于原始行人区域的像素值设置为来自只包含行人的图像的相应像素 值,从而得到输出图像。
在来自扩散模型的增强数据上训练模型,往往会 有过度强调虚假品质[1]的风险。通用的解决方案为原 始数据和增强数据分配不同的采样概率,以管理不平 衡[23]。我们采用类似的方法来平衡原始图像和增强图 像从DVA。数学上,该方法可以表述为:
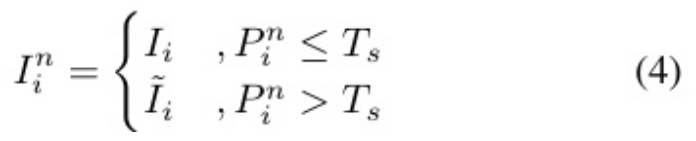
其中表示索引I在第n个epoch的图像,
表示索引I的原始图像,
表示索引I的增强图像,
表示索引I在 第n个epoch调用原始图像的概率,Ts表示每次图像选择调用原始图像的图像选择阈值。给定索引i,以Ts的 概率将原始图像Ii添加到第n个epoch中,否则将其增广图像
添加。
3.3. 组Softmax模块
我们观察到Re-ID对不同数量的行人类别有不同程度的特征学习的问题。对于数量较多的类别(头部类别), 它往往表现得更好,而对于数量较少的类别(尾部类别), 它的效率较低,这可能会对Re-ID的性能产生负面影响。
为了解决这个问题,我们提出了组Softmax (GS)模块, 如图2所示。GS将行人类别划分为几个不相交的组, 并对每组分别进行softmax操作。这样,数量相近的行 人类别就可以在同一组中竞争。因此,GS可以隔离数 量差异显著的类别,防止尾部类别的权重受到头部类 别的严重抑制。
具体来说,我们将训练数据集中的M个行人类的总数根据其在训练数据集中的数量划分为K个不同的 组,划分组的规则公式为:≤N(i)≤
,其中 i 的值为 1 ~ M, j 的值为1 ~ K, N(i)为训练数据集中第i个行人类 别的数量,
为第j个组的最低数量阈值,
为第j个组的最高数量阈值,M表示行人类别的数量,K为组数。
为了确保每个行人类别只分配给一组并保持有序 的组,我们指定j + 1组的最低数量阈值等于第j组的最 高数量阈值,即=
。为了便于分组,我们提出 Tjh的集合规则公式如下:
![]()
其中为第j个分组的最高数量阈值,j为分组的指数。
此外,我们分别对每个组应用softmax处理,并利 用Cross-Entropy Loss来计算组损失。然后,将组损均 值计算为Re-ID损失,公式如下:
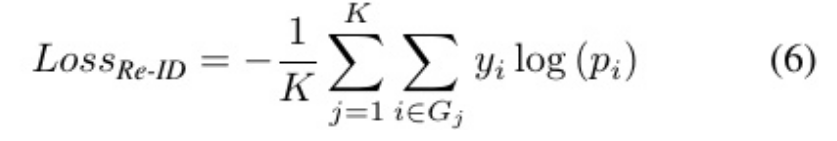
式中表示Re-ID损失,K表示组数,j表示组索 引,Gj表示第j组,yi表示Gj中的标签,pi表示Gj中的概率。
4、结论与不足
在本研究中,我们注意到不同行人的轨迹长度分 布存在显著的不平衡,揭示了现有MOT数据集中的长 尾分布问题。为了解决这个问题,我们提出了我们的 方法,该方法侧重于两个关键方面:信息增强和模块改 进。具体来说,我们介绍了针对视点状态定制的两种 数据增强方法,包括SVA和DVA,以及用于Re-ID的 GS模块。值得注意的是,我们的工作代表了在MOT 领域解决长尾分布的开创性努力。使用两个SOTA多 目标跟踪器,我们已经在MOTChallenge基准测试中验 证了我们的方法的有效性。实验结果表明,该方法有 效地缓解了长尾分布对MOT的影响。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)