家里的合同、发票、保单别再乱放了:用 paperless-ngx 搭一个私人档案馆
 家里最容易失控的东西,不一定是照片,也不一定是文件夹。很多时候,是这些纸:购房合同、保险单、体检报告、车辆保养单、电子发票、保修卡、孩子证书、银行账单、物业通知。它们平时不重要,真正要用的时候却很急。翻抽屉、找文件袋、问家人“你记不记得放哪了”,最后往往变成一场家庭级搜索灾难。
家里最容易失控的东西,不一定是照片,也不一定是文件夹。很多时候,是这些纸:购房合同、保险单、体检报告、车辆保养单、电子发票、保修卡、孩子证书、银行账单、物业通知。它们平时不重要,真正要用的时候却很急。翻抽屉、找文件袋、问家人“你记不记得放哪了”,最后往往变成一场家庭级搜索灾难。
今天介绍的开源项目 paperless-ngx,就是为这个问题准备的。
它可以把纸质资料、PDF、图片、邮件附件统一收进一个系统里,自动 OCR 识别文字,自动打标签,最后变成一个可以全文搜索的私人档案馆。
项目小卡片:
项目名称:paperless-ngx
项目定位:开源文档管理系统,适合扫描、索引、归档文档
适合场景:家庭档案、小团队票据、合同资料、发票归档
推荐部署:NAS / 小主机 / 软路由 / 家庭服务器
当前稳定版:v2.20.15,发布于 2026-04-27
项目热度:GitHub 约 41.9k stars
它解决的不是“存文件”,而是“找到文件”
很多人会把资料放到网盘、NAS 或电脑文件夹里。
这当然比纸堆好,但还是有三个问题:
第一,文件名经常不规范。
IMG_20260401.jpg
scan_001.pdf
合同最终版2.pdf
发票新.pdf
第二,PDF 和图片里面的文字搜不到。
第三,纸质原件和电子版本对不上。系统里有扫描件,柜子里还有原件。真正要拿原件时,还是不知道在哪个文件袋。
paperless-ngx 的价值在于:
它让文档进入系统后,不只是被保存,而是被识别、分类、检索和关联。
它长什么样?
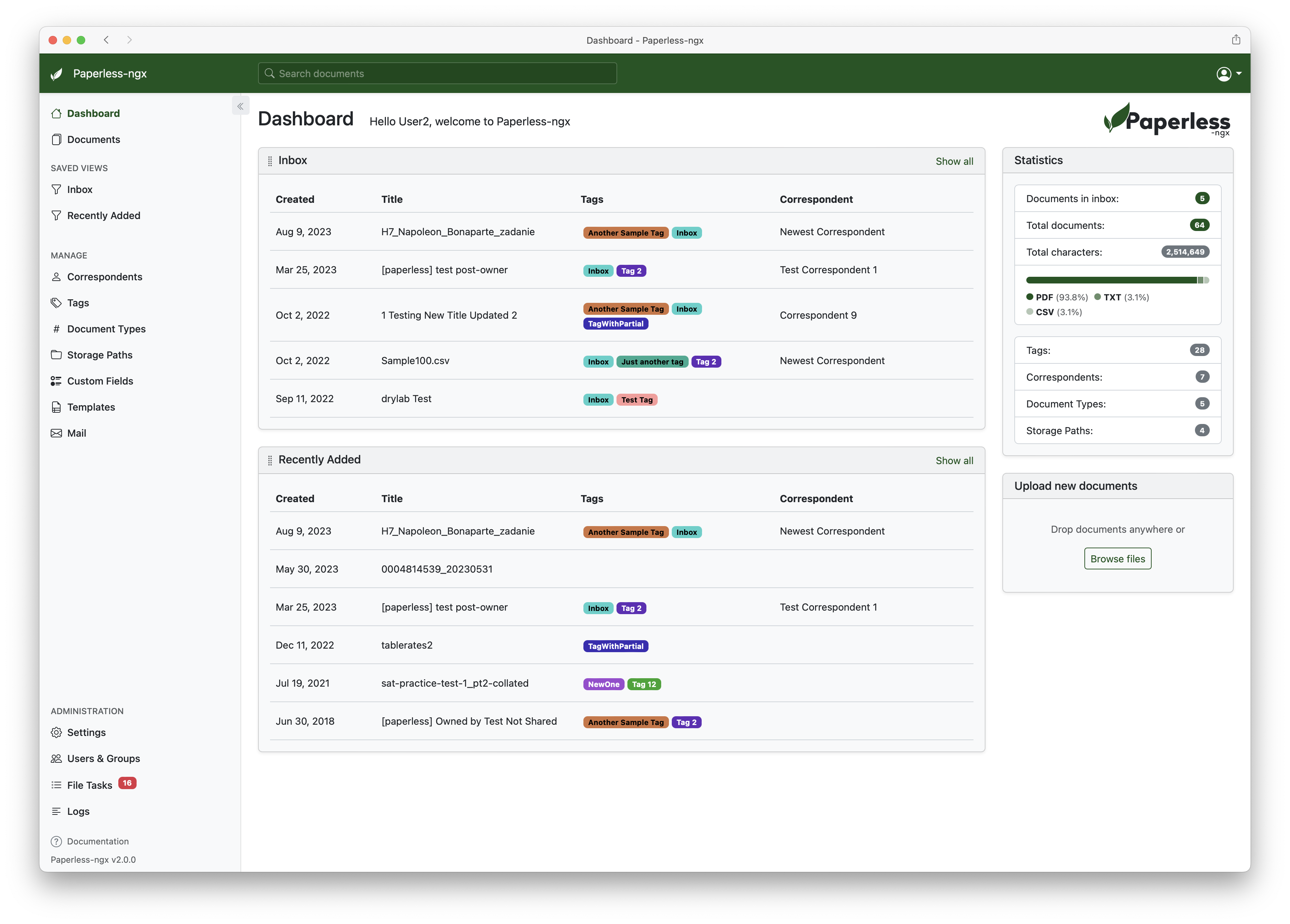
官方界面很接近一个“文档工作台”。

你可以用列表、卡片等方式浏览文档。
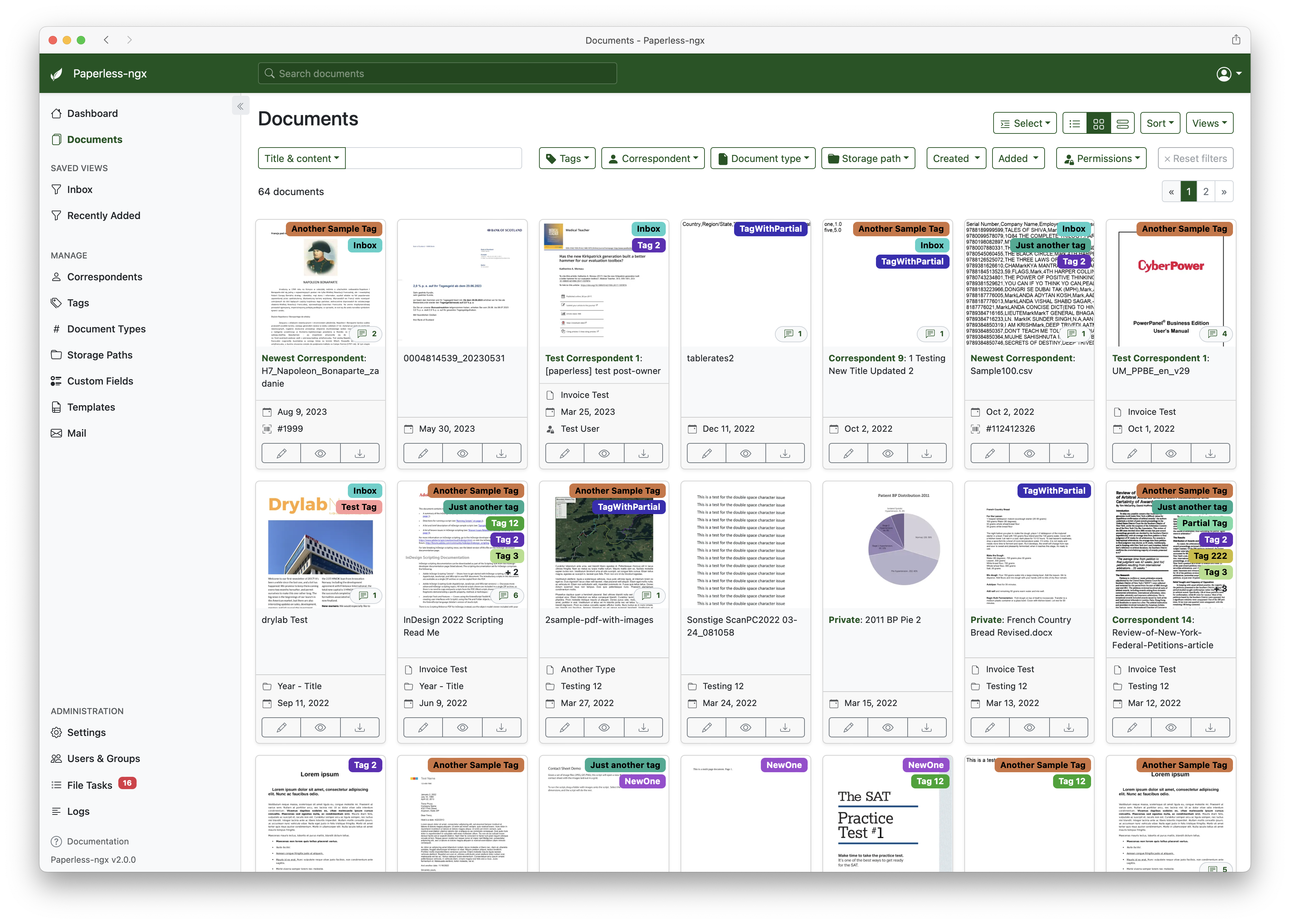
也可以直接全文搜索。OCR 识别后的内容、标题、标签、往来方、文档类型都能参与搜索。
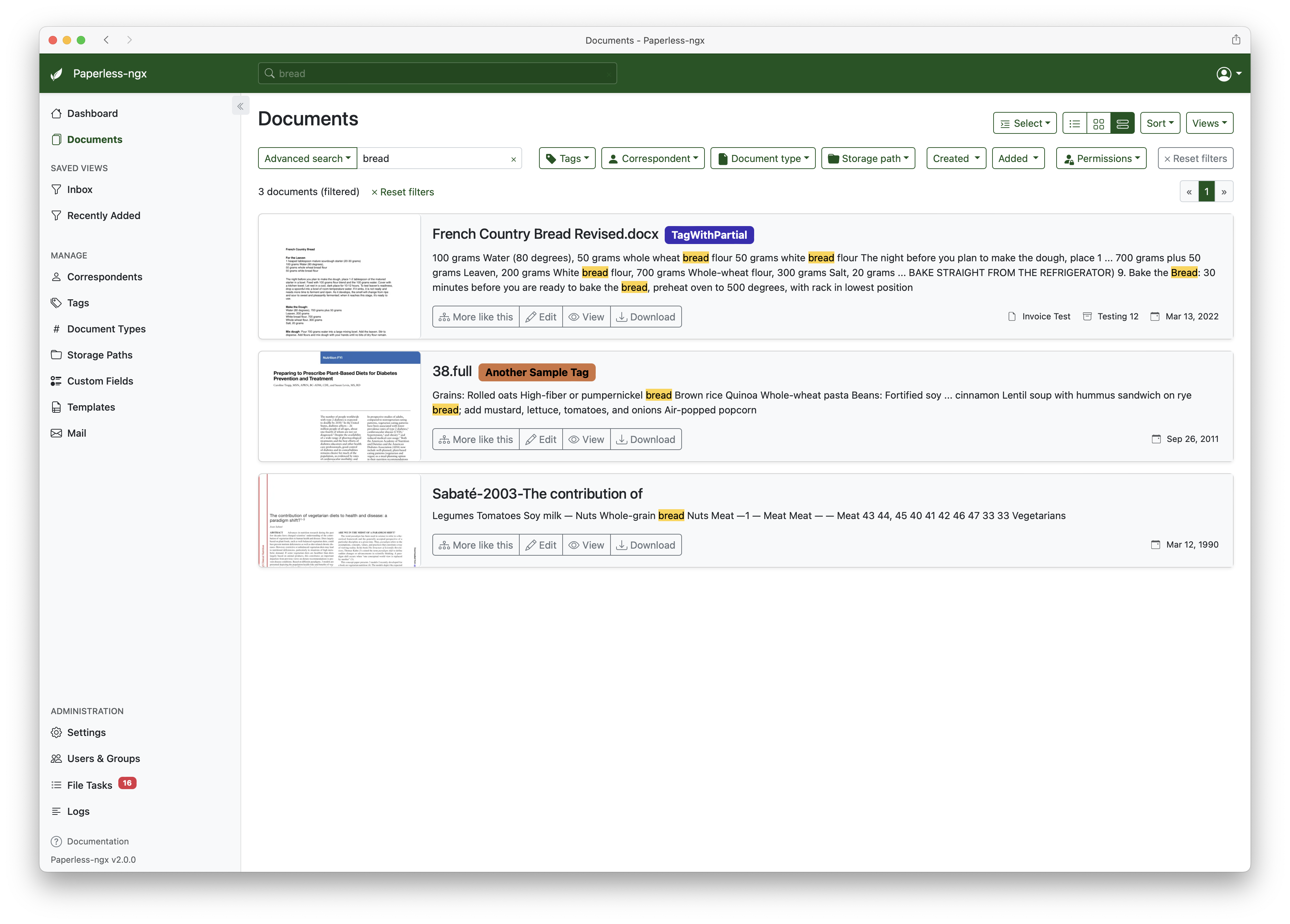
最适合家庭的资料类型
建议优先把这些资料放进去:
| 类别 | 示例 | 建议标签 |
|---|---|---|
| 保险 | 医疗险、车险、寿险、保单批单 | 保险、家庭成员名、到期提醒 |
| 房产 | 房本、租赁合同、物业合同、装修资料 | 房产、合同 |
| 汽车 | 行驶证、保养单、维修单、保险单 | 汽车、保养、保险 |
| 发票票据 | 电子发票、报销单、收据 | 发票、报销 |
| 医疗 | 体检报告、病历、处方、检查单 | 医疗、体检 |
| 证书 | 学历、资格证、获奖证书 | 证书 |
| 设备 | 说明书、保修卡、维修记录 | 家电、说明书、保修 |
不建议一开始就把所有历史资料全倒进去。先选一个小范围,比如“保险 + 合同 + 发票”,跑通流程后再扩展。
推荐部署方式:Docker Compose
如果你有 NAS、小主机、软路由,推荐用 Docker Compose。
新建目录:
mkdir -p paperless-ngx/{data,media,export,consume}
cd paperless-ngx
创建 docker-compose.yml:
services:
broker:
image: redis:7
restart: unless-stopped
db:
image: postgres:16
restart: unless-stopped
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: paperless
volumes:
- ./pgdata:/var/lib/postgresql/data
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
restart: unless-stopped
depends_on:
- db
- broker
ports:
- "8000:8000"
volumes:
- ./data:/usr/src/paperless/data
- ./media:/usr/src/paperless/media
- ./export:/usr/src/paperless/export
- ./consume:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_DBNAME: paperless
PAPERLESS_DBUSER: paperless
PAPERLESS_DBPASS: paperless
PAPERLESS_SECRET_KEY: change-me-to-a-long-random-string
PAPERLESS_TIME_ZONE: Asia/Shanghai
PAPERLESS_OCR_LANGUAGE: chi_sim+eng
PAPERLESS_URL: http://你的服务器IP:8000
启动:
docker compose up -d
创建管理员账号:
docker compose run --rm webserver createsuperuser
然后打开:
http://你的服务器IP:8000
第一次部署建议先在局域网内使用,不要急着暴露到公网。如果确实需要外网访问,至少要配好反向代理、HTTPS、强密码、备份和访问控制。
最核心的入口:consume 文件夹
上面的 Compose 里,我们映射了这个目录:
./consume -> /usr/src/paperless/consume
以后你只需要把 PDF、图片、扫描件放进本地的 consume 文件夹,系统就会自动处理:
- 发现新文件;
- OCR 识别文字;
- 生成缩略图;
- 建立全文索引;
- 根据规则匹配标签、文档类型、往来方;
- 移入正式归档目录。
官方推荐工作流大概就是这个思路:
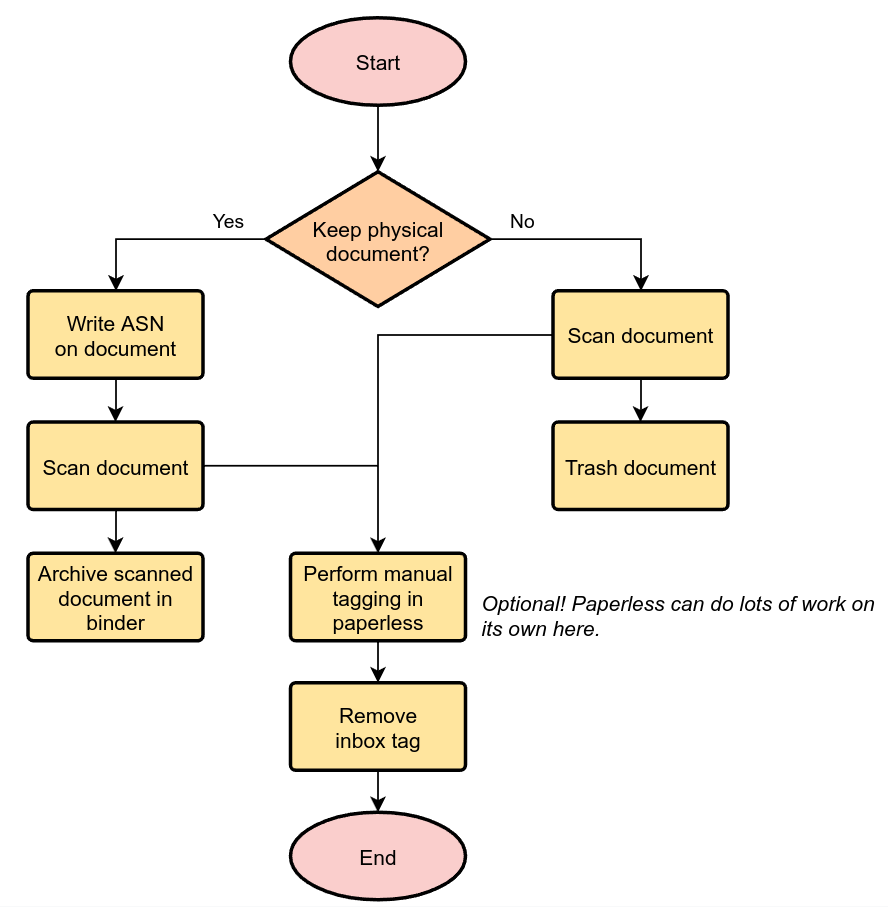
实际家庭用法可以更简单:
手机拍照 / 扫描仪扫描
↓
丢到 consume 文件夹
↓
paperless-ngx 自动 OCR
↓
检查标签和文档类型
↓
需要保留原件的,贴编号后放入文件盒
玩法一:建立一套“家庭标签体系”
很多人第一次用文档管理系统,会想建很多文件夹。
paperless-ngx 更适合用标签。
原因很简单:一份文档可以同时属于多个标签。
比如一张车险保单,可以同时打:
汽车
保险
2026
到期提醒
如果用传统文件夹,它只能放在一个地方;用标签,它可以从多个角度被找到。
家庭用户可以先用这套简单标签:
保险
合同
发票
医疗
房产
汽车
家电
证书
孩子
父母
待处理
需保留原件
标签体系越复杂,越容易半途而废。先少后多,才是长期可用的做法。
玩法二:用“文档类型”管理资料性质
标签解决“主题”,文档类型解决“这是什么东西”。
可以这样设置:
合同
发票
保单
说明书
体检报告
证书
账单
收据
通知
以后搜索时就很方便:
type:发票 家电
type:合同 装修
type:保单 车险
你也可以直接用中文关键词搜 OCR 内容,比如:
免赔额
保修期
租赁期限
发动机号
纳税人识别号
这才是它比普通文件夹强的地方。
玩法三:给纸质原件做 ASN 编号
很多家庭资料不能只留电子版。
比如房产材料、保险合同原件、医疗重要报告、车辆登记材料、盖章合同、证书原件。
这时可以用 paperless-ngx 的 ASN,也就是 archive serial number,给原件编号。
一个简单做法:
BX-0001 医疗险保单
CAR-0001 车险保单
HOME-0001 租房合同
MED-0001 体检报告
流程是:
- 扫描原件;
- 上传到 paperless-ngx;
- 在文档里填写 ASN;
- 给纸质文件贴同样编号;
- 原件放入对应文件盒。
以后系统里搜到文档,就能知道原件在哪。这比“我记得放在某个抽屉”可靠多了。
玩法四:邮件附件自动归档
paperless-ngx 可以从邮箱里自动抓附件。
这个功能特别适合电子发票、银行账单、保险通知、订单凭证、公司报销材料、各种 PDF 通知。
官方界面里可以配置邮件规则:
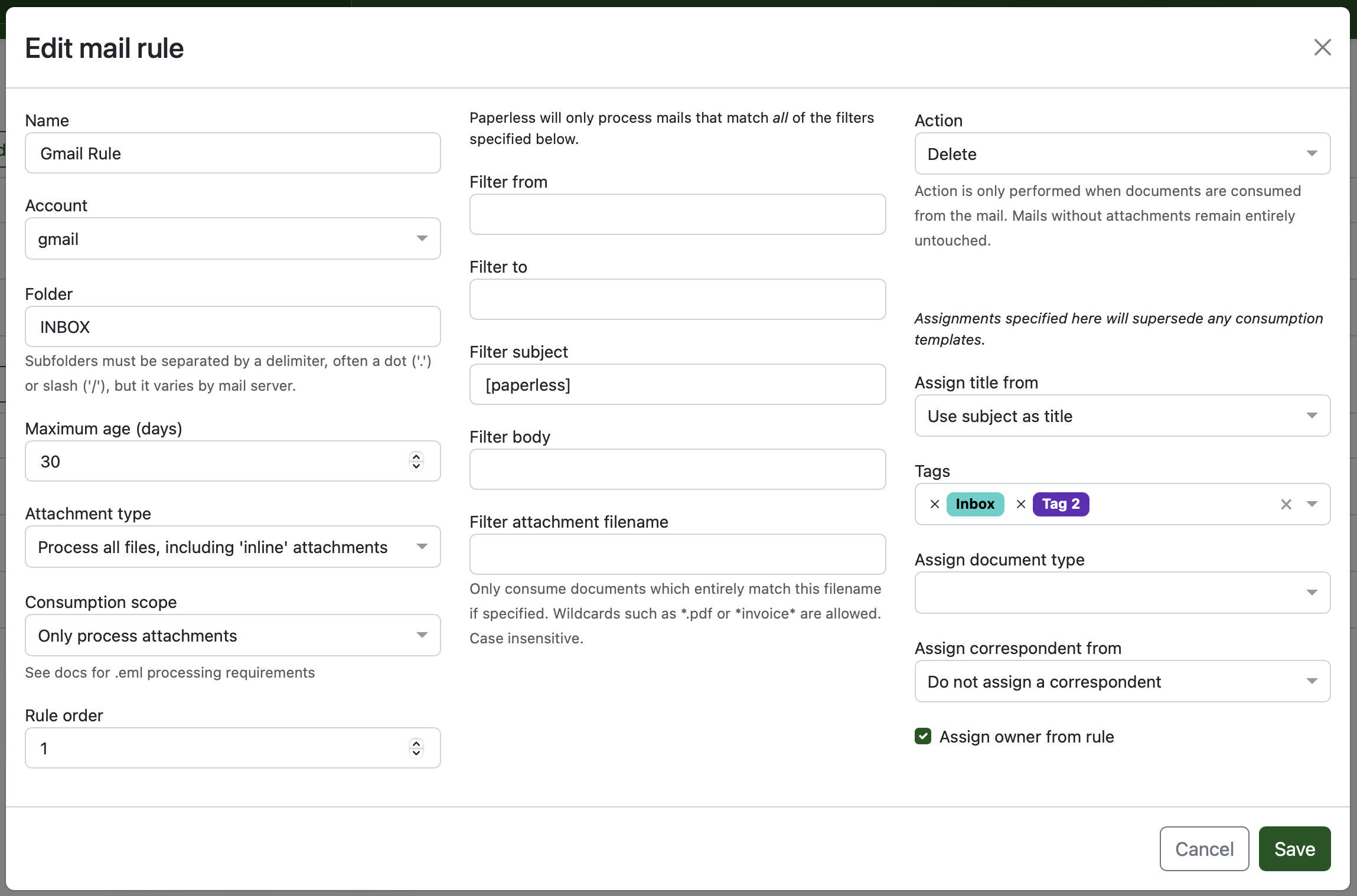
实用玩法:
邮箱里建一个文件夹:Paperless
收到需要归档的邮件后,移动到这个文件夹
paperless-ngx 定时检查
发现 PDF / 图片附件后自动导入
导入后给它打上“邮件”或“发票”等标签
如果你经常收到电子发票,可以再细一点:
来自开票平台 -> 标签:发票
来自保险公司 -> 标签:保险
来自银行 -> 标签:账单
未知邮件附件 -> 标签:待处理
这会让“整理发票”这件事轻松很多。
玩法五:批量整理旧资料
刚开始用时,最容易遇到的问题是:历史资料太多。
不要一次性导入几千份。
推荐节奏:
第一周,只导入最重要的 50 份。
保险
房产
汽车
证书
关键合同
第二周,导入近期高频使用的资料。
发票
报销单
设备说明书
保修卡
医疗报告
第三周,再处理历史资料。
每次导入后,用批量编辑统一处理标签、文档类型、往来方。
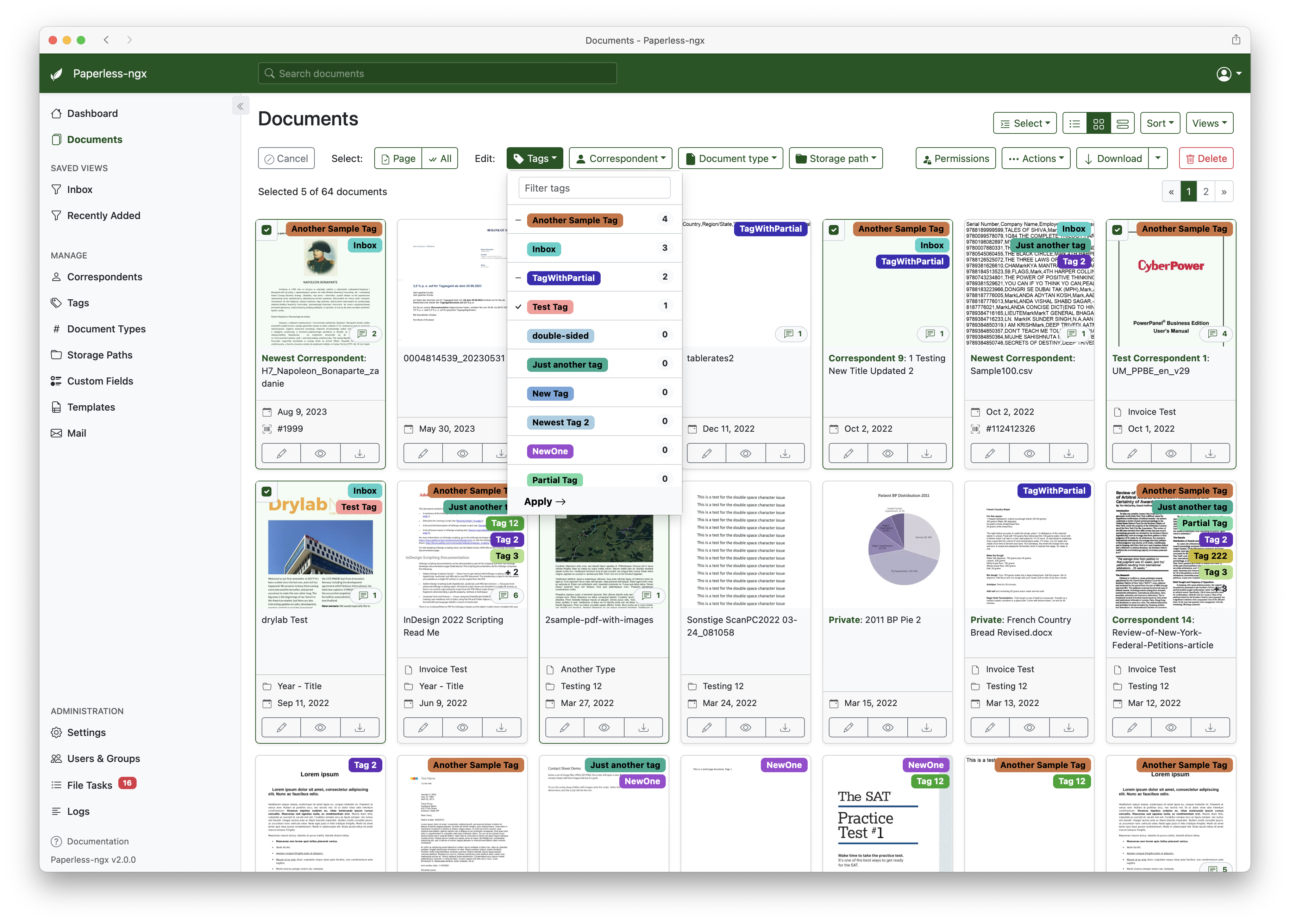
这个功能很实用,尤其是一次性导入同类资料时。
玩法六:搭配扫描工具
paperless-ngx 本身负责归档,不负责把纸变成扫描件。
你可以搭配这些方式:
| 工具 | 适合场景 |
|---|---|
| 手机扫描 App | 少量合同、发票、证书 |
| 一体机扫描仪 | 家庭偶尔使用 |
| 带自动进纸扫描仪 | 大量历史资料整理 |
| NAS 同步文件夹 | 自动把扫描件送进 consume |
| 邮箱规则 | 自动归档电子发票、账单 |
如果你家资料很多,自动进纸扫描仪会极大提高效率。
但如果只是轻度家庭使用,手机扫描也足够起步。
中文 OCR 注意事项
中文资料建议设置:
PAPERLESS_OCR_LANGUAGE=chi_sim+eng
这样可以兼顾中文和英文。
如果识别效果不理想,可以检查:
- 扫描件是否清晰;
- 图片是否歪斜;
- 分辨率是否太低;
- 容器内是否包含对应 OCR 语言包;
- 是否需要先把图片转成更清晰的 PDF。
OCR 不是魔法。纸张越清晰、光线越均匀、扫描越平整,识别效果越好。
备份一定要做
这是最重要的一节。
paperless-ngx 里存的不是普通文件,而是家庭档案。
至少要备份这些目录:
./data
./media
./pgdata
./export
docker-compose.yml
建议策略:
本机一份
NAS / 移动硬盘一份
异地或云端加密备份一份
如果你只备份 media,可能会丢数据库里的标签、文档类型、对应关系。
如果你只备份数据库,又会丢原始文件。
所以要把数据库、媒体文件和配置一起备份。
不建议这样用
这些坑可以提前避开:
- 不要一上来就导入全部历史文件;
- 不要把它直接裸奔暴露到公网;
- 不要只依赖 OCR,重要文件仍要人工检查;
- 不要把所有标签都设计得很复杂;
- 不要没有备份就把纸质原件扔掉;
- 不要只备份 PDF,忽略数据库和配置。
尤其最后一点很重要。
如果一份原件有法律、报销、医疗、保险价值,请先确认电子版是否足够,再决定要不要丢纸质原件。
我的推荐起步方案
如果你是家庭用户,可以这样开始:
部署位置:NAS 或小主机
部署方式:Docker Compose
导入入口:consume 文件夹
OCR 语言:chi_sim+eng
第一批资料:保险、合同、房产、汽车、证书
标签体系:控制在 10-15 个
原件管理:重要纸质文件贴 ASN 编号
备份策略:数据库 + media + 配置一起备份
先跑通一个小闭环:
扫描一份保单
上传到 consume
等待 OCR 完成
打标签:保险、家庭成员名、需保留原件
设置文档类型:保单
填写 ASN:BX-0001
把纸质原件放进保险资料盒
这个闭环跑通后,你就真正理解 paperless-ngx 的价值了。
写在最后
paperless-ngx 最适合的用户,不是“喜欢折腾工具的人”,而是那些真的被家庭资料、合同、票据折磨过的人。
它能做的不是简单保存文件,而是帮你建立一套可持续的家庭档案流程:
扫描、识别、分类、搜索、关联原件、定期备份。
当你某天需要找一份两年前的保单、一次维修记录、一张发票、一份合同,而不是翻箱倒柜,只要搜索一个关键词就能找到时,这个系统就值了。
项目地址:
https://github.com/paperless-ngx/paperless-ngx
如果你对 NAS、家庭服务器、开源工具、数字化收纳感兴趣,欢迎关注我。后面继续分享更多能真正用起来的开源项目和家庭实用玩法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)