一文搞懂 Linux 多线程互斥、同步、条件变量与信号量

文章目录
- 引言
- 1. 线程互斥
- 2. 互斥量 mutex
- 3. 使用 mutex 改进抢票系统
- 4. 互斥量实现原理探究
- 5. RAII 风格封装互斥锁
- 6. 线程同步
- 7. 条件变量接口
- 8. 条件变量简单案例
- 9. 为什么 pthread_cond_wait 需要互斥量
- 10. 条件变量封装
- 11. 生产者消费者模型
- 12. 基于 BlockingQueue 的生产者消费者模型
- 13. Task 任务类型
- 14. POSIX 信号量
- 15. 基于环形队列的生产消费模型
- 16. 线程池
- 17. 日志与策略模式
- 18. 策略模式实现日志输出
- 19. Logger 和 LogMessage
- 20. 线程安全的单例模式
- 21. 线程安全与可重入
- 22. STL、智能指针与线程安全
- 23. 常见锁概念补充
- 24. 高频技术题 / 面试题
-
- 24.1 为什么 ticket-- 不是原子操作?
- 24.2 互斥锁保护的到底是什么?
- 24.3 pthread_mutex_lock 加锁失败会发生什么?
- 24.4 为什么 pthread_cond_wait 要放在 while 里,而不是 if 里?
- 24.5 为什么 pthread_cond_wait 需要互斥锁?
- 24.6 生产者消费者模型有什么优点?
- 24.7 条件变量和信号量有什么区别?
- 24.8 线程池为什么能提高效率?
- 24.9 饿汉模式和懒汉模式有什么区别?
- 24.10 STL 容器为什么默认不是线程安全的?
- 24.11 什么是可重入函数?
- 24.12 线程安全函数一定可重入吗?
- 结语
引言
刚开始学线程的时候,我其实一直有一个比较简单的理解:线程就是“多个执行流一起跑”,只要 pthread_create 创建出来,大家各干各的就行了。但是学到线程同步和互斥之后,我才发现这个理解太浅了。
多线程真正麻烦的地方,不是“怎么创建线程”,而是多个线程同时访问同一份资源时,怎么保证数据不会乱。比如一个全局变量 ticket,看起来只是简单地 ticket--,但只要放到多线程环境下,就可能卖出 0 号票、-1 号票,甚至出现更离谱的数据。
这个地方一开始我挺容易想错:我以为 ticket-- 就是一句代码,应该天然是一个整体。后来往底层看才发现,它在 CPU 层面可能对应多条指令:先从内存读出来,再在寄存器里减一,最后再写回内存。只要中间发生线程切换,数据就可能出问题。
所以这篇博客主要是我学习线程互斥、线程同步、生产者消费者模型、信号量、线程池、线程安全与可重入时整理出来的理解。相比单纯记接口,我更想把几个问题想清楚:
- 线程为什么会不安全?
- 互斥锁到底保护了什么?
- 条件变量为什么必须配合互斥锁?
- 生产者消费者模型为什么这么经典?
- 线程池为什么能提升服务器效率?
- 什么叫线程安全,什么叫可重入?
学完之后我最大的感受是:多线程不是简单地“让程序跑得更快”,而是在共享资源、执行顺序和安全性之间做平衡。
1. 线程互斥
1.1 互斥相关的几个基础概念
学习线程互斥之前,先要把几个词分清楚:
共享资源:多个线程都能访问到的资源,比如全局变量、堆区对象、文件描述符、日志文件等。
临界资源:被多个执行流共享,并且需要保护的资源。
临界区:线程内部访问临界资源的那段代码。
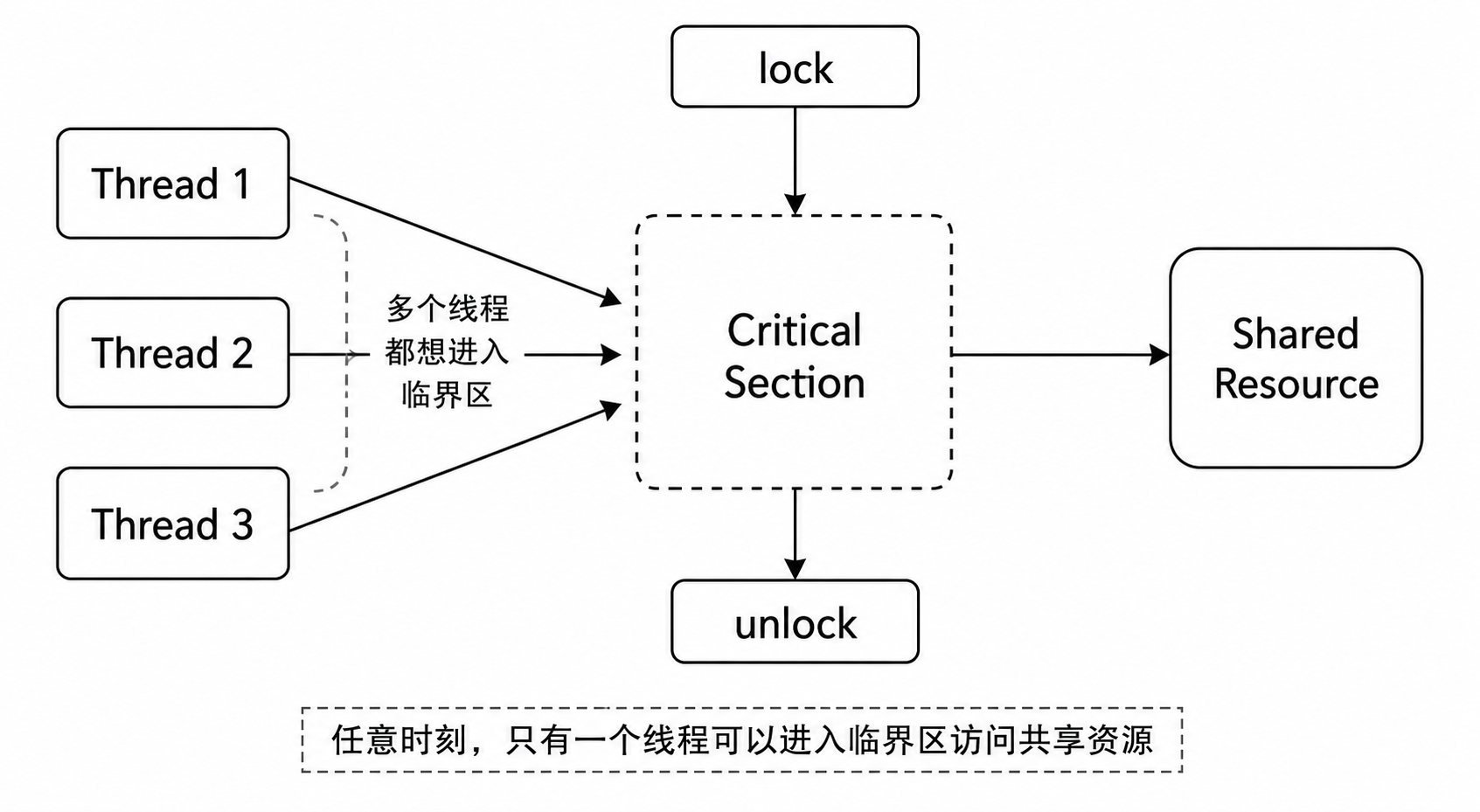
互斥:任意时刻,只允许一个执行流进入临界区访问临界资源。
原子性:一个操作不会被任何调度机制打断,要么全部完成,要么完全没做。
💡临界资源可以理解成宿舍公共洗衣机,临界区就是“你正在使用洗衣机”的那段时间。互斥就是同一时间只能一个人用,不能两个人同时把衣服塞进去。
1.2 为什么多个线程操作共享变量会出问题
先看一个最经典的抢票代码。
#include <stdio.h> // printf
#include <stdlib.h> // 标准库函数
#include <string.h> // 字符串相关接口
#include <unistd.h> // usleep
#include <pthread.h> // pthread_create / pthread_join
// 全局变量 ticket 属于共享资源
// 所有线程都可以访问它
int ticket = 100;
void *route(void *arg)
{
// arg 是 pthread_create 传进来的线程名字
// 这里强转成 char*,方便打印当前是哪一个线程在卖票
char *id = (char*)arg;
while (1)
{
// 判断票数是否大于 0
// 注意:这个判断本身不受保护
if (ticket > 0)
{
// 模拟业务处理耗时
// 在 sleep 的过程中,线程很可能被切走
usleep(1000);
// 打印当前线程卖出的票号
printf("%s sells ticket:%d\n", id, ticket);
// 对共享变量 ticket 做自减
// 这个操作不是原子操作
ticket--;
}
else
{
// 没票了,退出循环
break;
}
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
// 创建 4 个线程,同时执行 route 函数
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
// 主线程等待 4 个新线程结束
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}
可能出现的结果:
thread 4 sells ticket:100
...
thread 4 sells ticket:1
thread 2 sells ticket:0
thread 1 sells ticket:-1
thread 3 sells ticket:-2
这段代码最容易误解的地方在于:我一开始会觉得 if (ticket > 0) 已经判断过了,为什么还能卖出负数票?
关键原因有两个:
-
第一,
if判断完成之后,线程可能被切换走。比如线程 A 判断ticket > 0成立,此时票数是 1,但它还没来得及ticket--,线程 B、线程 C、线程 D 也可能进来判断,大家都认为还有票,于是最后就会卖出 0、-1、-2。 -
第二,
ticket--不是原子操作。
它看起来是一句 C/C++ 代码,但在底层可能被拆成类似下面几步:
# 查看可执行程序反汇编
objdump -d a.out > test.objdump
# 取出 ticket-- 对应的部分汇编代码
40064b: 8b 05 e3 04 20 00 mov 0x2004e3(%rip), %eax # load:从内存读取 ticket 到寄存器 eax
400651: 83 e8 01 sub $0x1, %eax # update:寄存器中的值减 1
400654: 89 05 da 04 20 00 mov %eax, 0x2004da(%rip) # store:把结果写回 ticket 的内存地址
也就是说,ticket-- 实际上可以拆成:
load :把 ticket 从内存加载到寄存器
update :在寄存器中执行 -1
store :把新值写回内存
只要这三步中间发生线程切换,就可能出现数据不一致。
💡这就像几个人同时看手机上的库存,大家看到还剩 1 件,于是都点了购买。问题不是“大家不会点按钮”,而是查看库存和扣减库存之间没有被保护起来。
2. 互斥量 mutex
2.1 为什么需要互斥量
想要解决上面的抢票问题,本质上要做到三点:
- 当一个线程进入临界区时,其他线程不能进入同一个临界区。
- 如果多个线程同时想进入临界区,只能让其中一个线程进去。
- 如果线程没有在临界区里执行,它就不能阻止其他线程进入临界区。
这三点总结起来,其实就是一句话:需要一把锁。
在 Linux 线程库中,这把锁通常就是互斥量 mutex。
互斥量的作用不是让所有线程都停下来,而是让多个线程在访问同一个临界资源时排队。
💡mutex 可以理解成厕所门上的锁。厕所本身是共享资源,进去上厕所的过程就是临界区。谁先锁门谁先用,其他人只能等门打开。
2.2 互斥量的初始化
互斥量有两种初始化方式。
2.2.1 静态初始化
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
这种方式一般用于 全局变量 或者 静态变量。它的特点是简单,不需要手动调用初始化函数。
2.2.2 动态初始化
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
参数解释:
mutex:要初始化的互斥量地址。attr:互斥量属性,一般传NULL,表示使用默认属性。
返回值:
- 成功返回
0。 - 失败返回错误码。
这里的 restrict 可以简单理解成一种编译器层面的提示,表示这个指针是访问该对象的主要方式。初学阶段不用被它卡住,重点理解函数作用即可。
2.3 互斥量的销毁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
销毁互斥量时需要注意:
- 使用
PTHREAD_MUTEX_INITIALIZER静态初始化的互斥量,一般不需要手动销毁。 - 不要销毁一个已经加锁的互斥量。
- 已经销毁的互斥量,后续不能再被任何线程加锁。
这个地方很容易写错:如果某个线程还在使用锁,另一个线程就把锁销毁了,程序行为就不可控了。
2.4 互斥量加锁和解锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
pthread_mutex_lock 的含义是申请锁。
如果锁当前没有被线程持有,当前线程加锁成功,继续向下执行。
如果锁已经被其他线程持有,当前线程会阻塞等待。
pthread_mutex_unlock 的含义是释放锁。
当当前线程访问完临界区后,必须释放锁,否则其他线程会一直等待。
3. 使用 mutex 改进抢票系统
3.1 加锁版本代码
#include <stdio.h> // printf
#include <stdlib.h> // 标准库函数
#include <string.h> // 字符串处理
#include <unistd.h> // usleep
#include <pthread.h> // pthread_create / pthread_join / pthread_mutex_xxx
#include <sched.h> // 调度相关接口
// 共享资源:票数
int ticket = 100;
// 全局互斥量,用来保护 ticket
pthread_mutex_t mutex;
void *route(void *arg)
{
char *id = (char*)arg;
while (1)
{
// 进入临界区之前先加锁
// 如果锁已经被其他线程拿走,当前线程会阻塞等待
pthread_mutex_lock(&mutex);
if (ticket > 0)
{
// 模拟业务处理耗时
// 注意:这里虽然 sleep,但因为锁没有释放,其他线程不能进入临界区
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
// ticket-- 被锁保护起来之后,
// 同一时刻只有一个线程能执行这段逻辑
ticket--;
// 临界区执行完毕,释放锁
pthread_mutex_unlock(&mutex);
}
else
{
// 即使没票了,也必须先释放锁
// 否则其他线程可能永远阻塞
pthread_mutex_unlock(&mutex);
break;
}
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
// 动态初始化互斥量
pthread_mutex_init(&mutex, NULL);
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
// 所有线程都结束后销毁互斥量
pthread_mutex_destroy(&mutex);
return 0;
}
3.2 代码理解
这段代码和前面最大的区别就是:
pthread_mutex_lock(&mutex);
和
pthread_mutex_unlock(&mutex);
把访问 ticket 的代码包起来了。
这里要注意一个非常重要的点:锁保护的是临界区,不是变量本身。
也就是说,ticket 这个变量还是那个变量,内存里没有发生什么神奇变化。真正变化的是:访问 ticket 的线程必须先抢到锁。
这个地方我一开始挺容易想错,总觉得“给变量加锁”像是变量自己被锁住了。后来才明白,锁本质上是保护访问这个变量的代码路径。
3.3 不能忘记解锁
这段代码里 else 分支也要解锁:
else
{
pthread_mutex_unlock(&mutex);
break;
}
如果这里忘记 pthread_mutex_unlock,当前线程在没票后直接 break,但锁还在它手里,其他线程就会永远卡在 pthread_mutex_lock。
这就是典型的死锁问题。
💡这就像你用完自习室钥匙后直接回宿舍了,但钥匙还在你口袋里。后面所有想进自习室的人都会被卡住。
4. 互斥量实现原理探究
4.1 i++ 和 ++i 为什么不是原子的
经过抢票问题之后,可以发现单纯的 i++、++i、i--、--i 都不是原子操作。
它们都可能被拆成:
读取内存数据
修改寄存器中的值
写回内存
如果多个线程同时执行,就可能发生覆盖写。
4.2 lock 和 unlock 底层为什么需要硬件支持
为了实现互斥锁,大多数 CPU 体系结构都会提供类似 swap 或 exchange 的指令。
这种指令可以把寄存器和内存单元的数据交换,并且这个交换过程是一条原子指令。
即使在多核 CPU 上,访问内存总线也有先后顺序,一个处理器执行交换指令时,另一个处理器必须等待。
可以用下面的伪代码理解:
lock:
movb $0, %al
xchgb %al, mutex
if al 的内容 > 0:
return 0
else:
挂起等待
goto lock
unlock:
movb $1, mutex
唤醒等待 mutex 的线程
return 0
这段伪代码想说明:加锁动作本身也必须是原子的。
如果加锁动作不是原子的,那就可能两个线程同时认为自己拿到了锁,这样互斥就失效了。
5. RAII 风格封装互斥锁
5.1 为什么要封装锁
直接使用 pthread_mutex_lock 和 pthread_mutex_unlock 有一个问题:非常容易忘记解锁。
尤其是在代码中出现 return、break、异常或者多个分支时,很可能某条路径没有释放锁。
C++ 中可以用 RAII 思想解决这个问题。
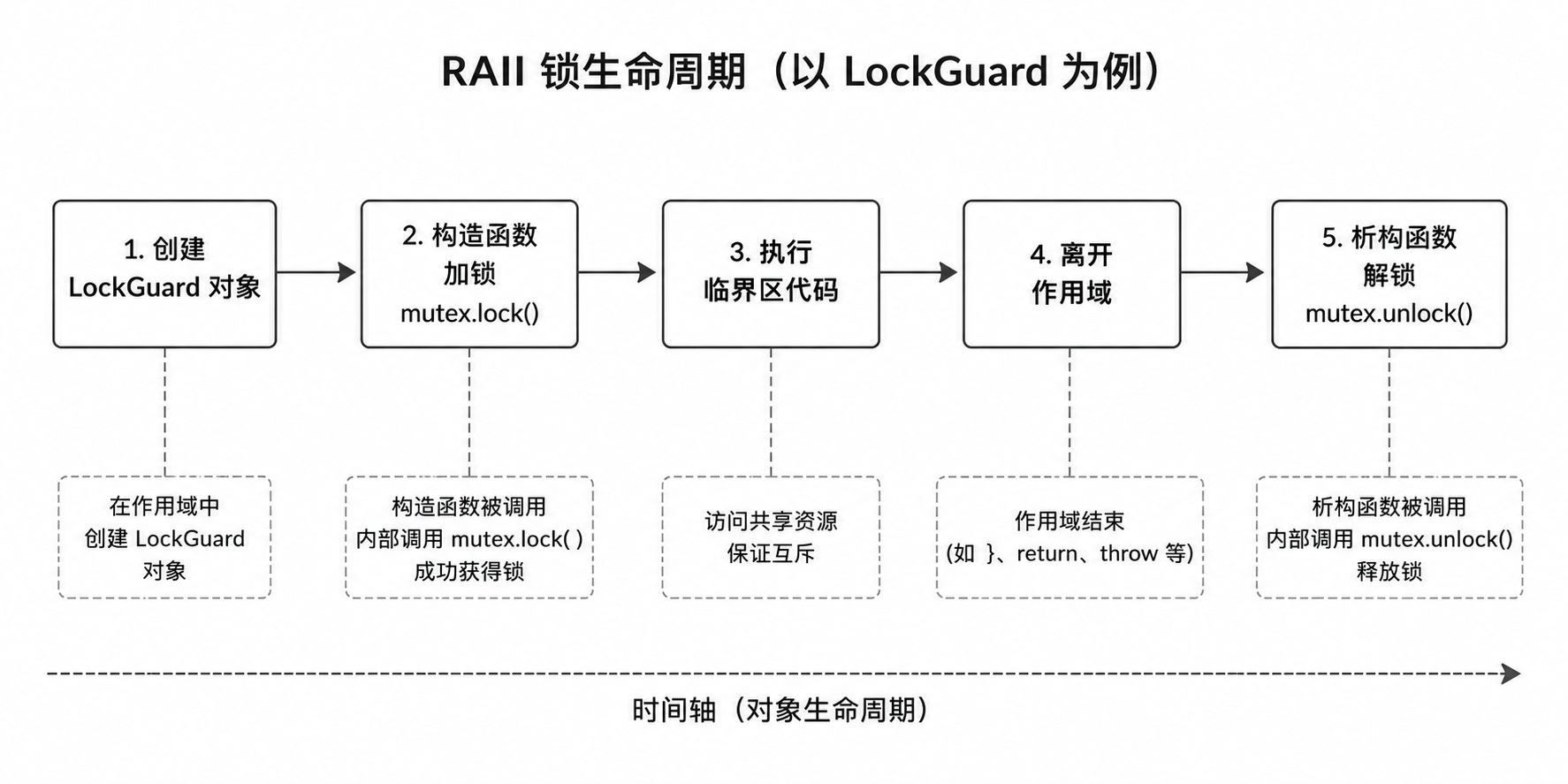
RAII 的核心是:
对象构造时获取资源。
对象析构时释放资源。
用在锁上就是:
构造函数加锁。
析构函数解锁。
💡RAII 就像离开教室自动关灯。你不用每次提醒自己“记得关灯”,因为这个动作已经和“离开教室”绑定在一起了。
5.2 Lock.hpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
namespace LockModule
{
// 对锁进行封装,可以独立使用
class Mutex
{
public:
// 删除拷贝构造
// 锁对象不应该被拷贝,否则多个 Mutex 对象可能管理同一把底层锁,容易出问题
Mutex(const Mutex &) = delete;
// 删除赋值运算符
const Mutex &operator=(const Mutex &) = delete;
Mutex()
{
// 初始化 pthread 互斥量
// nullptr 表示使用默认属性
int n = pthread_mutex_init(&_mutex, nullptr);
(void)n;
}
void Lock()
{
// 加锁
// 如果锁已经被其他线程持有,当前线程会阻塞
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
void Unlock()
{
// 解锁
// 当前线程访问完临界区后调用
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
pthread_mutex_t *GetMutexOriginal()
{
// 获取原始 pthread_mutex_t 指针
// 后面条件变量 pthread_cond_wait 需要用到原生互斥量
return &_mutex;
}
~Mutex()
{
// 销毁互斥量
int n = pthread_mutex_destroy(&_mutex);
(void)n;
}
private:
pthread_mutex_t _mutex;
};
// 采用 RAII 风格进行锁管理
class LockGuard
{
public:
LockGuard(Mutex &mutex)
: _mutex(mutex)
{
// 构造对象时自动加锁
_mutex.Lock();
}
~LockGuard()
{
// 对象析构时自动解锁
_mutex.Unlock();
}
private:
Mutex &_mutex;
};
}
5.3 使用 RAII 改写抢票代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include "Lock.hpp"
using namespace LockModule;
int ticket = 1000;
// 使用自己封装的 Mutex
Mutex mutex;
void *route(void *arg)
{
char *id = (char *)arg;
while (1)
{
// lockguard 是局部对象
// 构造时自动加锁,离开作用域时自动解锁
LockGuard lockguard(mutex);
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
}
else
{
break;
}
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}
5.4 RAII 代码理解
这个版本里没有显式写 Unlock,但是锁仍然会被释放。
原因是:
LockGuard lockguard(mutex);
是一个局部对象。
当程序执行完当前作用域时,lockguard 会自动析构,析构函数中会调用:
_mutex.Unlock();
这就是 RAII 的价值:把释放资源的动作交给对象生命周期管理。
C++11 标准库也有类似写法:
#include <mutex>
std::mutex mtx;
std::lock_guard<std::mutex> guard(mtx);
6. 线程同步
6.1 为什么有了互斥还需要同步
互斥解决的是同一时刻只能一个线程访问临界资源的问题。
但是同步解决的是线程之间按照某种顺序访问资源的问题。
比如一个线程访问队列,发现队列为空。这时它就算拿到了锁,也没有数据可以取。它不应该一直占着锁死等,而应该释放锁,然后等待生产者放入数据。
这就是条件变量要解决的问题。
6.2 条件变量
条件变量适合处理这种情况:
一个线程发现当前条件不满足,于是进入等待。
另一个线程修改了条件,然后通知等待线程继续执行。
例如:
某个线程想从队列中获取数据,但发现队列为空,于是进入等待状态。
后来另一个线程向队列中放入数据,并发送通知。
等待线程被唤醒后继续执行。
后面学习生产者消费者模型时,我们会看到条件变量最经典的应用场景。
💡条件变量就像外卖取餐叫号。你发现餐还没好,就坐着等。等店员叫到你的号,你再过去取餐。
7. 条件变量接口
7.1 初始化条件变量
#include <pthread.h>
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
参数说明:
cond:要初始化的条件变量。attr:条件变量属性,一般传NULL。
返回值:
- 成功返回
0。 - 失败返回错误码。
7.2 销毁条件变量
int pthread_cond_destroy(pthread_cond_t *cond);
销毁条件变量时要确保没有线程还在这个条件变量上等待。
7.3 等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
参数说明:
cond:当前线程要等待的条件变量。mutex:配合条件变量使用的互斥锁。
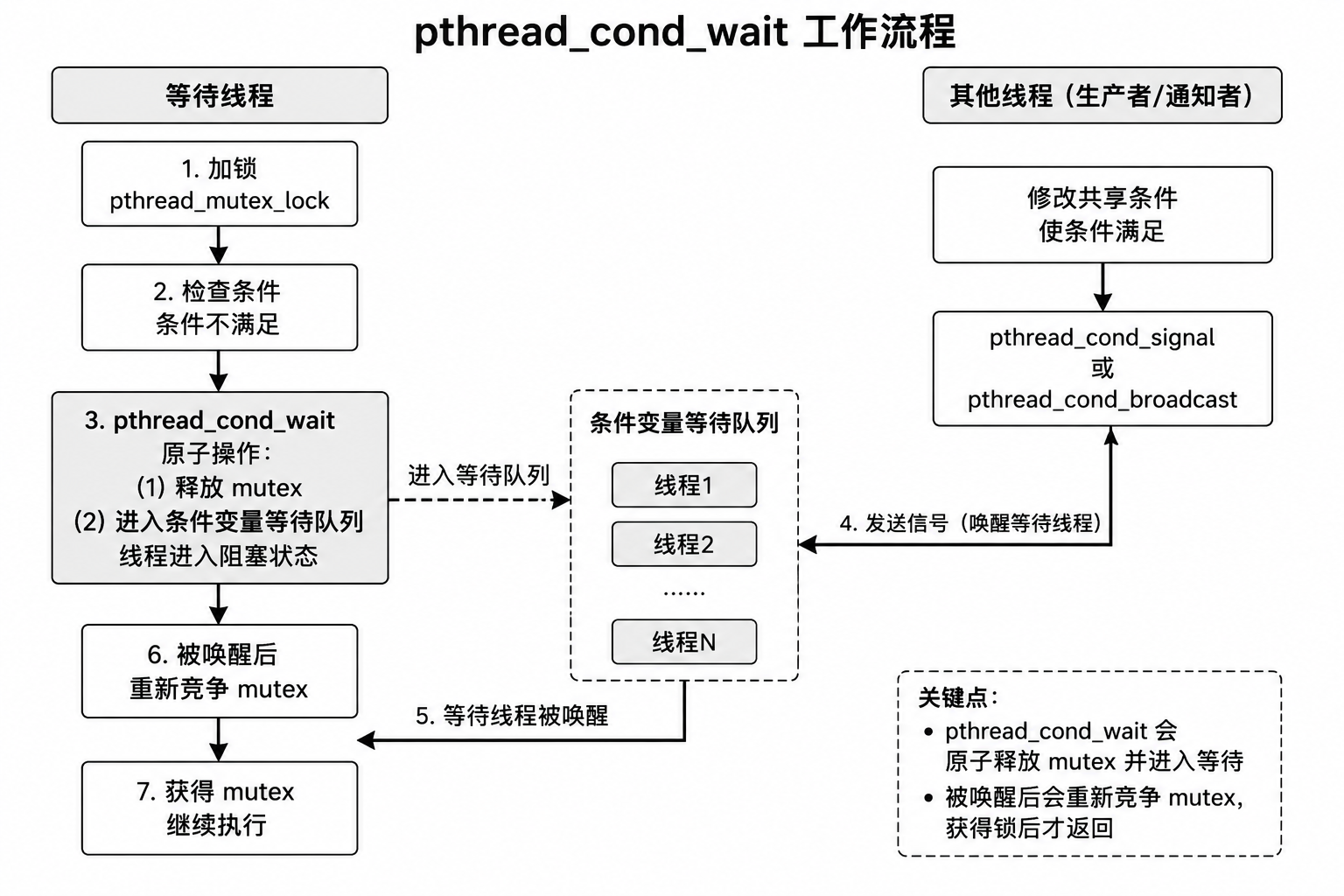
这个函数非常关键,它会做三件事:
- 释放当前线程持有的互斥锁。
- 让当前线程在条件变量上等待。
- 被唤醒后,重新竞争互斥锁,成功后才返回。
7.4 唤醒等待线程
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
pthread_cond_signal:唤醒一个等待线程。pthread_cond_broadcast:唤醒所有等待线程。
8. 条件变量简单案例
8.1 测试代码
#include <iostream>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
// 静态初始化条件变量
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
// 静态初始化互斥量
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *active(void *arg)
{
std::string name = static_cast<const char*>(arg);
while (true)
{
// 等待条件变量之前先加锁
pthread_mutex_lock(&mutex);
// 当前线程在 cond 条件变量上等待
// pthread_cond_wait 会自动释放 mutex
// 被唤醒后会重新竞争 mutex
pthread_cond_wait(&cond, &mutex);
std::cout << name << " 活动..." << std::endl;
// 执行完临界区逻辑后解锁
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main(void)
{
pthread_t t1, t2;
pthread_create(&t1, NULL, active, (void*)"thread-1");
pthread_create(&t2, NULL, active, (void*)"thread-2");
// 确保两个线程已经运行起来并进入等待状态
sleep(3);
while (true)
{
// 唤醒一个等待线程
// pthread_cond_signal(&cond);
// 唤醒所有等待线程
pthread_cond_broadcast(&cond);
sleep(1);
}
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
8.2 运行结果
$ ./cond
thread-1 活动...
thread-2 活动...
thread-1 活动...
thread-1 活动...
thread-2 活动...
这个结果不一定完全固定,因为线程调度顺序由操作系统决定。
pthread_cond_signal 每次只唤醒一个线程。pthread_cond_broadcast 会唤醒所有等待线程。
8.3 条件变量不是保存信号的容器
这里要注意一个容易踩坑的点:
条件变量不会保存历史信号。
如果没有线程正在等待,提前发送的 signal 可能会丢失。
所以条件变量一般要配合某个具体条件使用,而不是单纯把它当成“消息队列”。
9. 为什么 pthread_cond_wait 需要互斥量
9.1 条件变化一定涉及共享数据
条件变量等待的“条件”通常不是凭空出现的,而是由共享数据决定的。
比如:
队列是否为空。
队列是否满。
任务是否到来。
资源是否可用。
这些状态都属于共享数据,所以必须用互斥锁保护。
9.2 错误设计
一开始我也容易想成下面这样:先加锁,发现条件不满足,就解锁,然后等待。
// 错误设计:解锁和等待不是原子操作
pthread_mutex_lock(&mutex);
while (condition_is_false)
{
pthread_mutex_unlock(&mutex);
// 解锁之后、真正等待之前,
// 如果其他线程已经修改条件并发送信号,
// 当前线程就可能错过这次通知
pthread_cond_wait(&cond, &mutex);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);
问题就在于:
pthread_mutex_unlock(&mutex);
pthread_cond_wait(&cond, &mutex);
这两步之间不是原子的。
如果当前线程刚解锁,还没来得及进入等待,另一个线程就修改条件并发送信号,那么当前线程可能错过通知,后面就会一直阻塞。
9.3 正确理解 pthread_cond_wait
pthread_cond_wait 帮我们把“释放锁 + 挂起等待”做成一个原子过程。
也就是说,它不是简单地等待条件变量,而是带着锁一起配合完成同步。
条件变量的标准等待写法:
pthread_mutex_lock(&mutex);
while (条件为假)
{
// 必须用 while,不能简单用 if
pthread_cond_wait(&cond, &mutex);
}
// 条件满足后,访问共享资源
pthread_mutex_unlock(&mutex);
发送通知方的标准写法:
pthread_mutex_lock(&mutex);
// 修改条件
// 例如:往队列中放入数据
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
9.4 为什么要用 while 而不是 if
pthread_cond_wait 可能出现伪唤醒。
也就是说,线程被唤醒了,但条件不一定真的满足。
另外,如果多个线程被唤醒,资源可能已经被其他线程先拿走了。
所以被唤醒后必须重新判断条件。
💡这就像很多人在等奶茶,店员喊了一声“好了”,你不能不看单号就直接拿。你被喊醒了,不代表那杯一定是你的,还得重新确认条件。
10. 条件变量封装
10.1 Cond.hpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include "Lock.hpp"
namespace CondModule
{
using namespace LockModule;
class Cond
{
public:
Cond()
{
// 初始化条件变量
int n = pthread_cond_init(&_cond, nullptr);
(void)n;
}
void Wait(Mutex &mutex)
{
// 等待条件变量
// 这里必须传入原始 pthread_mutex_t*
int n = pthread_cond_wait(&_cond, mutex.GetMutexOriginal());
(void)n;
}
void Notify()
{
// 唤醒一个等待线程
int n = pthread_cond_signal(&_cond);
(void)n;
}
void NotifyAll()
{
// 唤醒所有等待线程
int n = pthread_cond_broadcast(&_cond);
(void)n;
}
~Cond()
{
// 销毁条件变量
int n = pthread_cond_destroy(&_cond);
(void)n;
}
private:
pthread_cond_t _cond;
};
}
10.2 封装时为什么不在 Cond 内部持有 Mutex
这里有一个设计细节:不要让 Cond 类内部强行持有某个 Mutex。
因为条件变量和互斥锁通常是一起被某个更大的数据结构管理的,比如阻塞队列、线程池。
如果 Cond 内部也绑定一把锁,后面组合时会让代码耦合变高。
所以更合理的方式是:Cond 只负责封装条件变量本身,等待时由外部传入对应的锁。
11. 生产者消费者模型
11.1 为什么要使用生产者消费者模型
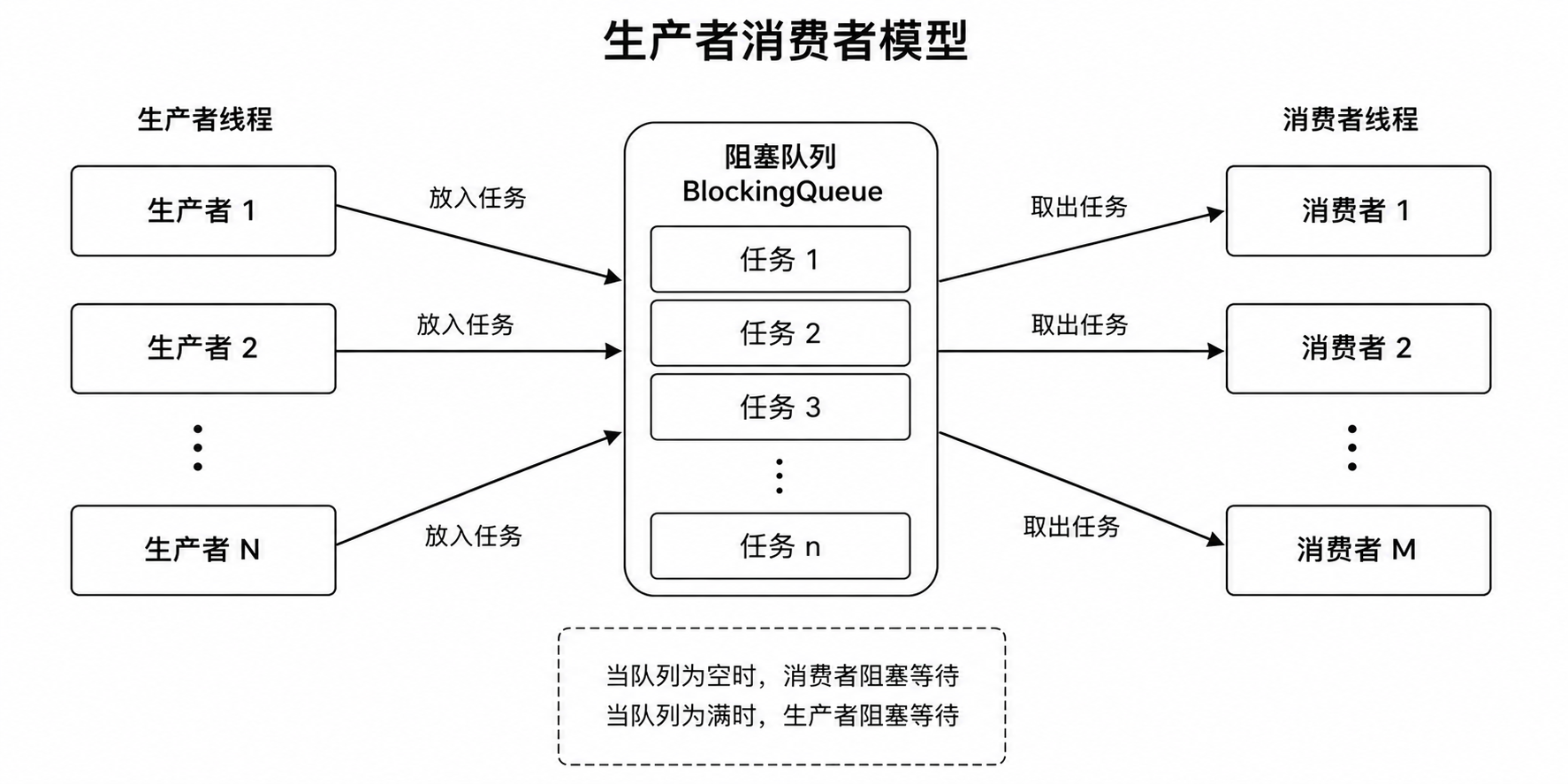
生产者消费者模型是多线程里非常经典的模型。
它的核心思想是:通过一个容器解决生产者和消费者之间的强耦合问题。
生产者生产完数据后,不直接交给消费者,而是放到阻塞队列中。
消费者不直接找生产者要数据,而是从阻塞队列里取。
这个阻塞队列就像缓冲区,平衡生产者和消费者的处理速度。
11.2 生产者消费者模型的优点
主要有三个:
第一,解耦。
生产者和消费者不直接通信,中间通过队列交互。
第二,支持并发。
多个生产者和多个消费者可以同时工作。
第三,支持忙闲不均。
如果生产者一段时间生产得快,队列可以暂时存放数据。
如果消费者一段时间处理得快,也可以快速消耗队列中的数据。
💡这就像食堂后厨和学生之间隔着取餐台。厨师只负责把饭放到取餐台,学生只负责从取餐台拿饭。双方不用一对一沟通,整体效率反而更高。
12. 基于 BlockingQueue 的生产者消费者模型
12.1 BlockingQueue 的特点
阻塞队列和普通队列的区别在于:
队列为空时,消费者取数据会阻塞。
队列满时,生产者放数据会阻塞。
这刚好可以用互斥锁和条件变量实现。
12.2 BlockQueue.hpp
#ifndef __BLOCK_QUEUE_HPP__
#define __BLOCK_QUEUE_HPP__
#include <iostream>
#include <string>
#include <queue>
#include <pthread.h>
template <typename T>
class BlockQueue
{
private:
bool IsFull()
{
// 判断队列是否满
return _block_queue.size() == _cap;
}
bool IsEmpty()
{
// 判断队列是否为空
return _block_queue.empty();
}
public:
BlockQueue(int cap)
: _cap(cap)
{
_productor_wait_num = 0;
_consumer_wait_num = 0;
// 初始化保护队列的互斥锁
pthread_mutex_init(&_mutex, nullptr);
// 初始化生产者等待的条件变量
pthread_cond_init(&_product_cond, nullptr);
// 初始化消费者等待的条件变量
pthread_cond_init(&_consum_cond, nullptr);
}
void Enqueue(T &in)
{
// 生产者进入临界区前加锁
pthread_mutex_lock(&_mutex);
while (IsFull())
{
// 队列满了,生产者不能继续生产
// pthread_cond_wait 会自动释放 _mutex
// 被唤醒后,会重新竞争 _mutex
_productor_wait_num++;
pthread_cond_wait(&_product_cond, &_mutex);
_productor_wait_num--;
}
// 进行生产
_block_queue.push(in);
// 如果有消费者正在等待,就唤醒一个消费者
if (_consumer_wait_num > 0)
{
pthread_cond_signal(&_consum_cond);
}
// 释放锁
pthread_mutex_unlock(&_mutex);
}
void Pop(T *out)
{
// 消费者进入临界区前加锁
pthread_mutex_lock(&_mutex);
while (IsEmpty())
{
// 队列为空,消费者不能消费
// 使用 while 是为了防止伪唤醒
_consumer_wait_num++;
pthread_cond_wait(&_consum_cond, &_mutex);
_consumer_wait_num--;
}
// 进行消费
*out = _block_queue.front();
_block_queue.pop();
// 如果有生产者正在等待,就唤醒一个生产者
if (_productor_wait_num > 0)
{
pthread_cond_signal(&_product_cond);
}
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_product_cond);
pthread_cond_destroy(&_consum_cond);
}
private:
std::queue<T> _block_queue; // 阻塞队列,属于共享资源
int _cap; // 队列容量上限
pthread_mutex_t _mutex; // 保护队列的锁
pthread_cond_t _product_cond; // 生产者等待条件变量
pthread_cond_t _consum_cond; // 消费者等待条件变量
int _productor_wait_num; // 正在等待的生产者数量
int _consumer_wait_num; // 正在等待的消费者数量
};
#endif
12.3 代码理解
这段代码里有几个关键点。
第一,判断队列满或空时必须在锁内完成。因为队列本身是共享资源。
第二,等待条件变量必须使用 while,不能只用 if。因为被唤醒不代表条件一定满足。
第三,生产者生产完数据后,要通知消费者。
消费者消费完数据后,要通知生产者。
第四,条件变量不是锁。
真正保护队列的是 _mutex,条件变量只是负责让线程在条件不满足时等待。
13. Task 任务类型
13.1 队列中不一定只能放 int
阻塞队列使用模板实现,是为了让队列中不仅可以放内置类型,也可以放对象或任务。
比如可以自定义任务类:
#pragma once
#include <iostream>
#include <string>
#include <functional>
// 任务类型 1:可以自己定义 Task 类
// class Task
// {
// public:
// Task() {}
//
// Task(int a, int b)
// : _a(a), _b(b), _result(0)
// {
// }
//
// void Excute()
// {
// // 执行任务
// _result = _a + _b;
// }
//
// std::string ResultToString()
// {
// return std::to_string(_a) + "+" + std::to_string(_b) + "=" +
// std::to_string(_result);
// }
//
// std::string DebugToString()
// {
// return std::to_string(_a) + "+" + std::to_string(_b) + "=?";
// }
//
// private:
// int _a;
// int _b;
// int _result;
// };
// 任务类型 2:使用函数包装器
// 只要能被调用,就可以作为任务放入队列
using Task = std::function<void()>;
std::function<void()> 很适合线程池,因为线程池不需要关心任务内部到底干什么,只需要取出来执行即可。
14. POSIX 信号量
14.1 POSIX 信号量的作用
POSIX 信号量和 System V 信号量的作用类似,都是用于同步操作,避免多个执行流冲突访问共享资源。
不过 POSIX 信号量可以用于线程间同步。
14.2 初始化信号量
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数说明:
sem:要初始化的信号量。pshared:为0表示线程间共享,非 0 表示进程间共享。value:信号量初始值。
14.3 销毁信号量
int sem_destroy(sem_t *sem);
14.4 等待信号量
int sem_wait(sem_t *sem);
sem_wait 对应 P 操作(拿资源,可以理解成“Pick”)。
它会让信号量的值减 1。
如果信号量为 0,线程会阻塞等待。
14.5 发布信号量
int sem_post(sem_t *sem);
sem_post 对应 V 操作(还资源,“Return”)。
它会让信号量的值加 1,并可能唤醒等待线程。
15. 基于环形队列的生产消费模型
15.1 环形队列的基本理解
环形队列可以用数组模拟,通过模运算让下标回绕。
普通队列判断空和满比较麻烦,因为起始状态和结束状态可能看起来一样。
常见做法有:
- 加计数器。
- 加标记位。
- 预留一个空位置。
- 使用信号量计数。
这里用信号量就非常合适。
15.2 Sem.hpp
#pragma once
#include <iostream>
#include <semaphore.h>
// 随手做一下封装
class Sem
{
public:
Sem(int n)
{
// pshared 为 0,表示线程间共享
// n 是信号量初始值
sem_init(&_sem, 0, n);
}
void P()
{
// 申请资源
// 如果信号量为 0,会阻塞
sem_wait(&_sem);
}
void V()
{
// 释放资源
// 信号量加 1
sem_post(&_sem);
}
~Sem()
{
sem_destroy(&_sem);
}
private:
sem_t _sem;
};
15.3 RingQueue.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <semaphore.h>
#include <pthread.h>
#include "Sem.hpp"
// 单生产,单消费
// 多生产,多消费
// "321":
// 3: 三种关系
// a: 生产和消费互斥和同步
// b: 生产者之间互斥
// c: 消费者之间互斥
// 2: 两类角色,生产者和消费者
// 1: 一个交易场所,环形队列
template <typename T>
class RingQueue
{
private:
void Lock(pthread_mutex_t &mutex)
{
pthread_mutex_lock(&mutex);
}
void Unlock(pthread_mutex_t &mutex)
{
pthread_mutex_unlock(&mutex);
}
public:
RingQueue(int cap)
: _ring_queue(cap),
_cap(cap),
_room_sem(cap), // 初始时所有位置都是空位
_data_sem(0), // 初始时没有数据
_productor_step(0),
_consumer_step(0)
{
// 多生产者之间需要互斥
pthread_mutex_init(&_productor_mutex, nullptr);
// 多消费者之间需要互斥
pthread_mutex_init(&_consumer_mutex, nullptr);
}
void Enqueue(const T &in)
{
// 生产者先申请空位
// 如果没有空位,说明队列满了,生产者阻塞
_room_sem.P();
// 多个生产者之间要保护生产下标
Lock(_productor_mutex);
// 一定有空间可以写入
_ring_queue[_productor_step++] = in;
// 下标回绕
_productor_step %= _cap;
Unlock(_productor_mutex);
// 写入数据后,通知消费者数据数量增加
_data_sem.V();
}
void Pop(T *out)
{
// 消费者先申请数据
// 如果没有数据,说明队列为空,消费者阻塞
_data_sem.P();
// 多个消费者之间要保护消费下标
Lock(_consumer_mutex);
*out = _ring_queue[_consumer_step++];
// 下标回绕
_consumer_step %= _cap;
Unlock(_consumer_mutex);
// 取走数据后,通知生产者空位数量增加
_room_sem.V();
}
~RingQueue()
{
pthread_mutex_destroy(&_productor_mutex);
pthread_mutex_destroy(&_consumer_mutex);
}
private:
// 1. 环形队列
std::vector<T> _ring_queue;
int _cap;
// 2. 生产和消费的下标
int _productor_step;
int _consumer_step;
// 3. 定义信号量
Sem _room_sem; // 生产者关心空位数量
Sem _data_sem; // 消费者关心数据数量
// 4. 定义锁,维护多生产多消费之间的互斥关系
pthread_mutex_t _productor_mutex;
pthread_mutex_t _consumer_mutex;
};
15.4 环形队列代码理解
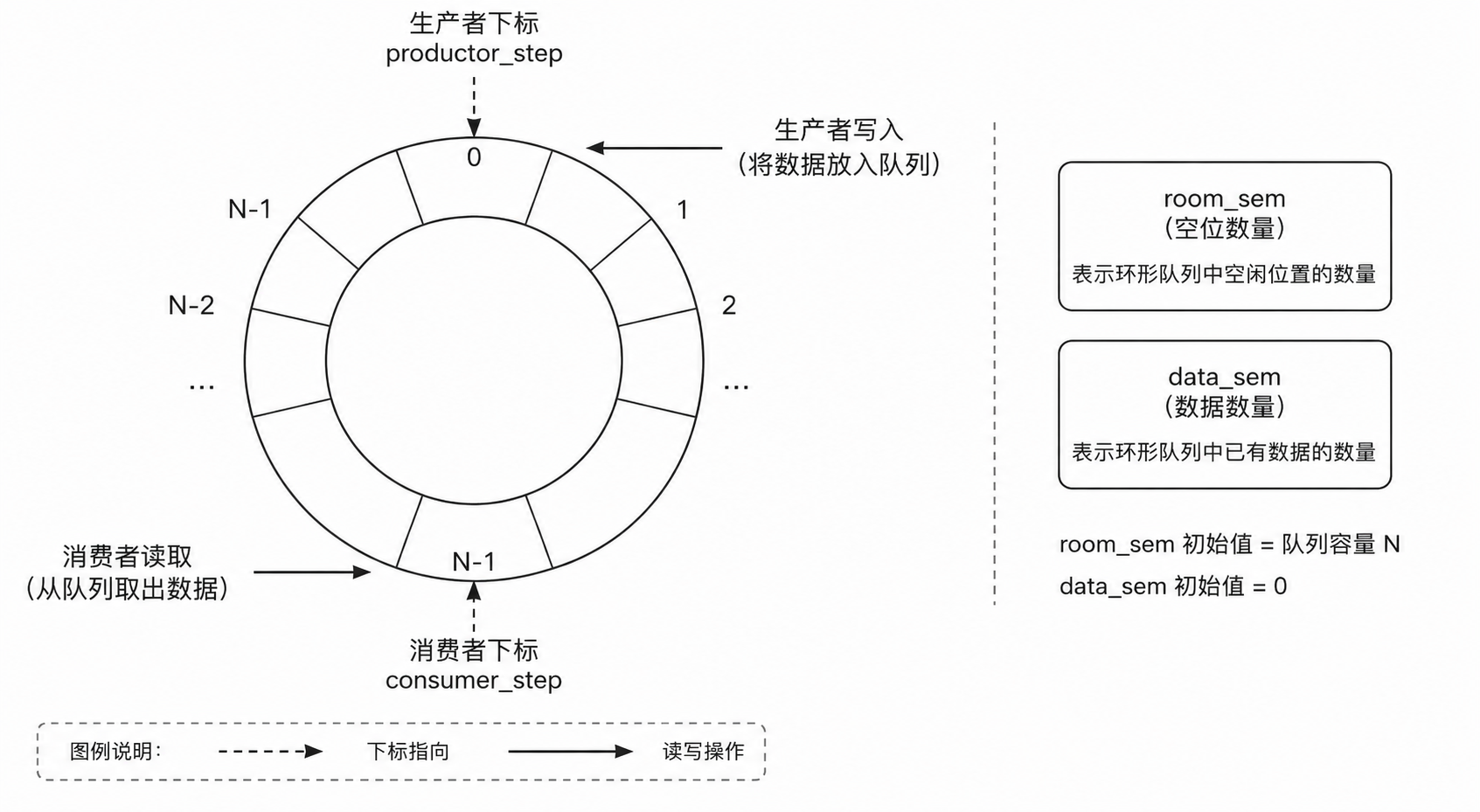
这段代码里最关键的是两个信号量:
_room_sem 表示空位资源。_data_sem 表示数据资源。
生产者执行顺序是:
申请空位
加生产者锁
写入数据
更新生产下标
解锁
释放数据资源
消费者执行顺序是:
申请数据
加消费者锁
取出数据
更新消费下标
解锁
释放空位资源
这里生产者之间需要互斥,因为多个生产者可能同时修改 _productor_step。
消费者之间也需要互斥,因为多个消费者可能同时修改 _consumer_step。
但是生产者和消费者之间主要通过信号量同步。
💡环形队列就像一个固定数量的快递柜。生产者放包裹前要先确认有空格,消费者取包裹前要先确认有包裹。空格数量和包裹数量,就是两个信号量。
16. 线程池
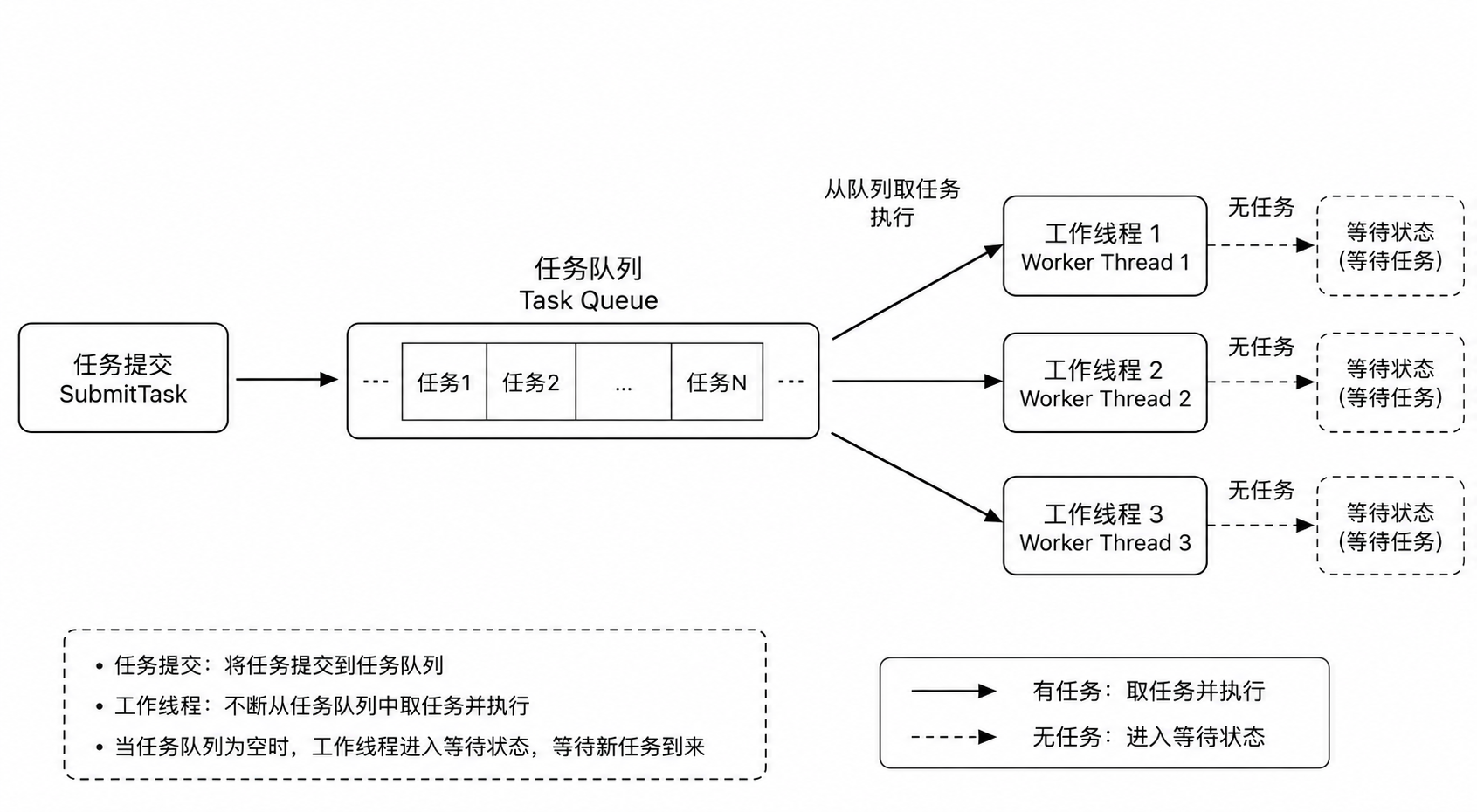
16.1 为什么需要线程池
服务器中如果每来一个任务就创建一个线程,开销会很大。
线程池的思路是:
提前创建一批线程。
任务来了之后放入任务队列。
线程不断从队列中取任务执行。
没有任务时线程等待,有任务时被唤醒。
线程池适合:
大量短任务。
突发请求比较多的服务器。
不希望频繁创建和销毁线程的场景。
💡线程池就像快递驿站提前安排好的工作人员。包裹来了直接分配给工作人员处理,而不是每来一个包裹临时招聘一个人。
16.2 线程池和生产者消费者模型的关系
线程池本质上就是生产者消费者模型的一种工程化应用。
提交任务的线程是生产者。
工作线程是消费者。
任务队列是交易场所。
条件变量负责没有任务时等待和有任务时唤醒。
所以理解了生产者消费者模型,再看线程池就会清楚很多。
17. 日志与策略模式
17.1 为什么线程池需要日志
多线程程序最难调试的地方是执行顺序不固定。
有些问题可能只在特定线程切换顺序下出现。
如果没有日志,就很难知道程序当时发生了什么。
一个比较完整的日志通常包含:
- 时间戳
- 日志等级
- 进程 pid
- 文件名
- 行号
- 日志内容
示例格式:
[2026-08-04 12:27:03] [DEBUG] [202938] [main.cc] [16] - hello world
[2026-08-04 12:27:03] [WARNING] [202938] [main.cc] [23] - hello world
💡日志就像实验记录本。程序正常跑的时候你可能觉得它没用,但一旦出问题,它就是你回溯现场的唯一线索。
17.2 日志等级
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
不同等级表示不同严重程度。
DEBUG:调试信息。INFO:普通运行信息。WARNING:警告信息。ERROR:错误信息。FATAL:严重错误信息。
17.3 日志等级转字符串
std::string LogLevelToString(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
这段代码的作用是把枚举值转成字符串,方便最终打印到日志中。
17.4 获取当前时间
std::string GetCurrTime()
{
time_t tm = time(nullptr);
struct tm curr;
// localtime_r 是线程安全版本
// localtime 返回的是静态区地址,多线程环境下不安全
localtime_r(&tm, &curr);
char timebuffer[64];
snprintf(timebuffer,
sizeof(timebuffer),
"%4d-%02d-%02d %02d:%02d:%02d",
curr.tm_year + 1900,
curr.tm_mon + 1,
curr.tm_mday,
curr.tm_hour,
curr.tm_min,
curr.tm_sec);
return timebuffer;
}
这里有一个细节:多线程环境下建议使用 localtime_r,而不是 localtime。
因为 localtime 可能使用静态缓冲区,多线程同时调用时可能造成数据覆盖。
18. 策略模式实现日志输出
18.1 策略模式的理解
策略模式简单来说就是:
把“会变化的行为”抽象成接口,然后让不同策略类去实现。
日志这里变化的部分是:日志输出到哪里。
可以输出到控制台。
也可以输出到文件。
后续还可以输出到网络、数据库等。
18.2 LogStrategy 接口
class LogStrategy
{
public:
virtual ~LogStrategy() = default;
// 不同策略的核心区别就是 SyncLog 的实现不同
virtual void SyncLog(const std::string &message) = 0;
};
这是一个抽象基类,定义了统一的日志输出接口。
18.3 控制台日志策略
class ConsoleLogStrategy : public LogStrategy
{
public:
void SyncLog(const std::string &message) override
{
// 显示器也是共享资源
// 多线程同时输出可能会交叉,所以也需要加锁
LockGuard lockguard(_mutex);
std::cerr << message << std::endl;
}
private:
Mutex _mutex;
};
这里显示器也被看成临界资源。
如果多个线程同时向终端打印,输出内容可能交叉在一起,所以也需要加锁。
18.4 文件日志策略
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const std::string logpath = defaultpath,
std::string logfilename = defaultname)
: _logpath(logpath),
_logfilename(logfilename)
{
LockGuard lockguard(_mutex);
if (std::filesystem::exists(_logpath))
{
return;
}
try
{
std::filesystem::create_directories(_logpath);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << '\n';
}
}
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::string log = _logpath + _logfilename;
// 追加方式打开日志文件
std::ofstream out(log.c_str(), std::ios::app);
if (!out.is_open())
{
return;
}
out << message << "\n";
out.close();
}
public:
std::string _logpath;
std::string _logfilename;
Mutex _mutex;
};
文件日志策略需要注意两个点:
第一,如果日志目录不存在,需要先创建目录。
第二,多线程写文件也需要保护,否则日志内容可能乱序或交叉。
19. Logger 和 LogMessage
19.1 Logger 类
class Logger
{
public:
Logger()
{
// 默认使用控制台日志策略
UseConsoleStrategy();
}
void UseConsoleStrategy()
{
_strategy = std::make_unique<ConsoleLogStrategy>();
}
void UseFileStrategy()
{
_strategy = std::make_unique<FileLogStrategy>();
}
private:
std::unique_ptr<LogStrategy> _strategy;
friend class LogMessage;
};
Logger 内部使用 std::unique_ptr<LogStrategy> 管理策略对象。
如果调用 UseConsoleStrategy,日志输出到控制台。
如果调用 UseFileStrategy,日志输出到文件。
19.2 LogMessage 类
class LogMessage
{
private:
LogLevel _type; // 日志等级
std::string _curr_time; // 当前时间
pid_t _pid; // 进程 ID
std::string _filename; // 文件名
int _line; // 行号
Logger &_logger; // 引用 Logger,用于调用具体策略
std::string _loginfo; // 拼接后的完整日志信息
public:
LogMessage(LogLevel type,
std::string filename,
int line,
Logger &logger)
: _type(type),
_curr_time(GetCurrTime()),
_pid(getpid()),
_filename(filename),
_line(line),
_logger(logger)
{
std::stringstream ssbuffer;
ssbuffer << "[" << _curr_time << "] "
<< "[" << LogLevelToString(type) << "] "
<< "[" << _pid << "] "
<< "[" << _filename << "] "
<< "[" << _line << "]"
<< " - ";
_loginfo = ssbuffer.str();
}
template <typename T>
LogMessage &operator<<(const T &info)
{
std::stringstream ssbuffer;
ssbuffer << info;
_loginfo += ssbuffer.str();
return *this;
}
~LogMessage()
{
if (_logger._strategy)
{
_logger._strategy->SyncLog(_loginfo);
}
}
};
这个类的设计也有 RAII 的味道。
构造时生成日志头部。
使用 << 拼接日志内容。
析构时自动把日志刷新出去。
19.3 宏封装
#define LOG(level) LogModule::Logger::LogMessage(level, __FILE__, __LINE__, logger)
#define ENABLE_CONSOLE_LOG_STRATEGY() logger.UseConsoleStrategy()
#define ENABLE_FILE_LOG_STRATEGY() logger.UseFileStrategy()
宏的好处是可以自动带上 __FILE__ 和 __LINE__。
这样打印日志时不需要手动写文件名和行号。
20. 线程安全的单例模式
20.1 为什么需要单例模式
有些对象在一个进程中只应该存在一份,比如:线程池、日志器、配置管理器。
- 如果创建出多个线程池,可能会造成线程数量失控。
- 如果创建出多个日志器,可能会导致日志输出混乱。
20.2 饿汉模式
template <typename T>
class Singleton
{
private:
// 程序启动时就创建对象
static T data;
public:
static T *GetInstance()
{
return &data;
}
};
饿汉模式的特点是:程序启动时就创建对象。
优点:简单、天然线程安全。
缺点:如果对象很大,会影响启动速度。即使后续不用,也已经创建了。
💡 饿汉模式就像吃完饭立刻洗碗。下一顿吃饭时可以直接用,但是你必须提前付出洗碗成本。
20.3 懒汉模式
template <typename T>
class Singleton
{
private:
static T *inst;
public:
static T *GetInstance()
{
if (inst == NULL)
{
inst = new T();
}
return inst;
}
};
懒汉模式的特点是:第一次使用时才创建对象。
优点:延时加载,不用就不创建。
缺点:普通写法线程不安全。如果多个线程第一次同时调用 GetInstance,它们可能都看到 inst == NULL,于是创建出多个对象。
💡 懒汉模式就像吃完饭不洗碗,下次吃饭前在洗碗,在每次吃饭前会多一个洗碗的过程。
20.4 线程安全的懒汉模式
#include <mutex>
template <typename T>
class Singleton
{
private:
// volatile 防止编译器过度优化
volatile static T *inst;
// 互斥锁保护第一次创建对象的过程
static std::mutex lock;
public:
static T *GetInstance()
{
// 第一层判断:减少不必要的加锁
if (inst == NULL)
{
lock.lock();
// 第二层判断:保证只有第一个抢到锁的线程真正创建对象
if (inst == NULL)
{
inst = new T();
}
lock.unlock();
}
return (T*)inst;
}
};
这里的双重判断很重要。
第一层 if 是为了性能:对象创建好之后,就不用每次都加锁。
第二层 if 是为了安全:防止多个线程排队进入锁后重复创建对象。
21. 线程安全与可重入
21.1 什么是线程安全
线程安全指的是:多个线程并发执行同一段代码时,不会因为访问共享资源而产生异常结果。
常见线程不安全原因:
- 访问共享变量没有加锁;
- 函数内部使用了静态变量;
- 多个线程同时操作同一个容器;
- 多个线程同时写同一个文件或显示器;
- 使用了不可重入函数。
21.2 什么是可重入函数
可重入函数指的是:函数在执行过程中被打断后,再次进入执行也不会出问题。
如果一个函数只使用局部变量,不访问共享资源,一般更容易是可重入的。
如果一个函数使用了全局变量、静态变量、malloc/free、标准 IO 等,就可能不可重入。
21.3 线程安全和可重入的关系
可重入函数通常是线程安全的。
线程安全函数不一定是可重入的。
比如一个函数内部加锁访问共享资源,它可能是线程安全的。
但是如果它在信号处理函数中被重入,可能因为重复加锁导致死锁。
21.4 常见不可重入情况
常见不可重入情况包括:
- 函数内部使用静态变量;
- 函数返回静态区地址;
- 函数调用了不可重入函数;
- 函数内部使用全局数据结构;
- 函数内部进行了加锁操作,但可能被信号打断后再次进入。
22. STL、智能指针与线程安全
22.1 STL 容器是否线程安全
STL 容器默认不是线程安全的。
原因很简单:标准库更偏向性能。如果每个容器操作都默认加锁,会带来很大性能损耗。
而且不同容器适合的加锁粒度也不同,比如:
- 有些场景需要锁整个容器;
- 有些场景只需要锁某个桶;
- 有些场景读多写少,适合读写锁。
所以 STL 通常把线程安全控制交给使用者。
22.2 智能指针是否线程安全
unique_ptr 通常不涉及多线程共享所有权,因为它强调独占。
shared_ptr 的引用计数操作通常是线程安全的。
因为引用计数可能被多个 shared_ptr 对象共享,标准库实现一般会使用原子操作保证引用计数正确。
但是注意:
shared_ptr 管理的对象本身不一定线程安全。
也就是说,多个线程拷贝 shared_ptr 通常没问题。
但是多个线程通过 shared_ptr 同时修改对象内容,仍然需要加锁。
💡shared_ptr 的线程安全更像“借书登记表是安全的”,但书本内容本身不是自动安全的。多个人同时在书上写字,还是会乱。
23. 常见锁概念补充
23.1 悲观锁
悲观锁的思想是:每次访问数据时,都认为别人可能会修改,所以先加锁。
互斥锁就是典型的悲观锁。
适合场景:
写操作较多。
冲突概率较高。
数据一致性要求高。
23.2 乐观锁
乐观锁的思想是:先不加锁,更新时再检查数据有没有被别人改过。
常见实现方式:
- 版本号机制;
- CAS 操作。
适合场景:
读多写少。
冲突概率较低。
希望减少加锁开销。
23.3 CAS 操作
CAS 全称 Compare And Swap。
它的逻辑是:
如果当前内存值等于预期值,就把它更新成新值。
如果不相等,说明数据被别人改过,更新失败,可以重试。
CAS 常常会配合自旋使用。
23.4 自旋锁
自旋锁的特点是:拿不到锁时不阻塞,而是一直循环等待。
优点:
避免线程挂起和唤醒开销。
缺点:
如果锁持有时间长,会浪费 CPU。
适合锁持有时间非常短的场景。
23.5 读写锁
读写锁适合读多写少的场景。
多个读者可以同时读。
写者写的时候需要独占。
读写之间互斥。
这样可以提高读多写少场景下的并发能力。
24. 高频技术题 / 面试题
24.1 为什么 ticket-- 不是原子操作?
ticket-- 在 C/C++ 代码中看起来是一句,但底层通常会拆成三步:
先从内存读取 ticket 到寄存器。
再在寄存器中减一。
最后把结果写回内存。
多线程环境下,如果线程在这三步中间被切换,就可能导致多个线程基于同一个旧值进行修改,最终造成数据不一致。
24.2 互斥锁保护的到底是什么?
互斥锁保护的不是变量本身,而是访问临界资源的代码段,也就是临界区。
如果一个共享变量有多处访问,那么这些访问位置都应该使用同一把锁保护。否则只保护一处是不够的。
24.3 pthread_mutex_lock 加锁失败会发生什么?
如果互斥量当前没有被占用,加锁成功,函数返回 0。
如果互斥量已经被其他线程占用,当前线程通常会阻塞等待。
如果使用方式错误,比如锁对象非法,可能返回错误码。
24.4 为什么 pthread_cond_wait 要放在 while 里,而不是 if 里?
因为可能存在伪唤醒。
即使线程被唤醒,也不能保证条件一定满足。尤其是多个线程同时等待时,某个线程被唤醒后,资源可能已经被其他线程抢走。
所以被唤醒后必须重新判断条件。
24.5 为什么 pthread_cond_wait 需要互斥锁?
因为条件变量等待的“条件”通常依赖共享数据,而共享数据必须被互斥锁保护。
同时,pthread_cond_wait 需要原子地完成释放锁和挂起等待。如果手动先解锁再等待,中间可能错过其他线程发送的通知,导致永久阻塞。
24.6 生产者消费者模型有什么优点?
主要有三个:
第一,解耦。生产者和消费者不直接通信,而是通过队列交互。
第二,支持并发。多个生产者和多个消费者可以同时工作。
第三,支持忙闲不均。队列可以作为缓冲区,平衡生产速度和消费速度。
24.7 条件变量和信号量有什么区别?
条件变量更强调“等待某个条件发生变化”,通常需要配合互斥锁使用。
信号量本身带计数能力,可以表示资源数量。比如环形队列中,空位数量和数据数量就很适合用信号量表示。
24.8 线程池为什么能提高效率?
线程池提前创建固定数量的线程,避免每来一个任务就创建和销毁线程。
它减少了线程创建销毁开销,也能限制线程数量,避免突发请求导致系统资源被耗尽。
24.9 饿汉模式和懒汉模式有什么区别?
饿汉模式是程序启动时就创建对象。优点是简单且线程安全,缺点是可能影响启动速度。
懒汉模式是第一次使用时再创建对象。优点是延时加载,缺点是多线程环境下需要加锁保护。
24.10 STL 容器为什么默认不是线程安全的?
因为 STL 设计时更注重性能。如果每个容器操作都默认加锁,会带来额外开销。
而且不同容器适合的加锁粒度不同,有的适合锁整个表,有的适合锁桶。因此标准库通常把线程安全控制交给使用者。
24.11 什么是可重入函数?
可重入函数指的是:函数在执行过程中被打断后,再次进入执行也不会破坏原来的执行结果。
可重入函数一般不依赖全局变量、静态变量,也不会使用不可重入资源。
24.12 线程安全函数一定可重入吗?
不一定。
线程安全函数可能通过加锁实现安全。
但是如果它在执行过程中被信号打断,然后在信号处理函数中再次调用,就可能重复加锁导致死锁。
所以可重入函数通常线程安全,但线程安全函数不一定可重入。
结语
学完线程同步与互斥之后,我对多线程的理解确实变了很多。
一开始我只是觉得线程就是“多个函数同时跑”,后来才发现,多线程真正难的不是创建,而是资源共享之后带来的不确定性。一个简单的 ticket--,如果放在单线程里完全没问题,但放在多线程里就可能出现负数票。这个现象背后其实牵扯到 CPU 指令、线程调度、临界区、原子性和锁。
互斥锁解决的是安全问题:同一时刻只允许一个线程进入临界区。
条件变量解决的是顺序问题:线程在条件不满足时应该等待,条件满足后再继续。
生产者消费者模型解决的是解耦问题:让生产和消费通过队列连接起来。
线程池解决的是工程效率问题:避免频繁创建销毁线程,提高服务器处理任务的能力。
这一部分让我感觉操作系统很多知识其实是连在一起的。进程线程、调度、锁、信号量、条件变量、生产者消费者、线程池,看起来是不同概念,但本质都围绕一个问题:多个执行流如何安全、高效、有序地协作。
后面再看服务器、网络编程、任务队列、日志系统时,这些内容就不是孤立的 API 了,而是能真正理解它们为什么这样设计。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)