多模态文档解析后处理开源模型:MinerU-Popo方案思路提升RAG性能
·
目前各类的文档解析方案(VLM-OCR)都是基于【单页】文档进行解析,输出每页文字、表格、图片+坐标框,但存在4类跨页缺点:
- 段落跨页被分页切割、文本断裂;
- 大表格分页拆分,上下表身割裂;
- 多级标题(一级/二级/三级标题)层级混乱、从属关系丢失;
- 插图和对应正文分离,图文无法绑定。
在RAG场景,需要全书/文档连贯的文档级结构化数据。
MinerU-Popo是一个后处理方案,在不改动原有VLM-OCR模型后对文档级结构进行重构。
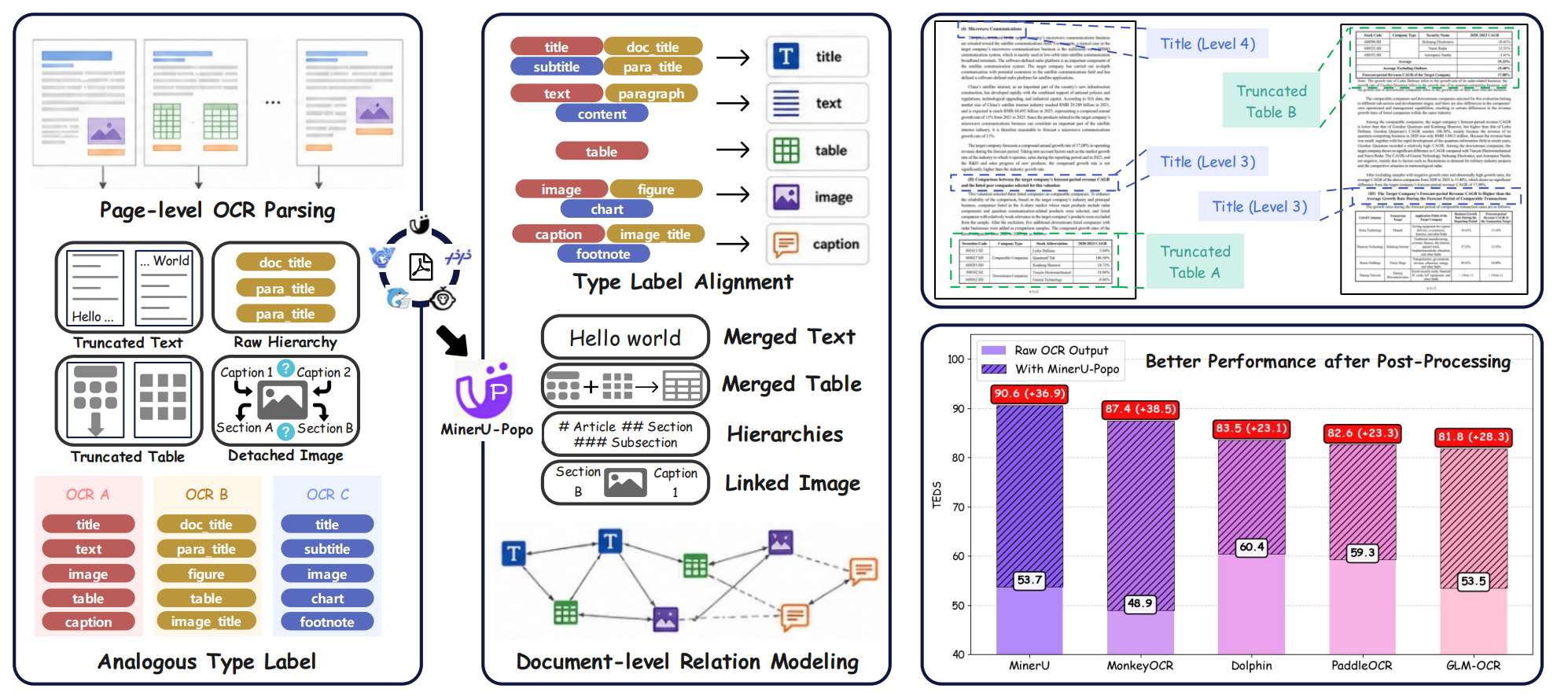
方法架构
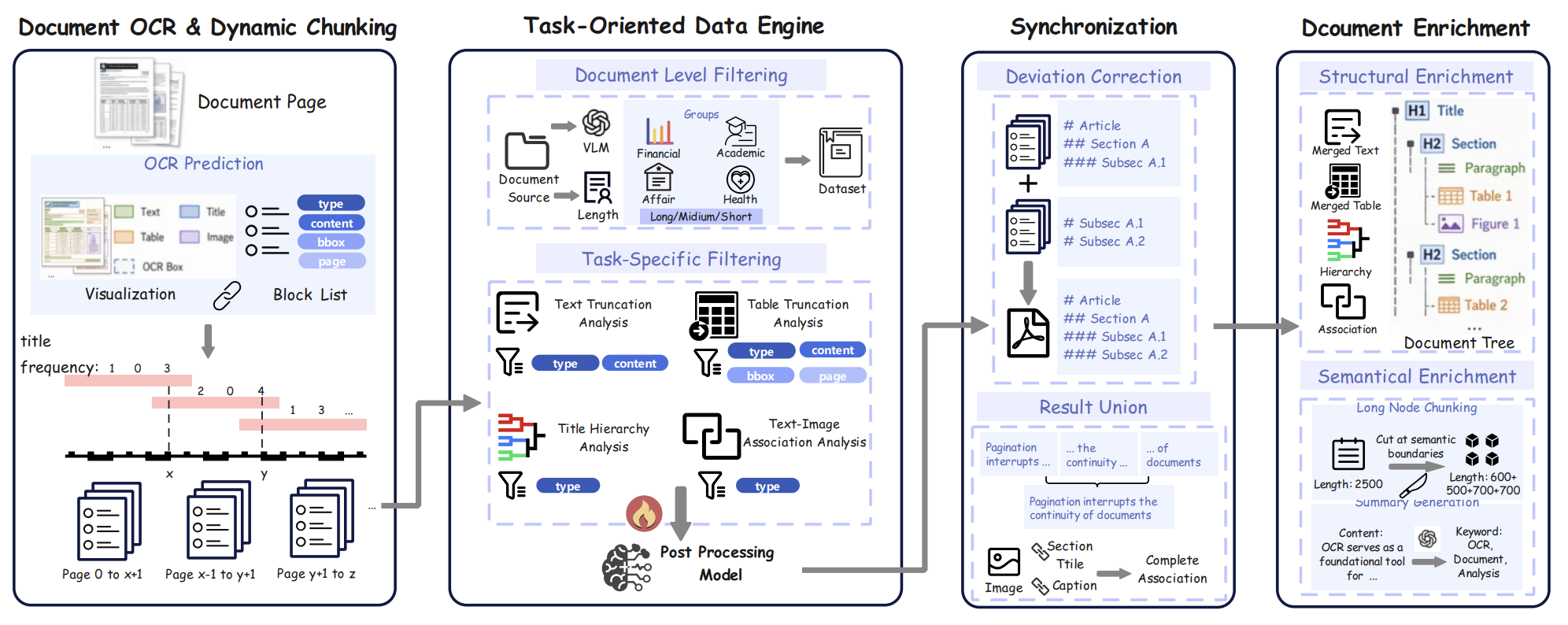
整体方案针对4类跨页缺点基于Qwen3-VL-4B构造4个任务各自独立数据集进行微调。对于【跨页文本截断、表格截断】,定义成二分类任务;

对于【标题层级重构】,定义成开放层级(1、2、3…n)预测;

【图文关联匹配(图片和图注 / 正文描述分散在不同页面,绑定图文)】,预测文字与其关联的图像或表格。

最终四项任务全部跑完后,所有零散页面元素被组装为文档树结构:全书(H0)→一级标题H1→二级H2→(段落/完整表格/绑定图片),直接适配RAG知识库入库。
实验评测

参考文献
MinerU-Popo: Universal Post-Processing Model for Structured Document Parsing,https://arxiv.org/abs/2605.24973
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
…

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)