Ollama安装(附百度网盘)以及导入大模型权重(详细流程)
随着开源大模型的迎来爆发式增长,在本地部署和运行大模型变得越来越简单。而在众多本地部署工具中,Ollama 凭借其极简的安装体验、高效的内存管理以及开箱即用的 API 支持,成为了目前最受欢迎的工具之一。
本文将带你从零开始安装 Ollama,并详细讲解如何将本地自定义的大模型权重(如从 Hugging Face 下载的 .guff 文件或.safetensors格式文件)导入到 Ollama 中,打造专属于你的本地 AI。

一、 什么是 Ollama?
Ollama 是一个专为本地机器设计的轻量级、可扩展的大模型服务框架。它不仅支持一键运行 Llama 3、Qwen 2、Mistral 等主流开源模型,还提供了一个非常强大的功能——通过配置 Modelfile,允许用户自由导入和定制第三方模型。
二、 安装 Ollama
Ollama 提供了对 Windows、macOS 和 Linux 的原生支持,安装过程极其简单。
1. 下载与安装
-
Windows & macOS: 访问 Ollama 官方网站 (ollama.com),下载对应系统的安装包,双击并一路点击 "Next" 即可完成安装。安装完成后,电脑任务栏会出现一个小图标。
-
百度网盘安装:在官网下载可能会比较慢,在这里我附上百度网盘下载:
链接: https://pan.baidu.com/s/1y8dm_AgXwrdNtMhOZwlRlA?pwd=mxwj 提取码: mxwj -
Linux: 打开终端,运行以下一键安装脚本:
curl -fsSL https://ollama.com/install.sh | sh
2. 验证安装
打开你的终端(CMD、PowerShell 或 Linux Terminal),运行以下命令验证是否安装成功:
ollama --version
//会显示你目前安装的版本号,例如:
ollama version is 0.30.4如果正常输出了版本号,说明 Ollama 已经在后台默默为你工作了。
三、 准备自定义模型权重
3.1 .GGUF格式的大模型
通常,我们在平台(如 Hugging Face 或 GitHub)上下载的适合本地量化运行的模型格式为 GGUF。
例如:qwen2-7b-instruct-q4_k_m.gguf
3.2 Hugging Face格式的大模型(如果大模型是.GGUF格式,直接跳过)
如果我们下载得到的文件后缀为.json、.safetensors,那它属于Hugginf Face格式。在嵌入式开发中,这相当于你拿到了散装的原生 C 语言源代码文件和头文件,而之前我们提到的 .gguf 文件,则是已经编译打包好、可以直接在单片机上运行的 .bin 固件。
接下开我们就要“编译”该文件转换成.guff格式。
第一步:准备llama.cpp工具链
因为转换脚本是 Python 写的,我们需要先把它下载到电脑上。
打开终端(如果你在 Windows 上,建议使用 WSL 或者确保你的电脑安装了 Git 和 Python 3.10+)。
下载 llama.cpp 源码:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp如果上述方式下载失败,则进行物理方式下载
浏览器直接搜索:https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.zip
-
你会下载到一个名为
llama.cpp-master.zip的压缩包。把它解压到你的C:\Users\电脑用户名\目录下。 -
改名对齐:把解压出来的文件夹名字改成
llama.cpp。 -
进入目录:打开你的终端,直接输入:
cd C:\Users\用户名\llama.cpp
第二步:安装转换脚本需要的Python依赖库
pip install -r requirements.txt第三步:执行格式转换
llama.cpp 提供了一个专门针对 Hugging Face 格式的转换脚本。我们直接运行它,把你下载好的模型文件的路径喂给它。在 llama.cpp 目录下执行以下命令:
python convert_hf_to_gguf.py /把你的模型文件所在的文件夹绝对路径写在这里/ f16 --outfile ./模型名.gguf
例如:
python convert_hf_to_gguf.py E:\AI\Llama3 --outtype f16 --outfile ./llama3_raw.gguf这一步就像是单片机中的编译过程,脚本会读取你模型文件所在文件路径的文件,将文件中的数据打包压缩成一个.gguf文件,该文件名可自定义。
第四步:压缩模型(可选操作)
刚刚生成的.gguf 可能较大。如果你的笔记本配置不是特别高,强烈建议对它进行量化(压缩)处理,这样模型大小会缩小,运行速度可以得到提升,且智商几乎不怎么受损。当然如果你的文件本来就很小(如3G左右),不压缩也行。
在终端继续执行:
# 编译出 llama.cpp 的量化工具
# 如果是在 Linux/WSL 下,直接 make 即可
make llama-quantize
# 开始量化压缩
./llama-quantize ./原模型名.gguf ./压缩后的模型名.gguf Q4_K_M
最终就可以得到,gguf格式的模型文件。
3.3 创建一个专用文件夹,用来存放模型和配置文件
-
新建文件夹,命名为my_llm
-
移入权重文件.gguf:把你手里拿到的模型权重文件
.gguf复制到这个 my_llm文件夹里。 -
编写配置文件Modelfile:在
my_llm文件夹内,新建一个空白记事本文件。将文件名彻底重命名为:Modelfile(必须删掉后缀.txt,名字没有任何大小写或后缀,就叫 Modelfile)。用记事本打开这个Modelfile,写进核心配置:(根据自己的需求,可以自行更改)
# 1. 引入模型权重(必须放在第一行)
FROM D:\OllamaModels\qwen2.5-7b-instruct.gguf
# 2. 模型行为参数配置(PARAMETER)
PARAMETER num_ctx 8192 # 扩大上下文到 8192 token
PARAMETER temperature 0.7 # 创造力系数
PARAMETER top_p 0.9 # 核采样阈值,配合 temperature 提升文本质量
PARAMETER stop "<|im_end|>" # 文本截断符号(防止模型自言自语,根据模型更换)
PARAMETER stop "<|im_start|>"
# 3. 设定系统提示词(SYSTEM)这里可以定制你想要的 AI 身份、语气、规矩
SYSTEM """
你是一个由个人部署的本地 AI 智能助手。
- 你必须使用专业、礼貌、简洁的中文进行回答。
- 当你不知道答案时,请直接诚实地回答不知道,不要编造事实。
- 优先使用 Markdown 格式来组织你的回答,使结构更清晰。
"""
# 4. 设置 Prompt 模板(非常重要!不同的模型有不同的模板,以下为 Qwen 格式示例)
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Output }}<|im_end|>"""最终你就得到了一个名为my_llm的文件夹,文件夹中有一个.gguf文件和Modelfile文件。
四、在Ollama中导入模型
打开终端,并 cd 进入到包含 Modelfile 和 .gguf 文件的目录下:
cd D:\my_llm
运行 ollama create 命令。语法的格式为 ollama create <自定义模型名称> -f ./Modelfile
ollama create my-custom-model -f ./Modelfile
随后终端会显示进度,类似于:
transferring model data
creating model layer
writing layer
success
当看到 success 时,说明模型已经成功导入到 Ollama 的本地仓库中了
五、启动大模型
导入成功后,你可以通过以下命令查看现有的本地模型列表:
ollama list
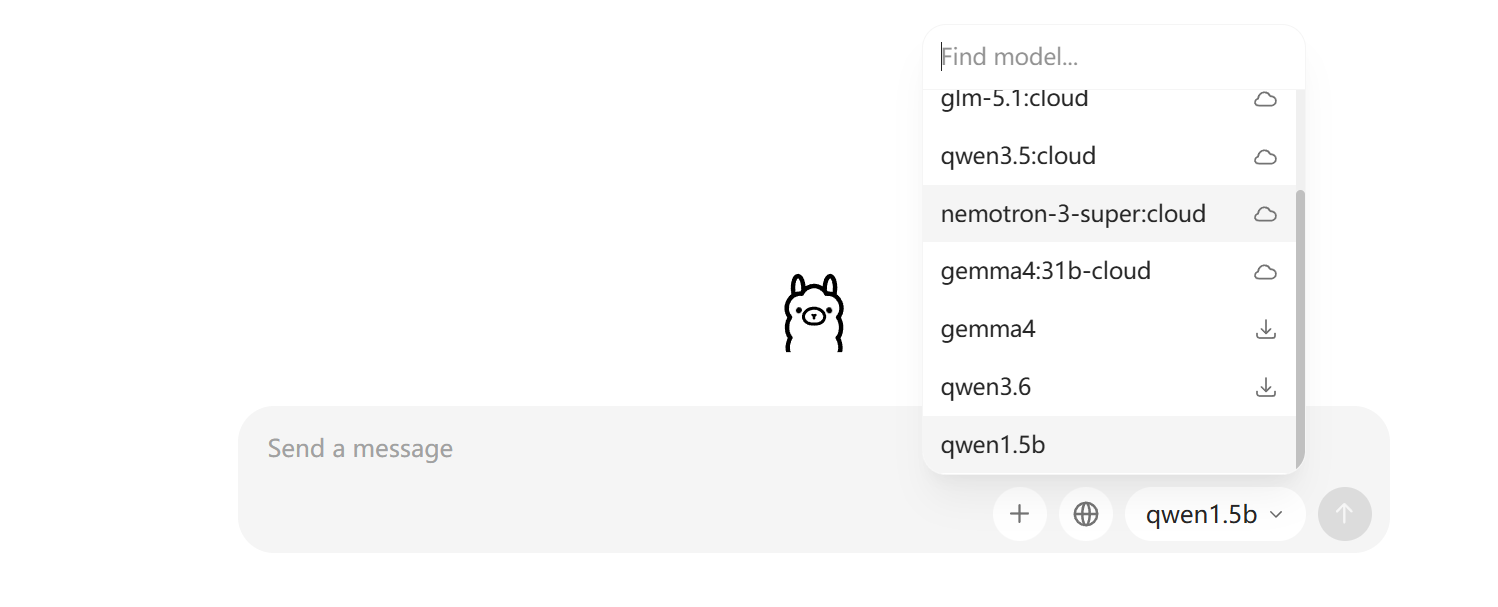
列表中应该会出现你刚刚创建的 my-custom-model,如下图(我自己下载的是qwen1.5b)

接下来,直接启动并与它对话:
ollama run my-custom-model
如下图:

进入对话界面后,此时你会看到终端里出现了一个可输入的聊天光标 >>>
试着输入“你好”,如果它能正常回你,说明大模型在你的笔记本上完全跑通了!
按 Ctrl + D 可以退出当前聊天。
同时可以在ollama图形化界面中选取自己的模型,进行图形化界面的对话:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)