开源项目推荐:五个AI与多媒体处理工具
开源项目推荐:五个AI与多媒体处理工具
本文介绍五个开源项目,分别涉及测试工作流、多媒体处理、OCR识别、语音转写和声纹识别领域。
1. TestSpec:结构化测试工作流工具
项目地址: https://github.com/mxr-vector/TestSpec
TestSpec是一个CLI工具,帮助QA团队通过结构化工作流创建、管理和跟踪测试工件。它集成了Claude Code、Qoder、Codex、Trae等多种AI代理。
核心功能
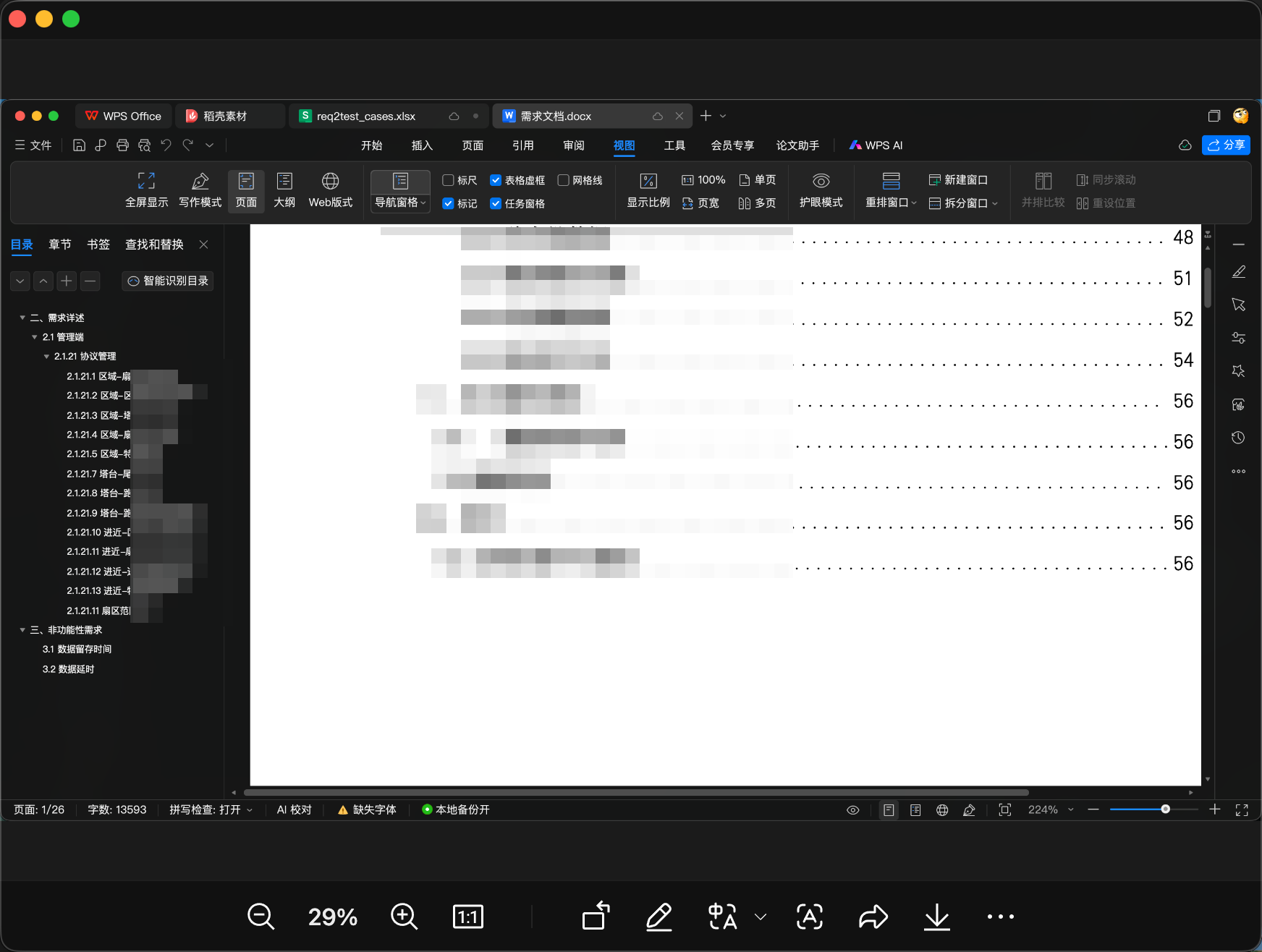
结构化工作流:TestSpec遵循从需求到测试用例的成熟测试设计流程,支持完整的测试生命周期管理。从需求分析、测试点生成到测试用例创建,每个步骤都有明确的指导和验证机制。
AI集成:项目支持多种AI代理集成,包括Claude Code、Qoder、Codex、Trae等。这些集成使得AI能够读取需求文档并生成语义工件,而CLI负责验证、导出、报告和归档等确定性任务。
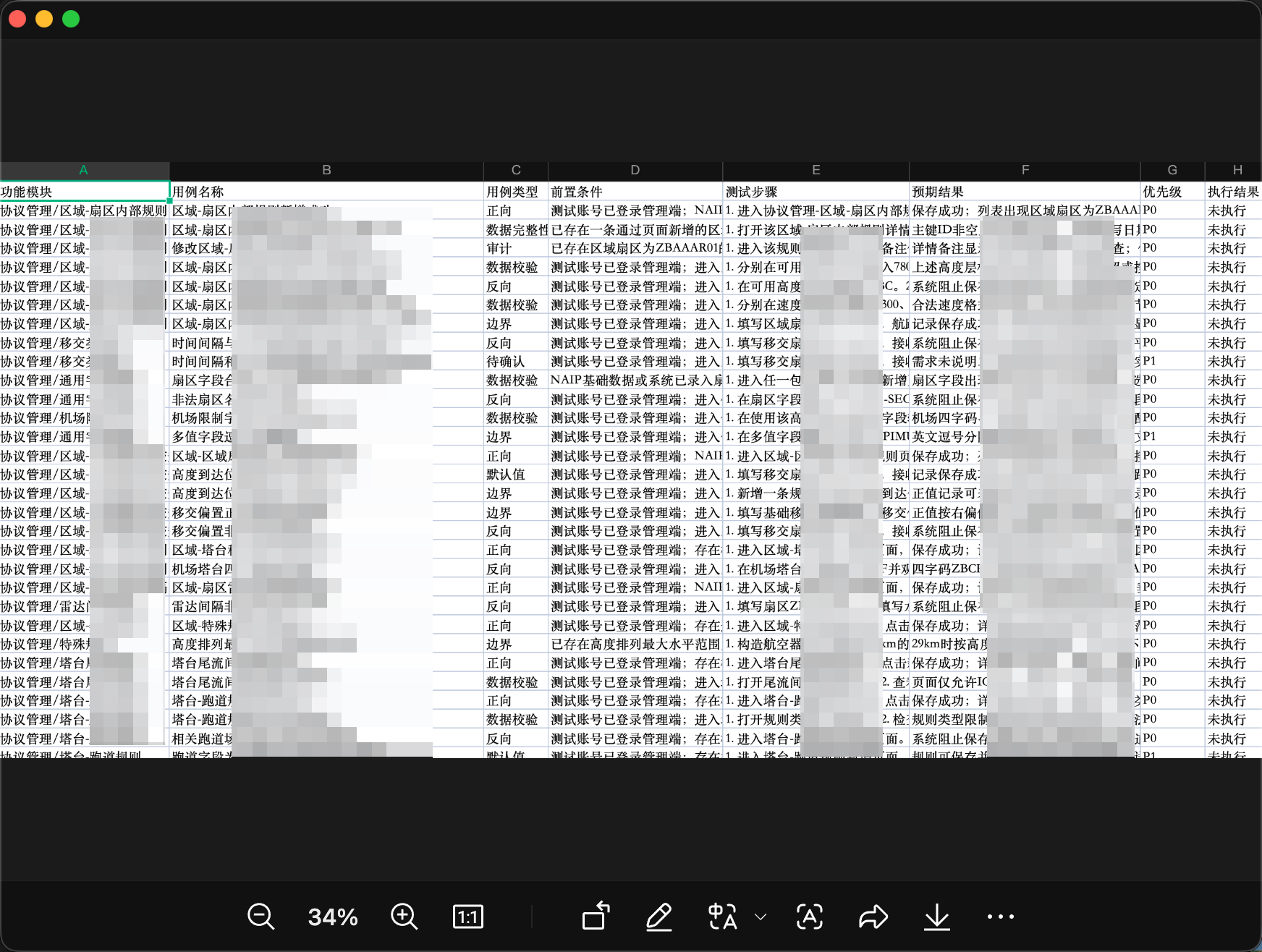
Excel导出:TestSpec可以生成包含功能测试和性能测试工作表的可执行测试用例。功能测试工作表包含步骤、预期结果、优先级和执行状态;性能测试工作表则包含基线目标、指标和执行状态。
思维导图导出:项目支持创建可视化测试用例图,便于团队评审和协作。
可追溯性:TestSpec维护需求、测试点和测试用例之间的完整关联,确保每个测试用例都能追溯到具体的需求来源。
归档系统:项目提供完整的归档系统,用于组织和保存已完成的测试周期,便于后续参考和审计。
使用场景
- 复杂系统的需求验证和测试设计
- 需要AI辅助的测试用例生成
- 团队协作的测试评审和反馈
- 测试周期的完整记录和追溯
实际效果

2. mediamtx-clients-ts:多媒体流处理客户端
项目地址: https://github.com/mxr-vector/mediamtx-clients-ts
mediamtx-clients-ts是一个基于Vue 3 + Vite + TypeScript的MediaMTX浏览器读流示例,用于验证RTSP/RTMP等源经MediaMTX转换后是否能在浏览器中稳定播放。
核心功能
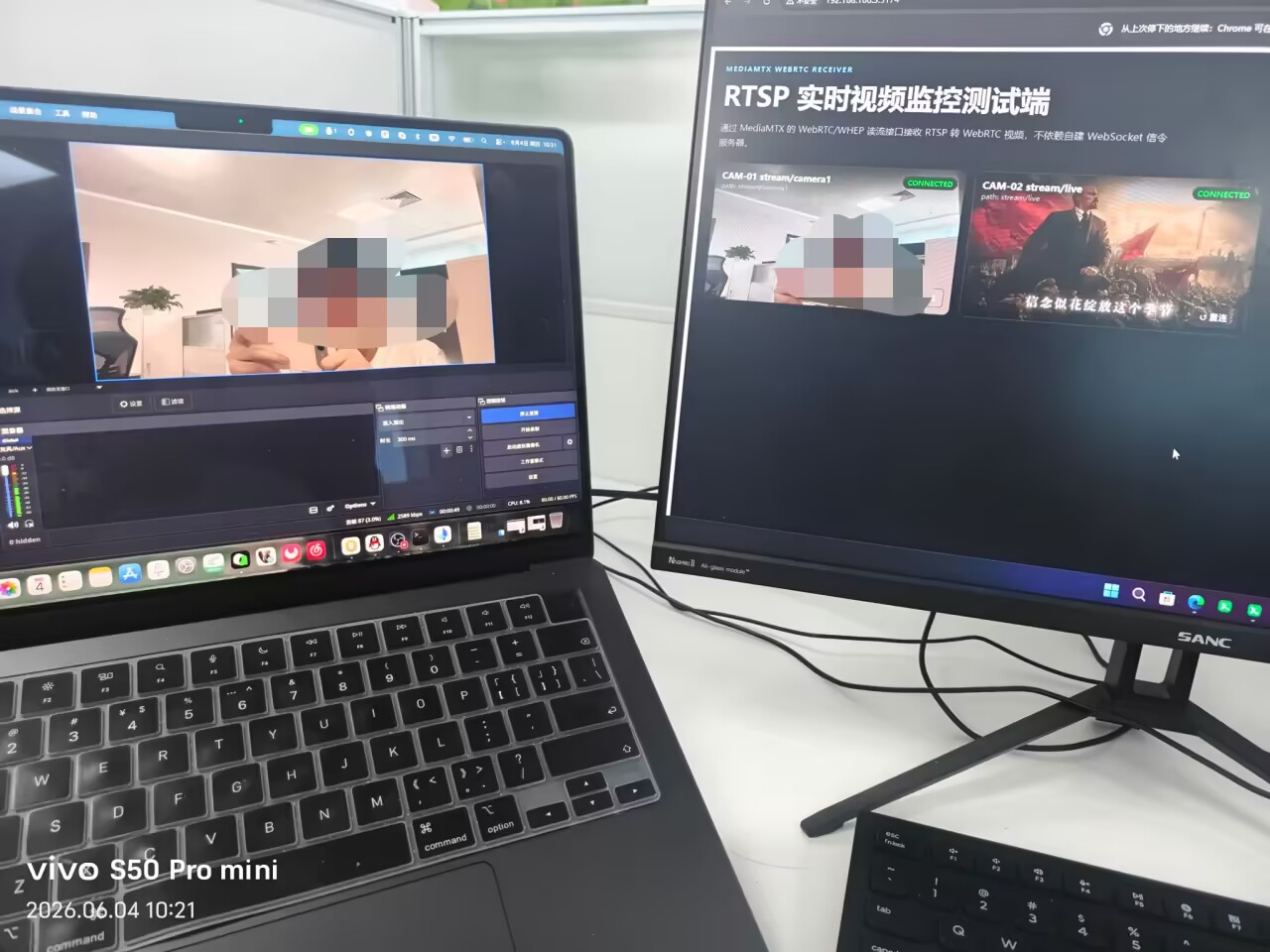
WebRTC/WHEP支持:项目实现了浏览器直接向MediaMTX /{path}/whep发起SDP offer/answer协商的功能,并将收到的MediaStream绑定到"video"元素。这种方式不需要自建WebSocket/Socket.io信令服务。
QUIC/MoQ支持:项目支持MediaMTX v1.19.0+的MoQ(Media-over-QUIC)浏览器读流。浏览器通过WebTransport连接MediaMTX /{path}/moq,再用WebCodecs解码并渲染到canvas。
多路流展示:支持多路stream path同屏展示,适合监控、视频会议等需要同时查看多个视频源的场景。
ICE/TURN配置:支持WebRTC STUN/TURN配置,TURN可按off/fallback/include控制成本,适应不同的网络环境。
自动资源管理:页面可切换WebRTC/WHEP与QUIC/MoQ,切换时自动卸载接收器并释放连接资源。组件卸载时自动清理RTCPeerConnection、媒体轨道、WebTransport、WebCodecs和渲染资源。
技术特点
- 使用TypeScript实现
- 采用Vue 3 Composition API
- 支持环境变量配置
- 提供文档和示例代码
使用场景
- 实时视频监控系统
- 视频会议和直播平台
- 多媒体内容分发网络
- 需要低延迟视频传输的应用
实际效果
3. RapidOCR-API:智能OCR识别服务
项目地址: https://github.com/mxr-vector/RapidOCR-API
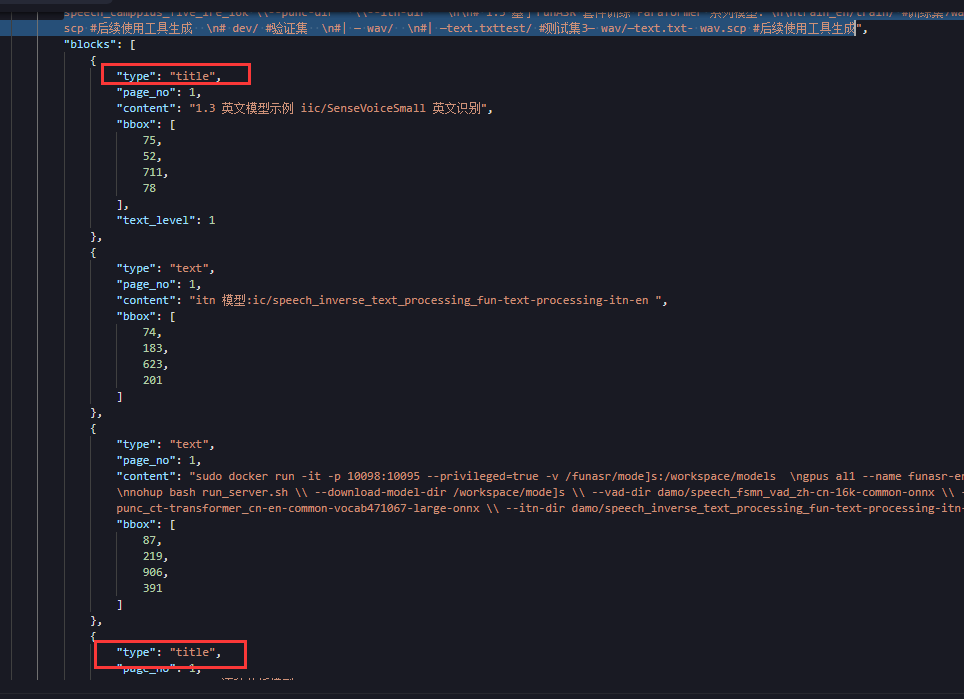
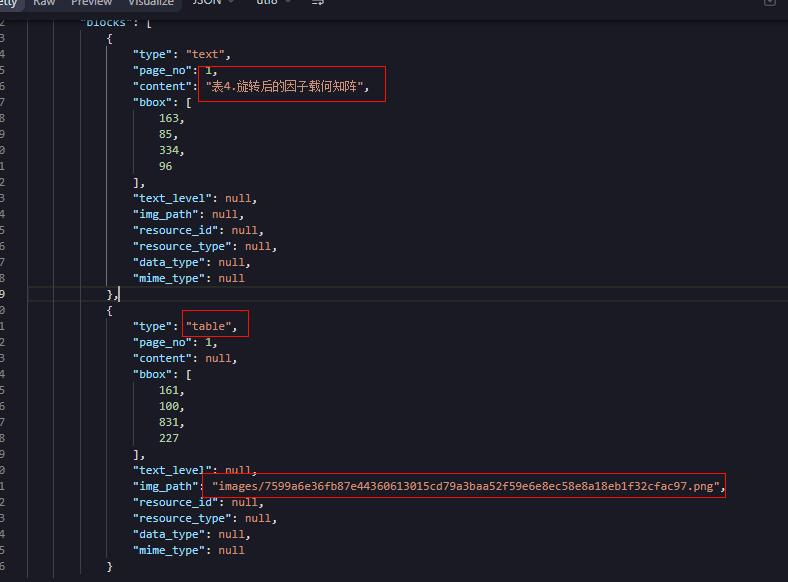
RapidOCR-API是将RapidOCR库做API封装的项目,采用FastAPI + uvicorn实现。它提供了快速调用RapidOCR的API接口,支持PDF光学扫描、图像识别、排版提取与恢复、公式提取等功能。
核心功能
PDF光学扫描:项目支持从PDF文档中提取文本内容,包括扫描版PDF的识别。PDF识别采用异步任务机制,上传后立即返回task_id,后台处理完成后可通过任务ID查询结果。
图像识别:支持多种图像格式的文字识别,包括普通图片和base64编码的图片。识别结果包含文本内容、文本框坐标和置信度。
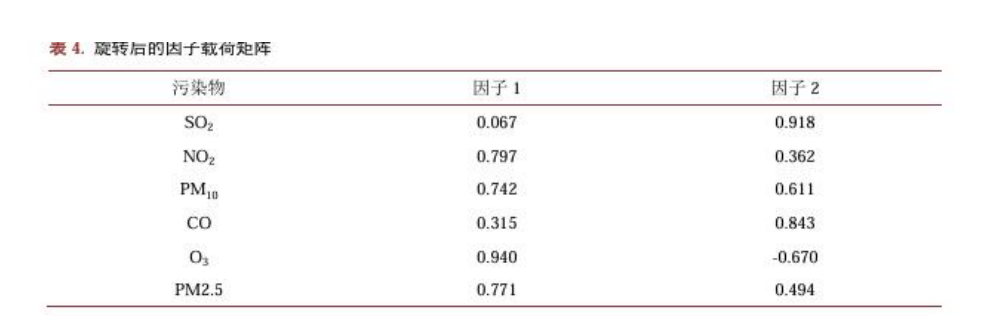
排版提取与恢复:当设置is_markdown=true时,项目能够保留逐行识别结果,并额外返回Markdown和精简结构化块字段。
公式提取:项目支持数学公式的识别和提取,基于RapidDoc模型实现。
异步任务管理:PDF处理采用异步任务机制,支持任务状态查询、结果获取和错误处理。任务状态包括pending、running、succeeded、failed。
技术架构
- 基于FastAPI框架,提供RESTful API接口
- 支持CPU和GPU环境,可选择性安装onnxruntime或onnxruntime-gpu
- 使用RapidOCR和RapidDoc模型
- 提供配置选项,包括上传限制、PDF渲染参数、存储路径等
使用场景
- 文档数字化和归档
- 学术文献的自动处理
- 企业文档的智能分析
- 需要保持文档格式的OCR处理
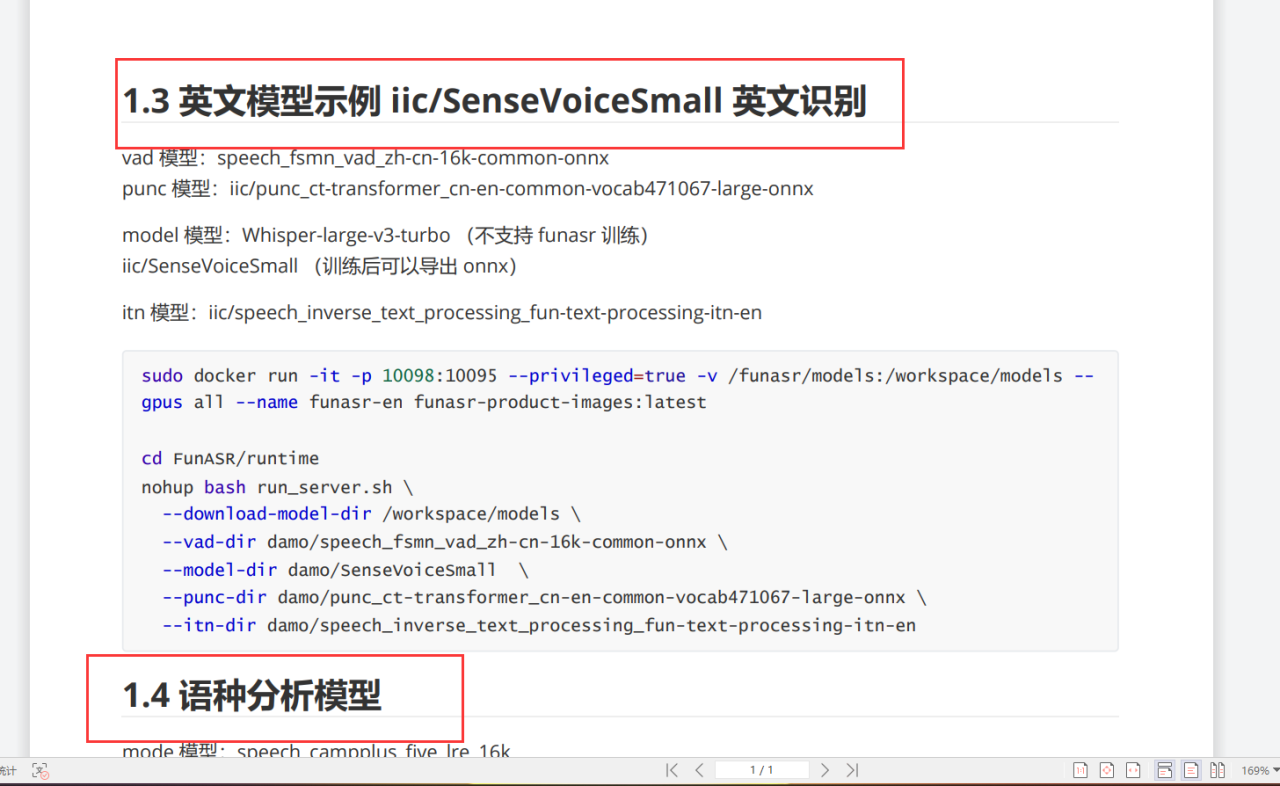
实际效果
4. Qwen3-ASR-GGUF:高效语音转写工具
项目地址: https://github.com/mxr-vector/Qwen3-ASR-GGUF
Qwen3-ASR-GGUF将Qwen3-ASR模型转换为可本地高效运行的混合格式,实现快速、准确的离线语音识别。项目主要依赖llama.cpp加速LLM Decoder。
核心功能
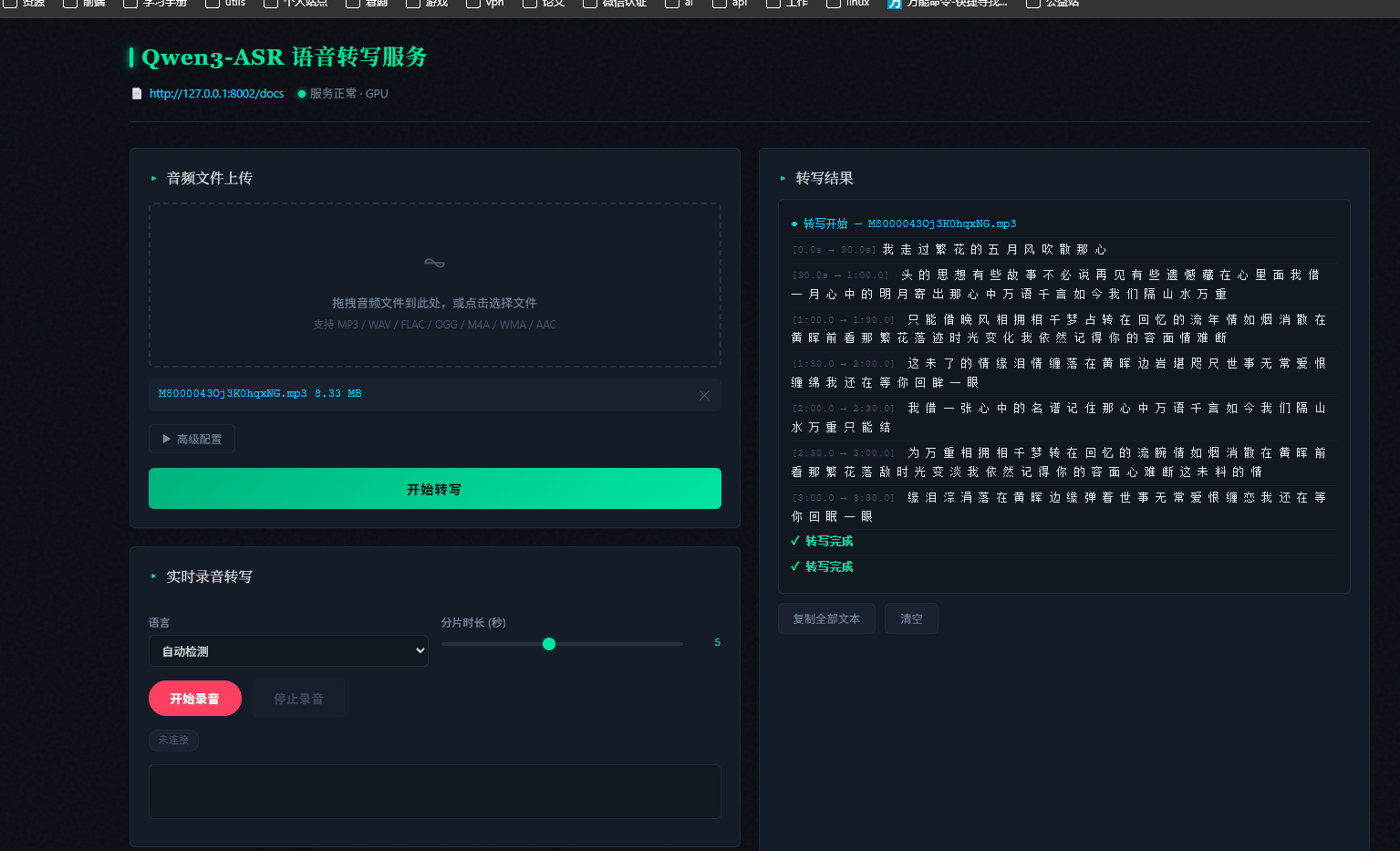
CPU实时转写:项目在CPU环境下实现毫秒级录音实时转写。在RTX 5050笔记本上的实测数据显示,50秒中文音频的总处理耗时仅需2.59秒,实时率(RTF)为0.052。
超大音频文件处理:支持1小时以上超大音频文件的转写,采用流式处理机制,避免内存溢出问题。
幻觉率降低:通过VAD(语音活动检测)和上下文增强技术降低语音转写过程中的幻觉率。VAD可减少静音段推理,上下文增强可提供背景信息。
字幕输出:支持ForceAligner对齐字级时间戳,输出SRT/JSON格式的字幕文件。
GPU加速:支持Vulkan/CUDA/ROCm/DirectML等多种GPU加速方案,可根据硬件环境选择最优配置。
技术特点
- 采用混合推理架构(ONNX Encoder + GGUF Decoder)
- 支持多种量化精度(FP16/INT8/INT4)
- 提供性能统计,包括编码等待、对齐总时、LLM预填充和生成时间
- 支持Web API和命令行工具两种使用方式
使用场景
- 会议记录和语音备忘录
- 视频字幕自动生成
- 语音内容分析和检索
- 需要离线处理的语音识别场景
实际效果
5. mxr-voiceprint-recognition-pytorch:声纹识别系统
项目地址: https://github.com/mxr-vector/mxr-voiceprint-recognition-pytorch
paper.md: https://github.com/mxr-vector/mxr-voiceprint-recognition-pytorch/blob/develop/paper.md
mxr-voiceprint-recognition-pytorch是一个基于Pytorch的声纹识别系统,包含声纹识别、声音意图识别、声学时序检测和语言强制对齐评分功能。
核心功能
声纹识别:项目支持多种声纹识别模型,包括EcapaTdnn、ResNetSE、ERes2Net、CAM++等。在CN-Celeb数据集上的测试显示,ERes2NetV2模型的EER(等错误率)为0.08071。
声音意图识别:基于qwen3-embedding-4b实现声音意图识别,能够从语音中提取语义信息。
声学时序检测:支持基于声学特征和CTC强制对齐的音频组件识别,用于省略检测。
语言强制对齐评分:提供语言强制对齐功能,能够评估语音与文本的匹配程度。
多种预处理方法:支持MelSpectrogram、Spectrogram、MFCC、Fbank、Wav2vec2.0、WavLM等多种数据预处理方法,可根据不同场景选择最优方案。
技术特点
- 支持多种损失函数,包括AAMLoss、SphereFace2、AMLoss、ARMLoss、CELoss等
- 提供性能对比实验数据
- 支持单GPU和多GPU训练
- 提供Web服务接口
使用场景
- 身份验证和安全访问控制
- 智能客服和语音助手
- 语音内容分析和检索
- 语音质量评估和教学
实际效果
内容过多,详见webapi体验
总结
以上五个开源项目分别覆盖了测试工作流、多媒体处理、OCR识别、语音转写和声纹识别领域。TestSpec提供结构化的测试工作流管理;mediamtx-clients-ts实现了浏览器端的多媒体流接收;RapidOCR-API封装了文档识别和排版恢复功能;Qwen3-ASR-GGUF提供了离线语音转写能力;mxr-voiceprint-recognition-pytorch实现了声纹识别和相关语音分析功能。
开发者可根据项目需求选择合适的工具。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)