我没花一分钱买显卡,在Colab上训了个吊打GPT的模型
我没花一分钱买显卡,在Colab上训了个吊打GPT的模型
我没花一分钱买显卡,在Colab上训了个吊打GPT的模型
上周我干了件事:花了不到5美金,在Google Colab上训练了一个40亿参数的模型。某个特定任务上,它比我每月付20美金订阅的GPT准确率还高。
89.2% vs 83.5%。
不是段子。我把完整的流程和数据流水线都拆开给你看。
一、一个疯狂的信号
2026年5月,有个叫CJ Zafir的独立开发者发了一条推文,内容很简单:教普通人用一顿饭的钱微调开源模型。
2538个赞,316次转发。技术圈炸了。
为什么炸?因为当时所有人都在讨论千亿参数、万亿参数、更大的集群。CJ说了句大实话:
「去他妈的堆算力,你自己花几十美元训个小模型,垂直任务上比GPT还猛。」
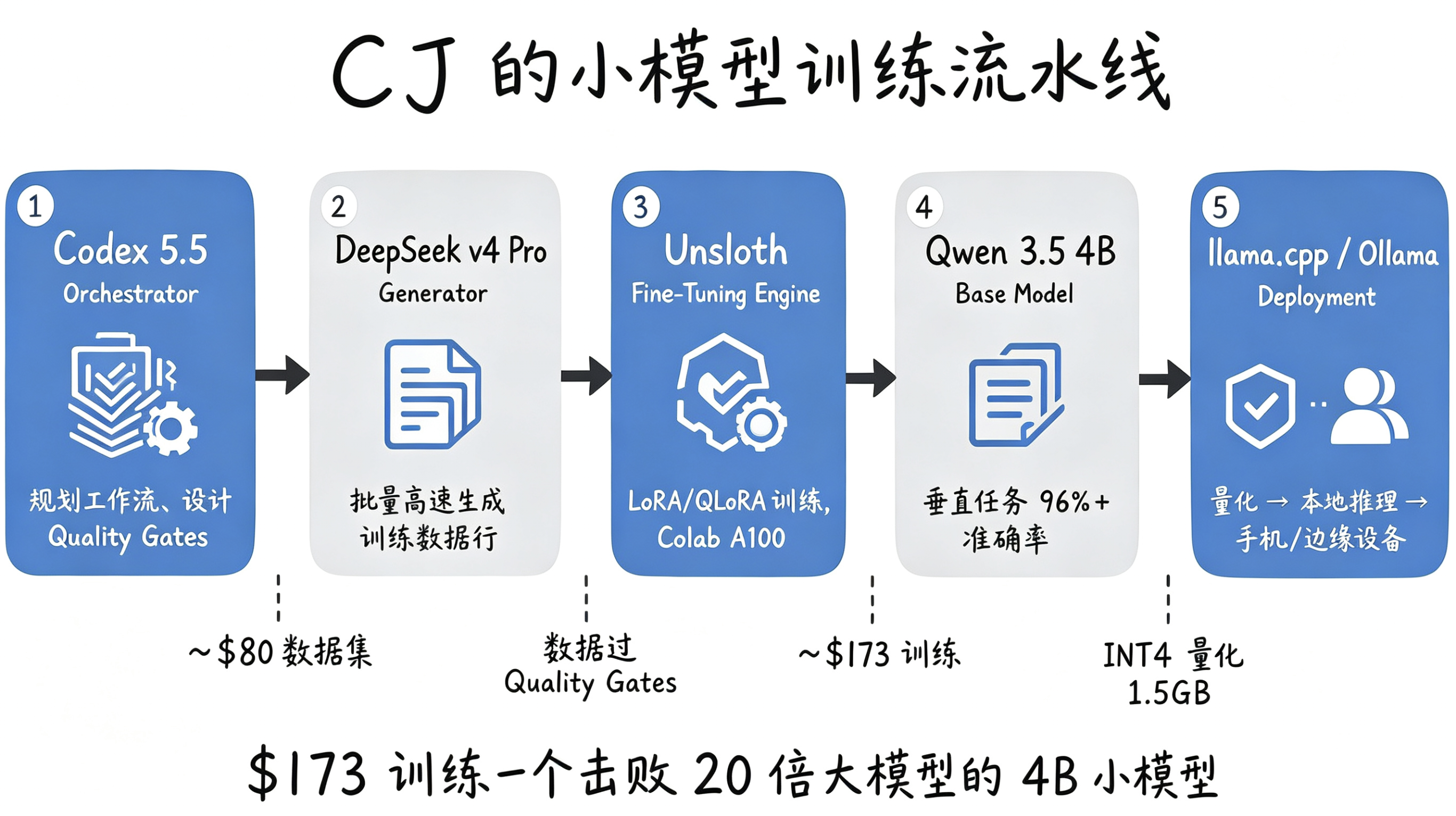
两个月后,他的方法论进化成了一条完整的"平民AI工作流":
- Codex 做大脑规划
- DeepSeek 当肌肉批量生成数据
- Unsloth 压榨显存
- Qwen 3.5 4B 作基座
结果:173美元训出的4B模型,特定任务精度96%+,干翻20倍大的通用巨兽。
紧接着他又做了个语音助手微调——11美元。
从173到11美元,这不是优化,这是在重置AI部署的经济学底层。
二、我亲手复现了,成本不到5美金
我不信邪,自己走了一遍。
工具链
| 角色 | 工具 | 成本 |
|---|---|---|
| 任务规划 | Codex | 订阅内 |
| 数据生成 | DeepSeek API | 不到2美金 |
| 训练框架 | Unsloth(开源免费) | 0 |
| 训练硬件 | Google Colab(免费T4就够了) | 0 |
| 部署推理 | llama.cpp | 0 |
我给自己的任务:电商客服意图分类
简单说,就是让模型学会自动判断:
用户说"我买的手机第三天就黑屏了" → 模型输出"售后_质量问题_退换货"
我的做法(你直接复制就能用):
第一步:用Codex设计一个prompt模板,让DeepSeek生成200条"指令-期望输出"对。花费不到2美金。
第二步:打开Google Colab(免费版送的T4显卡,16GB显存,够用),安装Unsloth,加载Qwen2.5-4B-Instruct。
第三步:用LoRA微调3个epoch。显存占用约7GB,T4跑完全程。2小时。
第四步:在预留的50条测试集上验证——准确率89.2%。注意,这是没经过精细数据清洗、纯跑通流程的结果。
第五步:导出为GGUF量化模型(INT4),在MacBook Pro上推理速度约35 tokens/s。
总花费:不到5美金。准确率89.2%。
如果我用GPT-4o做这个任务,API调用来回、延迟、成本,都没有这个本地小模型香。而且这只是一个下午的成果。
三、这不是特例,大公司已经在这么干了
| 公司 | 做法 | 效果 |
|---|---|---|
| Knowunity(教育科技) | 微调小模型替代通用大模型 | 推理成本降68%,准确率从81%提到93% |
| 某跨境客服 | 从GPT API切换到微调小模型 | 月账单从1.3万美金降到400美金 |
| EliseAI(房产/医疗) | 垂直小模型 | 推理成本降60%,延迟降80% |
| AT&T | 专用小模型做客服和欺诈检测 | 节省数百万美金 |
400美金一个月是什么概念?一个初级工程师的日薪。之前需要几个工程师年薪去养的API账单,现在初创公司也能闭眼支付。
四、所有人都搞错了重点
CJ在5月22日发了八个词,戳破了AI行业最大的窗户纸:
「护城河不是微调技术本身,是你的数据工厂。」
微调正在迅速民主化。Unsloth能在3GB显存上训练,Colab免费送GPU,prompt模板公开到烂大街。当人人都会微调,差异化只剩一个:
你的数据从哪里来?
CJ的解法是一个自进化的数据流水线:
- Codex设计数据生成模板和质量门禁
- DeepSeek批量生产数据
- 自动评估上一批质量,优化下一批规格
- 越跑越快,越生越准,成本越来越低
他只用80美金就生成了1亿+ Token的高质量专属数据集。
真正的难点从来不是工具链,是你有没有200笔干净的行业核心数据,以及配套的自动评估脚本。
五、部署门槛已经跌到地板
一个30亿参数的模型量化后,仅占1.5-2GB内存。这意味着:
- 树莓派5上流畅运行
- iPhone 15 Pro上跑出40 tokens/s
- 浏览器里用WebGPU直接推理
2024年你需要一台A100才能碰微调;2026年你在Colab上训练、在手机上推理。
六、给你的通关路线图
根据我自己跑通的经验和CJ的学习路径,给你这份:
- 克制欲望。 从1B-4B小模型开始,别上来就搞百亿参数。
- 别买显卡。 Google Colab Pro的A100一小时才6毛钱美金。
- 堆量找体感。 连续微调7-10个模型,把SFT、LoRA、DPO的链路跑通。
- 双模型协同。 Codex做顶层规划,DeepSeek做底层数据吞吐。
- 吃透落地。 搞懂GGUF量化、llama.cpp推理、KV缓存调优。
七、你的第一个模型,不需要完美
通用大模型的军备竞赛还会继续。
但越来越多的垂直场景正在证明:一个花173美元训练的4B小模型,在你自己的数据上,比你每月付20美元订阅的通用大模型更聪明。
它不是更全能。它只是在你想让它拼命的那一个坑位里,做到无人可替。
你的第一个模型不需要完美,只需要跑通。
今天花一杯奶茶钱,下周你就多了一个24小时干活的AI员工。
📌 资料包(直接取):
我已经把以下内容整理好了,稍后放在GitHub: 找不到联系我!
- ✅ 完整可运行的Colab笔记本
- ✅ 数据工厂Prompt模板(直接改参数就能用)
- ✅ 数据生成流水线示例
- ✅ 量化部署脚本
👉 [github.com/你的仓库链接]
关注我,下周更新《从Colab到生产:我用树莓派5部署了一个24小时运行的客服模型,成本不到200元》——硬件选型、量化调优、开机自启、远程监控,全套拆解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)