为什么你的 AI 写出来总像废话?问题不在提示词
今天来聊一个稍微深度一些的话题,你可能已经遇到过这种情况:
让 AI 分析一个行业,它能给你列出一堆趋势;让 AI 评价一个产品,它一定能说出优势、风险和建议;让 AI 写一篇文章,它也能给出结构完整、表达顺滑的内容。
问题是,读完之后你的内心毫无波动。
它没有说错,但也没有真正说出什么有意义的东西。它像一个永远礼貌、永远稳妥、永远站在平均线上说话的人。你得不到判断,只得到一份看起来很完整的整理。
“听君一席话,如听一席话”。

最近我看很多公众号文章都有这种感觉:不是明显的 AI 味,也不说满屏“稳稳地接住你”这种词,但就是读完没留下任何东西。它们最大的问题不是错,但总是给人一种看了等于没看的即视感。整体结构是完整的,实际上却没有一个地方真的改变了你的理解。
当然,这其实不是你的提示词写得不够好,也不是说你的模型差。更根本的问题是:现在的模型逻辑里,AI 默认会回到共识,而深度通常来自非共识。
有人给出了一个很关键的判断:当模型能力跨过某个门槛后,决定 AI 产出质量的主要变量,不再只是模型本身,而是你给它的 Context(上下文)密度。
这篇文章不只讲观点,也给一套可以马上开始的使用方法。
一、AI 为什么天然容易说“正确的废话”
LLM(大语言模型)的训练目标,本质上是预测下一个最可能出现的词。
“最可能”意味着什么?意味着它倾向于输出更多人会接受的表达。它会尽量全面、平衡、安全、无争议。再加上 RLHF(基于人类反馈的强化学习)会进一步奖励礼貌、稳妥、低风险的回答,AI 的默认性格就被塑造成了一个“共识机器”。
共识不是坏东西。
如果你完全不了解一个领域,靠着 AI 可以快速把你带到这个领域的平均水平。它能帮你补齐背景知识,列出常见框架,整理已有资料,避免一些低级错误。
但如果你已经在某个领域有经验,问题就出现了:平均水平不再够用。
你要的不是“大家都怎么说”,因为大家都这么说,而是“这件事真正重要的变量是什么”。你要的不是十条风险清单,而是哪一条风险会决定成败。你要的不是信息覆盖,而是判断优先级。
信息从来不稀缺,稀缺的是判断信息的能力。互联网每天生产的垃圾比有用的东西多得多,而有了 AI 的结果让筛选成本不降反升——因为垃圾好像也变得更像模像样了。
很多所谓 Deep Research,其实只是 Wide Research。
它扩大了信息覆盖面,但没有真正形成认知优势。它解决的是“我不知道这些信息”的问题,却没有解决“我应该如何判断这些信息”的问题。
真正的深度不是资料更多,而是筛选资料的标准更清楚。
同样一份行业报告,新手看到的是数据,老手看到的是异常;新手看到的是增长率,老手会追问增长来自渠道红利、产品结构变化,还是统计口径改变。差距不在信息本身,而在判断系统。

AI 缺的正是这个判断系统。
二、模型越强,越要重视 Context
过去我们优化 AI 的第一反应通常是:
- 换更强的模型;
- 写更复杂的提示词;
- 加更多工具;
- 让多个 Agent 分工协作。
这些方法当然有用,但它们都在优化同一个维度:模型能力。
问题是,模型能力正在变成一种越来越容易获得的公共资源。你能用 GPT、Claude、Gemini,别人也能用。模型升级会让所有人同时变强,但不会自动让你变得更独特。
真正稀缺的是你的个人上下文。
你过去做过什么判断,哪些判断后来被验证了,哪些判断错了;你更在意速度还是稳定,更在意表达锋利还是安全,更愿意押注结构变化还是短期机会;你在某个行业里反复踩过哪些坑,形成过哪些直觉。
这些东西不是说模型升级了就会自动进入 AI 了。
它们只存在于你的经历、笔记、对话、会议记录、复盘和一次次纠正 AI 的过程中。如果不被系统性记录,它们就会散掉,下次重头再来。
这就是 Context Infrastructure 的核心思想:
不要只把 AI 当成一个更聪明的问答工具,而要把它接入你的长期判断系统。
模型像 CPU,个人上下文像内存。CPU 足够快之后,很多任务的瓶颈不再是算力,而是内存里有没有真正有价值的数据结构。
AI 也是一样。
当模型已经足够聪明,你还只给它几句话背景,它就只能回到训练数据里的平均判断。你要它说出更接近你的判断,就必须把你的判断依据、偏好、原则和历史经验持续提供给它。
换句话说:提示词决定 AI 这一次怎么回答你,Context 决定 AI 长期怎么理解你。 大多数人还在优化前者,少数人已经在建设后者。
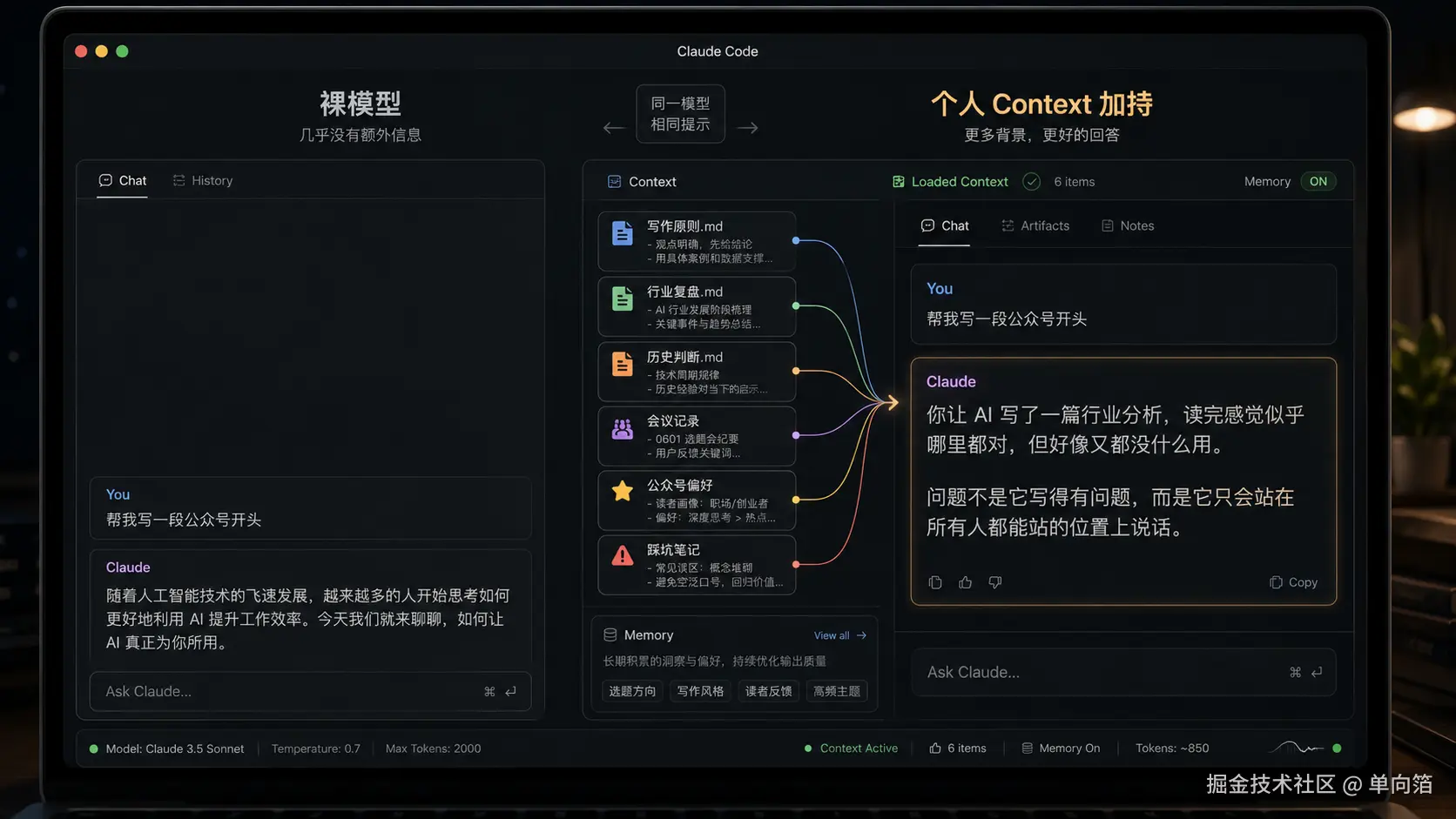
举个例子。同样一句"帮我写一段公众号开头":
裸模型输出:
随着人工智能技术的飞速发展,越来越多的人开始思考如何更好地利用 AI 提升工作效率。今天我们就来聊聊,如何让 AI 真正为你所用。
有个人 Context 的输出:
你让 AI 写了一篇行业分析,读完感觉似乎哪里都对,但好像又都没什么用。问题不是它写得有问题,而是它只会站在所有人都能站的位置上说话。
前者是训练数据里的平均开头,后者是基于"我讨厌泛化背景、要求直接进入具体矛盾"这条个人原则生成的。这个例子可能举得没有那么恰当,但我主要是想表达我的想法:模型一样的情况下,差距是会体现在 Context 里的。
三、别人的 Context 不能直接变成你的深度
最近我看到了 grapeot/context-infrastructure 这个项目,觉得还算有意思。它不是又一个“神奇提示词合集”,而是一个把个人判断、经验、偏好、失败教训持续沉淀进 AI 工作流的系统样本。
但这个项目容易被误解。
很多人看到开源项目,第一反应是 clone 下来直接用。
当然可以用,但不能替代你。
它的价值不是里面有几十条公理可以直接复制,而是它展示了一个运行了一年的个人上下文系统长什么样。你可以参考目录结构、记忆分层、技能组织方式、定时任务设计,但不能把作者的判断原则当成自己的判断原则。
因为深度不是格式,深度来自经历被反复压缩之后形成的偏见。
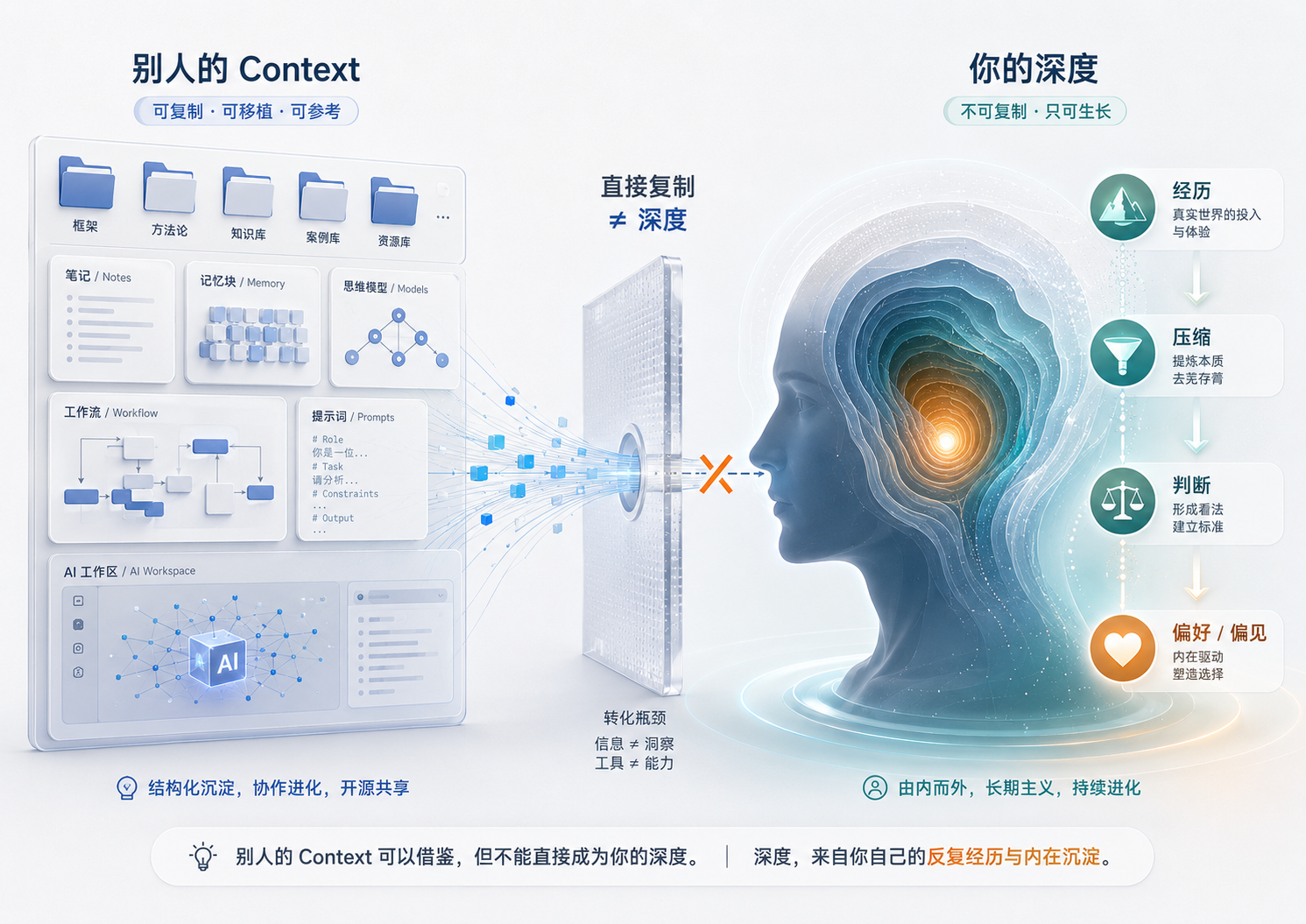
这里的“偏见”不是贬义词。每个真正有“判断力的人类”都会有偏见:偏好什么,讨厌什么,优先相信什么,默认怀疑什么,遇到复杂问题时先看哪个变量。
没有偏见的人,看起来客观,实际上很平庸。
AI 默认追求无偏,结果就是安全但无趣。你要让 AI 变深刻,就要把高质量的偏见注入进去:经过长期经验验证的偏好、判断标准和取舍逻辑。
这件事不能靠一句提示词完成。
比如你对 AI 说:“要写得有深度一点。”它并不知道你所谓的深度是什么。究竟是观点更尖锐、案例更具体、推理链更完整呢?还是能指出行业里大多数人不愿意承认的矛盾?
如果你没有把自己的标准写下来,AI 只能调用大众语料里的“深度感”:多用一堆抽象词,多像模像样地列几个维度,再搞几句辩证表达显得好像有思考。于是文章看起来更成熟,但仍然没有真正的判断。
怎么用这个项目:当蓝图,不当答案
grapeot/context-infrastructure 的正确打开方式不是复制,而是拆解。
你可以按这个顺序看:
- 先看
README.md,理解整体目录和三层结构; - 再看
rules/USER.md,把它改成你的个人信息; - 看
rules/COMMUNICATION.md,学习如何把沟通偏好写成规则; - 看
rules/axioms/,理解公理应该长什么样,但不要照抄内容; - 看
rules/skills/,学习如何把某类任务封装成可复用上下文; - 最后再研究
periodic_jobs/ai_heartbeat/,决定是否需要自动化。
如果你只是想快速体验:
git clone https://github.com/grapeot/context-infrastructure
cd context-infrastructure
然后用 Claude Code、Cursor 或 OpenCode 打开这个目录,先让 AI 阅读 AGENTS.md 和 rules/USER.md。
但要注意:这个体验只是让你看到"有上下文的 AI"和"裸模型"的差异,不代表它已经变成了你的 AI。真正属于你的系统,必须从你的原始材料开始积累。
四、一套可执行的 Context Infrastructure 搭建方法
不需要一开始就搭完整系统。
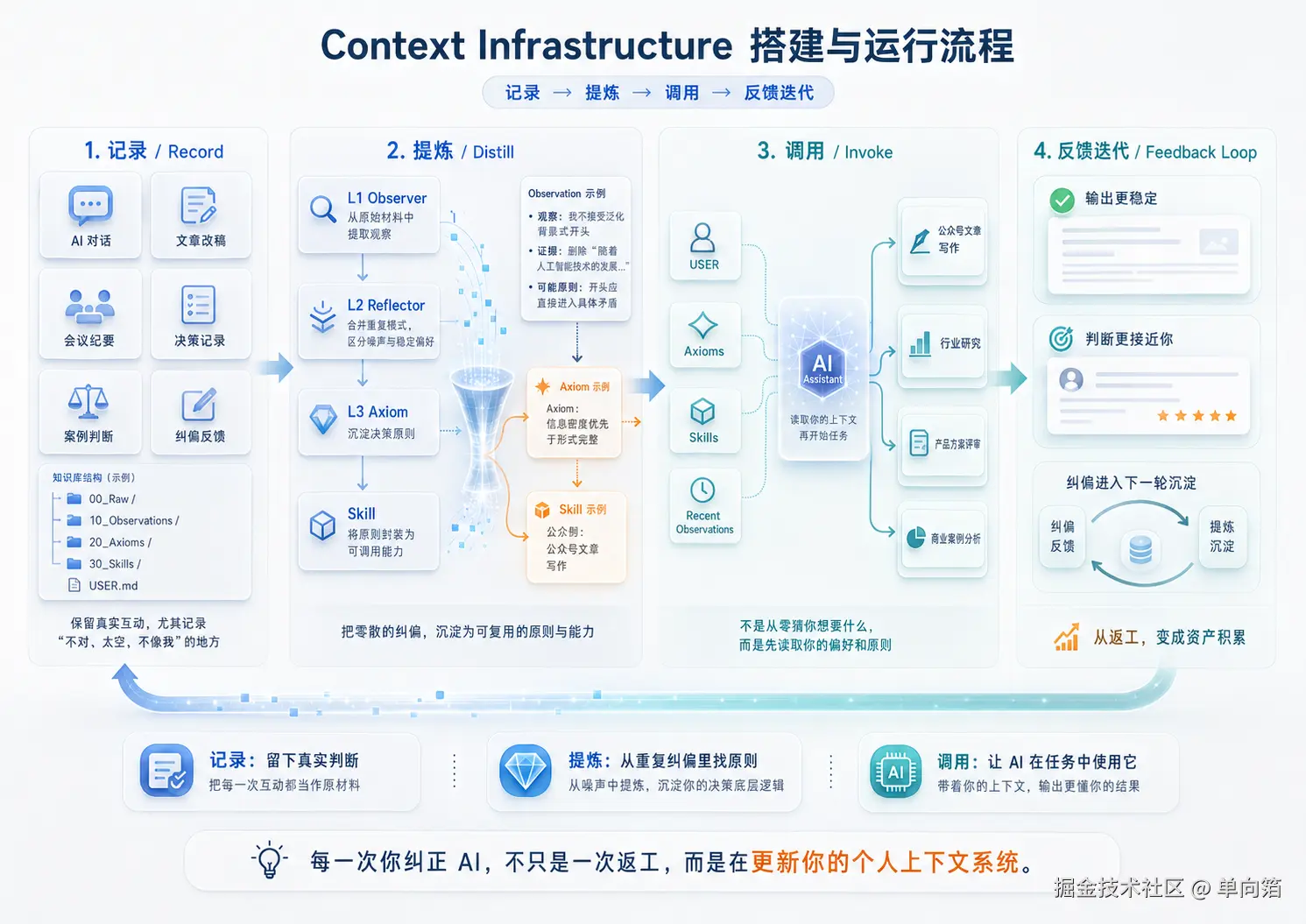
这套东西看起来有点复杂,又是 L1、L2、L3,又是 Axiom、Skill,但本质上其实就三件事:记录、提炼、调用。
记录,是把你和 AI 的真实互动留下来。尤其是你每一次觉得“不对”“太空”“不像我”的地方,这些不是废稿,而是最有价值的原始材料。
提炼,是从这些原始材料里找出稳定模式。一次不满意可能只是情绪,反复出现的不满意,才可能说明你有一个稳定的判断标准。
调用,是把这些判断标准写成 AI 能读懂、能复用的规则。下次你再让它写文章、做分析、改方案,它不是从零开始猜你想要什么,而是先读取你的偏好和原则。
所以后面的 L1 Observer、L2 Reflector、L3 Axiom、Skill,本质上都围绕这三个动作展开:先记录你真实的判断,再提炼成原则,最后让 AI 在具体任务里调用它。
1. 记录:先把你真实的判断留下来
第一步不是写一堆宏大的原则。
很多人一上来就想写“我的价值观”“我的写作风格”“我的判断体系”,最后很容易写成口号。因为人对自己的理解,很多时候是不准的。
你以为自己喜欢“有深度”,但到底什么叫有深度?
是观点更尖锐?是案例更具体?是推理更完整?还是能指出一个大多数人忽略的矛盾?
如果这些东西只靠你凭空总结,很容易写虚。
更靠谱的方法,是先记录真实材料。
如果你用 Obsidian,可以先建一个很小的目录:
AI-Context/
├── 00_Raw/ # 原始材料:对话、会议、文章摘录、决策记录
├── 10_Observations/ # 从原始材料中提取的观察
├── 20_Axioms/ # 稳定判断原则
├── 30_Skills/ # 按任务封装的使用说明
└── USER.md # 你的基本信息、偏好、禁忌和长期目标
不用一开始就追求完整。第一天只要先写一个 USER.md 就够了。
可以这样写:
# USER
## 我是谁
- 职业/领域:
- 当前最重要的项目:
- 长期关注的问题:
## 我的偏好
- 我喜欢直接、有判断力的回答,不喜欢泛泛而谈。
- 我希望文章先给核心判断,再给论证和方法。
- 我更在意结构清楚和观点有效,不追求辞藻华丽。
## 我的禁忌
- 不要写“随着时代发展”这类空话。
- 不要用没有信息量的排比。
- 没有验证的信息要明确标注不确定。
## 我当前最常使用 AI 做什么
- 写公众号文章
- 做行业资料整理
- 设计产品和内容选题
这一步的作用,是先给 AI 一个稳定的底座。
但真正重要的不是这个文件本身,而是你后面持续往里面补东西。
你可以先收集这些材料:
- 你和 AI 的高质量对话;
- 你纠正 AI 的记录;
- 你对某篇文章、某个产品、某个商业案例的判断;
- 会议纪要和项目复盘;
- 你做选择时的理由;
- 你后来发现自己判断错了的案例。
这里最关键的一类材料,是你对 AI 的纠正。
比如 AI 写了一段:
随着人工智能技术的快速发展,越来越多的人开始关注 AI 在工作和生活中的应用。
你觉得很空,把它删掉了。
这时候不要只删掉。你要顺手记一条观察:
- 观察:我不接受泛化背景式开头。
- 证据:我删除了“随着人工智能技术的快速发展……”这类句子。
- 可能原则:文章开头应该直接进入具体矛盾,而不是交代所有人都知道的背景。
- 置信度:中
这就是最早期的 Observation(观察)。
它还不是原则,只是一个带证据的记录。
但记录多了以后,你会开始看到自己稳定的判断偏好。
你纠正 AI 的每一次,都是在向自己解释自己。 这些解释积累起来,就是你的判断系统。
2. 提炼:从反复出现的纠偏里找原则
一条观察不值钱。
重复出现的观察,才值钱。
你今天不喜欢一个开头,可能只是当天心情不好;但如果你连续十次删除“随着时代发展”这种句子,那它就不是情绪了,而是一个稳定的判断标准。
所以第二步,是定期提炼。
你可以每周让 AI 读一遍这一周的 Observations,然后问它:
请阅读我本周记录的 Observations,帮我做一次提炼。
要求:
1. 合并重复出现的观察。
2. 找出跨场景反复出现的稳定偏好。
3. 区分一次性情绪和长期判断标准。
4. 提炼出可以写进 Axioms 的候选原则。
5. 每条原则都要保留证据来源,不要凭空总结。
输出格式:
## 本周稳定模式
## 本周一次性噪声
## 候选原则
## 需要继续观察的问题
这里的筛选标准只有一个:稳定性。
比如你可能会发现:
- 你在写文章时讨厌空话;
- 你在做产品方案时也讨厌为了完整而完整的功能;
- 你在开会时也不喜欢绕半天才说重点;
- 你在改 AI 输出时,总是要求先给判断,再给材料。
这些看起来是不同场景里的小毛病,但背后可能有同一个原则:
信息密度优先于形式完整。
如果一段内容不能改变读者理解,即使它表达正确,也应该删除。
这就可以升级成一条 Axiom(公理)。
Axiom 不是事实记录,而是你的决策原则。
事实是:
我不喜欢空话。
公理是:
当一段内容只是在维持结构完整,却没有提供新的判断、证据或方法时,应当删除或压缩。
两者差别很大。
前者只能让 AI 模仿你的语气,后者能让 AI 接近你的判断方式。
建议每条 Axiom 都用固定格式:
# Axiom:信息密度优先于形式完整
## 原则
当一段内容只是在维持结构完整,却没有提供新的判断、证据或方法时,应当删除或压缩。
## 适用场景
- 公众号文章写作
- 产品方案说明
- 行业分析报告
- 对外汇报材料
## 判断标准
- 这段话是否改变了读者对问题的理解?
- 这段话是否提供了新的证据或变量?
- 删除后,文章是否损失关键逻辑?
## 证据来源
- 2026-05-08_AI写作纠偏.md
- 2026-05-08_公众号选题判断.md
## 反例
如果目标是情绪动员或品牌叙事,可以保留少量节奏性表达,但不能替代判断。
这类内容积累到 10 条以后,AI 的输出会开始发生变化。
因为它不再只知道“你喜欢直接一点”,而是知道你为什么要直接,在哪些情况下必须直接,什么时候又可以不直接。
这才是上下文真正有价值的地方。
它不是帮 AI 记住你的个人信息,而是帮 AI 记住你的判断方式。
3. 调用:让 AI 在具体任务里使用这些原则
光有原则还不够。
如果你只是把一堆 Axiom 放在文件夹里,但每次写文章、做分析、改方案时都不让 AI 读取,那这些原则还是死的。
所以第三步,是把原则封装成 Skill(技能)。
Axiom 是原则,Skill 是使用说明。
一个 Skill 对应一类高频任务,比如:
- 公众号文章写作;
- 行业研究;
- 产品方案评审;
- AI 对话复盘;
- 商业案例分析。
以“公众号文章写作”为例,可以这样写:
# Skill:公众号文章写作
## 什么时候使用
当用户要求写公众号文章、选题大纲、文章改稿时使用。
## 核心目标
不是把资料整理完整,而是提出一个能改变读者理解的核心判断。
## 必须遵守的原则
1. 开头直接进入真实问题,不写宏大背景。
2. 每篇文章只能有一个主判断,不要同时讲太多观点。
3. 先解释“为什么多数人会误判”,再给新框架。
4. 方法部分必须具体到用户今天可以执行。
5. 删除正确但没有信息增量的段落。
## 常用结构
1. 读者熟悉的痛点
2. 对痛点的重新解释
3. 底层原因
4. 一个可执行框架
5. 具体操作步骤
6. 最后的判断
## 不要这样写
- 不要用“在这个快速变化的时代”开头。
- 不要只列清单,不给优先级。
- 不要用抽象词替代具体动作。
以后你让 AI 写公众号文章时,不要只说:
帮我写一篇有深度的文章。
这句话太抽象了。AI 不知道你说的“深度”到底是什么。
你应该这样说:
请使用《公众号文章写作》这个 Skill,并参考我的 Axioms,基于以下材料写一篇公众号文章。
要求:
1. 先给一个有判断力的标题。
2. 文章必须解释为什么普通 AI 输出容易停留在共识。
3. 方法部分要具体到我今天可以怎么搭建自己的 Context Infrastructure。
4. 不要写泛泛的趋势判断。
这时 AI 的输出质量会更稳定。
因为它不是在临时猜你想要什么,而是在调用你提前沉淀下来的判断标准。
更重要的是,这套系统不是一次性搭完就结束了。
每次 AI 写得不好,你都可以把这次纠正记录下来:
- 这次 AI 哪里写得不对?
- 我为什么觉得它不对?
- 我希望它按什么标准改?
- 这是不是我反复出现的判断偏好?
如果类似纠正反复出现,就把它升级成 Axiom,或者写进对应 Skill。
这样,每一次不满意都不只是一次返工,而是在更新你的个人上下文系统。
到最后,AI 不只是知道你的语气,而是逐渐知道你怎么判断、怎么取舍、怎么定义一篇文章到底有没有价值。
别人的 AI 是通用助手,你的 AI 是带着你十年经验的合伙人。 差距不在模型,在喂进去的东西。
写在最后
所以如果你今天只想做一件事,不要再去收藏新的提示词。
从下一次纠正 AI 开始,记录你为什么不满意。
不要只写“重写”“不够深”“太 AI 了”,而是写清楚三件事:
- 这段话到底哪里不对?
- 我希望它按什么标准改?
- 这个标准是不是反复出现?
这件事看起来很小,但它才是训练个人 AI 的起点。
因为真正的问题不是 AI 不够聪明,而是它不知道你怎么判断。你不把自己的判断过程记录下来,它就只能永远调用大众语料里的平均答案。
当所有人都能用同样的模型时,真正拉开差距的,不是谁更会写提示词,而是谁更早把自己的判断沉淀下来。
同质化的世界里怎么找寻你自身的不可或缺性?
AI 时代更新迭代日新月异,提示词会过期,模型会更新,工具会替换。
但你长期沉淀下来的判断、偏见和品味,一定会变成你的 AI 最难被复制的部分。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)