YOLO模型的改进
一.引言
截止2026年5月22日,YOLO主流迭代模型有YOLO、YOLOv2...YOLO11和YOLO26,一共12个模型版本。
- YOLO (You Only Look Once) 是一种流行的目标检测和图像分割模型,由Joseph Redmon 和Ali Farhadi在华盛顿大学开发。YOLO于2015年发布,因其高速度和高准确度而广受欢迎。
- YOLOv2 于2016年发布,通过引入批量归一化、锚框 (anchor boxes) 和维度聚类改进了原始模型。
- YOLOv3 于2018年发布,通过更高效的骨干网络、多个锚框和空间金字塔池化进一步提升了模型性能。
- YOLOv4 于2020年发布,引入了诸如Mosaic 数据增强、新的无锚检测头和新的损失函数等创新。
- YOLOv5 由Ultralytics于2026年发布,进一步提高了模型性能,并增加了超参数优化、集成实验跟踪以及自动导出到流行格式等新功能。
- YOLOv6 由美团于2022年开源,并应用于该公司的许多自动配送机器人中。
- YOLOv7 增加了额外的任务,如COCO关键点数据集上的姿态估计。
- YOLOv8 由Ultralytics于2023年发布,引入了新特性和改进,增强了性能、灵活性和效率,支持全方位的视觉 AI 任务。
- YOLOv9 引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
- YOLOv10 由清华大学研究人员使用 Ultralytics Python 软件包创建,通过引入端到端检测头,消除了非极大值抑制 (NMS) 的需求,提供了实时的目标检测进展。
- YOLO11:由Ultralytics于2024年9月发布,YOLO11 在多项任务中展现了卓越的性能,包括目标检测、分割、姿态估计、跟踪和分类,支持在各种 AI 应用和领域中部署。
- YOLO26:由Ultralytics于2026年发布,针对边缘部署进行了优化,支持端到端、无需 NMS 的推理。
这些模型由不同的组织开发,其中公认最权威的发布者为Ultralytics(公司),Ultralytics可以说是视觉人工智能领域的标杆。

二.YOLO模型改进方向概述
除了主流迭代模型,还有各类改进的YOLO模型,这些模型改进方向大致可以归纳几个主要类别:
- Backbone 改进(特征提取网络)
- Neck 改进(特征融合网络)
- Head 改进(检测头)
- 损失函数改进
在以下内容中,仅介绍常见的改进。
2.1.Backbone改进(特征提取网络)
主要目的是提升特征提取能力,使网络能更好地理解图像内容。
2.1.1.轻量化改进
在YOLO的Backbone中进行改进时,轻量化改进网络是指在保持较高检测精度的前提下,通过设计更高效的卷积结构,显著减少网络的参数量、计算量(FLOPs)和模型大小,从而提升推理速度、降低内存占用,使其能在资源受限平台上实时运行。
如 YOLOv4 使用 CSPDarknet53、YOLOv5/YOLOv8 使用 CSPNet 或改进的 Darknet 模块。
2.1.2.模型缩放(网络缩放)
通过系统性地调整网络深度、宽度(以及分辨率)这三个维度,从一个基础的小模型“缩放”出一系列不同大小、不同精度/速度的模型家族,如 YOLOv5系列:
|
模型 |
depth_multiple |
width_multiple |
效果 |
|
YOLOv5n |
0.33 |
0.25 |
最浅 + 最窄 |
|
YOLOv5s |
0.33 |
0.50 |
浅 + 标准宽 |
|
YOLOv5m |
0.67 |
0.75 |
中深 + 中宽 |
|
YOLOv5l |
1.00 |
1.00 |
基准深度 + 基准宽度 |
|
YOLOv5x |
1.33 |
1.25 |
更深 + 更宽 |
depth_multiple: 缩放深度 → 控制模块重复次数;
width_multiple: 缩放宽度 → 控制卷积核通道数。
增加层数(纵向)→ 提升抽象能力和感受野,利于大目标;
增加通道数(横向)→ 提升特征丰富度,利于小目标。
增大两者都是提升YOLO Backbone容量的有效手段,但会降低推理速度和增大资源开销。
2.1.3.注意力机制
在没有注意力机制的普通网络中,卷积核的权重是训练好后固定不变的。无论输入图片是什么,同一个卷积核都以同样的方式提取特征。
而加上了注意力机制,网络会根据输入特征图本身的内容,动态生成一个权重图,然后用这个权重图去加权原来的特征图。
常见的注意力机制可以按“关注什么维度”分为三类:
|
类型 |
关注维度 |
作用 |
代表机制 |
|
通道注意力 |
哪个特征 |
自动学习哪些特征通道更有用。比如,在识别狗时,毛发的通道权重变高。 |
SE ECA |
|
空间注意力 |
哪里 |
自动学习输入图像上哪个位置更重要。比如,忽略背景天空,只关注地面上的车辆。 |
CBAM |
|
自注意力 |
像素间关系 |
捕捉图像中任意两个像素之间的依赖关系。即使两个目标离得很远,也能建立联系。 |
Transformer |
2.2.Neck改进(特征融合网络)
Neck 主要用于多尺度特征融合,改善检测小目标或多尺度目标的能力。常见策略:
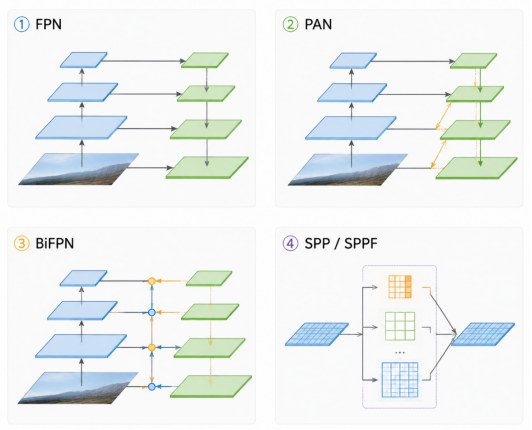
- FPN(Feature Pyramid Network):金字塔式多尺度特征融合。
- PAN(Path Aggregation Network):增加自底向上的特征传递,提高定位精度。
- BiFPN(Bidirectional FPN):双向信息流,提升特征融合效率。
- SPP(Spatial Pyramid Pooling)/SPPF:池化不同尺寸的感受野,提高对目标尺度适应能力。
2.3.Head 改进(检测头)
Head 决定了预测框和类别的生成方式。改进方向:
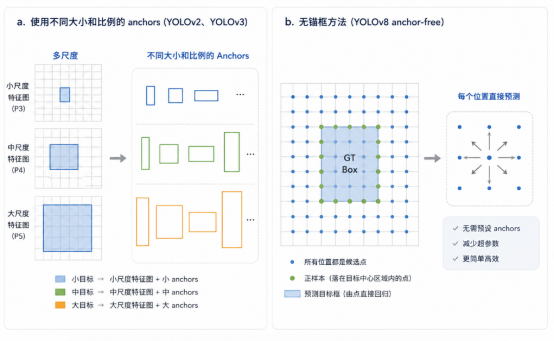
- Anchor 改进
- 使用不同大小和比例的 anchors(YOLOv2、YOLOv3)
- 无锚框方法(YOLOv8 anchor-free)
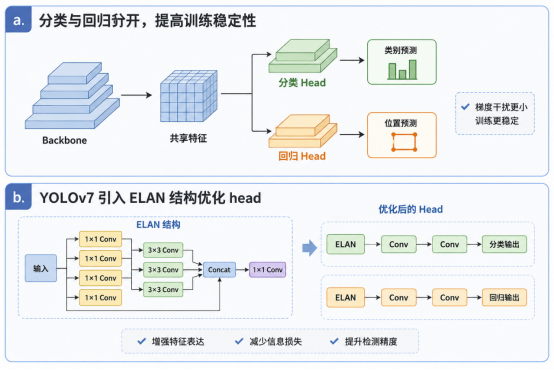
- 轻量化或解耦检测头
- 分类与回归分开,提高训练稳定性
- YOLOv7 引入 ELAN 结构优化 head
2.4.损失函数改进
目标是提升训练的收敛速度和检测精度。
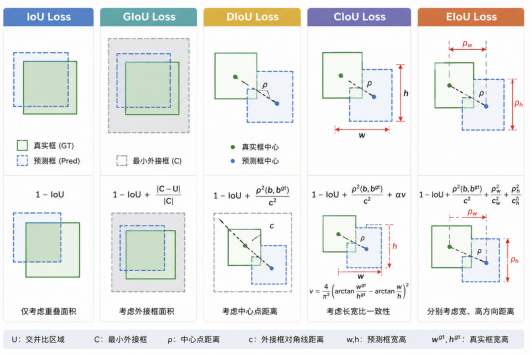
- IoU 损失系列
IoU Loss → GIoU → DIoU → CIoU → EIoU
- 分类损失
- Focal Loss 减少正负样本不平衡
- BCE(Binary Cross-Entropy)或 BCEWithLogits
三.本公司模型改进
3.1.DySnakeConv
由于道路资产中包含路灯杆等细长物体,本公司模型加入了蛇形卷积(DySnakeConv)加强学习。
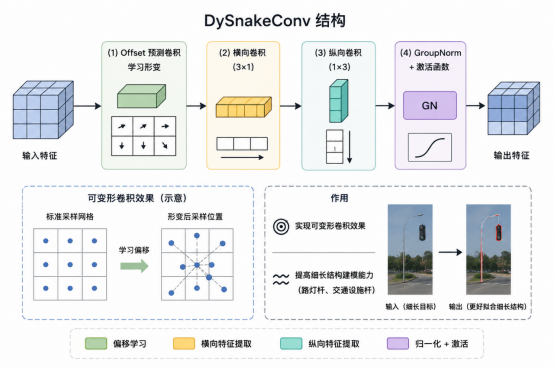
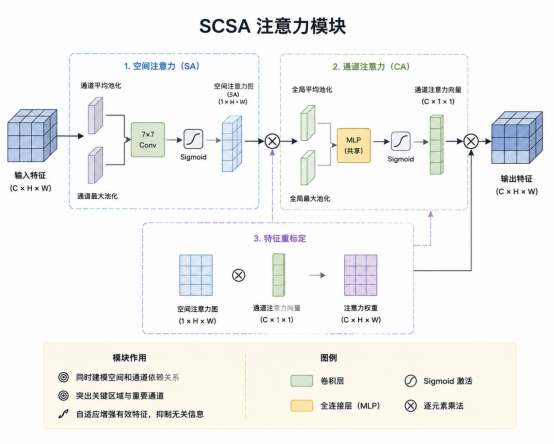
3.2.SCSA注意力模块
针对道路资产目标在复杂场景下易受背景干扰、特征表达不足的问题,在网络中引入 SCSA 注意力模块。该模块通过协同建模空间注意力与通道注意力,自适应增强目标区域的有效特征,突出关键结构信息,抑制无关背景噪声。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)