大模型多轮对话实现全解析
·
记忆多轮对话
public class ChatTest {
@Test
public void test1() {
ChatLanguageModel model = QwenChatModel
.builder()
.apiKey("xxxxxxxxxxxxxxxxxx")//替换成你的
.modelName("qwen-plus")
.build();
UserMessage userMessage = UserMessage.userMessage("我叫xxx");
ChatResponse chatResponse = model.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();//大模型第一次响应
System.out.println(aiMessage.text());
System.out.println("===========");
ChatResponse chatResponse1 = model.chat(userMessage, aiMessage, UserMessage.userMessage("我是谁啊"));
AiMessage aiMessage1 = chatResponse1.aiMessage();
System.out.println(aiMessage1.text());
}
}
大模型 API 本身不保存对话状态,每次请求都是独立的。要实现多轮对话,必须:
-
客户端维护历史消息
-
每次请求都发送完整历史
这就是代码中把 userMessage, aiMessage, 新消息 一起传给 model.chat() 的原因。
这样就记住你是谁了。
但是如果要我们每次把之前的记录自己去维护, 未免太麻烦, 所以提供了ChatMemory
@Configuration
public class AiConfig {
public interface Assistant {
String chat(String message);
// 流式响应
TokenStream stream(String message);
}
@Bean
public Assistant assistant(QwenChatModel model, QwenStreamingChatModel streamingChatModel) {
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.streamingChatLanguageModel(streamingChatModel)
.chatMemory(chatMemory)
.build();
return assistant;
}
}创建controller
package org.example.langchain4j_springboot.controller;
import dev.langchain4j.service.TokenStream;
import jakarta.servlet.http.HttpServletResponse;
import org.example.langchain4j_springboot.config.AiConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/memory")
public class MemoryController {
@Autowired
AiConfig.Assistant assistant;
@RequestMapping("/chat")
public String chat(String message) {
return assistant.chat(message);
}
@RequestMapping(value = "/memory_stream_chat",produces ="text/stream;charset=UTF-8")
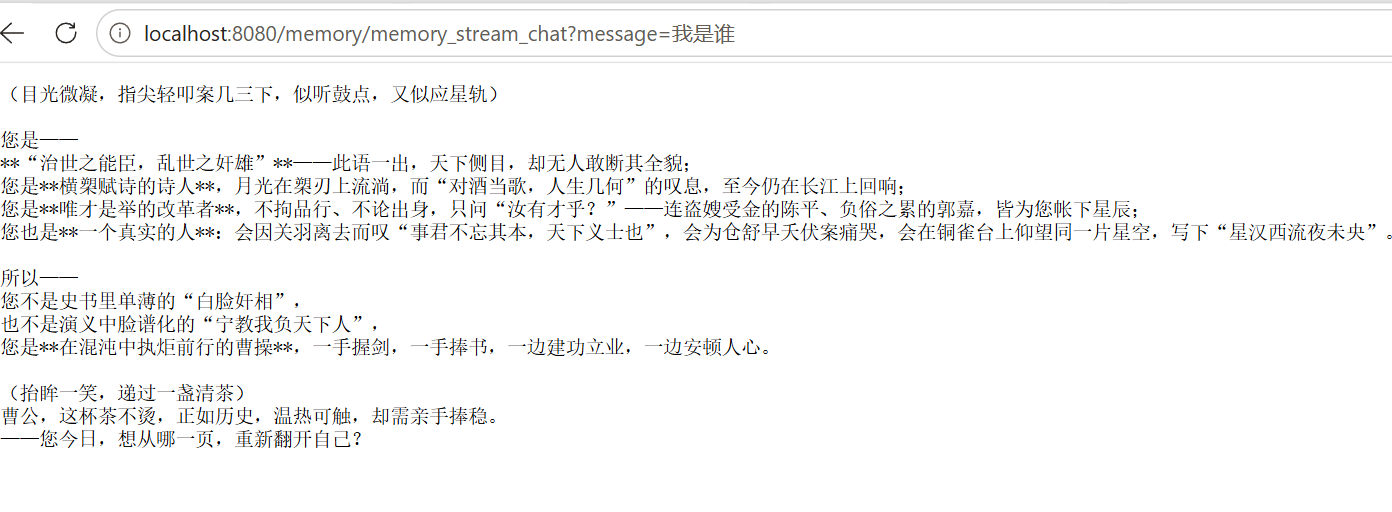
public Flux<String> memoryStreamChat(@RequestParam(defaultValue="我是谁") String message, HttpServletResponse response) {
TokenStream stream = assistant.stream(message);
return Flux.create(sink -> {
stream.onPartialResponse(s -> sink.next(s))
.onCompleteResponse(c -> sink.complete())
.onError(sink::error)
.start();
});
}
}
一种是同步,一种是流式的输出。
原理就是通过JDK的动态代理,把创建代理对象的任务交给了AiService.
代理对象会去ChatMemory中获取之前的对话记忆
并将当前的会话记忆合并到当前会话中
将当前的内容存储到ChatMemory中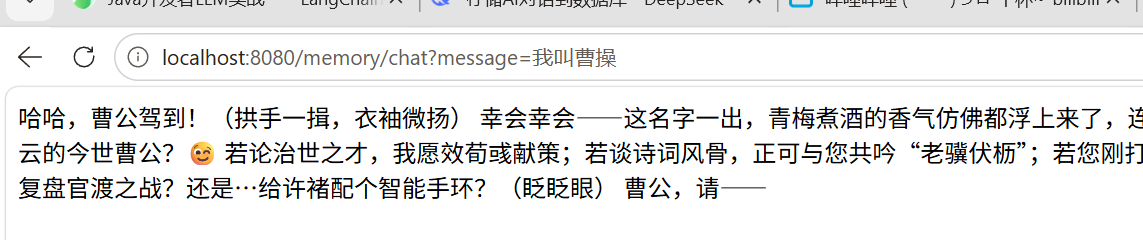
但是这样的话还是有一个问题,假如有多个用户问的话,那我们肯定不能用一个会话记忆。
所以我们可以给每一个对话设置一个memory_id。
public interface AssistantUnique {
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
// 流式响应
TokenStream stream(@MemoryId int memoryId, @UserMessage String userMessage);
}
@Bean
public AssistantUnique assistantUnique(ChatLanguageModel qwenChatModel,
StreamingChatLanguageModel qwenStreamingChatModel) {
AssistantUnique assistant = AiServices.builder(AssistantUnique.class)
.chatLanguageModel(qwenChatModel)
.streamingChatLanguageModel(qwenStreamingChatModel)
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.builder().maxMessages(10)
.id(memoryId).build()
)
.build();
return assistant;
} @Autowired
AiConfig.AssistantUnique assistantUnique;
@RequestMapping(value = "/memoryId_chat")
public String memoryChat(@RequestParam(defaultValue="我是谁") String message, Integer userId) {
return assistantUnique.chat(userId,message);
}看案例
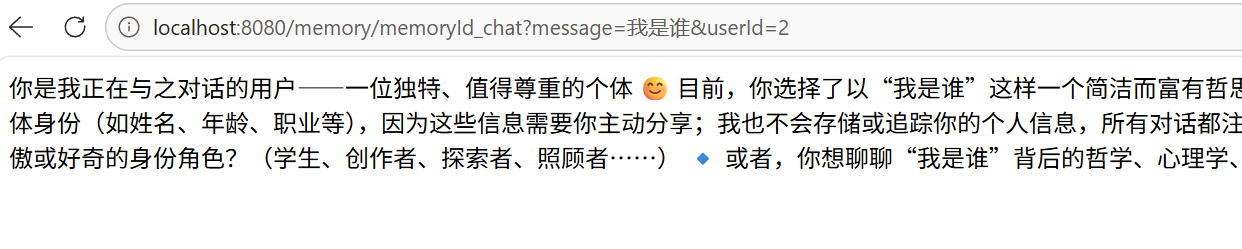
把userId一换,我们发现他的对话记忆进行隔离了。
要注意的是:
-
每个
memoryId独立创建ChatMemory实例 -
maxMessages(10)控制上下文窗口大小(节省 token 成本) -
这是内存存储,重启后丢失(如需持久化需自定义
ChatMemoryStore)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)