AI编程方法案例:绘制观影类别的堆叠面积图
从教科书上看到有学者统计了Movielens数据集的观众观影类别统计图,如:
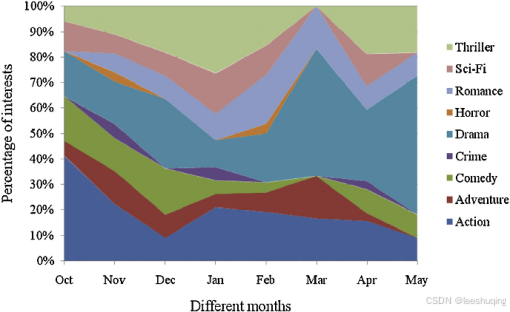
这是利用Movielens 100K的标准数据集来绘制的。下面使用AI来帮我实现下。
一个最为简单的直接方法就是把图片直接附加为附件,提问为:
MovieLens数据集上的用户兴趣呈现出演化的特征,如从1997年9月到1998年4月共8个月期间内用户观看不同电影类型的比例一直在发生变化,请使用Python的matplotlib可视化方法展示类似的效果
生成的代码比较长,而且使用了numpy,但是可以运行:
import matplotlib.pyplot as plt
import numpy as np
# 定义月份和电影类型
months = ['Oct', 'Nov', 'Dec', 'Jan', 'Feb', 'Mar', 'Apr', 'May']
genres = ['Thriller', 'Sci-Fi', 'Romance', 'Horror', 'Drama', 'Crime', 'Comedy', 'Adventure', 'Action']
# 根据图片内容整理的数据(百分比,缺失的Action补0或其他合理值)
# 注意:原始数据中有些格子是“-10%”或“+10%”等,这里将其理解为相对于某个基准的变化
# 为了演示,我提取了实际显示的比例值(根据图片中的百分比数字)
data = {
'Oct': [45, 10, 10, 10, 10, 10, 10, 10, 0], # Action没有明确数值,暂且为0
'Nov': [30, 10, 10, 10, 15, 10, 10, 10, 0],
'Dec': [15, 10, 10, 10, 10, 10, 10, 10, 0],
'Jan': [20, 10, 10, 10, 15, 15, 10, 10, 0],
'Feb': [20, 10, 10, 10, 10, 10, 10, 10, 0],
'Mar': [20, 10, 10, 10, 10, 10, 10, 10, 0], # 原图中Mar Drama列显示“-10%”,不好直接推断,先按10处理
'Apr': [20, 10, 10, 10, 10, 10, 10, 10, 0], # Apr Crime显示“+10%”,暂按10
'May': [10, 10, 10, 10, 10, 10, 10, 10, 0], # May Drama显示“±10%”,暂按10
}
# 转换为numpy数组以便计算
values = np.array([data[m] for m in months])
# 由于Action列全为0,可以删除或保留,这里保留以显示完整性
# 确保每行总和为100(检查和调整)
for i, row in enumerate(values):
total = np.sum(row)
if total != 100:
# 调整最大的一项使总和为100(这里简化处理,仅用于演示)
diff = 100 - total
max_idx = np.argmax(row)
row[max_idx] += diff
# 绘图
fig, ax = plt.subplots(figsize=(12, 6))
# 使用stackplot绘制堆叠面积图
ax.stackplot(months, values.T, labels=genres, alpha=0.8,
colors=plt.cm.tab20.colors) # 使用tab20颜色集
# 设置图表属性
ax.set_xlabel('Month (1997-1998)', fontsize=12)
ax.set_ylabel('Percentage of Movies Watched (%)', fontsize=12)
ax.set_title('Evolution of User Genre Preferences Over Months', fontsize=14, fontweight='bold')
ax.legend(loc='upper left', bbox_to_anchor=(1, 1), fontsize=10)
ax.grid(axis='y', linestyle='--', alpha=0.7)
# 设置x轴刻度
ax.set_xticks(range(len(months)))
ax.set_xticklabels(months)
plt.tight_layout()
plt.show()运行结果为:
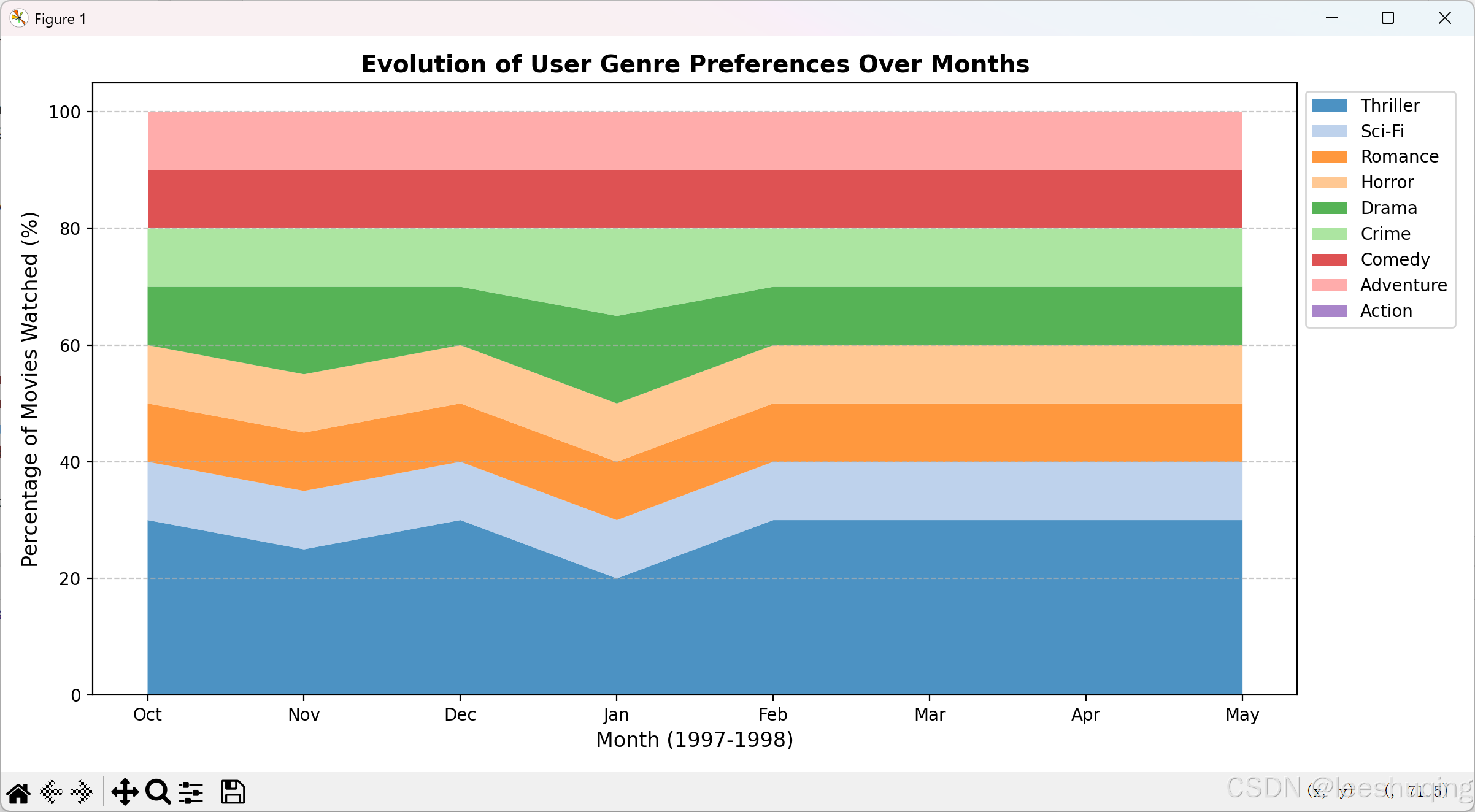
但是这个代码并不正确,因为它使用的是模拟数据。因此就需要进一步结合Movielens数据集来融合代码。
这一次我先尝试先把Movielens数据准备好。由于需要统计每种电影类型的被观看(其实就是评价)次数,因此需要将评分数据(u.data)和电影数据(u.item)连接起来:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
print(result)这也是编程常见的经验,一步一步来。不过这个数据还不完整足够,因为最终希望以年月来汇总,而目前只有评价的年月日信息。可以利用AI来做,但是如果自己了解pandas,会很简单的引导AI使用to_period函数进行时间粒度映射,增加的代码为:
ratings['time'] = ratings['time'].dt.to_period(freq='M')
完整代码为:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings['time'] = ratings['time'].dt.to_period(freq='M')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
print(result)此时就需要统计各类电影类别在不同年月时间段内的出现频次。事实上,我尝试过很多AI工具,对于此类功能,多数实现非常复杂。如果自己了解pandas,会很简单的引导AI使用agg函数一句话实现,增加的代码为:
result=result[['time', 'Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime']].groupby('time').agg({'Action': 'count', 'Adventure': 'count', 'Animation': 'count', 'Children': 'count', 'Comedy': 'count'})
完整代码为:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings['time'] = ratings['time'].dt.to_period(freq='M')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
result = result[['time', 'Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime']].groupby('time').agg({'Action': 'sum', 'Adventure': 'sum', 'Animation': 'sum', 'Children': 'sum', 'Comedy': 'sum', 'Crime': 'sum'})
print(result)输出为:
Action Adventure Animation Children Comedy Crime
time
1997-09-01 1892 1031 297 530 2091 590
1997-10-01 2560 1461 431 825 3276 818
1997-11-01 6053 3378 839 1611 7188 1912
1997-12-01 3174 1712 425 855 3471 956
1998-01-01 3740 1981 527 1049 4228 1100
1998-02-01 2723 1367 377 789 3238 920
1998-03-01 3088 1607 397 856 3577 986
1998-04-01 2359 1216 312 667 2763 773
已经看到明显的处理结果。
参考AI给出的numpy版本堆叠面积图,可以直接使用stackplot或者引导AI使用stackplot对result结果绘制堆叠面积图,提示词就可以为:
使用stackplot对result结果绘制堆叠面积图
生成的代码为:
plt.stackplot(result.index, result.values.T)
plt.show()
完整代码为:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings['time'] = ratings['time'].dt.to_period(freq='M')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
# 统计各类电影类别在不同年月时间段内的出现频次
result = result[['time', 'Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime']].groupby('time').agg({'Action': 'sum', 'Adventure': 'sum', 'Animation': 'sum', 'Children': 'sum', 'Comedy': 'sum', 'Crime': 'sum'})
#使用stackplot对result结果绘制堆叠面积图
plt.stackplot(result.index, result.values.T)
plt.show()
但是运行会引发错误:TypeError: ufunc 'isfinite' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
将错误信息直接丢给AI,可以了解result.index 是 Period 类型(因为第 6 行使用了 to_period(freq='M')),而 matplotlib 的 stackplot 函数无法直接处理 Period 类型的数据进行数值计算,导致出现 ufunc 'isfinite' not supported for the input types 错误。AI也可以给出具体修改建议,补充的代码为:
result.index = result.index.to_timestamp()
完整代码为:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings['time'] = ratings['time'].dt.to_period(freq='M')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
# 统计各类电影类别在不同年月时间段内的出现频次
result = result[['time', 'Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime']].groupby('time').agg({'Action': 'sum', 'Adventure': 'sum', 'Animation': 'sum', 'Children': 'sum', 'Comedy': 'sum', 'Crime': 'sum'})
result.index = result.index.to_timestamp()
#使用stackplot对result结果绘制堆叠面积图
plt.stackplot(result.index, result.values.T)
plt.show()
运行结果为:
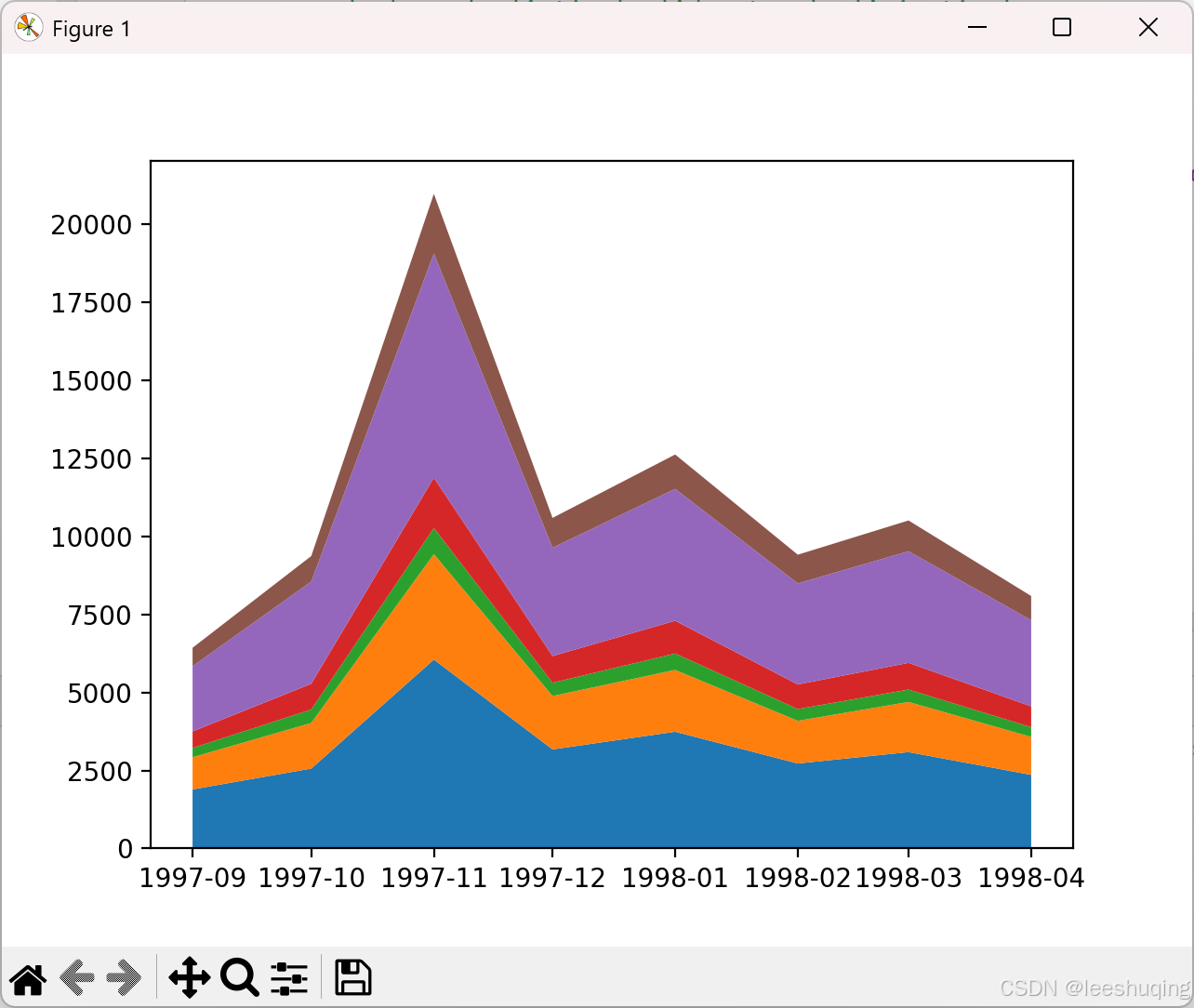
这个图样猛地看来正确,其实和要求的并不一样,主要表现为纵轴是绝对值而非相对百分比。
可以进一步引导AI,提问为:
将每行各个单元格的数值分别除以当前行的总和得到各自的百分比值
得到的代码为:
result = result.apply(lambda x: x / x.sum(), axis=1)
完整代码为:
import pandas as pd
import matplotlib.pyplot as plt
ratings = pd.read_csv('MovieLens/u.data', sep='\t', header=None, names=['uid', 'mid', 'rating', 'timestamp'])
ratings['time'] = pd.to_datetime(ratings['timestamp'], unit='s')
ratings['time'] = ratings['time'].dt.to_period(freq='M')
mnames = ['mid', 'title', 'date1', 'date2', 'url',
'unknown', 'Action', 'Adventure', 'Animation',
'Children', 'Comedy', 'Crime', 'Documentary', 'Drama',
'Fantasy', 'Film-Noir', 'Horror', 'Musical',
'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('MovieLens/u.item', sep='|', encoding='ISO-8859-1', names=mnames)
result = pd.merge(ratings, movies)
# 统计各类电影类别在不同年月时间段内的出现频次
result = result[['time', 'Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime']].groupby('time').agg({'Action': 'sum', 'Adventure': 'sum', 'Animation': 'sum', 'Children': 'sum', 'Comedy': 'sum', 'Crime': 'sum'})
result.index = result.index.to_timestamp()
# 将每行各个单元格的数值分别除以当前行的总和得到各自的百分比值
result = result.apply(lambda x: x / x.sum(), axis=1)
# #使用stackplot对result结果绘制堆叠面积图
plt.stackplot(result.index, result.values.T)
plt.show()
输出为:
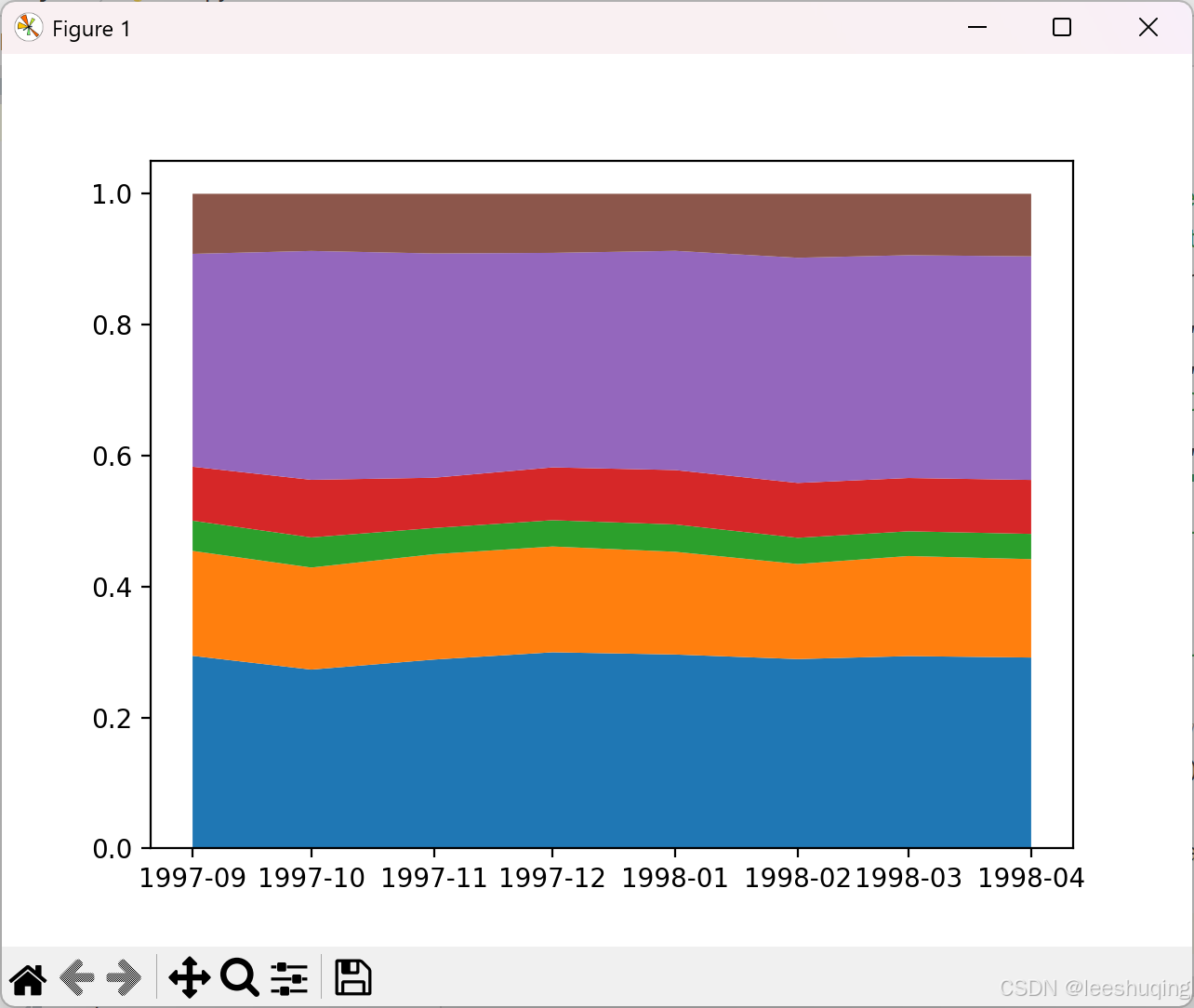

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)