告别NMS与DFL!YOLO26重塑实时目标检测的“极简美学”
一、研究来源
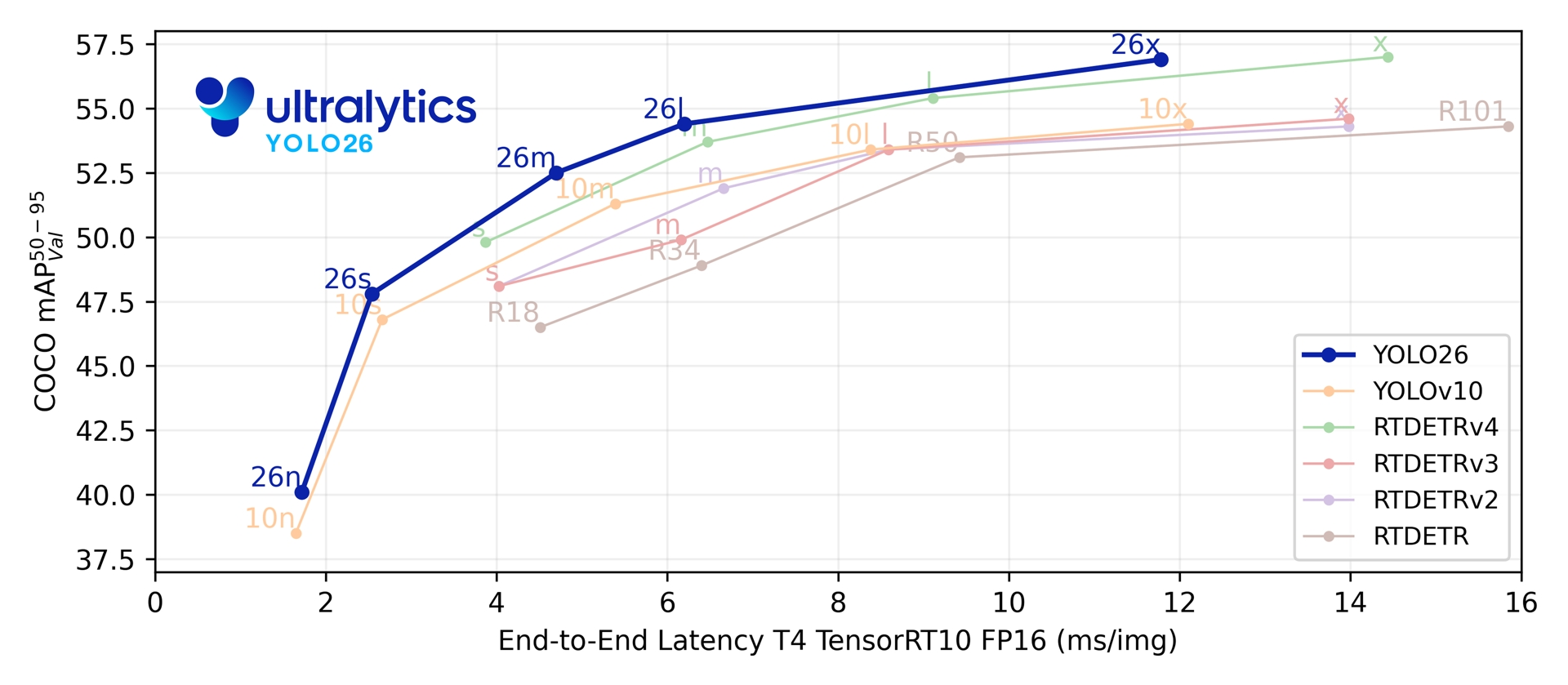
YOLO26 是 2025 年 9 月 Ultralytics 发布的 YOLO 系列最新模型,2026年1月14号发布代码,专为边缘设备和低功耗场景设计,解决了前代模型(如 YOLOv8-YOLOv13)依赖 NMS、DFL 导致的部署复杂、 latency 高等问题,同时满足实时目标检测的效率与精度需求,适配机器人、制造、物联网等多行业应用。
论文:YOLOv-26:https://arxiv.org/pdf/2509.25164
代码:ultralytics/docs/en/models/yolo26.md at main · ultralytics/ultralytics
官方介绍: Ultralytics YOLO26 - Ultralytics YOLO
这里与先有模型比较
| 对比维度 | YOLO26 (2025) | YOLOv11 (2024) | YOLOv13 (2025) |
|---|---|---|---|
| 核心架构创新 | 移除 DFL、端到端无 NMS 推理;ProgLoss+STAL;MuSGD 优化器 | C3k2 瓶颈 + SPPF+ C2PSA 模块;支持姿态 / 定向检测 | HyperACE 模块 + FullPAD 方案;超图增强特征交互 |
| 推理效率 | CPU 推理提速 43%,无后处理瓶颈,冷启动更快 | 依赖 NMS 后处理,存在 latency 开销 | 依赖 NMS 后处理,架构复杂度较高 |
| 部署兼容性 | 原生支持 ONNX/TensorRT/CoreML 等多格式;INT8/FP16 量化无明显精度损失 | 需适配导出,量化稳定性一般 | 导出需处理 DFL 和 NMS,低功耗设备适配差 |
| 小目标检测 | STAL 标签分配 + 多尺度特征,精度显著提升 | 依赖 C2PSA 注意力模块,效果有限 | 多尺度融合优化,但无专门小目标机制 |
| 支持任务 | 目标检测、实例分割、姿态估计、定向检测、分类(5 类) | 目标检测、实例分割、姿态估计、定向检测(4 类) | 仅支持目标检测 |
| 训练稳定性 | MuSGD 优化器 + ProgLoss,收敛快、无训练波动 | 传统 SGD/AdamW,需多轮超参调优 | 传统优化器,复杂架构易过拟合 |
二、网络结构理解
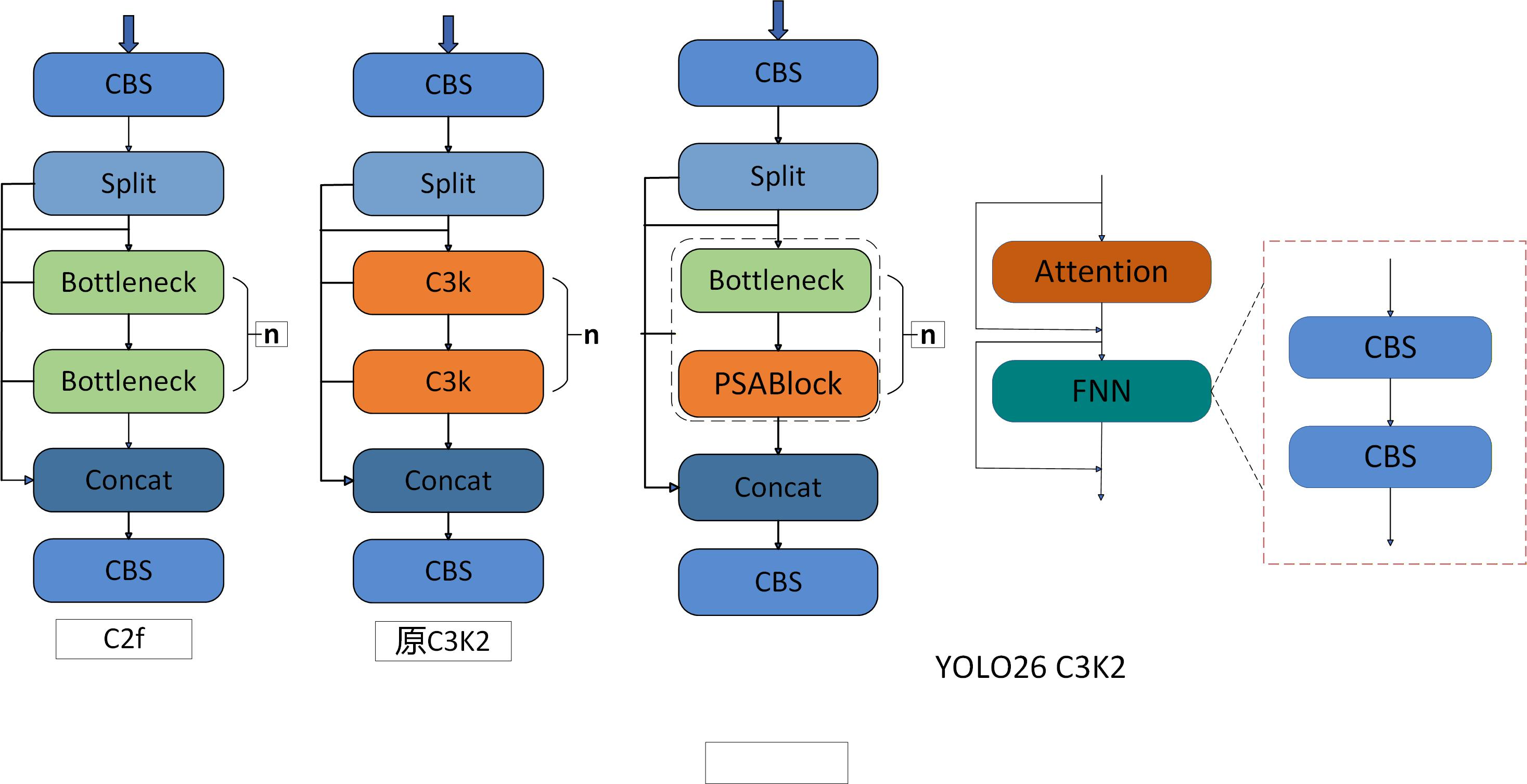
YOLO26 与 YOLO11 的结构差异主要体现在端到端推理设计、模块参数优化两方面,其骨干网络的 SPPF 模块新增核数与增强模式参数,检测头的 C3k2 模块则全面启用 True 模式,且最后一层新增通道缩放和增强参数,目的是提升特征交互效率,匹配小目标检测的 STAL 标签分配策略。
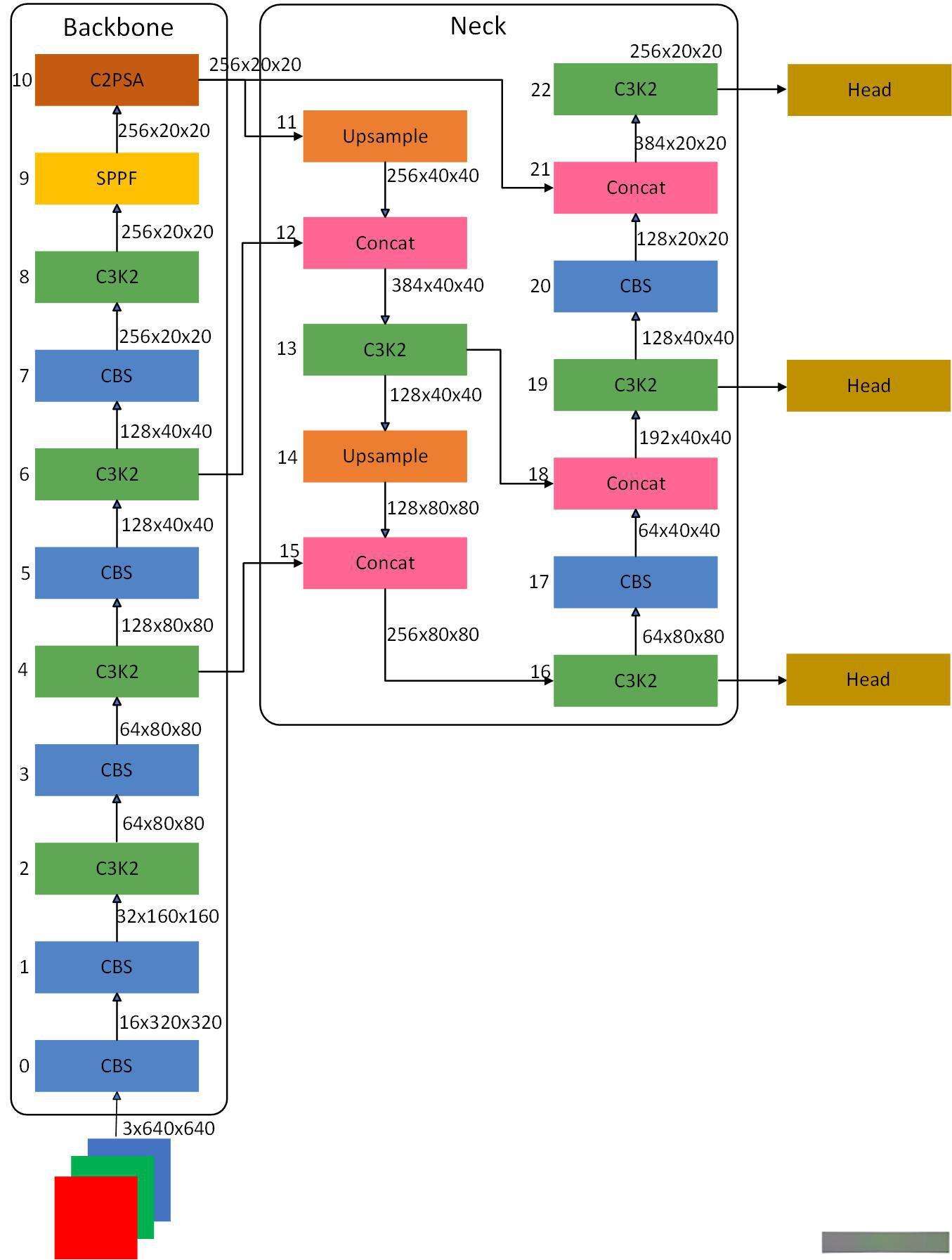
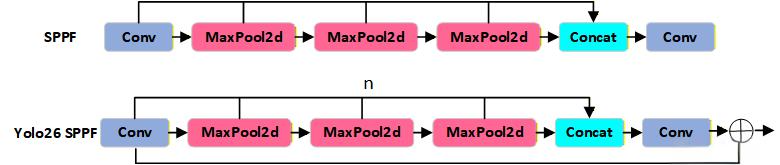
2.1 SPPF模块
YOLO26 相比 YOLO11 给 SPPF 新增了 shortcut=True 参数,启用残差连接;以及控制maxpool的次数。残差连接让 SPPF 模块在融合多尺度特征的同时保留原始输入信息,提升了特征传递效率,适配 YOLO26 端到端推理和小目标检测的设计目标。
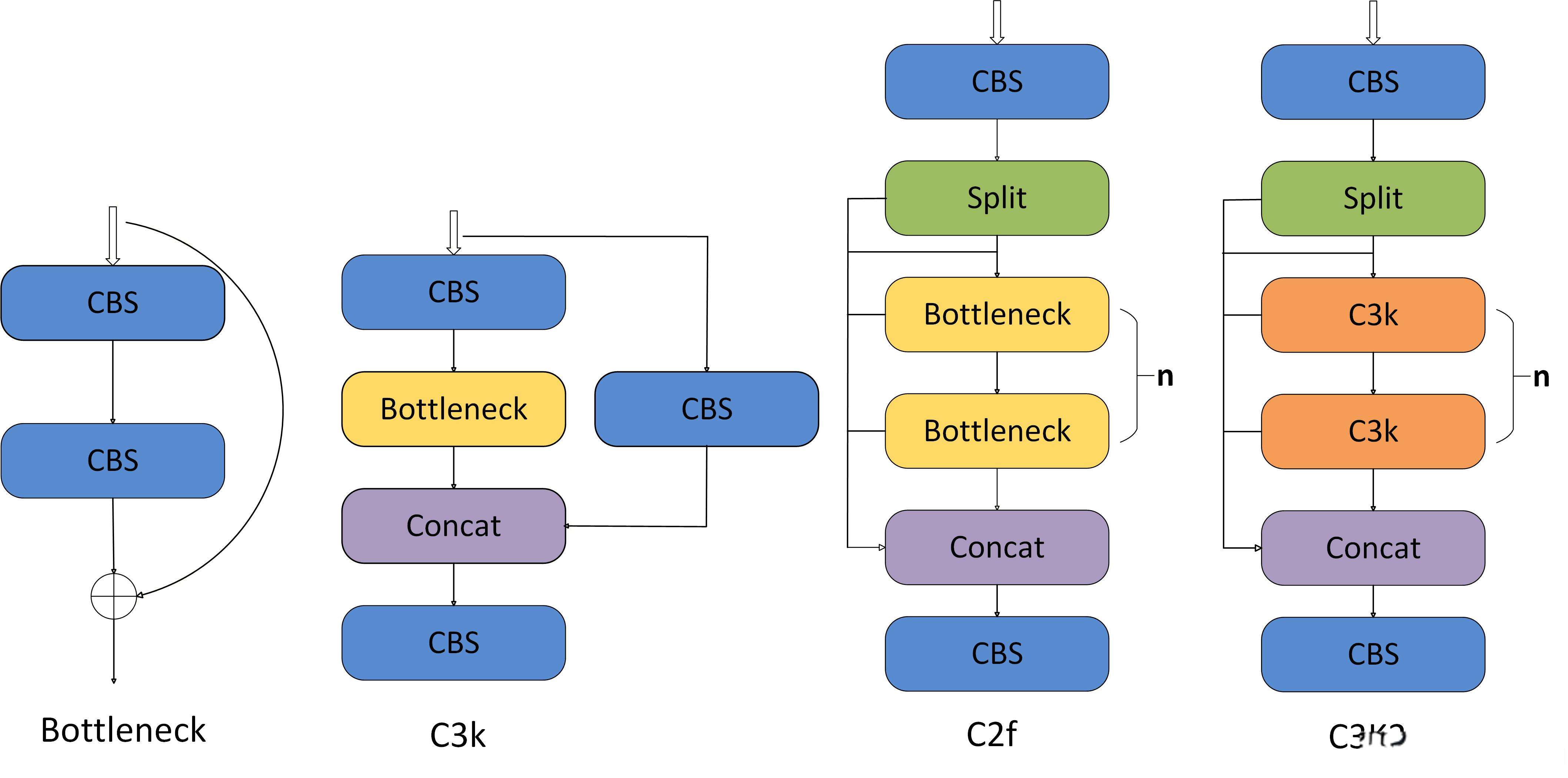
2.2 C3K2模块
两个版本 C3k2 类的实现差异,核心区别集中在初始化参数、内部模块构建逻辑两方面
| 对比维度 | 第一个 C3k2 版本 | 第二个 C3k2 版本 | 差异影响 |
|---|---|---|---|
| 初始化参数 | 新增 attn: bool = False 参数 | 无 attn 参数 | 支持注意力机制(PSABlock)的开关控制 |
| 内部模块逻辑 | 三层条件分支(attn → c3k → Bottleneck) | 两层条件分支(c3k → Bottleneck) | 第一个版本可集成注意力模块,功能更丰富 |
| 模块组合 | attn=True 时:Bottleneck + PSABlock 组合 | 无注意力模块组合 | 第一个版本能增强特征交互(适配小目标检测) |
三、创新点
YOLO26 的核心创新点围绕 “简化架构提效、精准优化提精度、适配部署降门槛” 三大核心目标,共 4 个关键突破,每个创新都针对性解决了前代 YOLO 模型的痛点,下面结合技术细节、解决的问题和实际效果展开说明:
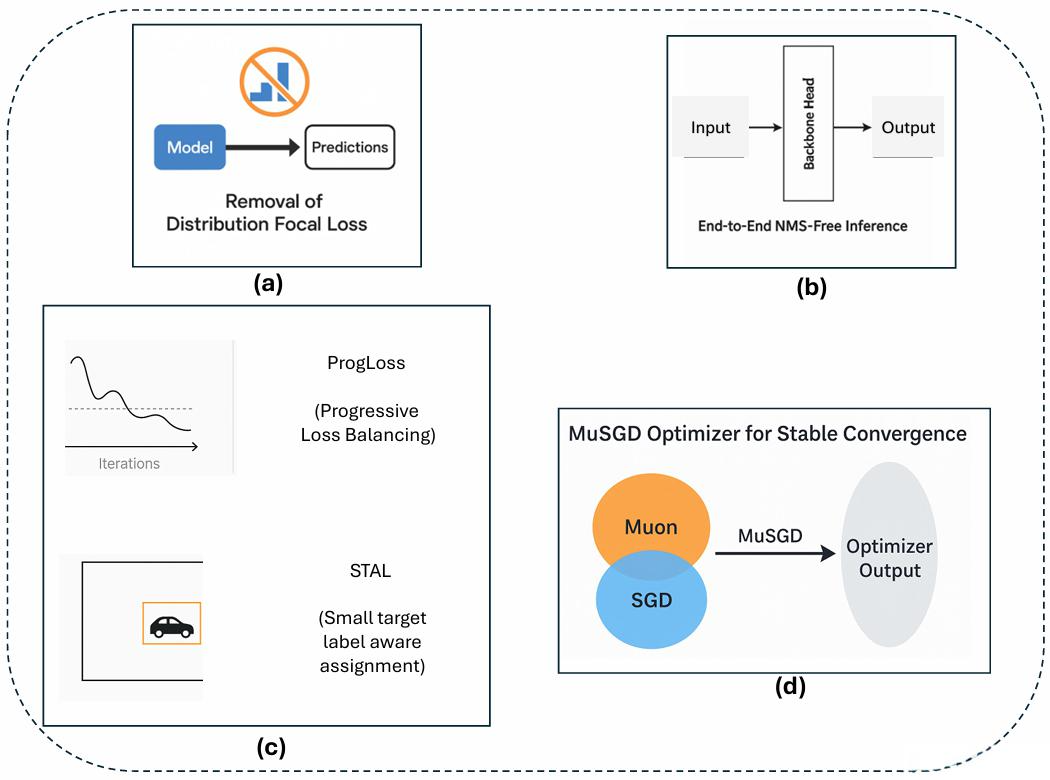
3.1 创新点 1:移除 DFL(Distribution Focal Loss )—— 轻量化回归,破除部署障碍
-
相对前面模型
DFL介绍
DFL 的全称是 Distribution Focal Loss,即 分布焦点损失。它是由旷视科技在 2020 年的论文《Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection》中提出的。yolov8中引入;
DFL 将目标值(如边界框的 x 坐标)建模为一个在某个数值范围内的离散分布。
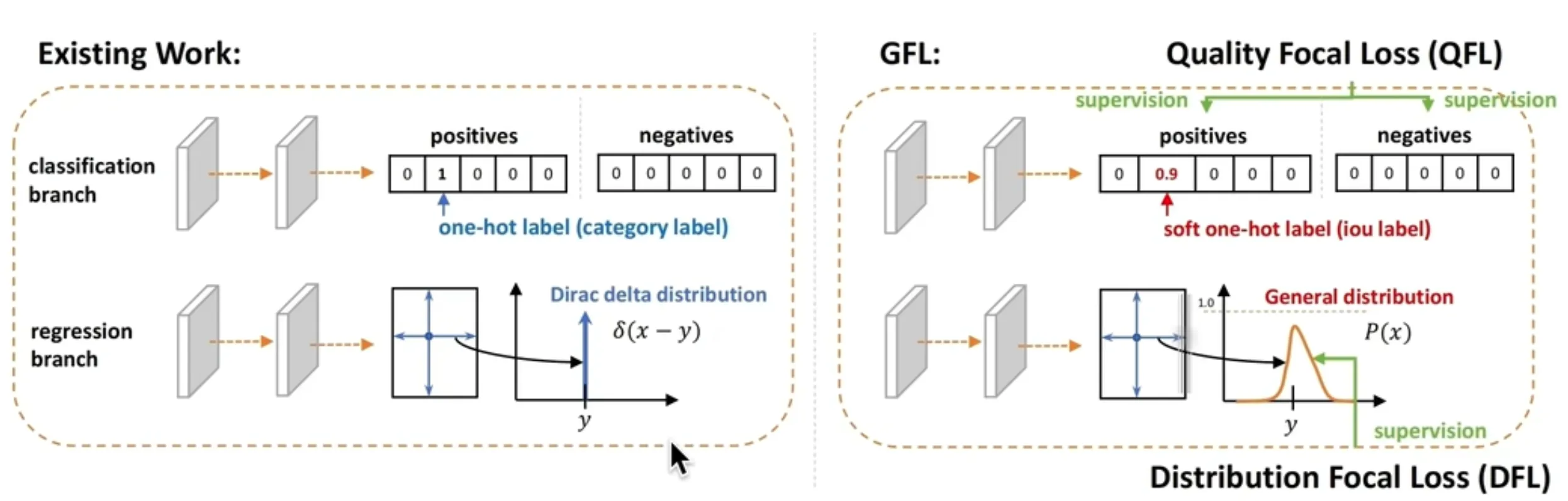
步骤分解:
定义范围:假设我们要预测的目标值 y(例如某个框的左侧 x 坐标)的真实值在 0 到 15 像素之间。我们将其离散化,用 16 个整数来表示这个范围,即 [0, 1, 2, ..., 15]。这 16 个点我们称之为“锚点”。
模型输出:模型不再只输出 1 个标量值,而是输出 16 个值(每个锚点一个),这 16 个值经过 Softmax 后形成一个概率分布 P = [P0, P1, ..., P15],表示 y 等于每个锚点值的概率。
从分布到预测值:最终的预测值 y_hat 不是简单地取概率最大的那个锚点,而是这个分布的期望值(加权平均):
y_hat = Σ(i * Pi),其中 i 是锚点,Pi 是其对应的概率。
例如,如果模型输出的概率集中在 5 和 6 周围(即 P5 和 P6 的值很高),那么最终的预测值 y_hat 就会是 5.x,实现了亚像素级别的精确回归。
| 狄克拉分布 | 狄克拉分布 | |
|---|---|---|
| 特点 | 单点概率为1,其他概率为0 | 从连续坐标到离散分布 |
| 输出过程 | 输出多个值,服从一般分布,任意分布 | 将连续坐标值建模为离散区间上的概率分布加权求和(积分)得到最终预测坐标 |
YOLOv8/v11/v13 等模型依赖 DFL 进行边界框回归:通过预测坐标的概率分布来优化定位精度,但会带来两个关键问题:
-
计算冗余:DFL 需要额外的分布参数计算,增加 15%-20% 的模型参数和推理耗时,尤其在 CPU / 边缘设备上表现明显;
-
部署麻烦:DFL 的分布计算逻辑难以适配低精度量化(如 INT8),导出 ONNX、TensorRT 等格式时需额外适配,易出现精度丢失或兼容性报错。
-
技术实现
YOLO26 彻底移除 DFL 模块,重新设计边界框回归头:
-
直接回归:回归头不再预测分布参数,而是直接输出边界框的 4 个坐标(x/y/w/h),将 “分布解码” 简化为 “直接回归”,计算逻辑更简洁;
-
精度补偿:通过后续 ProgLoss 的动态权重调节,弥补移除 DFL 后的定位精度损失,最终实现 “轻量化 + 精度不降”。
3.2 创新点 2:端到端无 NMS 推理 —— 消除后处理瓶颈,提速部署流程
End-to-End(端到端)检测 = 输入原始图片 → 模型前向传播 → 直接输出最终的检测框 / 类别 / 置信度,整个过程无需任何离线后处理(如 NMS、坐标裁剪、阈值筛选等),模型自身完成所有检测逻辑。
对比:传统 YOLO vs E2E YOLO
| 阶段 | 传统 YOLO | E2E YOLO |
|---|---|---|
| 模型输出 | 全量预测框(含大量重叠框) | 筛选后的最优检测框(无重叠) |
| 关键后处理 | 必须用 NMS 过滤重叠框 | 无 NMS,模型直接输出最终框 |
| 部署链路 | 模型 + 离线后处理脚本 | 纯模型(输入→输出) |
| 部署效率 | 后处理增加延迟(尤其边缘设备) | 延迟更低,适配端侧部署 |
| 训练目标 | 拟合全量锚框预测 | 拟合 “单框最优预测”(对齐推理) |
3.3 创新点 3:ProgLoss+STAL—— 精准优化训练,攻克小目标痛点
这两个创新是 YOLO26 提升精度的核心,尤其针对工业场景高频的 “小目标检测” 和 “训练不稳定” 问题:
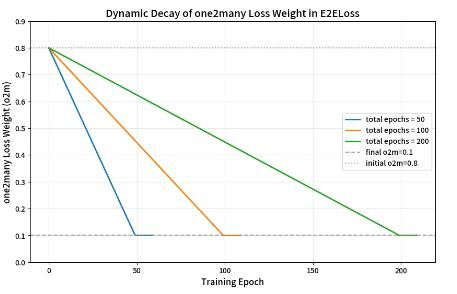
ProgLoss(Progressive Loss)—— 动态平衡损失,稳定训练收敛
-
双分支损失融合:「一对多」损失(粗匹配)保证模型覆盖更多候选框,「一对一」损失(精准匹配)提升模型定位精度,结合两者优势;
-
动态权重衰减:训练前期侧重「一对多」(让模型先学习大范围匹配),后期侧重「一对一」(让模型聚焦精准匹配),符合 “先粗后精” 的训练逻辑;
-
权重和恒定:始终保证 o2m + o2o = 1,避免总损失数值波动过大,保证训练稳定性。
-
这个损失含时候是融合「一对多 / 一对一」双分支的端到端检测损失,核心用于 YOLO 类模型的训练;
-
初始时「一对多损失」占 80% 权重,训练过程中线性衰减至 10%,「一对一损失」权重同步从 20% 升至 90%;
-
初始与终值固定:无论总训练轮数多少,o2m 初始值都是 0.8,最终稳定在 0.1。
-
衰减速率与总轮数负相关:总 epoch 越多,权重下降的斜率越小,衰减过程越平缓,避免训练后期权重突变。
-
稳定阶段无波动:当训练 epoch 超过 epochs-1 后,o2m 不再变化,保证训练末期损失计算的稳定性。
STAL(Small-Target Aware Label Assignment)—— 小目标专属标签分配
yolo26和yolo11标签分配策略的对比
| 对比维度 | yolo26(增强版 / E2E 适配) | yolo11 |
|---|---|---|
| 核心定位 | 适配端到端检测,支持动态锚框筛选(topk2) | 基础 TAL 分配器,仅支持固定 topk 筛选 |
| 初始化参数 | 新增stride、topk2参数 | 仅保留topk/num_classes等核心参数 |
| 锚框筛选逻辑 锚框筛选逻辑 | 支持双层 topk 筛选(topk→topk2) | 仅单层 topk 筛选 |
第一步:先理解核心问题 —— 小目标为什么容易漏选?
YOLO 的锚框是按特征层步长(stride) 生成的:
P3 层 stride=8:输入图片每 8 个像素对应 1 个锚框中心点;
P4 层 stride=16:每 16 个像素对应 1 个锚框;
P5 层 stride=32:每 32 个像素对应 1 个锚框。
对于小目标(比如宽 / 高 < 8 像素的目标),会出现两个致命问题:
-
锚框覆盖不到:小目标的 GT 框可能完全落在两个锚框中心点之间,导致没有锚框被判定为 “在 GT 内”;
-
筛选逻辑误判:代码中select_candidates_in_gts的核心是判断 “锚框中心点是否在 GT 框内”,如果 GT 框本身太小(<8 像素),计算时的数值误差(如eps=1e-9)会导致锚框被误判为 “不在 GT 内”,最终漏选。
举个例子:
小目标 GT 框宽 = 5 像素(<stride=8),锚框中心点坐标是 (10,10),GT 框坐标是 (8,8,13,13);
计算 “锚框中心点是否在 GT 内” 时,因数值精度问题,可能判定为 “不在”,导致这个小目标没有任何锚框匹配,训练时完全学不到。
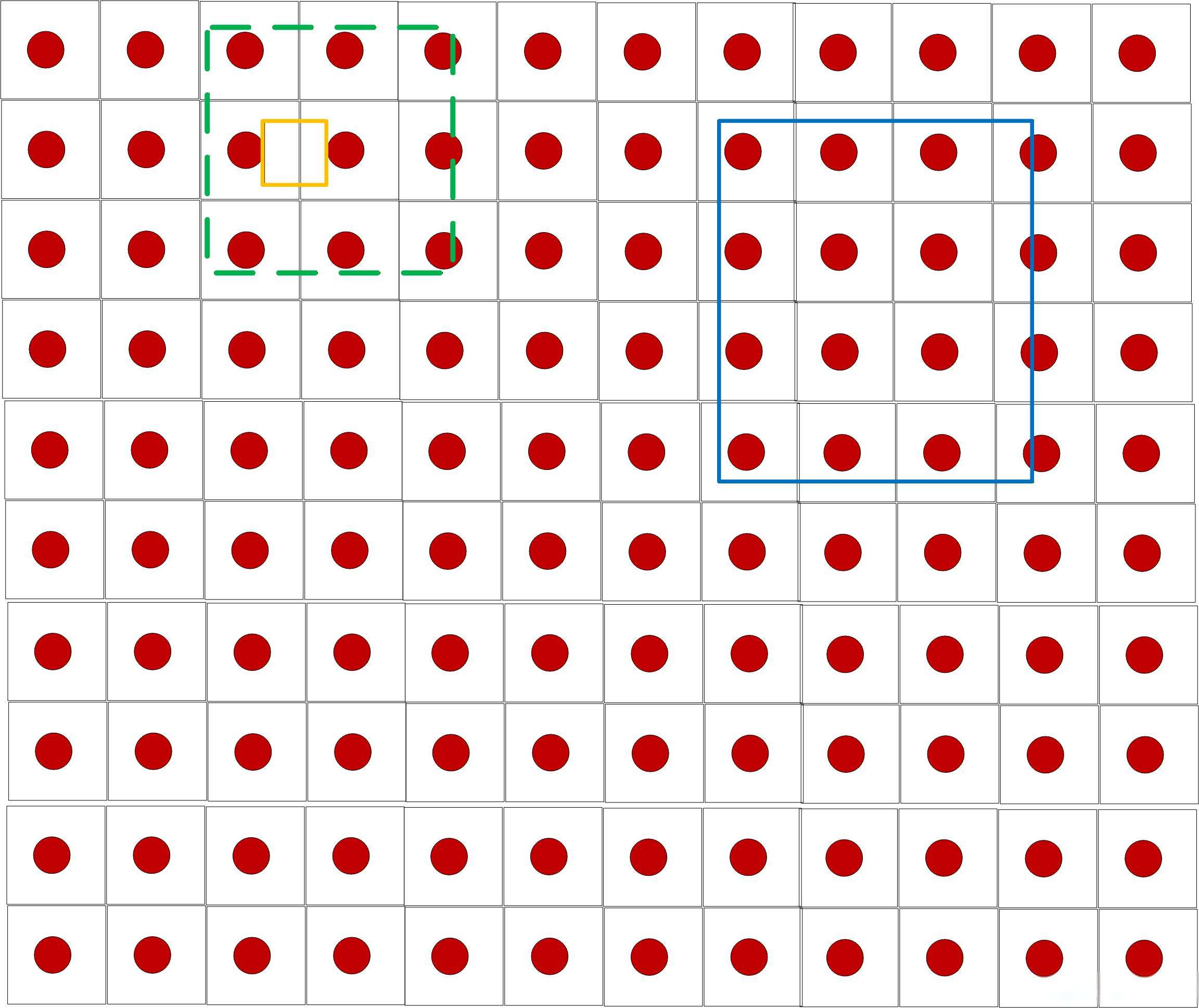
第二步:stride调整的核心逻辑 ——“放大” 小目标的 GT 框
代码的思路是:对小目标的 GT 框做 “虚拟放大”,让它的宽 / 高至少等于次小的 stride(16),从而保证有足够的锚框能被判定为 “在 GT 内”,避免漏选。如下图所示,红点的格子就代表着网格一个大小是8x8,蓝色的框是大目标,它可以包含很多的预测框,黄色的框是小目标,由于他太小了,因此里面没有锚点,那就不存在锚框。这样这个小目标就丢失了,为了不丢失,我们就将其放大,这样就有框去预测这个小目标了。
创新点 4:MuSGD 优化器 —— 兼顾收敛速度与泛化能力
相对前面的模型
传统 YOLO 模型使用 SGD 或 AdamW 优化器,存在明显短板:
-
SGD:泛化能力强,但收敛慢(需 300 + 轮),且需多轮调整学习率;
-
AdamW:收敛快(200 轮左右),但易过拟合,且量化后精度损失大(尤其在边缘设备上);
-
适配性差:无法匹配 YOLO26 的轻量化架构,易出现 “收敛快但泛化差” 或 “泛化好但收敛慢” 的矛盾。
技术实现
MuSGD 是融合 “SGD 稳定性” 和 “Muon 优化器快速收敛” 的混合优化器:
两阶段优化:
-
前期(前 50% epoch):采用 Muon 优化器(基于动量的自适应学习率),快速收敛到最优解附近,解决 SGD 收敛慢的问题;
-
后期(后 50% epoch):切换为 SGD 优化器,微调参数,避免 AdamW 的过拟合问题,提升泛化能力;
动量优化:针对 YOLO26 的轻量化架构,优化动量衰减策略(动量值从 0.9 逐步衰减到 0.85),减少内存占用,适配边缘设备训练。
实际效果
-
训练效率:训练轮数减少 30%,同等精度下训练时间缩短 25%-30%;
-
泛化能力:跨场景测试精度损失 < 2%,工业场景(如制造业缺陷检测)中过拟合率降低 40%;
-
量化适配:量化(INT8)后精度损失 < 1%,远优于 SGD(3%)和 AdamW(5%),适合低功耗设备部署。
3.3 传统 YOLO 为什么需要 E2E 改造?(核心痛点)
传统 YOLO 的推理流程是有 3 个致命问题,也是 E2E 要解决的核心:
-
部署不友好:NMS 是离线操作,无法融入模型推理图(如 ONNX/TensorRT 导出),边缘设备部署时需要额外开发后处理逻辑;
-
超参数敏感:NMS 的 IOU 阈值、置信度阈值需要手动调优,不同数据集 / 场景下泛化性差;
-
训练 - 推理不一致:训练时模型拟合 “全量锚框”,推理时用 NMS 筛选 “单框”,两者目标错位,导致最终检测效果打折扣。
四、总结:YOLO 实现 E2E 的核心思路
YOLO 的 E2E 改造不是 “重写模型”,而是通过训练策略 + 锚框分配 + 损失设计,让模型自身学会 “筛选最优框”:
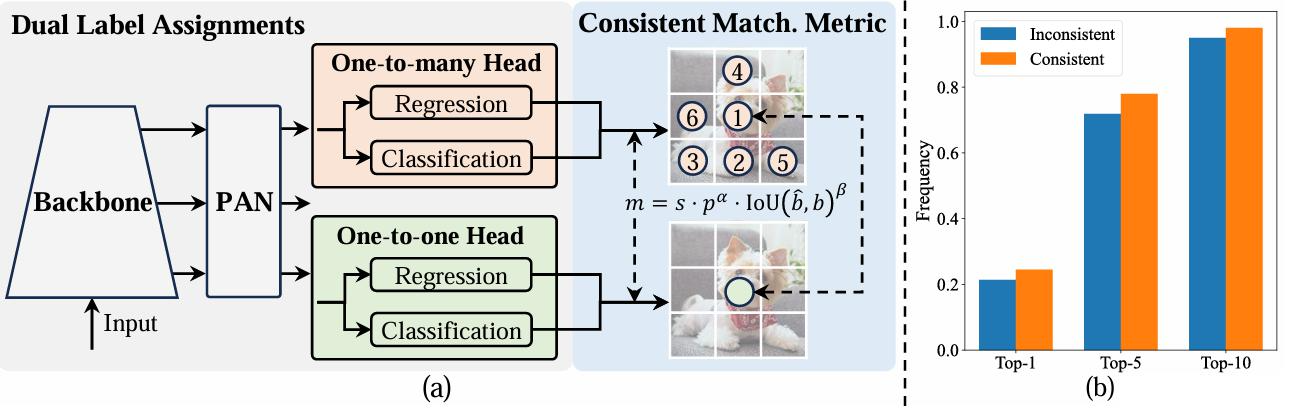
YOLO26 的端到端改造并非重写模型,而是通过训练策略 + 锚框分配 + 损失设计,让模型自身学会“筛选最优框”:
-
移除 DFL + 无 NMS:解决“效率低、部署难”的工程痛点;
-
ProgLoss + STAL:解决“小目标差、训练不稳”的精度痛点;
-
MuSGD:为上述改进提供“快速收敛、泛化稳定”的训练保障。
对于需要在边缘设备、低功耗场景部署实时检测的工程项目,YOLO26 在推理链路简洁性与训练稳定性上提供了更优的基线选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)