CPU始终100%,吞吐却只有别人十分之一?——一次高性能网关性能雪崩的完整分析
一、问题出现了
某运营商边缘节点部署了一套用户面网关。
系统采用:
DPDK + 多核Worker模型主要功能:
GTP-U解封装
↓
Session查找
↓
PDR/FAR匹配
↓
转发整体架构如下:
N3
|
|
+-------------+
| Gateway |
+-------------+
|
|
N6实验室压测结果:
| 项目 | 数值 |
|---|---|
| Worker | 16 |
| CPU频率 | 3.0GHz |
| Session | 10万 |
| PPS | 350万 |
| 时延 | <80us |
结果非常理想。
上线一个月后却收到告警:
流量增长后出现丢包
业务时延明显升高但查看系统状态时却发现一个奇怪现象:
top结果:
16个Worker
全部100%开发人员第一反应:CPU已经满了,需要增加服务器。
但事实证明:
这完全是误判。
二、DPDK为什么CPU永远100%
先解释一个很多传统Linux开发者容易误解的问题。
Linux Socket程序:
while(1)
{
recvfrom(fd,...);
}没包时:
线程睡眠CPU利用率下降。
而DPDK:
while(1)
{
nb_rx = rte_eth_rx_burst(...);
process();
rte_eth_tx_burst(...);
}即使没有任何流量:
Worker仍在轮询RX Ring因此:
CPU永远100%这意味着:
CPU利用率
不能作为DPDK程序性能指标真正重要的是:
PPS
Cycle Per Packet
Cache Miss三、问题的第一现场
进一步统计:
| 指标 | 数值 |
|---|---|
| Worker数 | 16 |
| CPU | 100% |
| PPS | 80万 |
| Session | 220万 |
奇怪的地方出现了:
实验室:
10万Session
350万PPS现网:
220万Session
80万PPSCPU同样100%。
为什么性能差了4倍?
四、perf告诉了真相
执行:
perf stat -e cycles,instructions,cache-misses结果:
cycles 3.2e12
instructions 2.1e12
cache-misses 5.8e10继续:
perf record
perf report热点函数:
rte_hash_lookup占比:
42%这意味着:
CPU大部分时间
都在查Session五、Session表设计出了问题
Session结构:
struct upf_session
{
uint64_t seid;
uint32_t teid;
pdr_t pdr;
far_t far;
qer_t qer;
statistics_t stat;
timer_t timer;
};大小:
约256Byte现网:
220万Session总内存:2200000 × 256B ≈ 563MB
即:
约560MB看起来不大。
但问题来了。
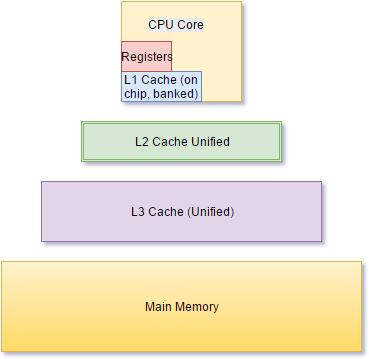
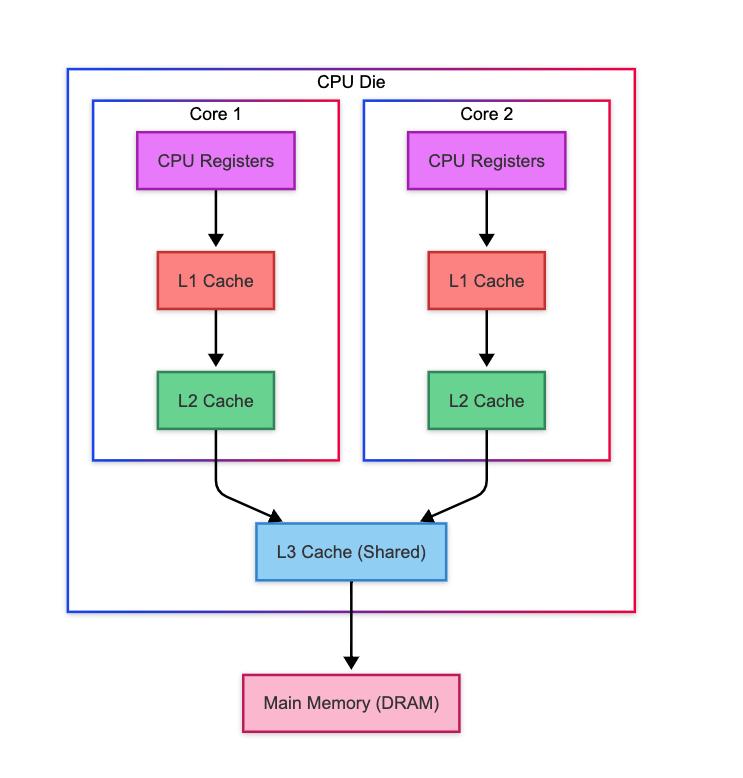
六、CPU真正害怕的东西:Cache Miss
现代Xeon:
| 层级 | 大小 |
|---|---|
| L1 | 32KB |
| L2 | 1MB |
| L3 | 30MB~60MB |
而Session表:
560MB远超L3容量。
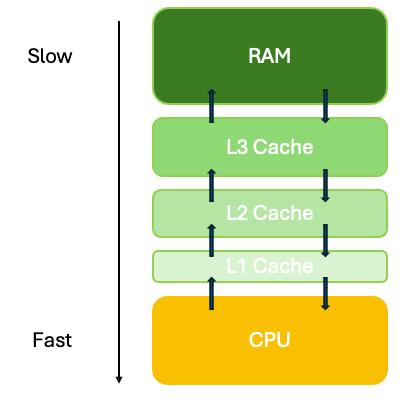
于是:
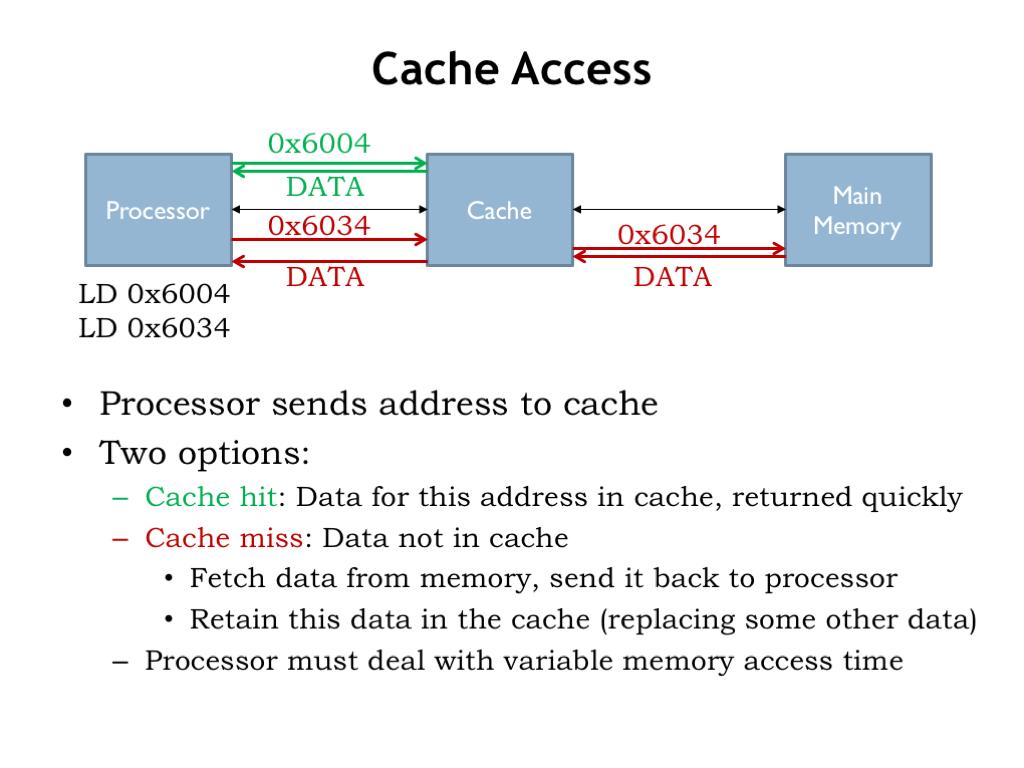
每个包到来:
TEID
↓
Hash
↓
Session Lookup
↓
DRAM访问CPU开始等待内存。
七、CPU其实一直在发呆
很多人认为:
CPU 100%
说明CPU很忙实际上:
CPU可能正在:
等待内存返回数据例如:
L1访问:
1nsL2:
4nsL3:
10nsDRAM:
80~120ns差距超过:
100倍于是:
CPU看似100%
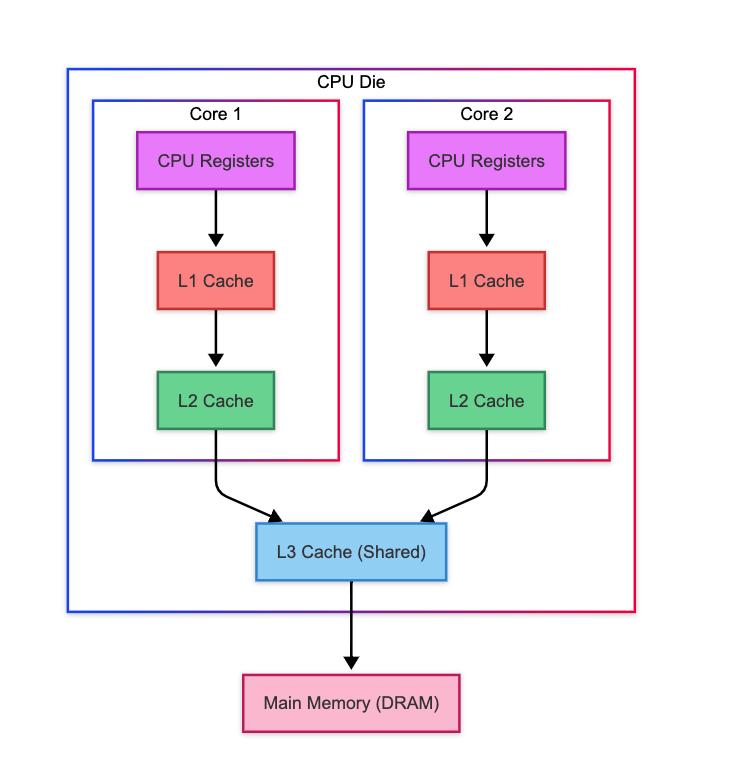
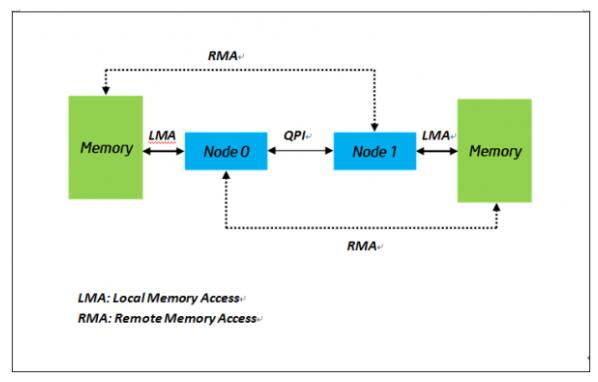
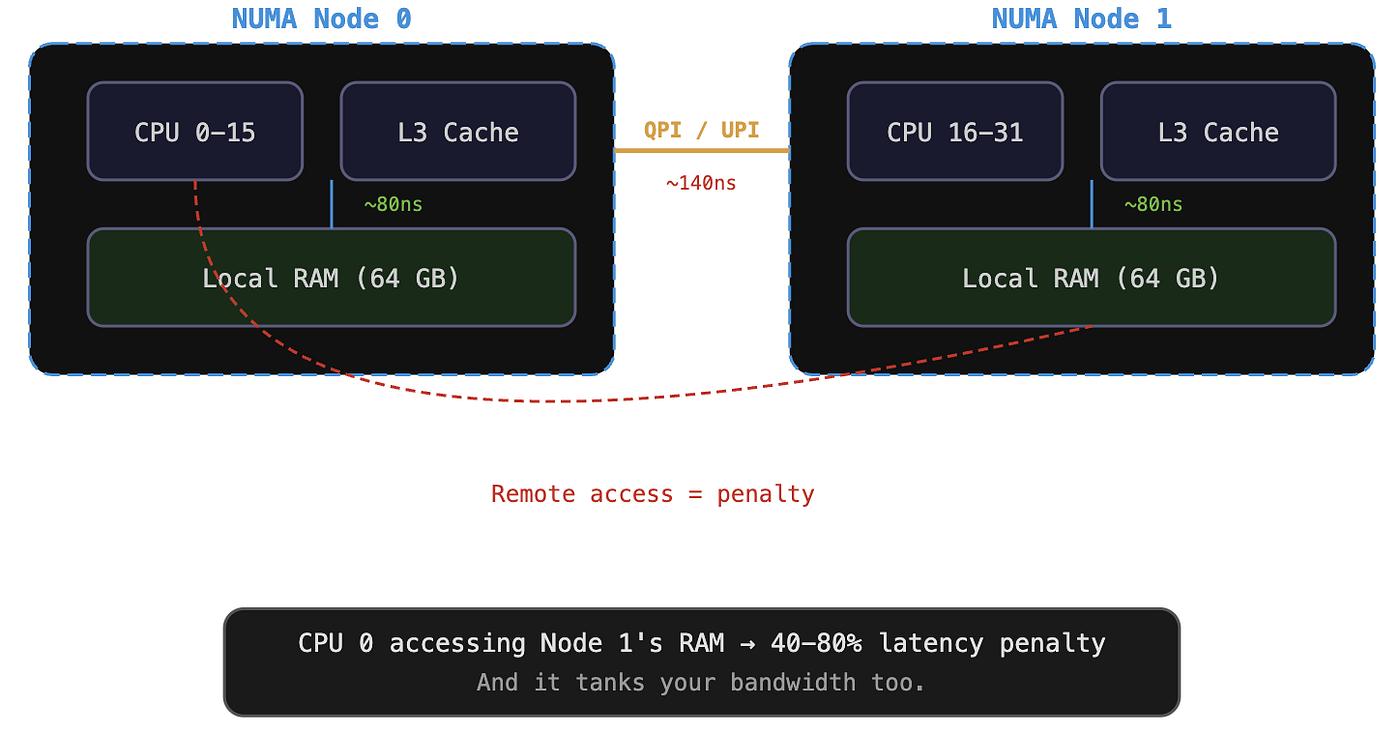
实际上大量Cycle被浪费八、NUMA又补了一刀
服务器配置:
2 Socket结构:
Socket0
├─CPU 0~15
└─Memory0
Socket1
├─CPU16~31
└─Memory1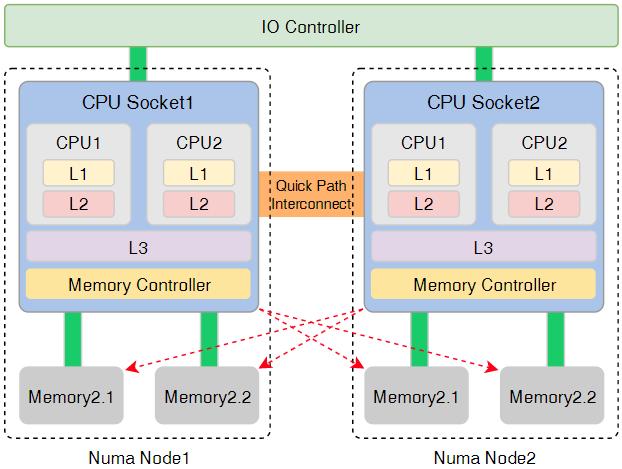
检查发现:
Worker运行在Socket0
Session分配在Socket1于是:
跨NUMA访问延迟从:
90ns变成:
150ns+PPS进一步下降。
九、更隐蔽的问题:共享状态
原始架构:
RX
|
----------------
| | |
W0 W1 W2
|
|
Global Session Table统计信息:
session->pkt_cnt++;多个Worker同时更新。
于是:
Cache Line竞争开始出现。
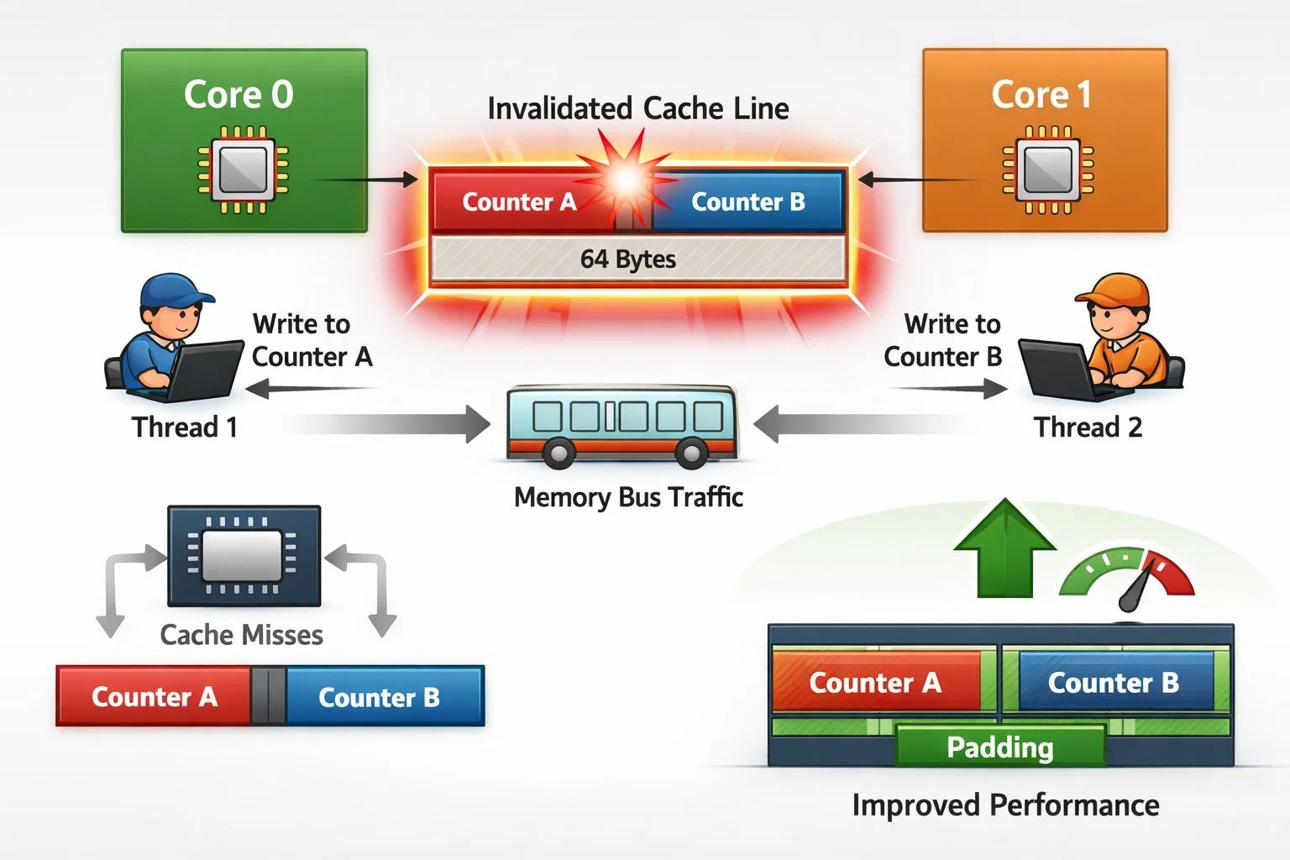
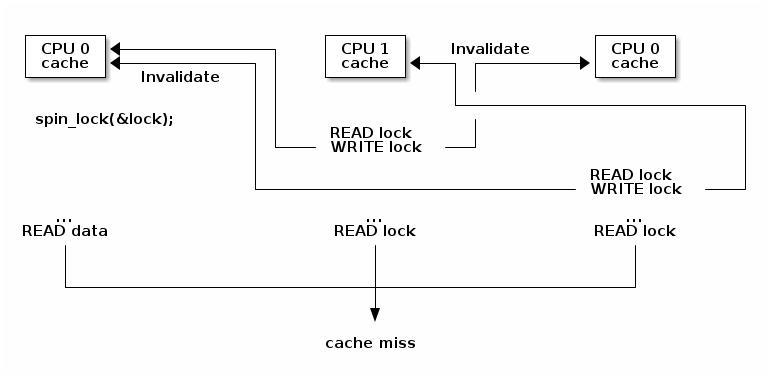

即使没有显式加锁:
MESI协议也会导致:
Cache Line Ping-Pong性能进一步恶化。
十、为什么Flow Affinity如此重要
高性能网关最重要原则:
同一Flow永远属于同一个Worker例如:
worker_id = teid % worker_num;架构变成:
Dispatcher
|
--------------------------------
| | | | |
V V V V V
W0 W1 W2 W3 W4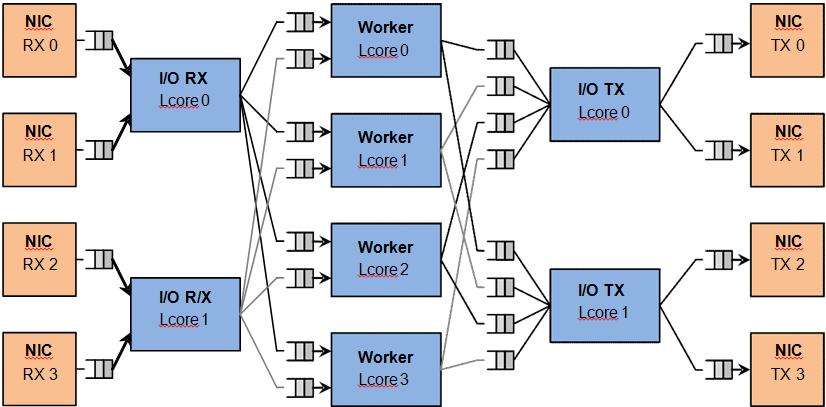
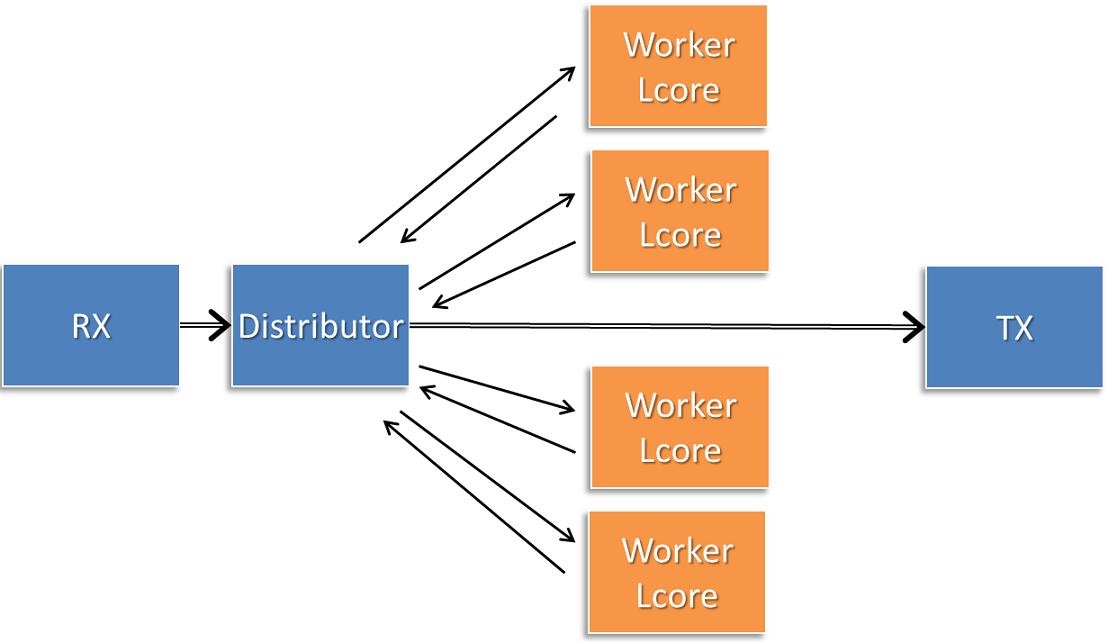
这样:
同一个TEID
固定进入同一个Worker十一、状态本地化
进一步优化:
不要:
Global Session Table改为:
Worker0 Session Pool
Worker1 Session Pool
Worker2 Session Pool
Worker3 Session Pool即:
State Ownership原则:
谁处理Flow
谁拥有State这样:
无锁
无竞争
无跨核同步十二、Dispatcher + Worker架构
最终架构:
NIC
|
RX Queue
|
Dispatcher
|
-----------------------------------
| | | | |
V V V V V
Worker0 Worker1 Worker2 Worker3 Worker4
| | | | |
| | | | |
Session Session Session Session SessionDispatcher职责:
解析GTP-U头
提取TEID
Hash分发Worker职责:
Session Lookup
PDR匹配
FAR执行
QER处理
转发Session仅属于本Worker。
十三、批处理带来的收益
不要:
process_one_packet();要:
rte_eth_rx_burst();例如:
32 Packet一批处理。
收益:
- 更高Cache命中率
- 更少函数调用
- 更好的流水线利用率
- 更少Ring访问次数
十四、优化后的结果
优化前:
| 指标 | 数值 |
|---|---|
| Worker | 16 |
| CPU | 100% |
| PPS | 80万 |
| Session | 220万 |
| Cycle/Packet | 6000+ |
优化后:
| 指标 | 数值 |
|---|---|
| Worker | 16 |
| CPU | 100% |
| PPS | 420万 |
| Session | 220万 |
| Cycle/Packet | 1100 |
可以看到:
CPU始终100%
但吞吐提升超过5倍这才是DPDK系统真实的优化效果。
十五、高性能网关设计原则
经过这次故障分析,可以总结出高性能网关设计的五条核心原则:
1. Flow Affinity
同一Flow固定进入同一Worker。
2. State Ownership
状态归属线程。
3. NUMA Awareness
网卡、CPU、内存保持同NUMA。
4. Batch Processing
尽可能批量处理数据包。
5. Cache First
设计首先考虑Cache命中率,而不是代码优雅性。
结语
许多开发者认为高性能网关的瓶颈来自CPU主频、核数或者算法复杂度。但在现代DPDK系统中,更常见的情况是:CPU已经100%运行,却有大量周期浪费在等待内存、跨NUMA访问和缓存一致性维护上。
从本质上说,高性能网关优化的核心并不是让CPU更忙,而是让CPU把每一个Cycle都花在真正的数据处理上。当Flow、State、Cache和NUMA形成统一设计时,系统才能从百万PPS平滑扩展到数百万甚至千万PPS,这也是UPF、CGNAT和下一代边缘网关架构设计的关键所在。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)