【LangChain-AI】聊天模型--调用工具
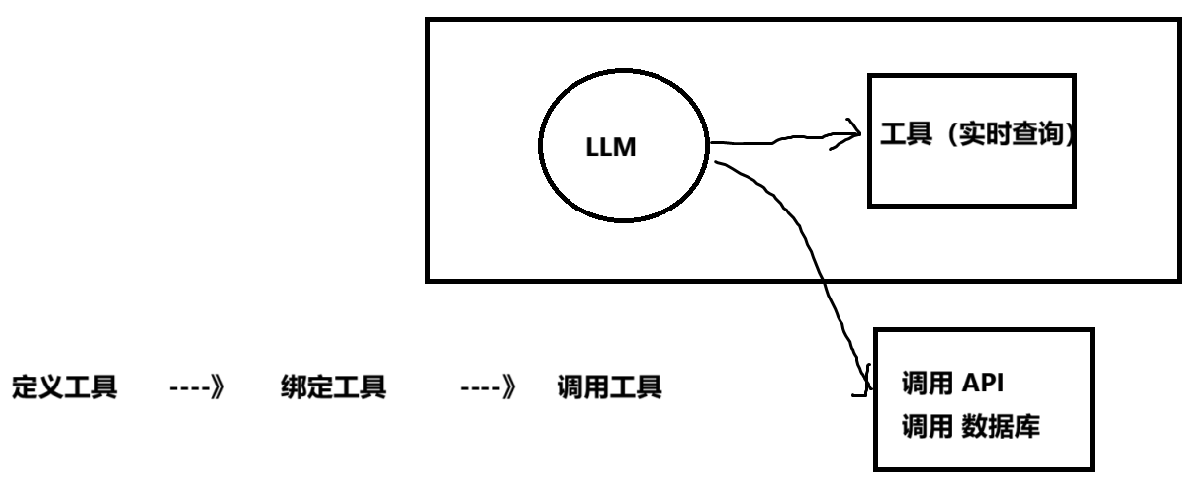
工具调用根本作用是让大语言模型(LLM)具备与外部世界交互的能力。
LLM 本身是一个封闭的知识系统,其能力受限于其训练数据(存在滞后性)和内在的文本生成逻辑。它无法执行直接计算、查询实时信息、操作数据库或调用任何外部 API。工具调用打破了这层壁垒,其作用具体体现在:
-
扩展能力边界:模型可以借助工具完成它自身无法完成的任务,如执行数学计算、搜索网络、查询数据库等。
-
保证信息实时性:通过调用搜索工具或数据库查询工具,LLM 可以获取最新的、训练数据中不存在的信息,避免回答过时或“一本正经地胡说八道”。
-
处理复杂任务:将一个复杂的用户请求(如“分析我上个月的消费趋势”)分解成多个步骤,并依次调用不同的工具(如“从数据库获取数据” -> “用 Python 进行数据分析” -> “生成图表”)来协同完成。协调这件事这更体现在 Agent 智能体上。
-
连接现有系统:可以将企业内部已有的系统、API 和数据库封装成工具,让 LLM 成为一个用自然语言驱动的统一接口,极大地提升了自动化和集成能力。
所以,在 LangChain 中,聊天模型害提供了工具调用的功能。
1. 创建工具
1.1. 方式一:使用@tool装饰器创建工具
1.1.1 模式1:常规用法
使用@tool和 python 函数来创建:
from langchain_core.tools import tool
# 定义工具
@tool
def add(a:int, b:int) -> int:
return a + b
print(add.invoke({"a": 1, "b": 2}))
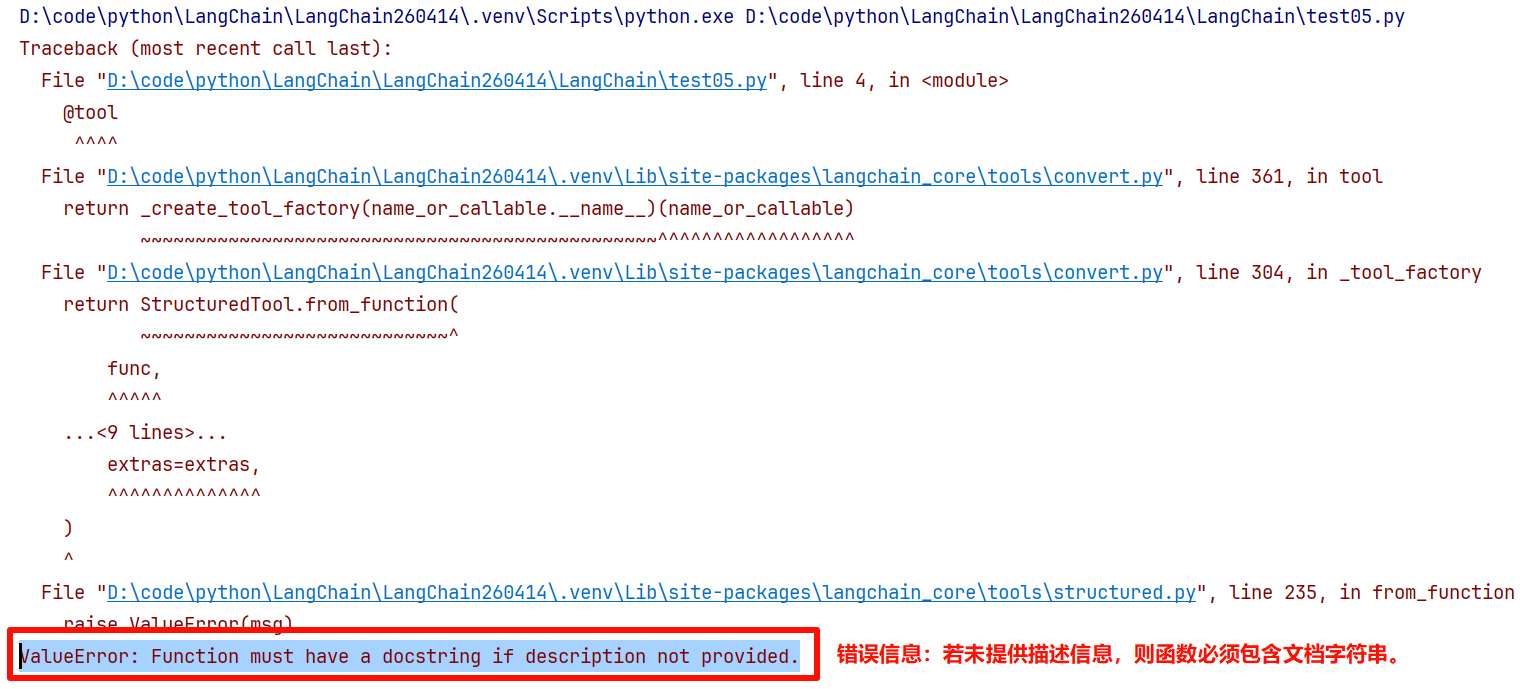
此时如果运行,会出现报错,报错信息如下:
那我们接下来就给它一个字符串文档:
from langchain_core.tools import tool
# 定义工具
@tool
def add(a:int, b:int) -> int:
"""两数相加
Args:
a:第一个整数
b:第二个整数
"""
return a + b
print(add.invoke({"a": 1, "b": 2}))
此时再次进行运行,结果正确:

结论:函数名、字符串文档和类型提示都需要定义。
类型提示:参数的类型 & 返回值的类型。
工具的属性:工具名称(函数名)、工具描述(文档字符串)、工具参数(类型提示)。
为什么需要定义这些呢?
这些信息都是传递给工具 schema 的。
1.1.2. 什么是 Schema?
JSON 我们大家都很熟悉,JSON schema 是用来描述整个 JSON结构的。
有了JSON Schema之后,就可以知道JSON长什么样,用来做校验工作。
那么同理,工具也是有属性的,工具 Schema 是用来描述工具结构的。
from langchain_core.tools import tool
# 定义工具
@tool
def add(a:int, b:int) -> int:
"""两数相加
Args:
a:第一个整数
b:第二个整数
"""
return a + b
print(add.invoke({"a": 1, "b": 2}))
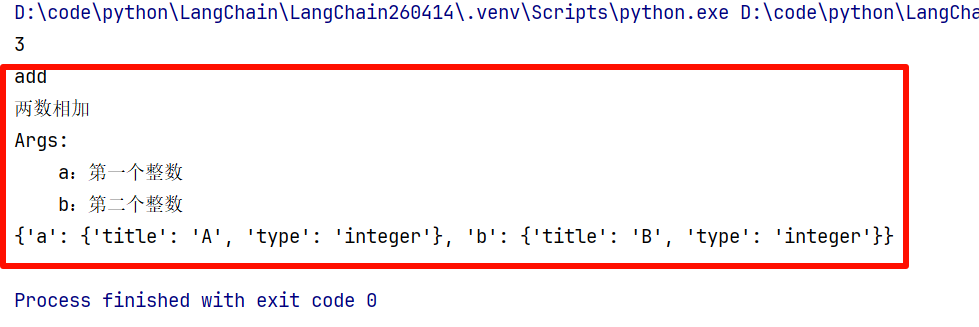
# 获取工具名称、描述、参数
print(add.name)
print(add.description)
print(add.args)
运行结果:
1.1.3. 工具为什么需要这些属性?
属性:工具名称、工具描述、工具参数。
我们定义的这些工具是要提供给聊天模型调用的,我们将提示词写的越标准,聊天模型给我们的回复也会更高可用。
对于工具来说:
1. 工具的名称可以让 LLM 知道有哪些工具,可以调用哪些工具。
2. 工具的描述实际上就是在写提示词,告诉模型工具的能力,让模型在执行任务的时候知道调用哪个工具。
3. 工具的参数可以让模型知道怎么调用工具,要传入什么参数,传入的参数类型是什么。
只要能把工具的这三个属性传递过去,就能定义出来工具。
1.1.4. 文档字符串
推荐使用 Google 风格的文档字符串。
def fetch_data(url, retries=3):
"""从给定的URL获取数据。
Args:
url (str): 要从中获取数据的URL。
retries (int, optional): 失败时重试的次数。默认为3。
Returns:
dict: 从URL解析的JSON响应。
"""
# ... 函数实现 ...
1.1.5. 模式2:依赖 Pydantic 类
在LangChain中,可以使用Pydantic,它提供了运行时数据的校验和类型检查。
from langchain_core.tools import tool
from pydantic import BaseModel, Field
# 定义参数(add工具的输入)
class AddInput(BaseModel):
"""两数相加"""
a: int = Field(..., description="第一个整数") # 三个点表示:这个字段的必填的,没有默认值
b: int = Field(..., description="第二个整数")
# 将参数传递给tool
@tool(args_schema=AddInput)
def add(a:int, b:int) -> int:
return a + b
print(add.invoke({"a": 1, "b": 2}))
# 获取工具名称、描述、参数
print(add.name)
print(add.description)
print(add.args)
运行结果:

1.1.6. 模式2:依赖 Annotated
from typing import Annotated
from langchain_core.tools import tool
# 定义工具
@tool
def add(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相加
Args:
a:第一个整数
b:第二个整数
"""
return a + b
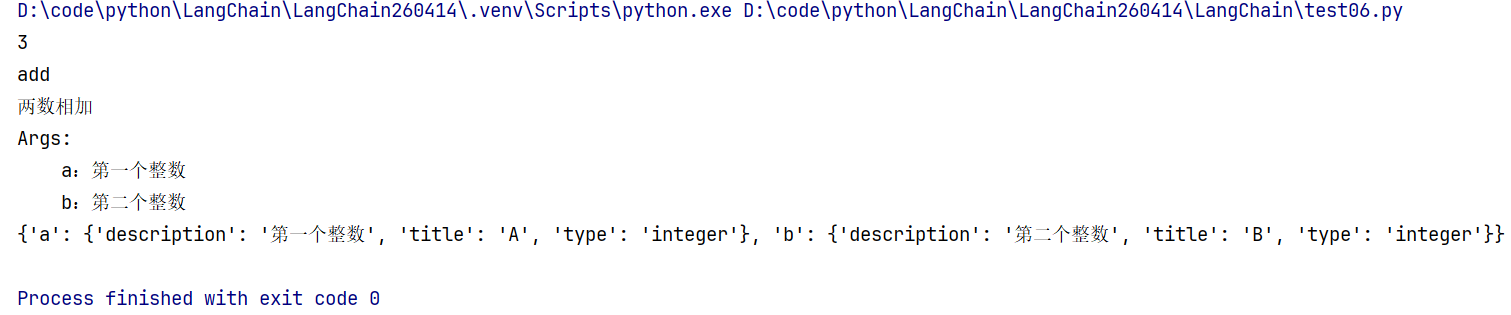
print(add.invoke({"a": 1, "b": 2}))
# 获取工具名称、描述、参数
print(add.name)
print(add.description)
print(add.args)
1.2. 方式二:使用 StructuredTool 类提供的函数创建工具
1.2.1. 常规用法
# 使用StructuredTool类提供的函数创建工具
from langchain_core.tools import StructuredTool
# 定义方法
def add(a:int, b:int) -> int:
"""两数相加"""
return a + b
# 定义工具
add_tool = StructuredTool.from_function(func=add)
# 执行工具
print(add_tool.invoke({"a": 1, "b": 2}))
1.2.2 加入配置,依赖Pydantic类
# 使用StructuredTool类提供的函数创建工具
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
# 定义参数
class AddInput(BaseModel):
a: int = Field(description="第一个整数")
b: int = Field(description="第二个整数")
def add(a:int, b:int) -> int:
return a + b
# 定义工具
add_tool = StructuredTool.from_function(
func=add,
name="ADD", # 工具名
description="两数相加", # 工具描述
args_schema=AddInput, # 工具参数
)
# 执行工具
print(add_tool.invoke({"a": 1, "b": 2}))
print(add_tool.name)
print(add_tool.description)
print(add_tool.args)
1.1.3. 加入 response_format 配置
可以保留工具调用的过程。保留过程可以帮助我们在出现问题的时候分析问题。
# 使用StructuredTool类提供的函数创建工具
from typing import Tuple, List
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
# 定义方法
class AddInput(BaseModel):
a: int = Field(description="第一个整数")
b: int = Field(description="第二个整数")
# 方法返回一个元组, str是返回的结果,List[int]是保留的过程
def add(a: int, b: int) -> Tuple[str, List[int]]:
nums = [a, b]
content = f"{nums}两数相加的结果是{a + b}"
return content, nums
# 定义工具
add_tool = StructuredTool.from_function(
func=add,
name="ADD", # 工具名
description="两数相加", # 工具描述
args_schema=AddInput, # 工具参数
response_format="content_and_artifact" # 大模型不知道工具返回的结果中哪部分是结果,哪部分是过程,加上这个参数才能让大模型区分开。
)
# 执行工具
# print(add_tool.invoke({"a": 1, "b": 2})) # 这样调用的结果只会显示结果,不会显示过程,是因为这种调用方法是手动调用工具的写法,需要模拟大模型调用工具的方式,才能看到过程。
# print(add_tool.name)
# print(add_tool.description)
# print(add_tool.args)
# 模拟大模型调用工具
print(add_tool.invoke(
{
"name": "ADD",
"args": {"a": 1, "b": 2},
"type": "tool_call", # 调用类型 必填
"id": "111" # id:工具调用的关联标识符,大模型要调用ADD工具,需要用id将工具调用请求和工具调用结果关联起来,必填
}
))
输出结果:
对于聊天模型来说,就可以通过字段content获取结果,通过字段artifact获取过程。但是实际上聊天模型是获取content为主的。
2. 工具绑定与调用
from typing import Annotated
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
# 定义工具
@tool
def add(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相加"""
return a + b
@tool
def multiply(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相乘"""
return a * b
# 定义model
model = ChatDeepSeek(model="deepseek-chat")
# 绑定工具
tools = [add, multiply]
# 返回了一个新的Runnable,一个绑定了新的工具的model
model_with_tools = model.bind_tools(tools=tools)
# 调用工具
print(model_with_tools.invoke("2乘3等于多少???"))
输出结果
content='2乘3等于6。\n\n我们可以用工具计算一下:' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 71, 'prompt_tokens': 371, 'total_tokens': 442, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 371}, 'model_provider': 'deepseek', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402', 'id': '3fce2ee8-ac0a-4f1d-b67d-e6acec32d09c', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--019e972c-35da-7101-884d-4e91e9d9f4c2-0' tool_calls=[{'name': 'multiply', 'args': {'a': 2, 'b': 3}, 'id': 'call_00_5Lc30LrcTN4I4YZA49Jk2866', 'type': 'tool_call'}] invalid_tool_calls=[] usage_metadata={'input_tokens': 371, 'output_tokens': 71, 'total_tokens': 442, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
对返回的结果格式化一下:
content = '2乘3等于6。\n\n我们可以用工具计算一下:'
additional_kwargs = {
'refusal': None
}
response_metadata = {
'token_usage': {
'completion_tokens': 71,
'prompt_tokens': 371,
'total_tokens': 442,
'completion_tokens_details': None,
'prompt_tokens_details': {
'audio_tokens': None,
'cached_tokens': 0
},
'prompt_cache_hit_tokens': 0,
'prompt_cache_miss_tokens': 371
},
'model_provider': 'deepseek',
'model_name': 'deepseek-v4-flash',
'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402',
'id': '3fce2ee8-ac0a-4f1d-b67d-e6acec32d09c',
'finish_reason': 'tool_calls',
'logprobs': None
}
id = 'lc_run--019e972c-35da-7101-884d-4e91e9d9f4c2-0'
tool_calls = [{
'name': 'multiply',
'args': {
'a': 2,
'b': 3
},
'id': 'call_00_5Lc30LrcTN4I4YZA49Jk2866',
'type': 'tool_call'
}] invalid_tool_calls = [] usage_metadata = {
'input_tokens': 371,
'output_tokens': 71,
'total_tokens': 442,
'input_token_details': {
'cache_read': 0
},
'output_token_details': {}
}
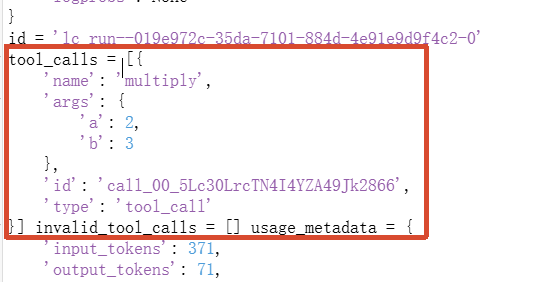
可以看到,大模型在执行任务的时候,根据我们的提示词语义选择并调用了我们给它绑定的工具。
2.1 强制大模型调用工具
大模型是否调用工具,是根据我们的提示词语义和工具的相关性来决定的,并不是说,我们给它绑定了工具,它就每次都调用工具,但是我们可以强制大模型调用某个工具。
只需要在绑定工具的时候,加上一个参数,并设置其值为any:
model_with_tools = model.bind_tools(tools=tools, tool_choice="any")
调用结果:
可以看到它确实调用了我们指定的工具,但是content是空的。
2.2 将工具输出传递给聊天模型
上面我们调用工具,虽然可以拿到计算结果,但是它返回的结果不是我们想要的形式,我们希望它返回2 * 3的结果为:6,而不是单单的一个6。
上面我们调用大模型返回的结果中有一个tool_calls字段,可以看到,这个字段中的内容,和我们上面模拟大模型调用姿势的时候是一模一样的。
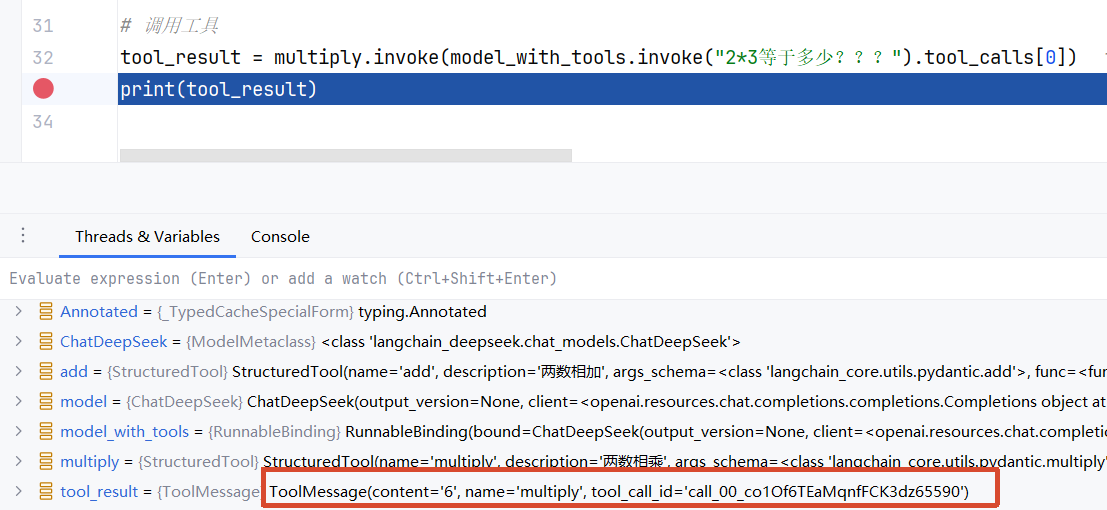
通过调试可以看到,工具调用返回的是一个ToolMesage。那么我们就可以构造在一个messages消息列表,将其传给大模型。
from typing import Annotated
from langchain_core.messages import HumanMessage
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
# 定义工具
@tool
def add(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相加"""
return a + b
@tool
def multiply(
a : Annotated[int, ..., "第一个整数"],
b : Annotated[int, ..., "第二个整数"],
) -> int:
"""两数相乘"""
return a * b
# 定义model
model = ChatDeepSeek(model="deepseek-chat")
# 绑定工具
tools = [add, multiply]
# 返回了一个新的Runnable,一个绑定了新的工具的model
model_with_tools = model.bind_tools(tools=tools, tool_choice="any")
# 调用工具
# tool_result = multiply.invoke(model_with_tools.invoke("2*3等于多少???").tool_calls[0])
# print(tool_result)
# 定义消息列表,添加要传递给聊天模型的消息
message = [
HumanMessage("2*3等于多少???;2+1等于多少???"),
]
ai_msg = model_with_tools.invoke(message)
message.append(ai_msg)
# print(ai_msg)
# 我们给了两个问题,分别调用了两个工具,tool_calls中也有两个元素。
# tool_calls = [
# {'name': 'multiply','args': {'a': 2,'b': 3},'id': 'call_00_KQZFPPxU1AfuVwTZciOL0371','type': 'tool_call'},
# {'name': 'add','args': {'a': 2,'b': 1},'id': 'call_01_z1Zq9jSk9vlHmgU73uP40488','type': 'tool_call'}
# ]
# 构建toolmessage,并添加到消息列表中
for too_call in ai_msg.tool_calls:
# 定义一个查找的字典,并通过tool_call里面的name(忽略大小写)去查找tool
selected_tool = {"add": add, "multiply": multiply}[too_call["name"].lower()]
tool_msg = selected_tool.invoke(too_call)
message.append(tool_msg)
print(message)
print(model.invoke(message).content)
输出结果: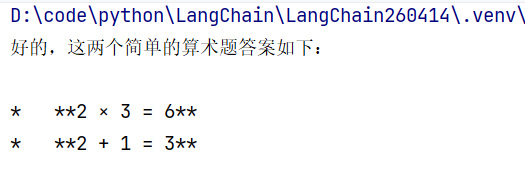

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)