重磅开源!LocateAnything 一站式搞定全场景视觉定位,解码速度暴涨 10 倍
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录

一、摘要
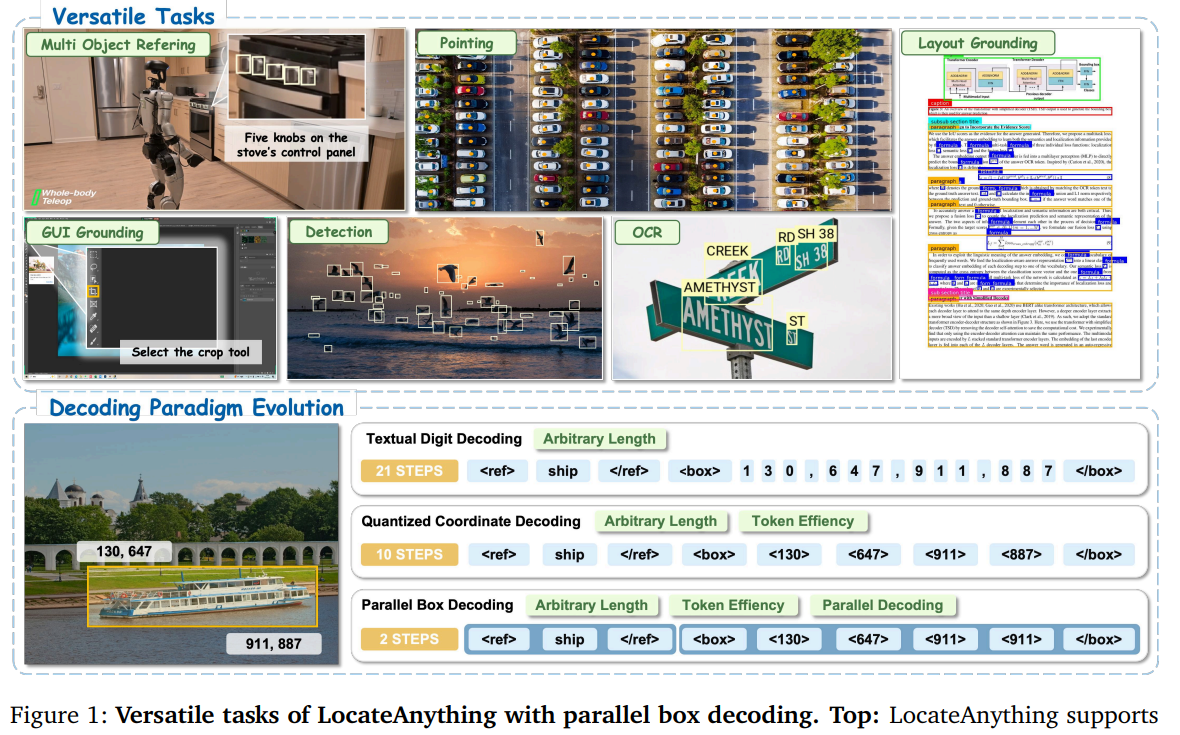
传统多模态大模型做视觉定位、目标检测时,大多把检测框坐标拆分成逐个token串行生成,串行推理不仅速度慢,还割裂坐标之间的空间关联,容易出现定位精度不足的问题。来自NVIDIA联合港理工、普林斯顿、南大等多所高校团队提出LocateAnything,核心创新为并行框解码(PBD),将整张检测框视作不可拆分的原子单元,单步并行输出完整坐标。团队自研超大规模数据集LocateAnything-Data(总计1.38亿条标注样本、1200万张独立图片、7.85亿标注框),覆盖六大视觉定位任务。模型设计快/慢/混合三种推理模式,兼顾推理速度与定位精度,在COCO、LVIS、GUI定位、文档解析、OCR、指点定位等海量基准测试中大幅超越现有主流VLMs方案,最高解码吞吐提升2.5倍以上,打通机器人、智能体等低时延落地场景。
二、研究背景
当下视觉语言模型(VLM)已经成为通用感知交互底座,机器人、GUI自动化、文档解析等落地场景,都需要模型依托自然语言指令精准框选图像目标。但现有方案普遍采用逐token自回归(NTP)串行解码:把框坐标拆为数字字符或离散量化token逐个生成(原文图1左侧串行示例)。
这种串行结构存在两大痛点:第一,坐标 ( x 1 , y 1 , x 2 , y 2 ) (x_1,y_1,x_2,y_2) (x1,y1,x2,y2)具备强空间耦合关系,拆分编码破坏几何约束,模型容易输出畸形框、错位框;第二,逐一生成带来巨大推理时延,目标数量越多、解码步数越多,吞吐量暴跌。
现有多token预测(MTP)加速方案多随机划分文本块,无视检测框的结构化特征,容易跨框乱生成token、引入虚假关联,速度提升有限还伴随精度下滑。基于上述痛点,研究团队针对性设计框对齐式并行解码PBD,从编码结构上解决速度-精度矛盾。
三、应用场景
LocateAnything是全任务统一定位通用框架,一套模型兼容六大落地场景,覆盖工业、智能终端、办公自动化、机器人领域:
-
通用目标检测:开放集/闭集物体识别、长尾目标检测(LVIS、COCO)、密集小目标检测(无人机图像VisDrone、高密度数据集Dense200);

-
GUI界面定位:电脑/手机界面图标、按钮、输入框查找,赋能桌面智能体、自动化脚本(ScreenSpot-Pro数据集);
-
指代理解定位:依托自然语言描述圈定图像指定物体(RefCOCOg、HumanRef等指代数据集);
-
文档版面解析:PDF、图文文档图表、段落、标题分区检测(DocLayNet、M6Doc);
-
场景OCR文字检测:图片内任意印刷/手写文本框提取(TotalText、ICDAR系列OCR数据集);

-
指点任务:根据文字指令在图像中点选目标点位,适用于机器人视觉交互。
四、模型架构与方法原理介绍
4.1 整体模型架构
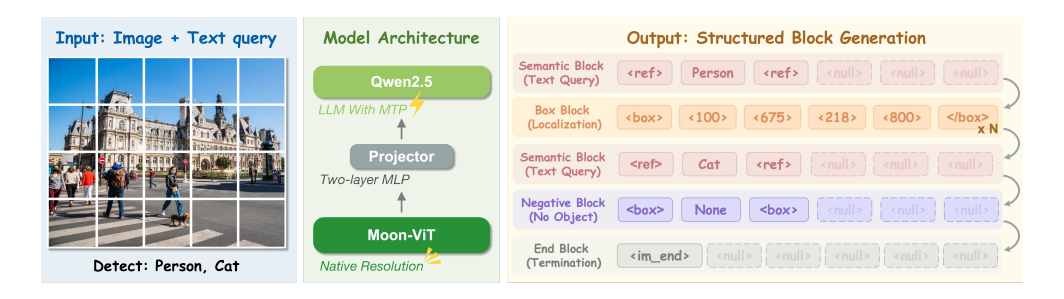
LocateAnything基于成熟VLM改造,视觉编码器选用Moon-ViT(原生分辨率编码,保留精细空间特征),文本解码器基于Qwen2.5,中间通过两层MLP映射层打通图文特征。模型摒弃传统逐坐标输出逻辑,全部输出内容统一封装为固定长度结构化Block,划分为四类功能块:语义块(存储类别/描述文本)、框块(存储完整4维坐标)、负样本块(无目标时输出)、结束块(标识生成终止),单个框Block一次性打包+四个坐标+全部内容,是并行解码的基础。
4.2 三种解码范式对比
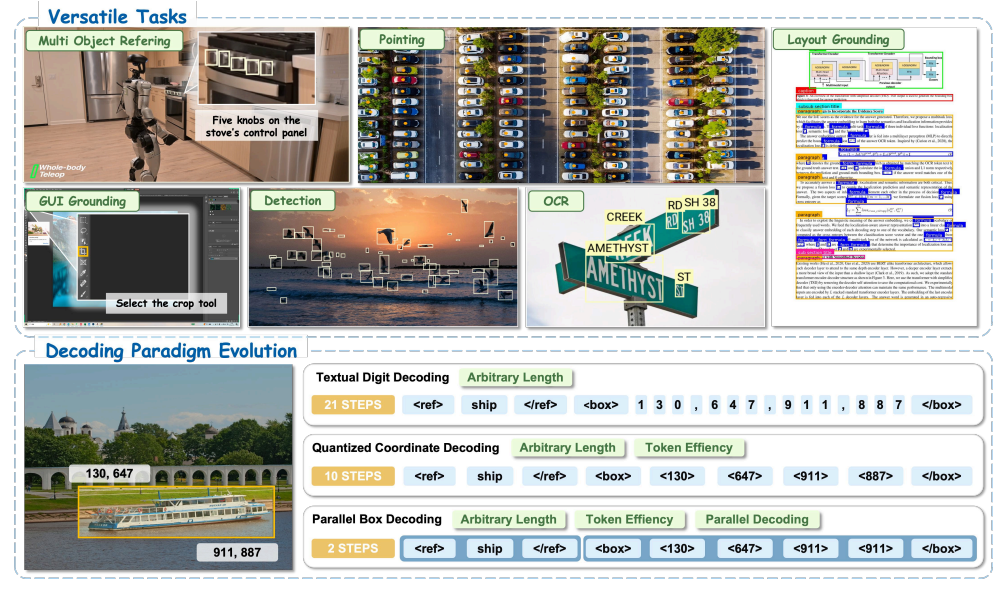
- 传统逐字符/量化NTP解码:坐标拆成单个数字依次解码,一个框需要十几步生成,串行耗时极高;
- 通用无规则MTP解码:随机切块并行预测,切块边界和检测框边界不匹配,容易出现坐标跨框错乱、空间混乱;
- 本文PBD并行框解码:单个完整BBox作为最小预测单元,一个Block一次性输出整套坐标,同框内坐标双向注意力互通,天然贴合几何关联约束。
4.3 双分支联合训练策略
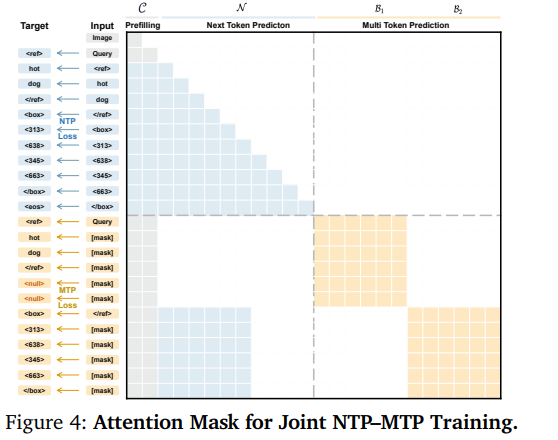
训练阶段采用NTP串行分支+PBD并行分支双损失联合优化( L = L n t p + L b l k L=L_{ntp}+L_{blk} L=Lntp+Lblk),搭配定制异构注意力掩码:
- NTP分支沿用标准因果注意力,保证模型保留原生大模型文本生成能力;
- Block跨块使用因果注意力(只能看前文Block),同Block内部开启双向注意力,让模型学习框内坐标联动规律;
训练配套Stream Packing、MagiAttention两大工程优化,解决变长序列训练显存浪费、不规则注意力加速难题。
4.4 三档自适应推理模式
模型上线提供三种可切换推理方案,按需调配速度与精度:
- 慢速模式(Slow/NTP):原生自回归逐token生成,精度上限最高,用于高精度标注、数据集精加工;
- 快速模式(Fast/PBD):全并行Block生成,吞吐量拉满,适用于端侧机器人、实时推理设备;
- 混合模式(Hybrid)【生产首选】:默认并行生成,实时校验输出:出现格式错乱、坐标置信度低于阈值时,仅对异常Block退回NTP重生成,兼顾绝大多数加速收益与输出稳定性。
4.5 自建超大训练数据集LocateAnything-Data
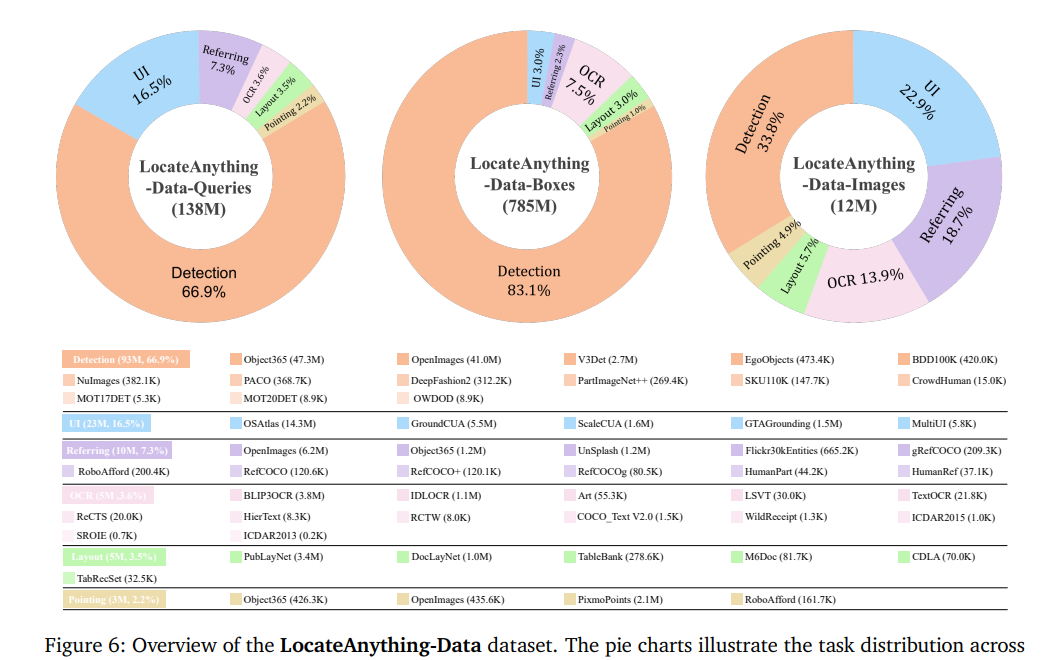
团队搭建自动化数据引擎,依托开源标注数据+无标注原图自动生成海量标注,数据集合计1.38亿条查询文本,分6大任务类目:通用检测(66.9%)、GUI定位(16.5%)、指代定位(7.3%)、OCR(3.6%)、版面解析(3.5%)、指点任务(2.2%),还人工构建海量负样本(无目标查询)抑制模型虚检;数据生成借助Qwen3-VL、Molmo、SAM3等模型自动扩充多样自然语言查询,极大提升模型泛化能力。
五、实验对比结果
5.1 通用目标检测基准
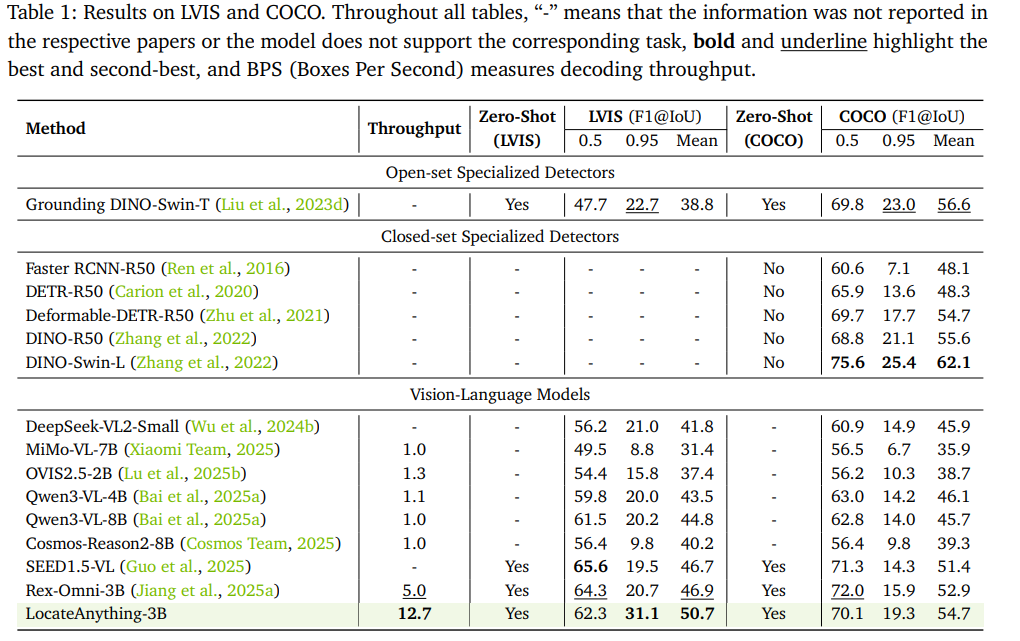
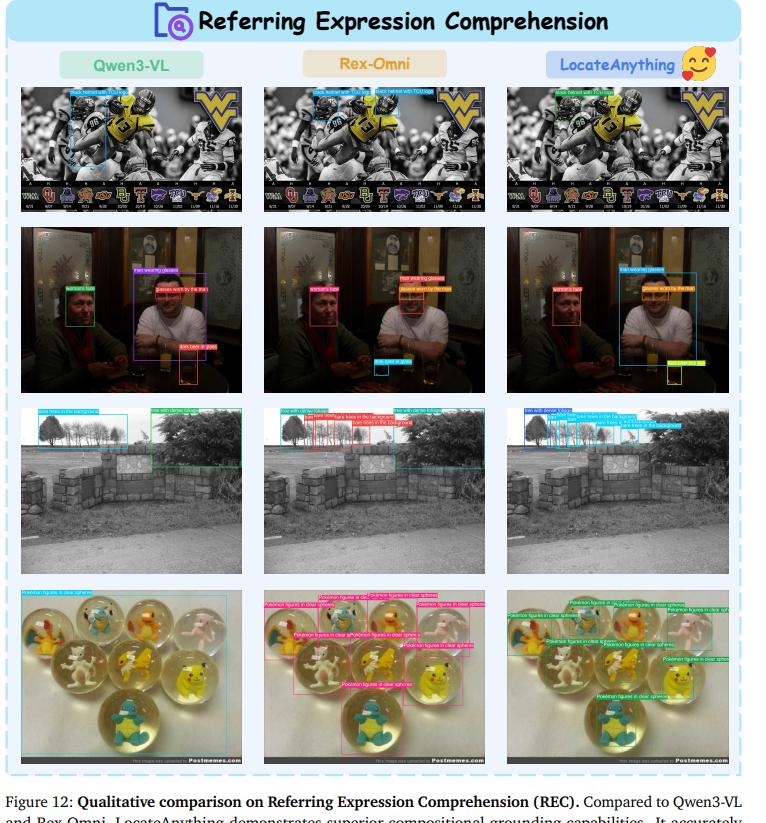
在COCO通用物体、LVIS长尾物体、VisDrone/Dense200密集小目标数据集上,LocateAnything-3B相较同参数量Rex-Omni、Qwen3-VL、DeepSeek-VL等主流VLM全面领先:
- LVIS平均F1相较Rex-Omni提升3.8%,COCO平均F1提升1.8%;
- 密集场景VisDrone均值F1达39.9,Dense200达58.7,密集堆叠物体分割效果显著优于竞品;
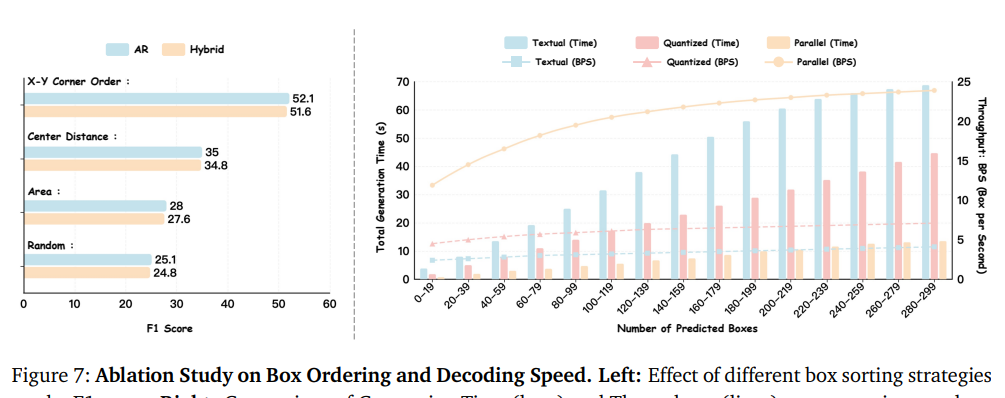
- 吞吐速率碾压基线:混合模式下12.7BPS(每秒处理框数),是Qwen3-VL(1.1BPS)的10倍以上、Rex-Omni(5.0BPS)的2.5倍(原文表1)。
5.2 细分专项任务
-
GUI界面定位:3B尺寸LocateAnything在ScreenSpot-Pro平均F1=60.3,超越7B~32B规格专用GUI大模型;
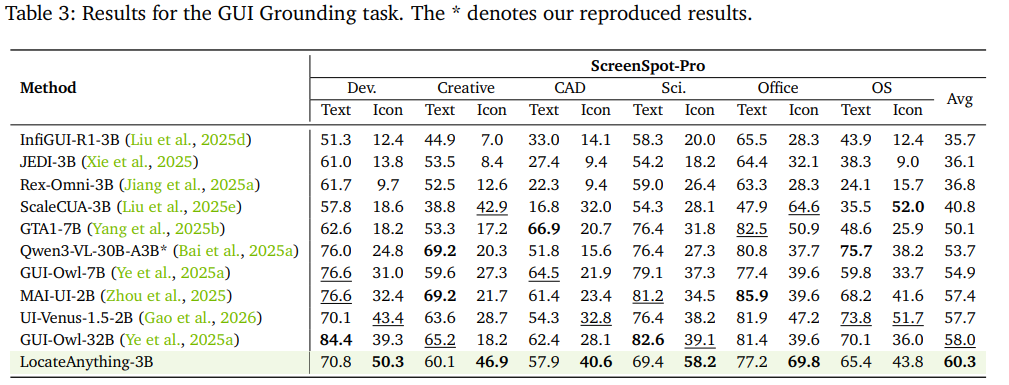
-
文档&OCR:DocLayNet均值F1=76.8、M6Doc=70.1,超过专用文档检测DocLayout-YOLO与各类VLMs;TotalText OCR指标43.3刷新SOTA;
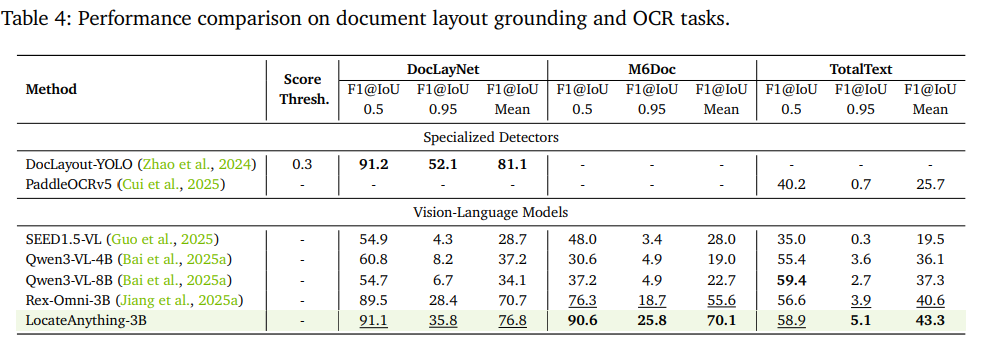
-
指代定位:HumanRef平均F1=78.7,RefCOCOg测试集77.6,精细文本描述定位优势突出;
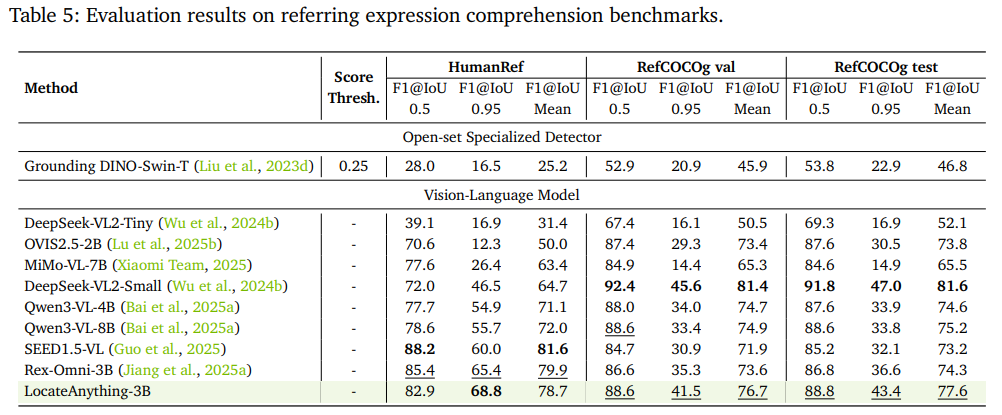
-
指点任务:COCO指点F1=83.9、Dense200=87.6,全品类指点基准全面领先同规格模型。
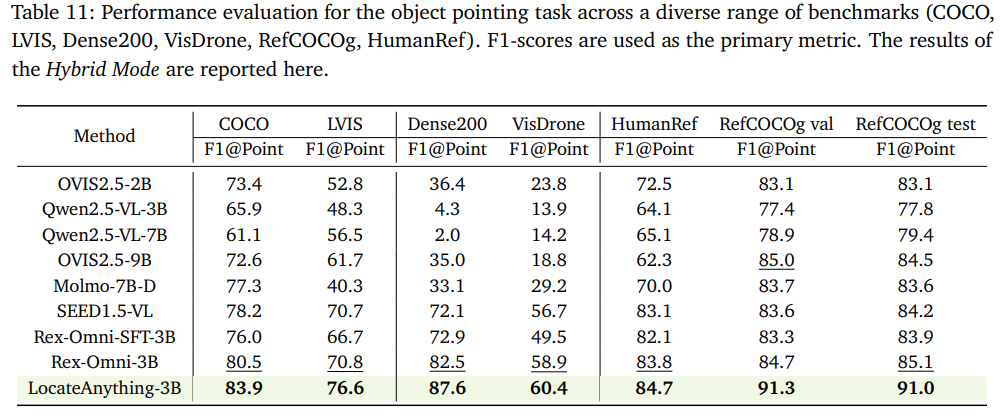
六、总结与展望
6.1 研究总结
- 方法创新:首创PBD并行框解码,打破VLM视觉定位串行解码桎梏,以检测框为原子单元并行生成,从结构匹配坐标天然几何关联;
- 工程落地优势:快/慢/混合三档推理模式,适配从实时端侧到高精度标注全场景需求;
- 数据赋能:自研千万级图片、上亿标注的多领域混合数据集,补齐多场景数据短板,实现开放域全任务定位SOTA;
- 泛化可靠:解码架构可插拔适配任意主流VLM骨干,通用性强。
6.2 未来展望
当前模型依靠监督微调完成训练,后续研究方向集中在三点:
- 引入强化学习优化Block并行生成策略,进一步降低混合模式退回NTP重解码的概率,持续提升极限推理速度;
- 拓展3D空间定位能力(论文同步衍生LocateAnything3D相关工作),落地自动驾驶、3D机器人感知;
- 持续扩充多语种、小众行业标注数据,拓展医疗影像、工业质检等垂直场景落地。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)