LSTM在“预测光伏电站最佳清洗时间点”中的应用
项目背景
在光伏电站中,由于沙尘因素的影响,会造成发电量的下降,继而导致发电收益的损失。在小型电站中,这种由沙尘造成的损失可能微不足道。但对于一些中、大型电站,由沙尘造成的收益损失会很明显,因此,需要对光伏电站进行及时清洗,而清洗时间点与增加收益、节省开支息息相关。如果清洗时间点过早,清洗费用大于沙尘给电站造成的收益损失,会导致不必要的清洗开支;如果清洗时间点过晚,沙尘给电站造成的收益损失大于清洗费用,又会给电站造成不必要的损失。因此,选择一个合适的清洗时机尤为重要。
“最佳清洗时间点”计算原理
最佳清洗时间点的选择就一个原则:当沙尘对光伏电站造成的损失大于此光伏电站的清洗费用时,就是最佳清洗时间点。虽然原理很简单,但是如何计算出“最佳清洗时间点”是一个很困难、严肃的问题。在考虑多项参数、经过各专家的研究后,结合监测设备得出了一套较为严谨的计算“最佳清洗时间点”的公式。
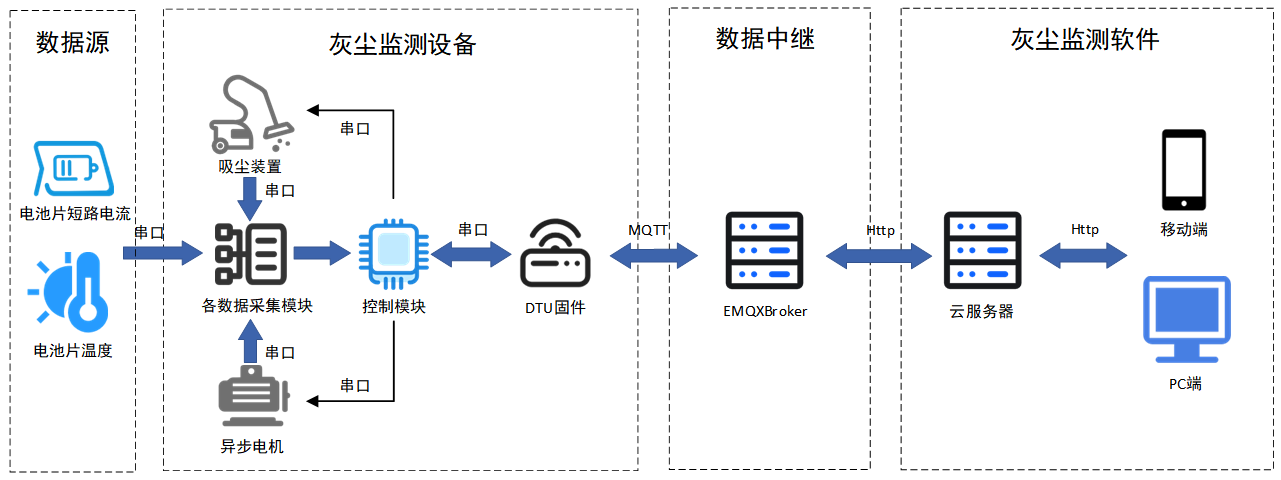
监测设备及“计算公式”原理
监测设备主要由MCU、DTU固件、INA226电流监测芯片、热电偶、两块光伏电池片(短路电流范围为0-1000ma)组成,一片自然积灰,跟光伏电站的清洁度保持同步,另外一片则由电机驱动的滚刷进行清洗,保持清洁。由于光伏电池片的短路电流与太阳辐照成正相关,灰尘遮挡会造成光伏电池片所能接收到的辐照度下降。因此,自然积灰电池片和清洁电池片之间短路电流的差值就能够表征灰尘量。公式正是利用了这一特性,再结合温度、电价、各类修正系数等参数,从而能够动态(正常积灰情况下累积收益损失增大,下雨等自然清洗因素下累积收益损失减小)地计算出整个电站的累计收益损失,进而与电站清洗费用做对比,得出“最佳清洗时间点”。
“公式计算法”存在的问题
通过公式虽然能够计算出电站的最佳清洗时间点,但是这个计算和判断是实时的,无法做到预测。例如,今天公式判断出当前电站收益损失等于或大于清洗费用,那就通知用户进行清洗。但是,用户接收到通知后往往没办法立即清洗,因为还需要进行协调人员等各项工作。在接到清洗通知与进行实际清洗操作之间,往往会有几天的窗口期,而在这个窗口期内收益损失会继续累积,对于中大型电站而言,是一笔不小的损失。因此,对于清洗时间点的预测就尤为重要。对于预测,选择了LSTM,而通过监测设备累积的数据、公式计算得到的数据则成为了训练LSTM的原始数据。
数据结构
在构建光伏电站灰尘监测LSTM预测模型时,由于缺乏大量真实传感器历史数据,所以本项目实验中基于NOCT标准温度修正模型和青海地区的气象参数,生成了5台设备跨2年、30分钟间隔的约17.5万条时序数据进行LSTM模型验证。相当于后端每30分钟接收、计算、存储一次数据,最终一共收集17.5万条数据,足够用于LSTM进行训练。模拟场景为0.1954元/kWh上网电价、清洗费用0.0145 元/W/年、电站大小200KW。
在LSTM的训练过程中,输入特征用到了:isc1(清洁电池片短路电流)、isc2(积灰电池片短路电流)、temp(电池片温度)、p_loss(功率损失)、hours_since_clean(距上次清洗时间小时数)、day_of_year(该条数据产生于一年当中的第几天)。其中,isc1、isc2、temp为监测数据,p_loss、hours_since_clean、day_of_year为计算所得的数据。训练标签为is_cleaning_day(是否清洗0/1)。

模拟数据的合理性
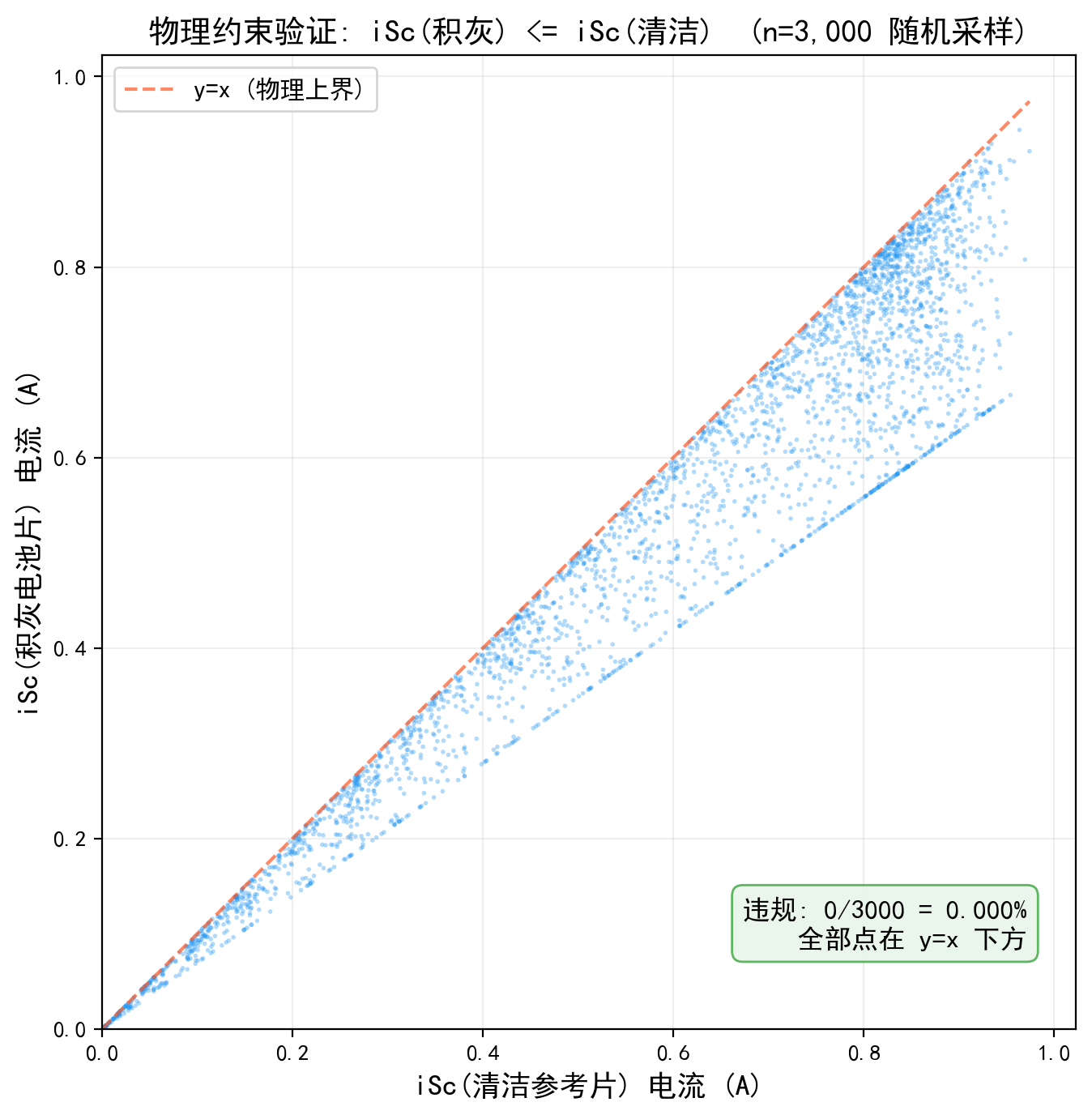
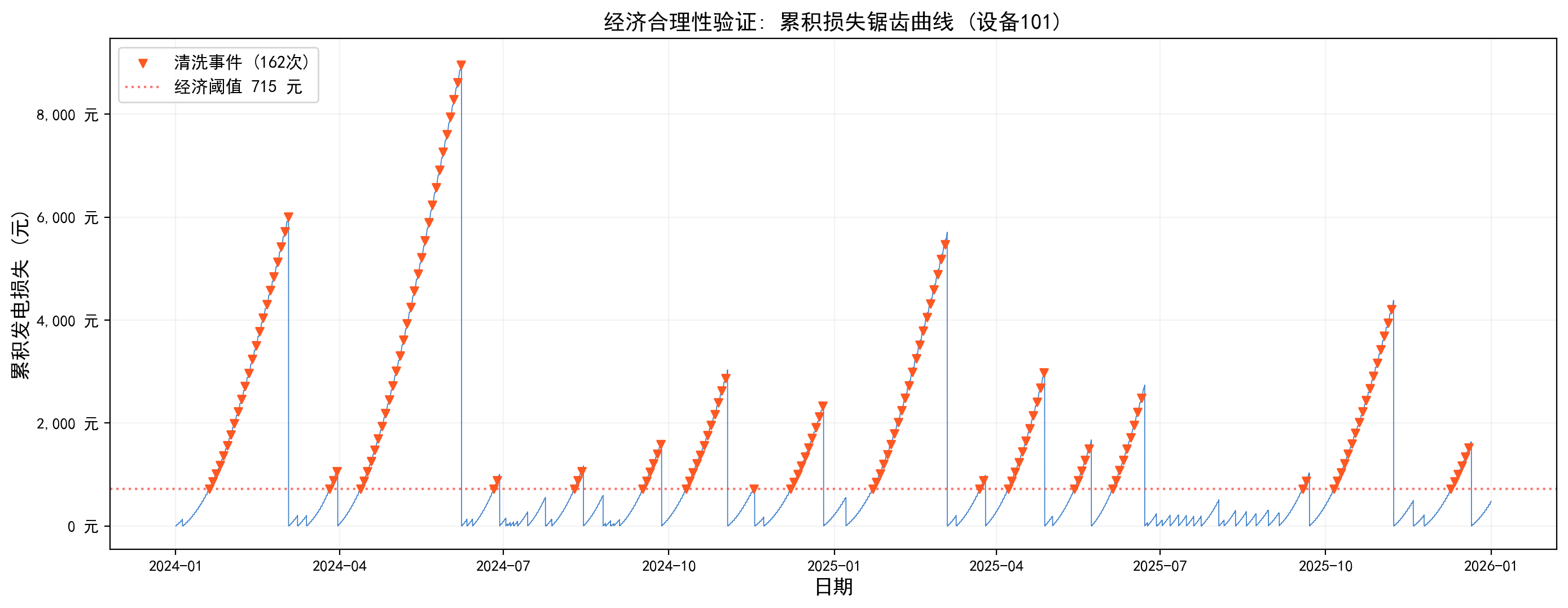
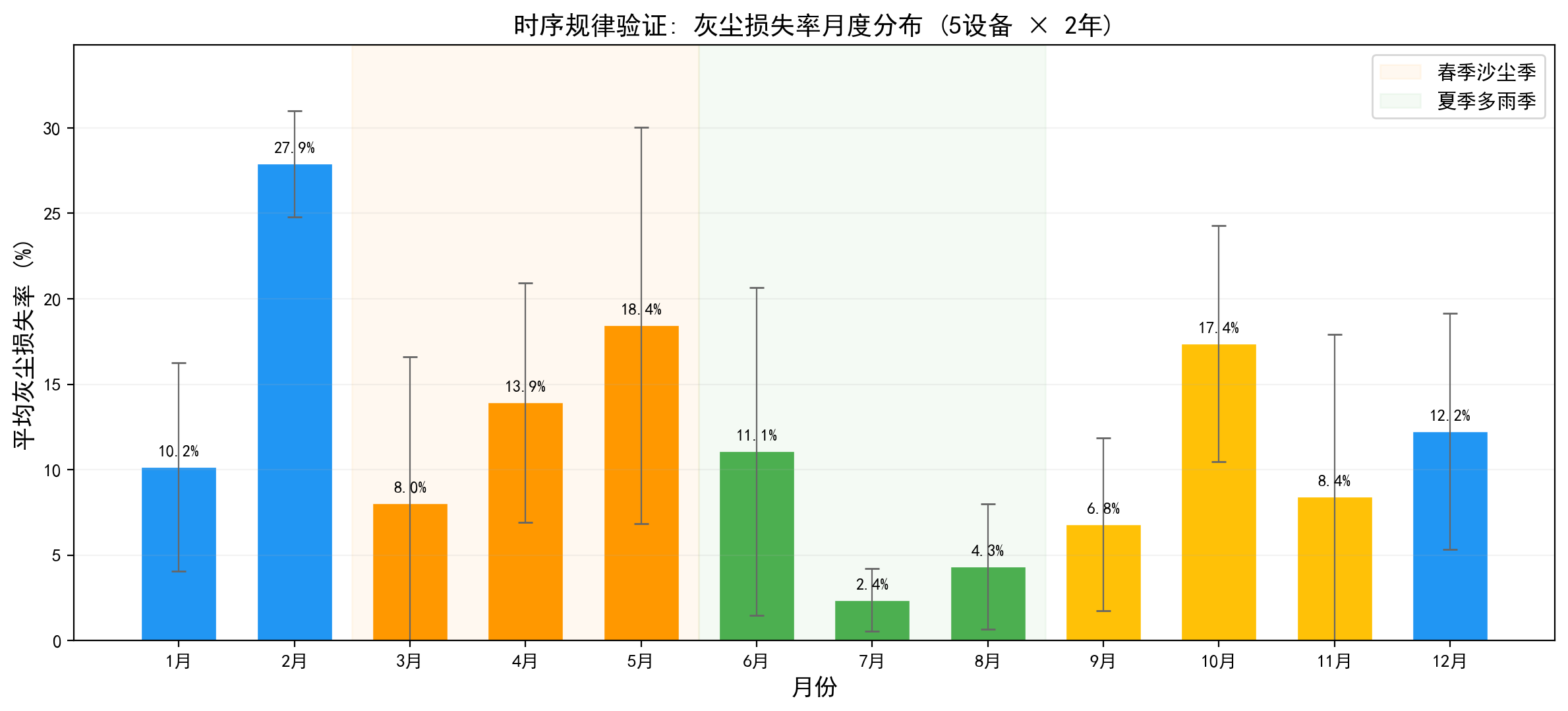
为验证数据的可信性,从三个维度交叉检验:首先是“物理约束”,灰尘监测的核心假设是积灰电池片电流(iSc₂)不超过清洁参考片(iSc₁),随机抽取3000个样本点做散点图,所有点严格落在 y=x 参考线下方,100%通过率,证明衰减模型正确嵌入了能量守恒和IV特性约束;其次是“经济决策逻辑”,清洗本质是损失与成本的比对,只有当累积发电损失超过单次清洗成本(715元,基于0.1954元/kWh电价和200kW容量)时才触发清洗,累积损失曲线呈现经典的"单调递增、触发阈值、重置归零"锯齿形态,61次清洗事件中67%由经济阈值驱动、33%来自降雨和定期维护等混杂因素,后者增加了预测难度但也更贴近真实运维场景;最后是“季节规律”,月度灰尘损失率分布与青海气候较为吻合:春季沙尘暴高发期损失率达12-15%,为全年峰值,夏季受降雨清洗效应影响骤降至2-6%的全年最低区间,秋冬温和回升至8-12%。这种显著的季节性波峰波谷为LSTM学习长周期时序依赖提供了充分信号。该数据集的正样本率仅0.46%(极度类别不平衡,与电站实际清洗频率一致),在物理规律、经济机制和统计分布上均比较合理。
LSTM的应用及调优
选用LSTM进行最佳清洗时间点的预测,其核心原因是LSTM具有“记忆性”,即它能够将上一个时间步的信息传递到下一个时间步。其次,由于LSTM中“记忆单元”、“遗忘门”、“输入门”的存在,能够有选择的遗忘和保留信息,从而避免早期信息在长序列中被“冲淡”。而且LSTM也能有效缓解梯度爆炸和梯度消失的问题。在本项目中,对最佳清洗时间点的预测高度依赖于过去的大量历史信息,因此非常适合使用LSTM进行训练。
阶段一
最开始训练时,采用了六维特征(isc1、isc2、temp、p_loss、hours_since_clean、day_of_year)+单点标签(is_cleaning_day)进行训练。
数据预处理
规定样本窗口WINDOW_STEPS为96(即一个样本包含96个序列),偏移量LABEL_OFFSET为24,为了做到预测,将单点标签“后移”了24个序列,即12小时的数据量,意味着训练后模型能做到提前十二小时进行预测(如输入特征是1月1日下午六点的数据,对应的单点标签应该是1月2日早上六点的数据)。
加载数据后首先对数据进行按电站id、设备id进行排序,然后将每组排好序的数据分别按时间进行排序。接着将每组排好序的数据以滑动窗口的形式进行样本切分,输入特征中每个样本取96个序列,每个样本所对应的特征标签为每个样本中最后一个序列所对应的特征标签,之所以每个样本(96个序列)能对应一个标签,就是因为LSTM具备“记忆性”,LSTM中每个样本的最后一个时间步都能包含以往时间步的隐藏层信息。然后将切分好的样本和标签分别拼接成array数组。
# 单点标签逻辑
def build_sequences(group_df, window, label_offset, features):
vals = group_df[features].values
labels = group_df["is_cleaning_day"].values
n_row = len(vals)
sequences, seq_labels = [], []
for i in range(n_row - window - label_offset + 1):
seq = vals[i: i + window]
label = labels[i + window + label_offset - 1]
sequences.append(seq);
seq_labels.append(label)
if not sequences: return np.empty((0, window, len(features))), np.empty((0,))
return np.array(sequences), np.array(seq_labels).astype(np.int32)
X_list, y_list = [], []
for (sid, did), grp in df.groupby(["station_id", "device_id"]):
grp = grp.sort_values("d_time")
X_g, y_g = build_sequences(grp, WINDOW_STEPS, LABEL_OFFSET, ALL_FEATURES)
if len(X_g) > 0:
X_list.append(X_g);
y_list.append(y_g)
X_all = np.concatenate(X_list);
y_all = np.concatenate(y_list)
给每个切分好的样本打上时间戳,每个样本的时间戳为每个样本当中最后一个序列所对应的时间。最后,根据时间进行数据的重排列,保证训练集全部早于测试集。
# 按时间切分
sample_d_times = []
for (sid, did), grp in df.groupby(["station_id", "device_id"]):
grp = grp.sort_values("d_time")
times = grp["d_time"].values;
n = len(times)
for i in range(n - WINDOW_STEPS - LABEL_OFFSET + 1):
sample_d_times.append(times[i + WINDOW_STEPS - 1])
sample_d_times = np.array(sample_d_times)
sort_idx = np.argsort(sample_d_times)
X_all = X_all[sort_idx];
y_all = y_all[sort_idx];
sample_d_times = sample_d_times[sort_idx]
split_idx = int(len(X_all) * TRAIN_RATIO)
X_train, y_train = X_all[:split_idx], y_all[:split_idx]
X_test, y_test = X_all[split_idx:], y_all[split_idx:]构建dataset数据集。在构建dataset数据集时,应当注意两个问题,一个是数据的归一化问题,另一个是数据的过采样问题。由于特征的量纲有很大的差异,所以一定得进行归一化,防止梯度爆炸。在这个数据集中,最大的一个问题就是正样本(需要清洗)比例过少,而负样本(无需清洗)比例过大,那么就会导致模型严重偏向负样本,几乎永远预测"不需要清洁"。所以要对正样本进行过采样,让模型"看到"更多正样本,学会区分。对正样本进行过采样的原则是:正负比例不超过 1:3,最多复制 20 倍。
class SequenceDataset(Dataset):
def __init__(self, npz_path, scaler=None, fit_scaler=False, oversample=True):
data = np.load(npz_path)
X_raw = data["X"].astype(np.float32) # (N,96,6) ⬅ 阶段1
y_raw = data["y"].astype(np.float32)
if fit_scaler:
self.scaler = StandardScaler()
N, T, F = X_raw.shape
self.X = torch.tensor(self.scaler.fit_transform(X_raw.reshape(-1, F)).reshape(N, T, F), dtype=torch.float32)
elif scaler is not None:
self.scaler = scaler;
N, T, F = X_raw.shape
self.X = torch.tensor(self.scaler.transform(X_raw.reshape(-1, F)).reshape(N, T, F), dtype=torch.float32)
else:
self.scaler = None;
self.X = torch.tensor(X_raw, dtype=torch.float32)
self.y = y_raw
if oversample:
pos_idx = np.where(y_raw == 1)[0]
neg_idx = np.where(y_raw == 0)[0]
target_pos = min(len(neg_idx) // 3, len(pos_idx) * 20)
repeats = max(1, target_pos // len(pos_idx))
oversampled_pos = np.repeat(pos_idx, repeats)
self.indices = np.concatenate([neg_idx, oversampled_pos])
np.random.shuffle(self.indices)
else:
self.indices = np.arange(len(self.y))
def __len__(self):
return len(self.indices)
def __getitem__(self, idx):
real_idx = self.indices[idx]
return self.X[real_idx], torch.tensor(self.y[real_idx])LSTM训练
构建LSTM模型。此模型中,隐藏状态维度选取64、LSTM层数选取2、Dropout 比率选取0.3、每个时间步的特征数为6,分类头:Linear(64→32) → ReLU → Dropout → Linear(32→1)。在构建LSTM模型时,依然需要注意上述的正负样本比例极端不平衡的问题。在正负样本极端不平衡的情况下,如果不做任何处理,模型在初始化时由于偏置为0,权重×特征的期望近似为0,导致近似有sigmoid(0)=0.5,即模型一开始时对所有样本都输出50%正类概率。但实际情况却是99.37%的样本都是负类,这就会导致模型在前几个epoch浪费算力“纠正”概率值。而最后一层的偏置直接控制最终输出的概率。所以,在一开始时就需要手动去设置最后一层的偏置,让模型一开始时就预测出接近真实样本比例的值。最后一层偏置的设置原则是:log(正样本比例/(1-正样本比例))。
class DustLSTM(nn.Module):
def __init__(self, input_dim=6, hidden=64, lstm_layers=2, dropout=0.3): # ⬅ 阶段1: 6
super().__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=hidden,
num_layers=lstm_layers, batch_first=True,
dropout=dropout if lstm_layers > 1 else 0, bidirectional=False)
self.classifier = nn.Sequential(
nn.Linear(hidden, 32), nn.ReLU(), nn.Dropout(dropout), nn.Linear(32, 1))
pos_rate = 0.0064;
bias_val = np.log(pos_rate / (1 - pos_rate))
self.classifier[-1].bias.data.fill_(bias_val)
def forward(self, x, phy_idx=None, tmp_idx=None):
_, (h, _) = self.lstm(x);
return self.classifier(h[-1]).squeeze(-1)构建训练函数。在构建训练函数时,应当注意两个一问题:一是每个batch训练开始之前要清除梯度值,因为在Pytorch中,梯度值是默认进行累加的;二是在每个batch反向传播之后、参数更新之前应当进行梯度裁剪,按比例缩小梯度,防止梯度爆炸。
def train_epoch(model, loader, criterion, optimizer, pbar=None):
model.train();
total_loss, correct, total = 0.0, 0, 0
for x, y in loader:
x, y = x.to(DEVICE), y.to(DEVICE);
optimizer.zero_grad()
logits = model(x);
loss = criterion(logits, y)
loss.backward();
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
with torch.no_grad():
pred = (torch.sigmoid(logits) >= 0.5).float()
total_loss += loss.item() * len(x);
correct += (pred == y).sum().item();
total += len(x)
if pbar: pbar.update(len(x)); pbar.set_postfix({"loss": f"{loss.item():.4f}"})
return total_loss / total, correct / total训练结果
损失函数采用了FocalLoss损失函数,因为FocalLoss是专门为解决类别极端不平衡和难易样本不平衡而设计的一种损失函数。γ选取2.0 的标准值,因为γ=0时能够把易分负样本的 loss 压到趋近于零,避免再出现易分样本还在贡献梯度的情况。调节不同的α值,分别将其调为0.99、0.50、0.75,发现0.75时效果最佳,因为0.99使得正样本权重过大,而0.50又使得正样本权重过小,0.75恰好能做到权重的平衡。
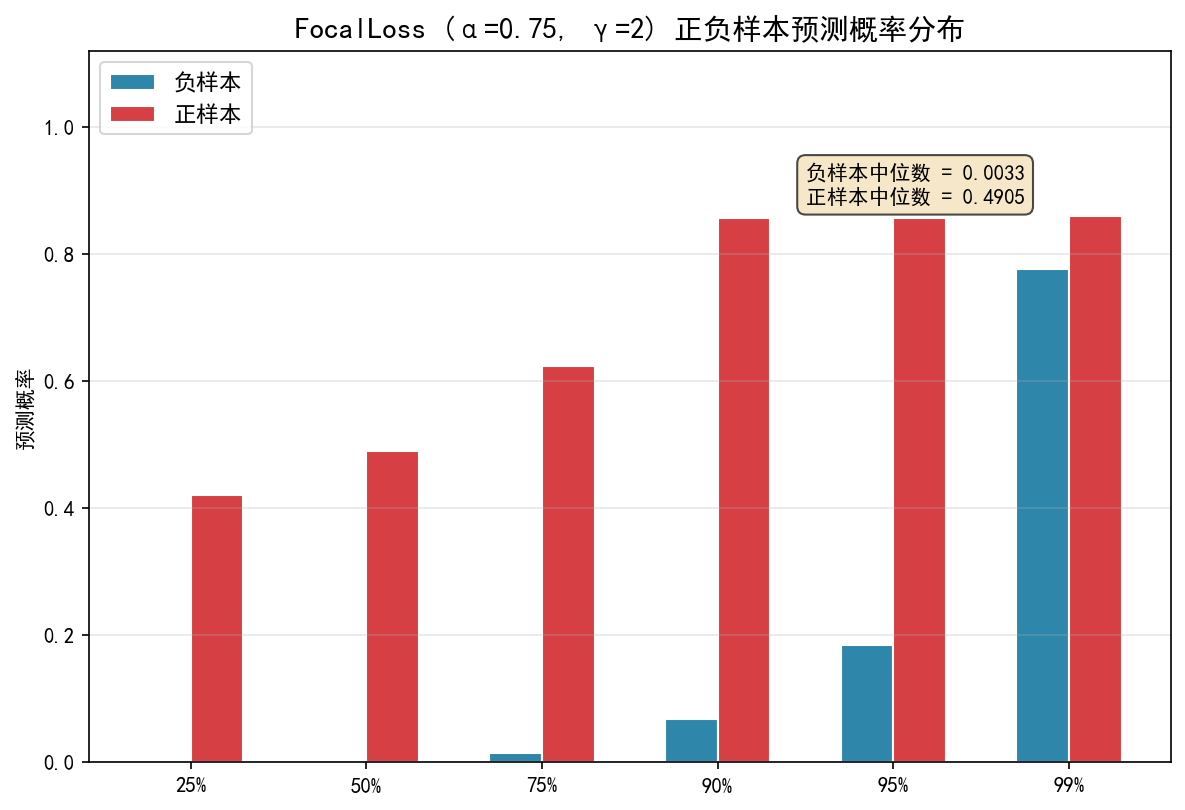
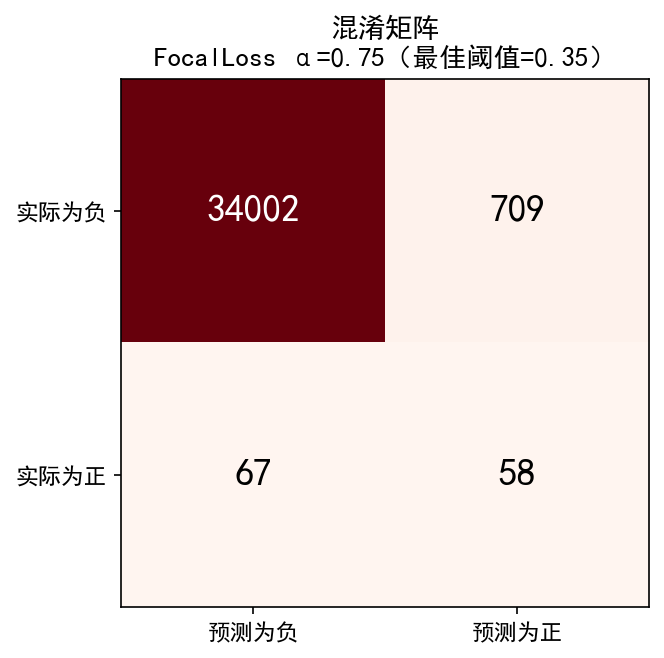
模型(FocalLoss α=0.75, γ=2.0, 12h 窗口 × 7 特征)在模拟数据上得到的 AUC为0.9623,说明模型对清洗事件的排序判别能力较强。概率分布数据显示负样本中位数 0.003、正样本中位数 0.49,集中在 0.42~0.86 区间,75% 的负样本输出低于 0.014,说明模型对“不需要清洗”的判断非常确定,而不能够很好的判断“需要清洗”。混淆矩阵(阈值 0.5)中真正例 58、假负例 67(漏报率 54%),假正例 709、真负例 34119,Recall 偏低。虽然模型能较好地进行分类,但是效果依然并不理想。
| 指标 | 数值 |
|---|---|
| AUC | 0.9623 |
| 最佳阈值 | 0.35 |
| 精确率 Precision | 0.08 |
| 召回率 Recall | 0.46 |
| F1 | 0.13 |
| 负样本中位数概率 | 0.0033 |
| 正样本中位数概率 | 0.4905 |
| 假阳性 FP(阈值=0.5) | 709 |
| 假阴性 FN(阈值=0.5) | 67 |
阶段二(调优)
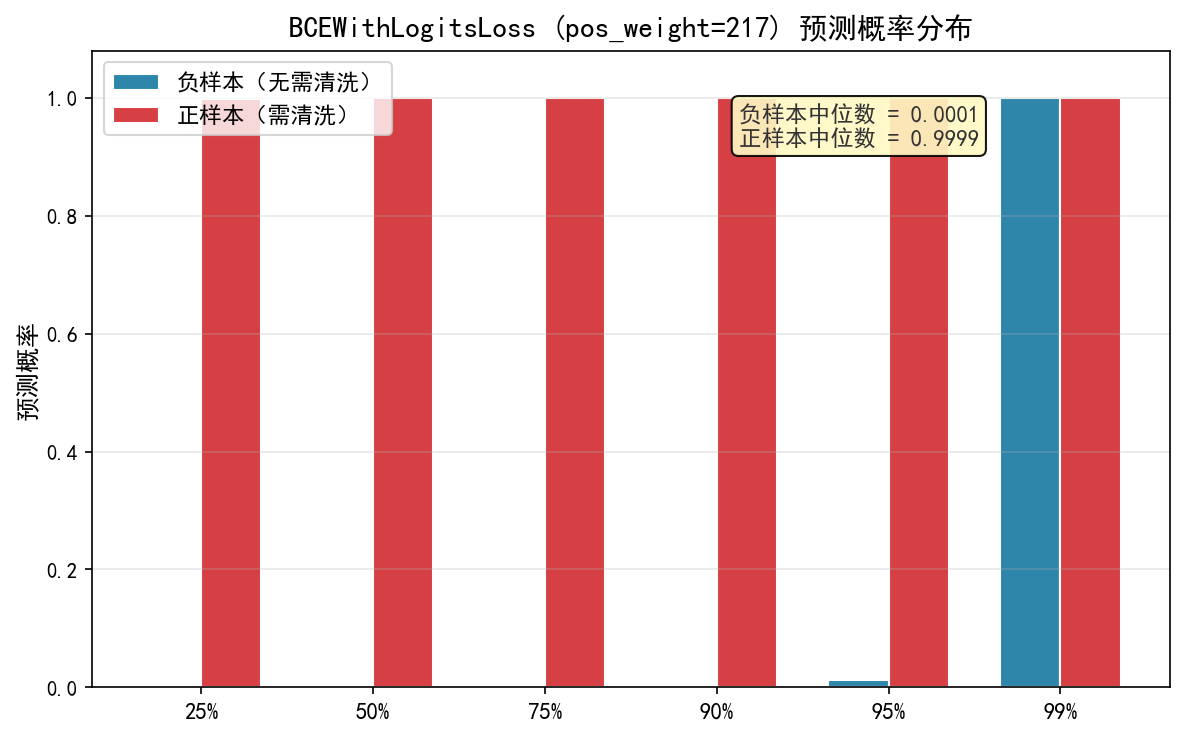
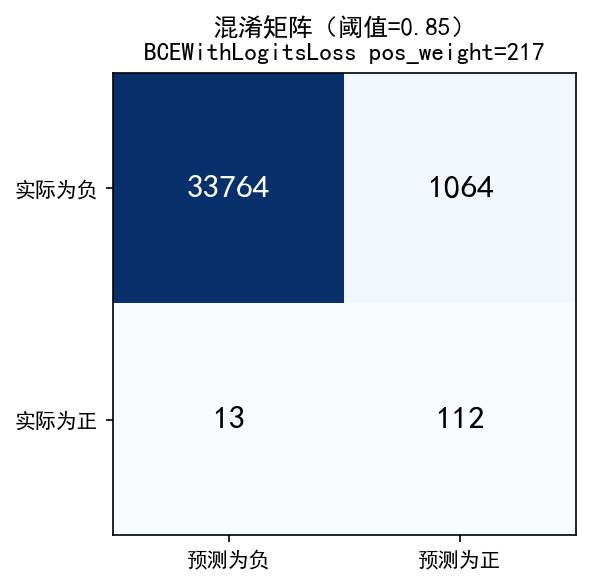
使用 BCEWithLogitsLoss(pos_weight≈217) 在模拟数据上训练,取得了 AUC=0.9838 的判别效果,优于之前的 FocalLoss 的所有 α 配置。概率分布显示负样本中位数 0.0001、正样本中位数 0.9999,两个分布极其清晰地分离,模型对“不需要清洗”和“需要清洗”的判断都非常确定。仅约 1% 的负样本(约 348 条)被误推至 0.9999 附近,属于真正的难例而非模型失控。混淆矩阵(最佳阈值0.85)中真正例112、假负例13(漏报率10%),假正例1064、真负例 33764,Recall=0.90、Precision=0.10。与后续 Focal Loss(α=0.75) 相比,pos_weight 在数据上实现了更高的 AUC、更干净的分布分离和更优的召回率,说明在特征工程充分的条件下,BCEWithLogitsLoss + pos_weight 本身就是解决极端不平衡分类的有效方案。
| 指标 | pos_weight=217 | FocalLoss α=0.75 |
|---|---|---|
| AUC | 0.9838 | 0.9623 |
| 负样本中位数 | 0.0001 | 0.0033 |
| 正样本中位数 | 0.9999 | 0.4905 |
| Recall | 0.90 | 0.46 |
| Precision | 0.10 | 0.08 |
| FP | 1064 | 709 |
| FN | 13 | 67 |
基线对比
为验证 LSTM 的时序建模是否必要,在同一份数据上做了两组基线对比。逻辑回归(仅窗口均值特征)AUC=0.80,XGBoost(同样均值特征,但具备非线性决策能力)AUC=0.87,LSTM(96 步时序输入)AUC=0.98。非线性带来约 7 个点增益,时序信息再追加 11 个点。特征工程 + 非线性树的组合在 0.87 附近封顶,剩下 11 个百分点的提升只能来自对 96 步内 iSc2 下降斜率的时序建模,而这正是灰尘累积过程的物理本质。
| 模型 | 能力边界 | AUC |
|---|---|---|
| 逻辑回归 | 线性 + 无时序 | 0.8032 |
| XGBoost | 非线性 + 无时序 | 0.8700 |
| LSTM | 非线性 + 时序 | 0.9838 |
结论
LSTM 在模拟数据上取得的 AUC=0.9838,必须放在"数据干净"的前提下理解,模拟数据由物理模型驱动生成,不受传感器漂移、通信丢包、等真实场景噪声的干扰。正因为输入信号的纯净,LSTM 才能不受干扰地从 96 步时序中提取出灰尘累积的趋势。这一结果的核心价值不在于数值本身,而在于它验证了方法论的有效性: LSTM 结构确实能够在极度类别不平衡的条件下实现可靠的前瞻性预警,应用于本项目当中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)