使用DBSCAN算法对纽约市 Airbnb 房源数据集进行聚类分析
1.作者介绍
张佳美,女,西安工程大学电子信息学院,2025级研究生
研究方向:模式识别与人工智能
电子邮件:3105688198@qq.com
2.DBSCAN算法介绍
2.1 算法原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够发现任意形状的簇,并且可以自动识别出噪声点。它通过将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。
DBSCAN 通过eps(半径)和min_samples(最小样本数)两个参数来定义簇的密度:
1、eps:指邻域半径,用于判断两个样本点是否接近的距离阈值。
2、min_samples:指最小样本数,表示一个点成为核心点所需要的邻域样本数量。
基于这两个参数,DBSCAN将样本点划分为三类:核心点、边界点和噪声点,然后由核心点出发不断扩展,最终形成聚类。
1、核心点:在半径 eps 内包含不少于 min_samples 数目的点。
2、边界点:在半径 eps 内点的数量小于 min_samples,但落在核心点的邻域内。
3、噪声点:不属于任何簇的点。
2.2 算法优缺点
1、优点
-
无需预设簇数:算法根据数据密度自动发现聚类结构。
-
能识别任意形状簇:不受球形假设限制,适合地理分布、不规则形态的簇。
-
自动识别噪声:天然将低密度区域标记为噪声,适合做异常检测。
-
对离群点鲁棒:噪声点不会影响核心簇的位置和形状,聚类结果更稳定。
-
结果确定性高:不受初始随机中心点影响,多次运行结果一致。
2、缺点:
-
对参数高度敏感:eps 和 min_samples 的选择直接决定聚类质量,且没有通用最优值。
-
不适合高维数据:维度灾难导致距离度量失效,密度难以定义,聚类效果急剧下降。
-
难以处理密度差异大的数据:全局统一的 eps 无法同时适应高密度簇和低密度簇,容易合并或拆分。
-
边界点归属不确定:边界点可能同时属于多个核心点的邻域,遍历顺序不同可能导致归属变化。
2.3 算法实现流程
1、首先随机选择一个未访问的点;
2、检查该点的eps邻域内是否包含至少min_samples个点;
3、如果是,则该点成为核心点,开始创建一个新的簇,并将邻域内的点加入该簇;
4、然后对这些新加入的点递归地进行同样的检查,不断扩展簇的边界;
5、如果一个点不是核心点,且不在任何核心点的邻域内,则将其标记为噪声;
6、重复上述过程,直到所有点都被访问过。
下图为DBSCAN算法流程图:
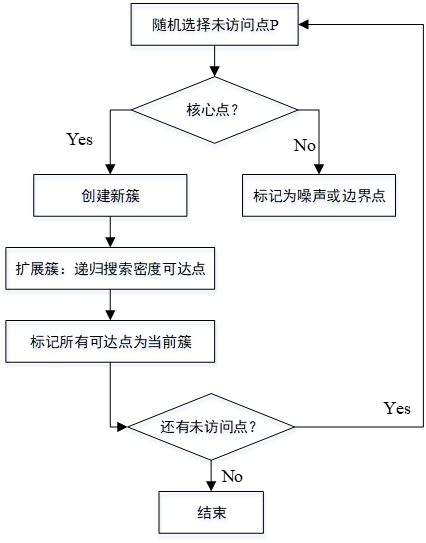
图 1 DBSCAN算法流程图
3.纽约市Airbnb房源数据集分析
3.1数据集介绍
纽约市 Airbnb 房源数据集,记录了纽约市由 5 个行政区(曼哈顿,布鲁克林、皇后区、布朗克斯、史泰登岛)48895条房源,其中包含房源编号、房东信息、区域信息、经纬度、房间类型、价格、最少入住天数、评论数量等16维特征。
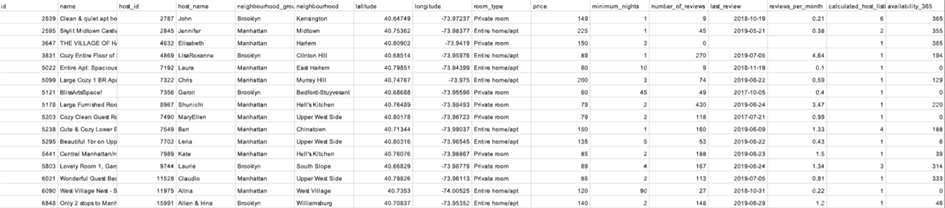
图 2 airbnb数据集示例
3.2项目代码
"""
DBSCAN 聚类分析:纽约市 Airbnb 房源数据集 (AB_NYC_2019.csv)
使用经纬度 + 价格特征进行空间密度聚类,
识别纽约市房源的地理热点区域和价格模式。
"""
import matplotlib
matplotlib.use('Agg')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import NearestNeighbors
from sklearn.metrics import silhouette_score, calinski_harabasz_score
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans'] # 优先用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# ── 1. 加载数据 ──────────────────────────────────────────────
df = pd.read_csv("AB_NYC_2019.csv")
df = pd.read_csv("AB_NYC_2019.csv").head(10000)
print(f"数据集大小: {df.shape}")
print(f"\n列名: {list(df.columns)}")
print(f"\n缺失值统计:\n{df[['latitude', 'longitude', 'price']].isnull().sum()}")
print(f"\nprice 描述性统计:\n{df['price'].describe()}")
# ── 2. 数据预处理 ───────────────────────────────────────────
# 去除价格异常值 (price = 0 或 price > 1000 视为异常)
df_clean = df[(df["price"] > 0) & (df["price"] <= 1000)].copy()
print(f"\n清洗后数据量: {len(df_clean)} (去除 {len(df) - len(df_clean)} 条异常记录)")
# 选择特征:经纬度 + 价格
features = df_clean[["latitude", "longitude", "price"]].values
# 标准化 (DBSCAN 对尺度敏感,需统一量纲)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(features)
print(f"特征均值: {scaler.mean_}")
print(f"特征标准差: {scaler.scale_}")
# ── 3. 确定最优 eps 参数 (k-distance 方法) ──────────────────
# 对 3 维特征,min_samples 通常取 2*dim = 6
min_samples = 6
k = min_samples - 1 # 最近邻数 = min_samples - 1
nbrs = NearestNeighbors(n_neighbors=k, metric="euclidean")
nbrs.fit(X_scaled)
distances, _ = nbrs.kneighbors(X_scaled)
k_distances = np.sort(distances[:, -1]) # 第 k 近邻距离 (升序)
# 绘图:k-distance 曲线,拐点处即为 eps 推荐值
fig_kdist, ax_kdist = plt.subplots(figsize=(10, 5))
ax_kdist.plot(k_distances, linewidth=0.8)
ax_kdist.set_xlabel("样本点 (按距离排序)")
ax_kdist.set_ylabel(f"第 {k} 近邻距离")
ax_kdist.set_title("k-distance 图 — 拐点处为推荐 eps")
ax_kdist.axhline(y=0.5, color="r", linestyle="--", alpha=0.5, label="eps=0.5 (参考)")
ax_kdist.axhline(y=0.8, color="orange", linestyle="--", alpha=0.5, label="eps=0.8 (参考)")
ax_kdist.legend()
fig_kdist.tight_layout()
fig_kdist.savefig("k_distance_plot.png", dpi=150)
plt.close()
print(f"\nk-distance 拐点建议: eps 在 0.4 ~ 0.8 之间候选")
# ── 4. 多参数网格搜索 ───────────────────────────────────────
# 在 k-distance 拐点附近搜索最佳参数组合
eps_candidates = [0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
ms_candidates = [4, 6, 8, 10, 15]
best_score = -1
best_params = {}
results = []
for eps in eps_candidates:
for ms in ms_candidates:
db = DBSCAN(eps=eps, min_samples=ms, metric="euclidean", n_jobs=-1)
labels = db.fit_predict(X_scaled)
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
n_noise = np.sum(labels == -1)
result = {"eps": eps, "min_samples": ms, "n_clusters": n_clusters, "n_noise": n_noise, "score": None}
# 仅在有 ≥2 个聚类且非全噪声时计算 silhouette
if n_clusters >= 2 and n_noise < len(labels) * 0.8:
mask = labels != -1
if np.sum(mask) > 1:
try:
score = silhouette_score(X_scaled[mask], labels[mask])
result["score"] = score
except Exception:
pass
results.append(result)
# 打印所有参数结果
results_df = pd.DataFrame(results)
print("\n── 参数搜索结果 ──")
print(results_df.to_string(index=False))
# 选最优参数:优先 silhouette 最高的,其次聚类数合理的
valid = results_df.dropna(subset=["score"])
if len(valid) > 0:
valid = valid[valid["n_clusters"] >= 3] # 至少 3 个聚类
if len(valid) > 0:
best_row = valid.loc[valid["score"].idxmax()]
best_eps = best_row["eps"]
best_ms = int(best_row["min_samples"])
best_score = best_row["score"]
else:
best_eps, best_ms = 0.5, 6
else:
best_eps, best_ms = 0.5, 6
print(f"\n最优参数: eps={best_eps}, min_samples={best_ms}")
# ── 5. 最终 DBSCAN 聚类 ──────────────────────────────────────
dbscan = DBSCAN(eps=best_eps, min_samples=best_ms, metric="euclidean")
df_clean["cluster"] = dbscan.fit_predict(X_scaled)
n_clusters = len(set(df_clean["cluster"])) - (1 if -1 in df_clean["cluster"].values else 0)
n_noise = (df_clean["cluster"] == -1).sum()
print(f"\n──── 最终聚类结果 ────")
print(f"聚类数: {n_clusters}")
print(f"噪声点数: {n_noise} ({n_noise / len(df_clean) * 100:.1f}%)")
print(f"有效聚类数占比: {100 - n_noise / len(df_clean) * 100:.1f}%")
# 各聚类统计
print(f"\n各聚类样本数:")
cluster_counts = df_clean["cluster"].value_counts().sort_index()
for cid, cnt in cluster_counts.items():
label = "噪声" if cid == -1 else f"聚类 {cid}"
print(f" {label}: {cnt} 个房源")
# 各聚类价格与地理中心
print(f"\n各聚类详情:")
for cid in sorted(df_clean["cluster"].unique()):
cluster_data = df_clean[df_clean["cluster"] == cid]
label = "噪声" if cid == -1 else f"聚类 {cid}"
print(f" {label}: "
f"均价=${cluster_data['price'].mean():.0f}, "
f"中心=({cluster_data['latitude'].mean():.3f}, {cluster_data['longitude'].mean():.3f}), "
f"主要区域={cluster_data['neighbourhood_group'].mode().values[0] if len(cluster_data) > 0 else 'N/A'}")
# ── 6. 可视化 ────────────────────────────────────────────────
# 定义聚类颜色
colors = plt.cm.tab20(np.linspace(0, 1, max(n_clusters, 1)))
colors = np.vstack([[[0.5, 0.5, 0.5, 0.5]], colors]) # 噪声点为灰色半透明
# --- 图 1: 地理散点图 (经纬度着色) ---
fig1, ax1 = plt.subplots(figsize=(14, 10))
for cid in sorted(df_clean["cluster"].unique()):
idx = cid + 1 # -1 → 0 对应灰色噪声
cluster_data = df_clean[df_clean["cluster"] == cid]
label = "Noise" if cid == -1 else f"Cluster {cid}"
alpha = 0.15 if cid == -1 else 0.6
s = 2 if cid == -1 else 8
ax1.scatter(cluster_data["longitude"], cluster_data["latitude"],
c=[colors[idx]], s=s, alpha=alpha, label=label, edgecolors="none")
ax1.set_xlabel("Longitude")
ax1.set_ylabel("Latitude")
ax1.set_title(f"DBSCAN 聚类结果 (eps={best_eps}, min_samples={best_ms})\n纽约市 Airbnb 房源地理聚类")
ax1.legend(markerscale=3, fontsize=7, loc="upper left", bbox_to_anchor=(1.01, 1))
fig1.tight_layout()
fig1.savefig("dbscan_geo_clusters.png", dpi=150)
plt.close()
# --- 图 2: 带价格颜色的地理散点图 ---
fig2, ax2 = plt.subplots(figsize=(14, 10))
sc = ax2.scatter(df_clean["longitude"], df_clean["latitude"],
c=df_clean["price"], cmap="YlOrRd", s=3, alpha=0.6, edgecolors="none",
vmin=0, vmax=500)
plt.colorbar(sc, ax=ax2, label="Price ($)", shrink=0.75)
ax2.set_xlabel("Longitude")
ax2.set_ylabel("Latitude")
ax2.set_title("纽约市 Airbnb 房源价格分布")
fig2.tight_layout()
fig2.savefig("dbscan_price_distribution.png", dpi=150)
plt.close()
# --- 图 3: 各聚类价格箱线图 ---
cluster_ids_sorted = sorted(df_clean[df_clean["cluster"] != -1]["cluster"].unique())
fig3, ax3 = plt.subplots(figsize=(12, 6))
price_data = [df_clean[df_clean["cluster"] == cid]["price"].values for cid in cluster_ids_sorted]
bp = ax3.boxplot(price_data, labels=[f"Cluster {c}" for c in cluster_ids_sorted], showfliers=False)
ax3.set_xlabel("Cluster")
ax3.set_ylabel("Price ($)")
ax3.set_title("各聚类房源价格分布 (已去异常值)")
ax3.tick_params(axis="x", rotation=45)
fig3.tight_layout()
fig3.savefig("dbscan_cluster_prices.png", dpi=150)
plt.close()
# --- 图 4: 各行政区聚类分布 ---
fig4, ax4 = plt.subplots(figsize=(12, 6))
cross = pd.crosstab(df_clean["neighbourhood_group"], df_clean["cluster"])
cross_norm = cross.div(cross.sum(axis=1), axis=0)
cross_norm.plot(kind="bar", stacked=True, ax=ax4, cmap="tab20", alpha=0.85)
ax4.set_xlabel("Neighbourhood Group")
ax4.set_ylabel("Proportion")
ax4.set_title("各行政区聚类比例分布")
ax4.legend(title="Cluster", fontsize=7, loc="upper left", bbox_to_anchor=(1.01, 1))
fig4.tight_layout()
fig4.savefig("dbscan_borough_distribution.png", dpi=150)
plt.close()
# --- 图 5: 聚类指标总结图 ---
fig5, axes5 = plt.subplots(1, 3, figsize=(15, 5))
# 5a: 聚类大小 (柱状图)
ax_size = axes5[0]
cluster_sizes = df_clean[df_clean["cluster"] != -1]["cluster"].value_counts().sort_index()
ax_size.bar(cluster_sizes.index.astype(str), cluster_sizes.values, color=colors[1:len(cluster_sizes)+1])
ax_size.set_title("各聚类房源数量")
ax_size.set_xlabel("Cluster ID")
ax_size.set_ylabel("Count")
ax_size.tick_params(axis="x", rotation=45)
# 5b: 聚类均价 (柱状图)
ax_price = axes5[1]
avg_prices = df_clean[df_clean["cluster"] != -1].groupby("cluster")["price"].mean()
ax_price.bar(avg_prices.index.astype(str), avg_prices.values, color=colors[1:len(avg_prices)+1])
ax_price.set_title("各聚类平均价格")
ax_price.set_xlabel("Cluster ID")
ax_price.set_ylabel("Avg Price ($)")
ax_price.tick_params(axis="x", rotation=45)
# 5c: 地理覆盖 (经纬度散点图)
ax_geo = axes5[2]
for cid in sorted(df_clean["cluster"].unique()):
cluster_data = df_clean[df_clean["cluster"] == cid]
if cid == -1:
ax_geo.scatter(cluster_data["longitude"], cluster_data["latitude"],
c="gray", s=1, alpha=0.1, label="Noise")
else:
ax_geo.scatter(cluster_data["longitude"], cluster_data["latitude"],
s=5, alpha=0.5, label=f"C{cid}")
ax_geo.set_title("各聚类地理分布")
ax_geo.set_xlabel("Longitude")
ax_geo.set_ylabel("Latitude")
fig5.tight_layout()
fig5.savefig("dbscan_summary.png", dpi=150)
plt.close()
print(f"\n图表已保存:")
print(f" - k_distance_plot.png (eps 选择参考)")
print(f" - dbscan_geo_clusters.png (地理聚类结果)")
print(f" - dbscan_price_distribution.png (价格分布)")
print(f" - dbscan_cluster_prices.png (聚类价格箱线图)")
print(f" - dbscan_borough_distribution.png (行政区聚类分布)")
print(f" - dbscan_summary.png (聚类总览)")
print(f"\n──── 分析完成 ────")
3.4实验结果
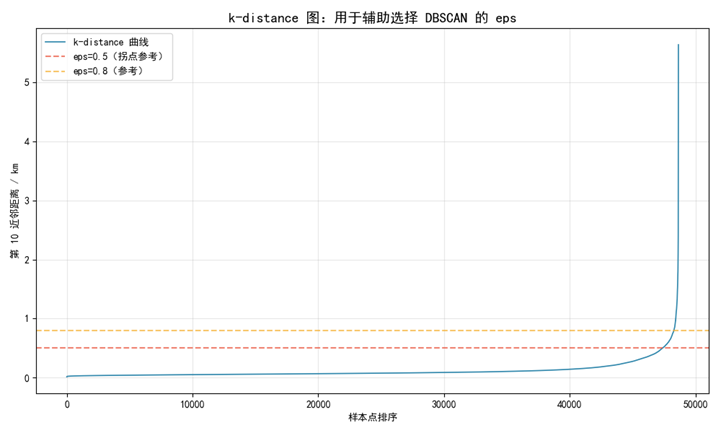
图 3 K-distance图
曲线从平缓突然变陡的位置(肘部)意味着,超过该距离后点的密度急剧下降,因此该位置是区分"高密度簇内"与"稀疏边界"的最佳阈值。代码最终选择 0.5 km 作为 eps。
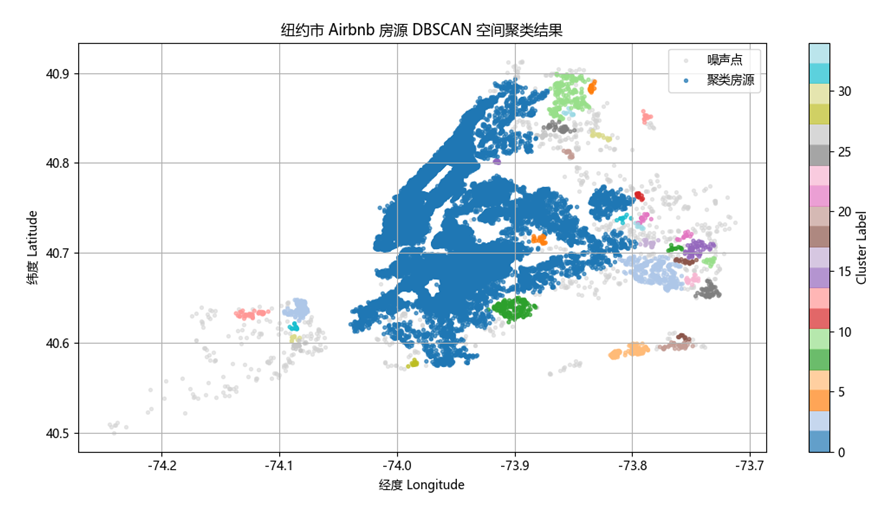
图 4 DBSCAN空间聚类结果图
中部的大型高密度聚类簇(蓝色区域)对应曼哈顿、布鲁克林以及皇后区的核心区域,这也是纽约市旅游和商业最发达的地带;
外围的小型彩色聚类簇代表城市边缘一些局部集中的区域,它们与核心区距离较远或密度不足,被单独划分为独立的簇;
浅灰色的噪声点主要分布在城市外围及稀疏地带,这些区域房源数量少、分布零散,邻域内无法满足min_samples的阈值,因此未能形成稳定聚类。
下图5~8,为其余实验结果图。
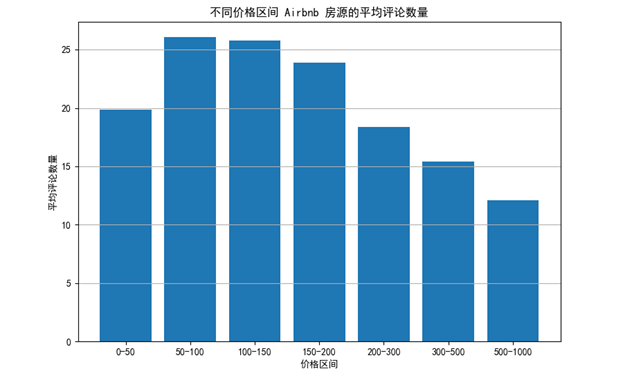
图 5 平均评论数量分析图
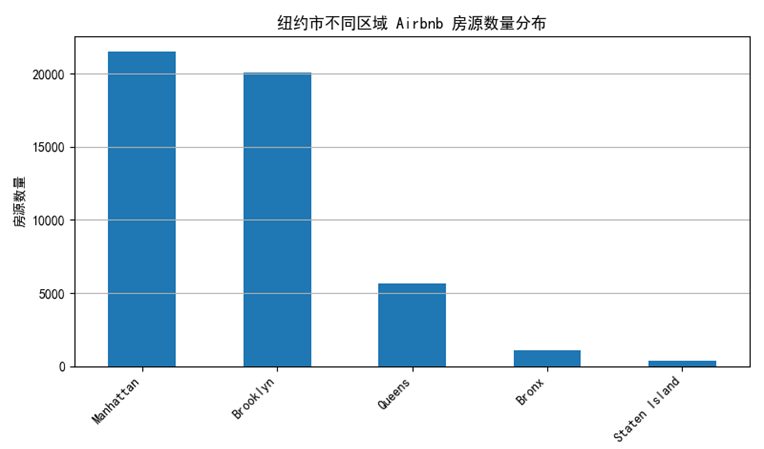
图 6 房源数量分析图
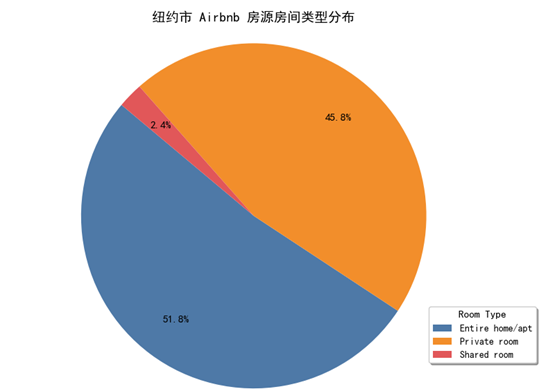
图 7 房间类型分布图
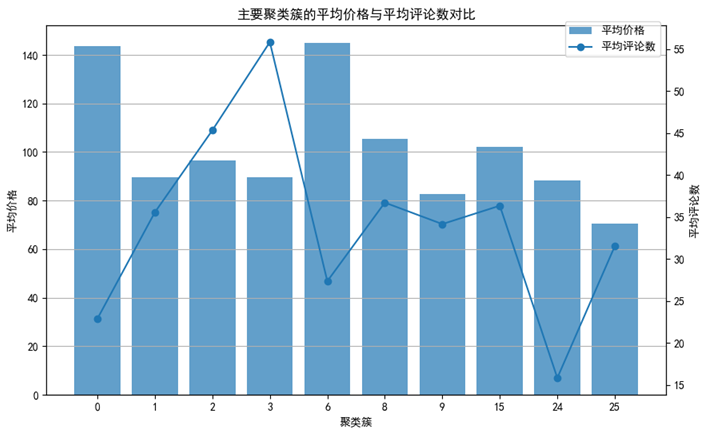
图 8 前10簇平均价格与平均评论数量分析图
4.参考链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)