Data Agent技术介绍(下)
📌 技术干货 · 共四个阶段
本文为系列下篇,涵盖阶段三:从 Skill 到本体语义层与阶段四:团队技术进展。上篇已介绍阶段一(语义层接入探索)与阶段二(从查数到决策)。
系列上篇在这里:Data Agent 技术介绍(上)
在上篇中,我们介绍了指标语义层如何解决"查得准"的问题,以及 Skill 体系如何让 Agent 从"查数"走向"决策"。然而,随着 Skill 数量的增长,一个更深层的问题浮出水面:当业务规则散落在数十个 Skill 的 Prompt 中时,谁来保证这些规则的一致性?
本文将从 Skill 体系的边界出发,深入探讨本体化语义层的必要性——它不仅是语义层的升级,更是 Agent 从"能干活"走向"值得信赖"的关键一跃。
阶段三:从 Skill 到本体语义层
1、Skill 能力边界:为什么"会查数"不等于"懂业务"
阶段二中,我们通过 Skill 让 Agent 从"初级分析师"走到了"策略师"。Agent 能做异常检测、趋势预测、四象限诊断,甚至能给出最后的决策建议。但这里有一个不能回避的问题:Skill 的天花板,本质上是"它能拿到什么材料"。
如果把Data Agent比作一个医生,Skill相当于诊断流程(望闻问切 → 开处方),语义层相当于化验报告。如果化验报告本身——指标口径、维度关系、业务规则——散落在各个Skill的Prompt里各自维护,那么:同一个"销售额",metric-query用的口径和inventory-strategy用的口径可能不一致;新增一个"渠道",要同时改5个Skill的Prompt;业务规则(如"到店超过1000天的商品算滞销")只在某个Skill里硬编码,换一个Skill就不知道。
Skill越做越多,口径管理和知识复用就会越来越重要。这便是从"Skill探索"自然走向"本体语义层"的动因。
2、两类语义层:指标语义层 vs 本体化语义层
今天行业里都在讲"语义层",但大家讲的并不是同一件事。我们可以将语义层分为两类:
2.1 指标语义层(阶段一、二所用)
核心问题:"这个数到底怎么算?"以指标、维度、口径为核心单位。解决的是:
- "销售额"含不含税、退不退货;
- "新客"按注册还是按首单算;
- "华东区"包含哪些省市;
- "同比"对齐到哪个时间窗口。
优势:对于标准化、高频的问数场景(统一口径、固定报表、管理驾驶舱),投入产出比极高。阶段一的NL→MQL→SQL链路和阶段二的六个Skill,本质上都建立在指标语义层之上。
边界:当问题从"看什么"走到"为什么",指标语义层开始吃力。例如问"为什么华东区女装销售额下降",系统需要知道:
- 销售发生在什么业务事件里(下单、退款,还是缺货?);
- 女装是产品对象上的哪层分类属性;
- 销售额下降是订单量下降、客单价下降,还是退款/折扣/渠道变化造成的;
- 哪些对象和事件值得继续被追问。
这些内容,单靠指标公式是表达不出来的。
2.2 本体化语义层
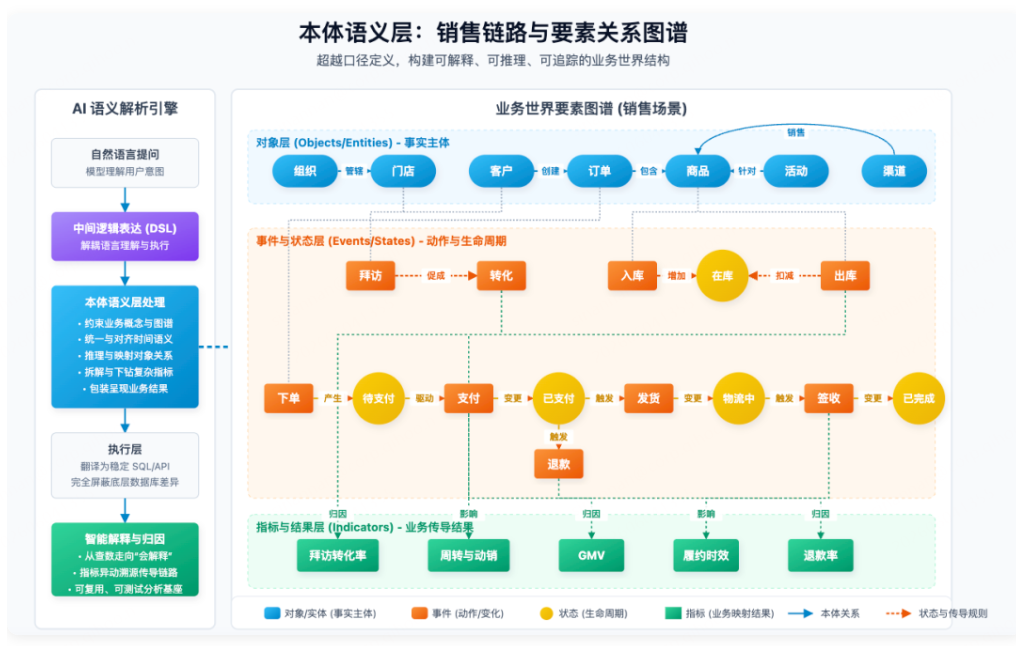
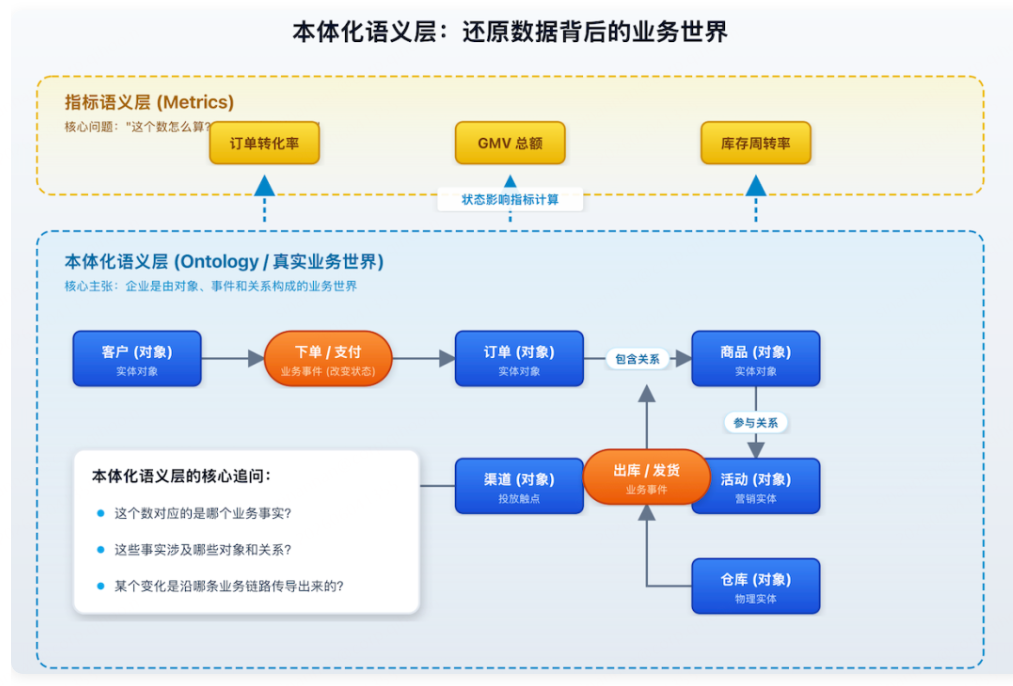
核心问题:"这个数背后的业务世界是什么样的?"以对象、事件、关系、规则为核心单位。它的主张是:企业不是由一堆指标组成的,而是由对象、事件和关系构成的业务世界。
- 客户、订单、商品、门店、渠道、仓库、组织——是对象;
- 下单、支付、发货、签收、退款、入库、出库——是事件;
- 客户"下"订单、订单"包含"商品、商品"参与"活动、活动"投放于"渠道——是关系;
- 事件改变对象状态,状态影响指标,指标反映运行结果。
指标语义层回答了"这个数怎么算",本体化语义层还要回答:
- 这个数对应的是哪个业务事实;
- 这些事实涉及哪些对象和关系;
- 某个变化是沿哪条业务链路传导出来的;
- 如果往下分析,该看哪些对象、哪些事件、哪些规则。
2.3 六维对比
|
维度 |
指标语义层 |
本体化语义层 |
|
建模单位 |
指标、维度、口径 |
对象、事件、关系、规则 |
|
表达能力 |
聚合分析 |
聚合分析 + 跨对象筛选 + 事件链路 + 状态变化 + 动态分组 |
|
问题覆盖 |
标准化问数 |
问数 → 归因 → 解释 → 建议 → 动作 |
|
系统可解释性 |
"这个指标怎么算出来的" |
"为什么是这些对象和事件共同导致了这个结果" |
|
维护重心 |
指标池、维度池、公式、别名映射 |
业务对象建模、事件链路、关系网、规则显性化 |
|
天花板 |
取决于能把多少问题收敛成指标表达 |
取决于能把业务世界表达得多完整 |
关键认知:本体化语义层不是不要指标层,而是把指标层纳入更大的业务世界表达中。指标仍然重要,口径仍然要统一,只是它们不再是语义层的全部。
3、为什么本体化语义层是 Agent 时代的数据基建"新地基"
3.1 行业共识:2026年主流厂商的路线殊途同归
|
厂商 |
动作 |
|
微软 Fabric IQ |
将 Ontology 作为 Fabric 预览能力,entity/property/relationship 与数据资产绑定 |
|
Snowflake Cortex Analyst |
强调 Semantic Views |
|
Databricks Genie |
要求领域专家维护 datasets、sample queries、text guidelines、knowledge store |
|
dbt Semantic Layer |
继续把指标定义、semantic graph、MetricFlow 往统一语义层推进 |
|
Google Looker |
把 Looker semantic layer 通过 MCP 接给 Gemini CLI 和其他 Agent |
方向一致:大模型要进入企业数据生产,不能只靠模型自己猜,模型之外必须有一层机器可读、可治理、可复用的业务语义基座。
3.2 传统数仓为什么能用?因为人在替系统"补洞"
过去十几年,分析师靠经验知道哪个表是月结口径,业务同学靠默契知道"新客"默认按首单算。人是会脑补的,隐性知识填补了系统的语义缺失。
但 Agent 不会继承这些默契。如果系统没告诉它某字段虽叫amount却已扣过退款、某宽表只能用于日报不能用于月结、某客户标签市场部能用风控部门不能用——Agent就会在这些缺口上产生幻觉。
3.3 只做 Prompt 和 Harness,本质上是在用胶带修地基
很多项目的做法:Schema扔进去 → 补一段Prompt → 答错了继续加Prompt → 某部门口径特殊再加规则 → 角色权限不同再加约束。
短期Demo能跑,长期生产大概率失控。因为Prompt和Harness解决的是"过程控制"(你应该怎么做),但解决不了"输入材料本身对不对"。
3.4 本体化语义层真正解决的:Agent 的"世界模型"
当对象、事件、关系、规则被显性化以后,Agent拿到的就不再是一堆表和字段,而是一套业务世界的地图。这张地图的价值:
降低幻觉源
材料本身更明确、更可信、更结构化。
收敛推理空间
模型在已定义的对象、关系、指标、权限和动作空间里做规划,不用在无限Schema里乱猜。
支撑角色差异
财务、运营、销售需要不同口径、不同路径、不同权限,放进语义模型里比写进超长Prompt更可维护。
支持归因与行动
只看指标只能回答"掉了多少",理解对象和事件,才能回答"为什么掉、影响了谁、下一步能做什么"。
与RBAC、审计、数据血缘形成工程闭环
每次回答都可追溯到哪些对象、哪些关系、哪些指标、哪些权限约束。
4、技术路线的演进:NL2SQL → NL2MQL2SQL → NL2LF2SQL
直接让模型在复杂Schema上生成SQL(NL2SQL),一旦Schema变大、Join变多、口径变杂,准确率和稳定性会急剧下降。
阶段一我们走的 NL2MQL2SQL(指标语义层方案)是在中间加一层MQL抽象——LLM负责将自然语言转为指标查询描述(MQL),确定性引擎再把MQL编译成SQL。这一跳已经大幅提升了稳定性,但它仍然以"指标+维度+条件+时间"为表达单元,难以表达对象关系和事件链路。
本体化语义层的技术路线进一步升级为 NL2LF2SQL:
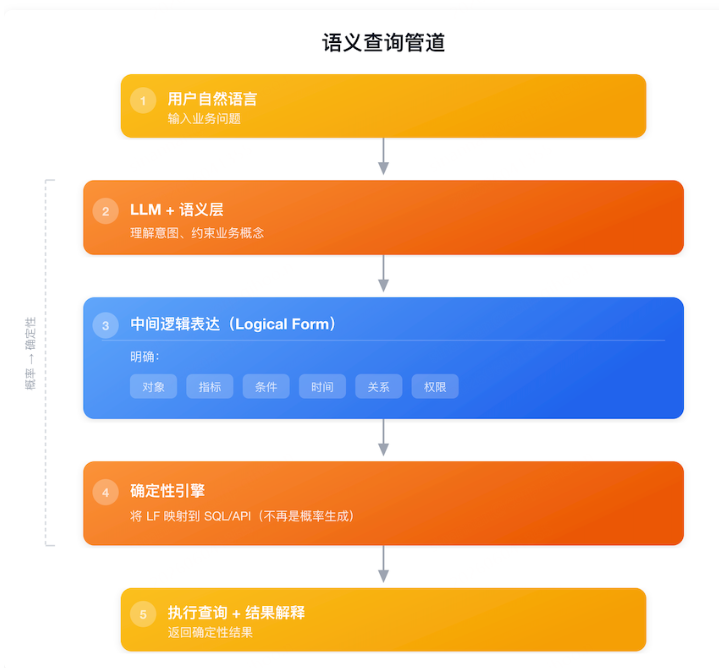
关键设计:把"语言理解"和"结构化执行"拆开。模型负责意图理解,语义层负责约束和映射,引擎负责稳定翻译。一旦结果不对,企业能知道错在意图理解、语义映射、指标口径、Join路径还是底层数据质量——而不是面对一个"也不知道为什么错"的黑盒。
5、企业落地的现实路径
不建议一上来就搞全集团、全域、全流程的超级本体工程。更现实的路径是从一个高价值业务域切入:
第一步:梳理领域内的核心对象、事件、关系和指标
- 销售经营域:客户、订单、商品、活动、渠道、组织是对象;下单、支付、发货、退款是事件;GMV、毛利、复购率、客单价是指标。
- 明确财务/运营/销售分别用什么口径,哪些数据能看哪些不能看。
第二步:沉淀成可维护的语义模型
- 表字段和业务概念绑定,指标公式和口径版本化。
- 对象关系显性化,角色权限联动。
- 关键业务规则能被查询链路和Agent运行时读取。
第三步:建立中间逻辑表达(Logical Form)
- 让模型先把问题翻译成可检查的业务逻辑表达
- 再由确定性引擎映射到查询和动作。
第四步:建立评估体系
- 沉淀黄金问题集、标准答案、典型追问、异常样例和回归测试。
- 参考Snowflake verified examples、Databricks Inspect的做法。
第五步:在可信语义基座上接入Harness工程
- Plan、Tool Calling、MCP、Skill、Prompt、Guardrail——这些站在可靠材料上才能真正发挥作用。
6、三层架构总览
结合阶段一到阶段三的探索,Data Agent的完整架构演化为: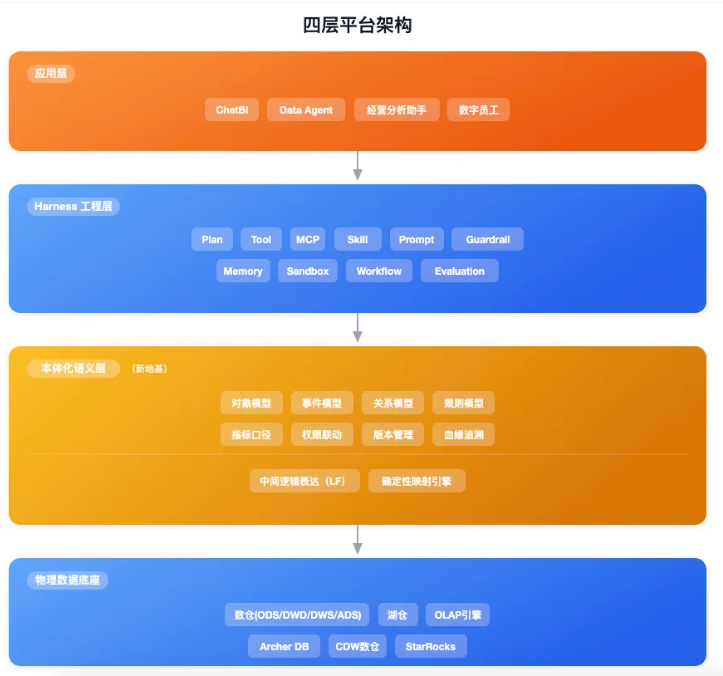
7、一句话总结
指标语义层让AI会查数,本体化语义层让AI开始理解业务。Skill将领域认知编码为可执行方法论,但若没有本体化语义层作为统一的事实基座,Skill体系迟早会陷入"口径分散、规则重复、知识不可复用"的维护黑洞。从Skill到本体语义层,不是换一个更高级的词,而是让Agent从"能干活"走向"值得信赖"。
团队技术进展
已上线
|
模块 |
状态 |
说明 |
|
指标语义层版 Data Agent |
✅ 已上线 |
阶段一的 NL→MQL→SQL 全链路已在生产环境运行,支持智能问数、口径统一、权限校验、结果可解释 |
|
Skill 体系 |
✅ 已上线 |
查数、归因、异常检测、趋势预测、分析报告、定时调度等 Skill 已在实际业务中投入使用 |
|
本体化语义平台 |
✅ 已上线 |
对象模型、事件模型、关系模型、规则引擎等核心能力已完成搭建,支持 Logical Form 中间表达与确定性映射 |
进行中:渐进式演进路线
当前团队正推进一条渐进式演进路线,而非一次性推倒重来:
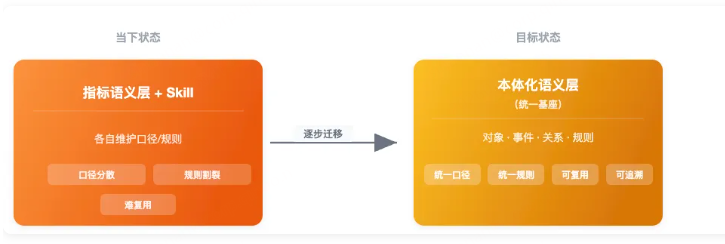
核心思路:已将本体化语义平台作为"新地基"搭建完成。后续业务规则的表达逐步从 Skill Prompt 迁移到本体语义层。
今天:部分规则写在 Skill 的 Prompt 里,部分硬编码在代码里
明天:业务规则逐步收敛到本体化语义层中的规则模型,Skill 变为编排器,不再自己携带口径
最终:Skill 本身被大幅简化甚至消解,语义层从"查数接口"升级为 Agent 可直接理解的"业务世界模型"
不是一夜之间停掉 Skill、切换本体层。而是让本体层先把 Skill 里的领域知识"吃进去"——每收敛一条规则,Skill 就轻一点;每建模一类关系,Agent 就准一点。最终状态是:本体的归本体、编排的归编排、执行的归执行,各层职责清晰、不再互相"补洞"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)