KV Cache和分组多头注意力GQA
写在前面
大模型生成文本时,为什么越往后速度越快?长上下文场景下,显存是如何被吃掉的?KV Cache 和 GQA 是解决这些问题的关键机制。本文将用最直观的方式拆解这两个概念,帮助你在技术面试和实际应用中游刃有余。此文章意在总结视频的文字和结论,补充知识点,欢迎大家关注我的这个公众号和 up 的视频!
一、KV Cache:用空间换时间的推理绝招
1.1 核心概念:什么是 KV Cache?
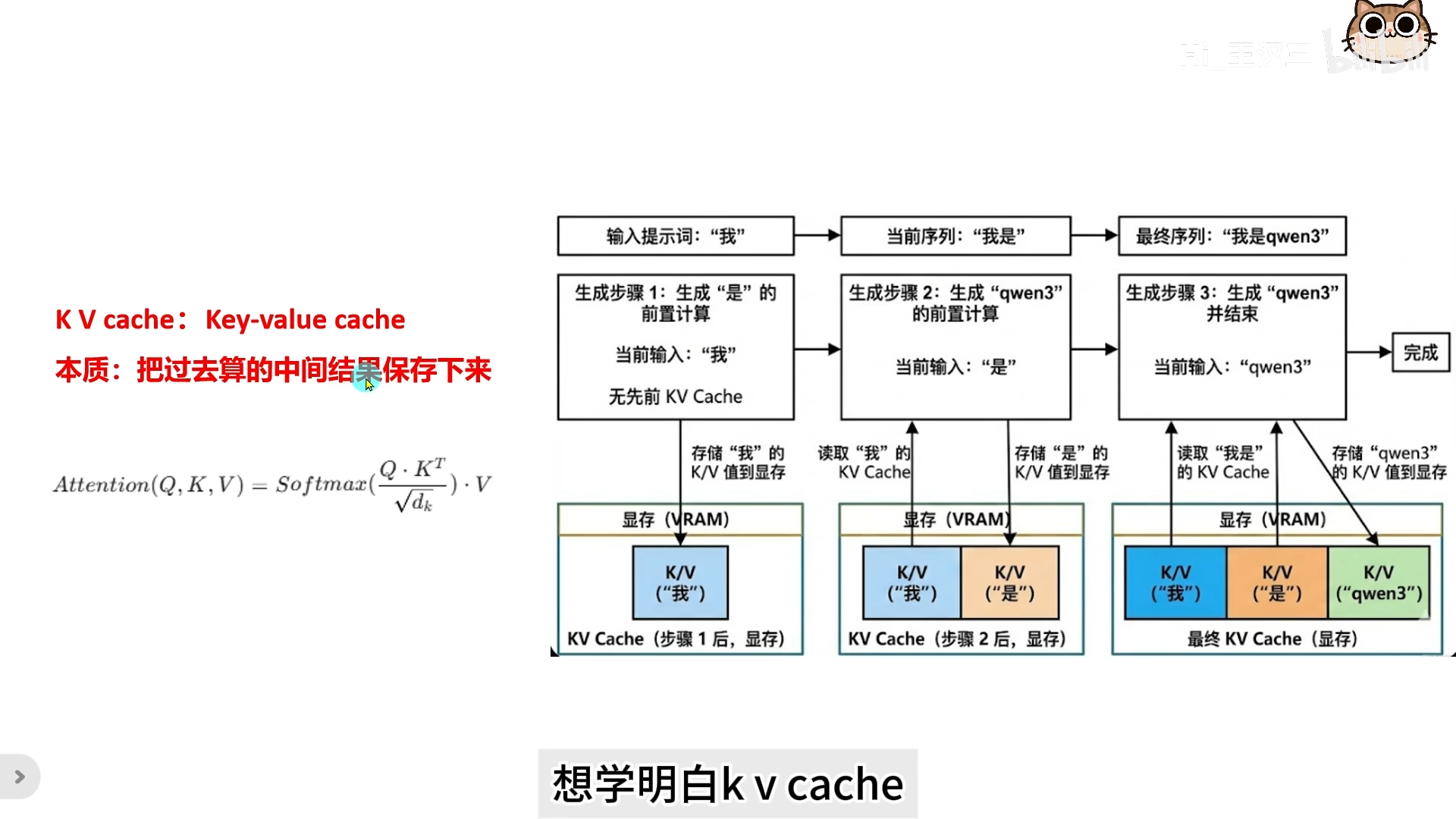
KV Cache(Key Value Cache)是大型语言模型在推理阶段为加速生成速度而引入的核心机制。其本质是将过去计算过的中间结果(K值和V值)存储下来,避免重复计算**,本质是**用空间换时间**的操作。
1.2 工作原理
我们先回顾自注意力的公式:
设输入 X∈Rn×d,n 为序列长度,d 为隐藏维度。单头注意力:
模型的每一层在做自注意力时,都需要计算 Q、K、V。如果没有 KV Cache,生成每个新 token 时,整个历史上下文都要重新过一遍模型,历史 token 的 K、V 被反复计算,效率极低。
如果我们将每一步计算的 K 值和 V 值缓存到 GPU 显存中,下次生成时直接复用历史 KV 值,只需计算新 token 的 KV。KV Cache 的存储计算方式为:
其中 为层数, 为隐藏维度, 为序列长度,bytes 在 fp16 下为 2。单条序列、fp16 时简化为:
1.3 核心价值:两种方式的对比
无 KV Cache 的朴素做法:每生成第 t 个 token,都把整个序列 [x1,x2,…,xt] 再过一遍 Transformer,重新计算所有 token 的 Q、K、V。
| 生成步骤 | 重新计算的 token |
|---|---|
| 预测 token 2 | 重新算 token 1 的 K、V |
| 预测 token 3 | 重新算 token 1、2 的 K、V |
| 预测 token 4 | 重新算 token 1、2、3 的 K、V |
| 预测 token n | 重新算 token 1 到 n−1 的 K、V |
冗余量:到第 n 个 token 时,历史 token 的 K、V 已被重复计算 (n−1)×L×H 次(L 层、H 个头)。
复杂度对比
| 方式 | 每步计算量 | 总复杂度 |
|---|---|---|
| 朴素 | 对 t 个 token 做完整前向 | O (n2)(n 为生成长度) |
| KV Cache | 只算当前 token 的 Q、K、V,K/V 从缓存读 | O(n) |
核心价值:KV Cache 让计算量从 O (n²) 降至 O (n),句子越长,加速效果越明显。
这意味着上下文越长,显存压力越大。这就引出了下一个问题 —— 如何减少 KV Cache 的大小。
硬件瓶颈
- GPU 算力很强,但内存带宽有限(参考之前的公众号文章:# 谈谈 CPU、内存、显存、GPU 在大模型的作用和性能瓶颈)
- 朴素方式每步都要从显存反复读入整段历史的 K、V,带宽成为瓶颈
- 注意力变成 memory-bound,GPU 大量时间在等数据
- KV Cache 把历史 K、V 留在显存,减少重复搬运,显著加速
KV Cache 使用场景
| 场景 | 是否用 KV Cache |
|---|---|
| 训练 | 不用。训练时整段序列一次性前向,所有 token 并行算注意力,不存在「逐步生成、重复算历史」的场景。 |
| 推理 / 文本生成 | 用。逐 token 自回归,KV Cache 可大幅加速 |
| 预填充(Prefill) | 第一次处理 prompt 时,可批量算完 prompt 的 K、V 并写入 cache |
| 解码(Decode) | 每生成 1 个 token,只算新 token 的 Q、K、V,K、V 追加到 cache |
结论:KV Cache 是推理优化手段,训练不涉及。
1.4 为什么只缓存 K、V,不缓存 Q?
- K、V 可复用:推理时模型权重不变,历史 token 的 embedding 也不变,因此每个历史 token 的 和 是确定性的,只需计算一次,后续所有生成步骤均可复用 、。它们代表过去 token 的 “被查询” 表示,只需算一次,永久有效。
- Q 不可复用:Q 是当前 token 的 “查询” 向量,代表 “当下”。每步生成的 token 不同,Q 也完全不同。它只用于当前步去 “问” 历史,下一步会换成一个全新的 Q。因此缓存 Q 毫无意义。
一句话总结:K、V 是历史的 “被查询者”,只需算一次;Q 是当下的 “查询者”,每步都变,缓存无用。
二、 GQA(分组查询注意力)原理
2.1 背景问题
随着大模型上下文长度不断增加(如 32K、128K),KV Cache 占用的显存会变得非常恐怖,甚至超过模型权重本身。这不仅占用大量显存,更重要的是 GPU 读取 KV Cache 的速度跟不上计算速度,导致推理过程中卡顿、速度变慢。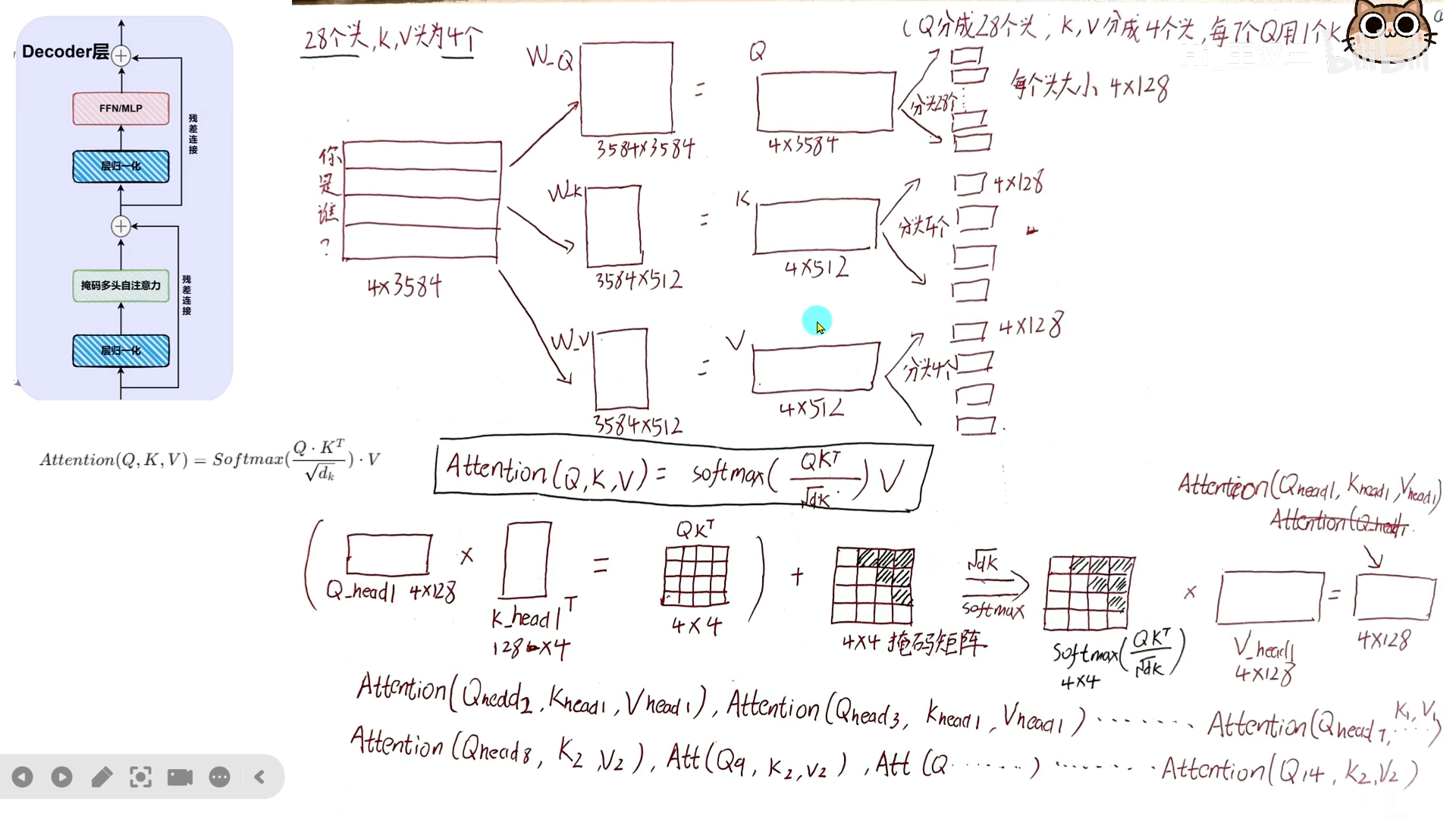
2.2 GQA 核心思想
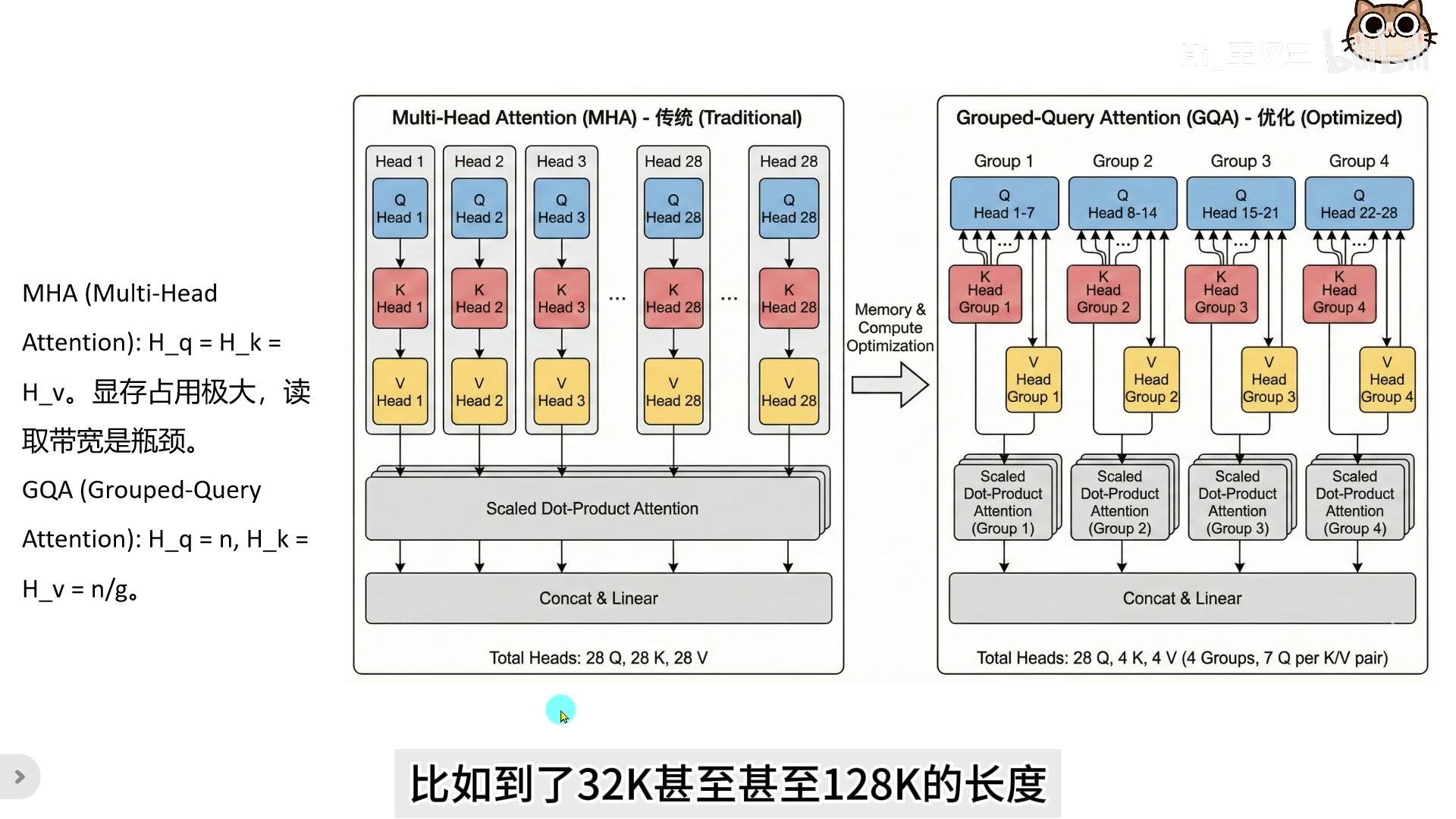
GQA(Grouped Query Attention,分组查询注意力)的核心思想是:Query 头数远多于 KV 头数,多个 Query 头共享一组 KV 头。
以 Qwen3 为例:
- Q(Query)分成 28 个头
- K(Key)和 V(Value)各分成 4 个头
- 每 7 个 Query 头共享 1 组 KV 头
2.3 分头操作详解
假设隐藏层维度 ,每个 head 维度 :
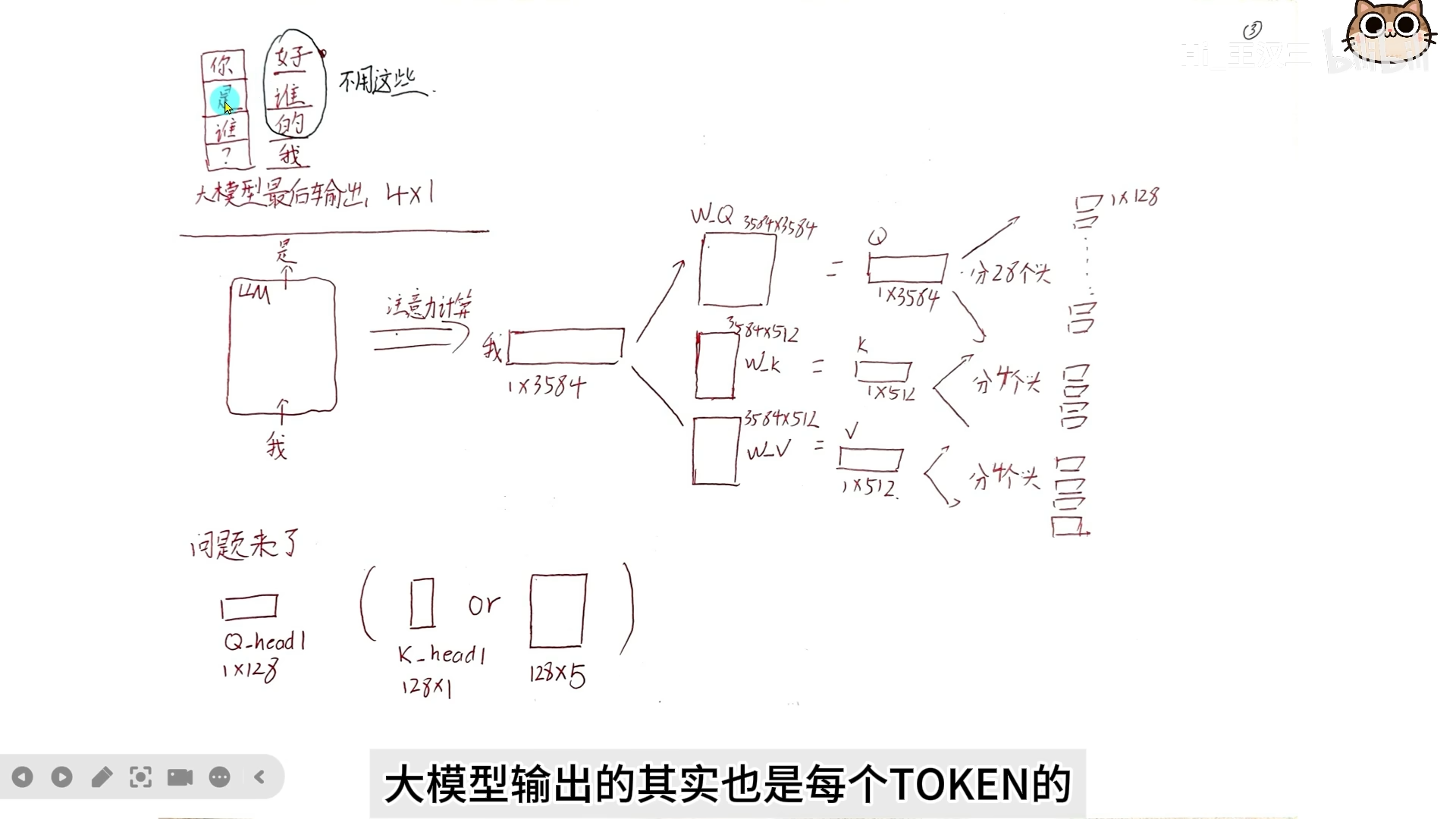
Query 分头:
- 3584 维切成 28 份,每份 128 维
- 即 维度为
Key/Value 分头:
- 3584 维切成 4 份,每份 128 维
- 即 维度为
计算时:
- 到 与 、 配对计算
- 到 与 、 配对计算
- 以此类推…
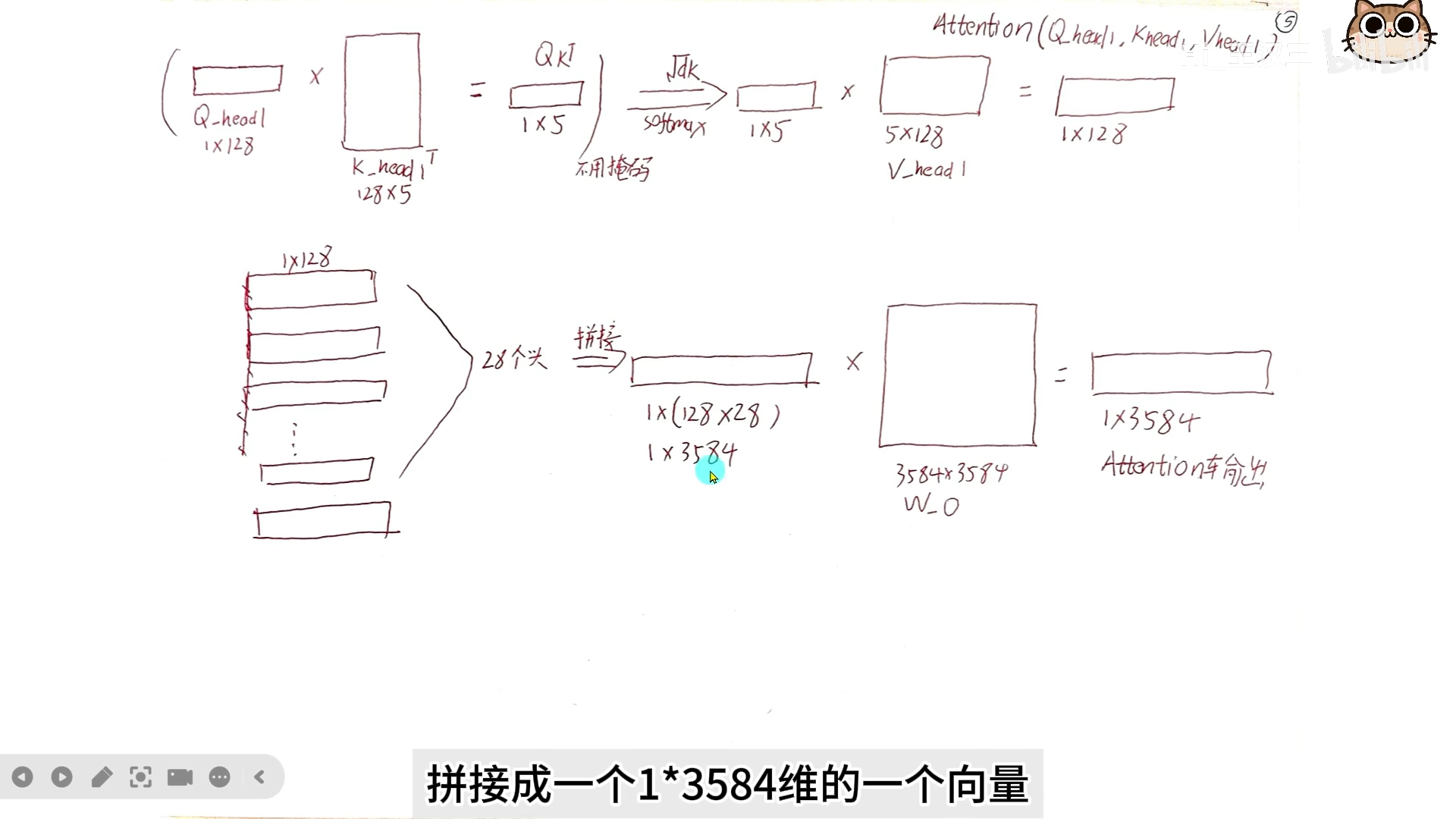
最后 28 个 head 的输出拼接后,通过输出权重矩阵 汇总成一个向量。
2.4 显存节省分析
| 项目 | MHA(多头注意力) | GQA(分组注意力) |
|---|---|---|
| KV 头数 | 28 | 4 |
| 显存占用 | 28 份 | 4 份 |
| 压缩比 | 1x | 约 7 倍 |
GQA 在不显著损失模型精度的情况下,大幅压缩了 KV Cache 的显存占用,使得模型能够支持更长的上下文。
三 KV Cache 与 GQA 协同工作
4.1 第一轮推理(首次输入)
输入序列:“你”、“是”、“谁”、“?”
- 编码:4 个 token → 向量
- 分头:Q 分成 28 头,K、V 各分成 4 头
- 计算:各 head 分别计算自注意力
- 输出:预测下一个 token(如 “我”)
- 缓存:将 K、V 值存入显存
4.2 第二轮推理(生成新 token)
输入序列:“你”、“是”、“谁”、“?”、“我”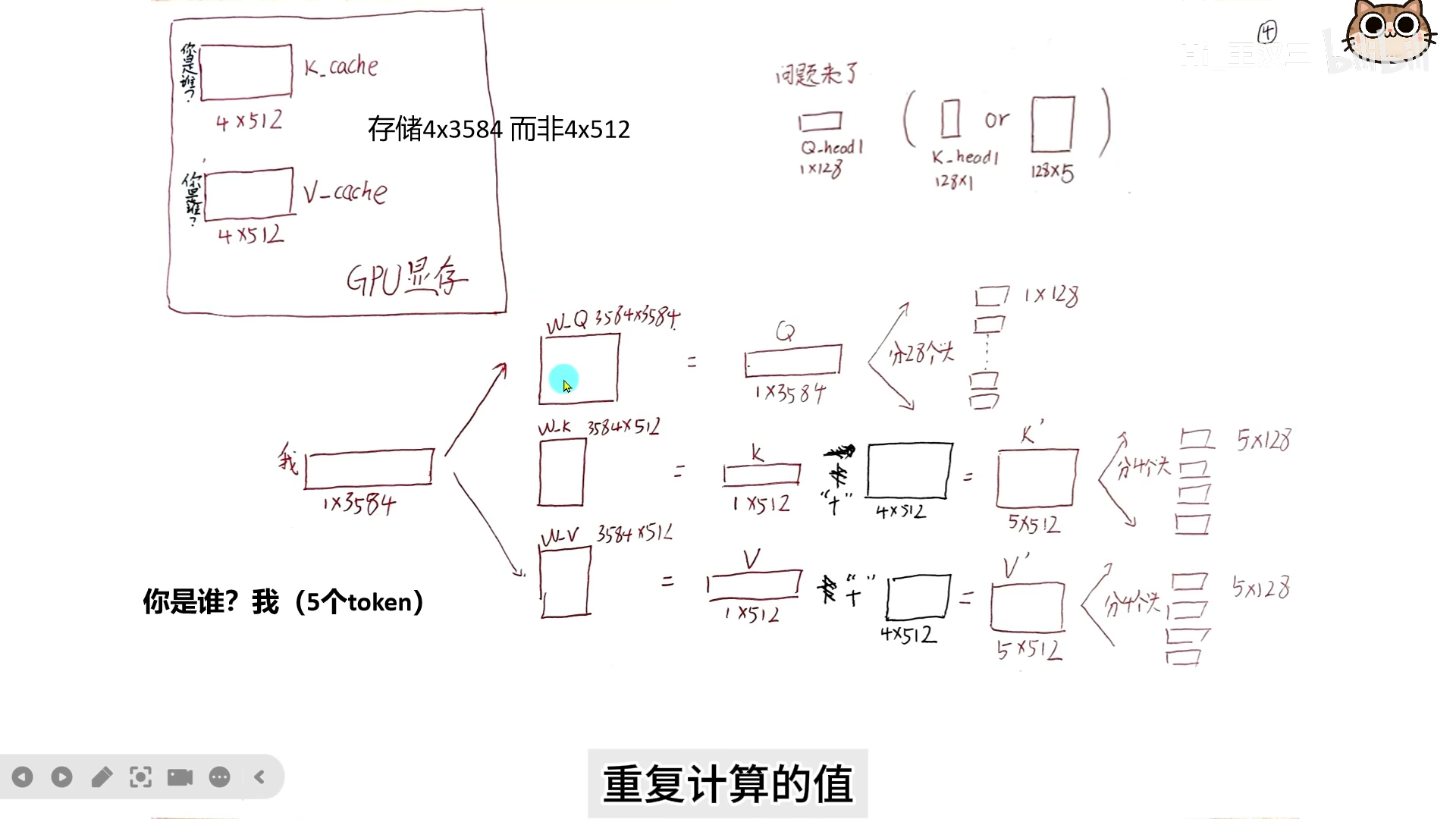
- 复用缓存:从显存读取第一轮的 K、V
- 新 token 计算:只计算 “我” 的 K、V( 维)
- 拼接:新 K/V 与缓存的 K/V 拼接
- 不是相加,是拼接(沿序列维度)
- 拼接后: 维( 或 )
- 分头后计算:
- ()× ()→ 矩阵
- 经 softmax、mask 处理后 × → 输出
- 拼接 28 个 head 输出 → 乘以 → 最终输出
- 缓存更新:将新的 K、V 加入缓存
4.3 关键优化点
- 避免重复计算:无需重新计算 “你是谁?” 的 K、V
- 显存压缩:GQA 使得 KV Cache 只存储 4 头而非 28 头,显存节省约 7 倍
- 推理加速:计算量大幅减少,生成速度显著提升
五、面试题与答案
题目 1:什么是 KV Cache?它的作用是什么?
答案:
KV Cache(Key Value Cache)是 LLM 推理阶段的核心加速技术。作用是用空间换时间:将每一步计算的 K 值和 V 值缓存在 GPU 显存中,避免每次生成新 token 时重复计算历史 token 的 K、V,从而大幅提升推理速度。
以 “你是谁?我” 为例:第二轮推理时,无需重新计算 “你是谁?” 的 K、V,只需计算 “我” 的 K、V 并与缓存拼接,节省大量计算资源。
题目 2:KV Cache 面临的最大挑战是什么?
答案:
显存瓶颈。随着上下文长度增加(如 32K、128K),KV Cache 占用的显存急剧增长,甚至超过模型权重本身。这不仅占用大量显存,更重要的是 I/O 带宽成为瓶颈 ——GPU 读取 KV Cache 的速度跟不上计算速度,导致推理卡顿。
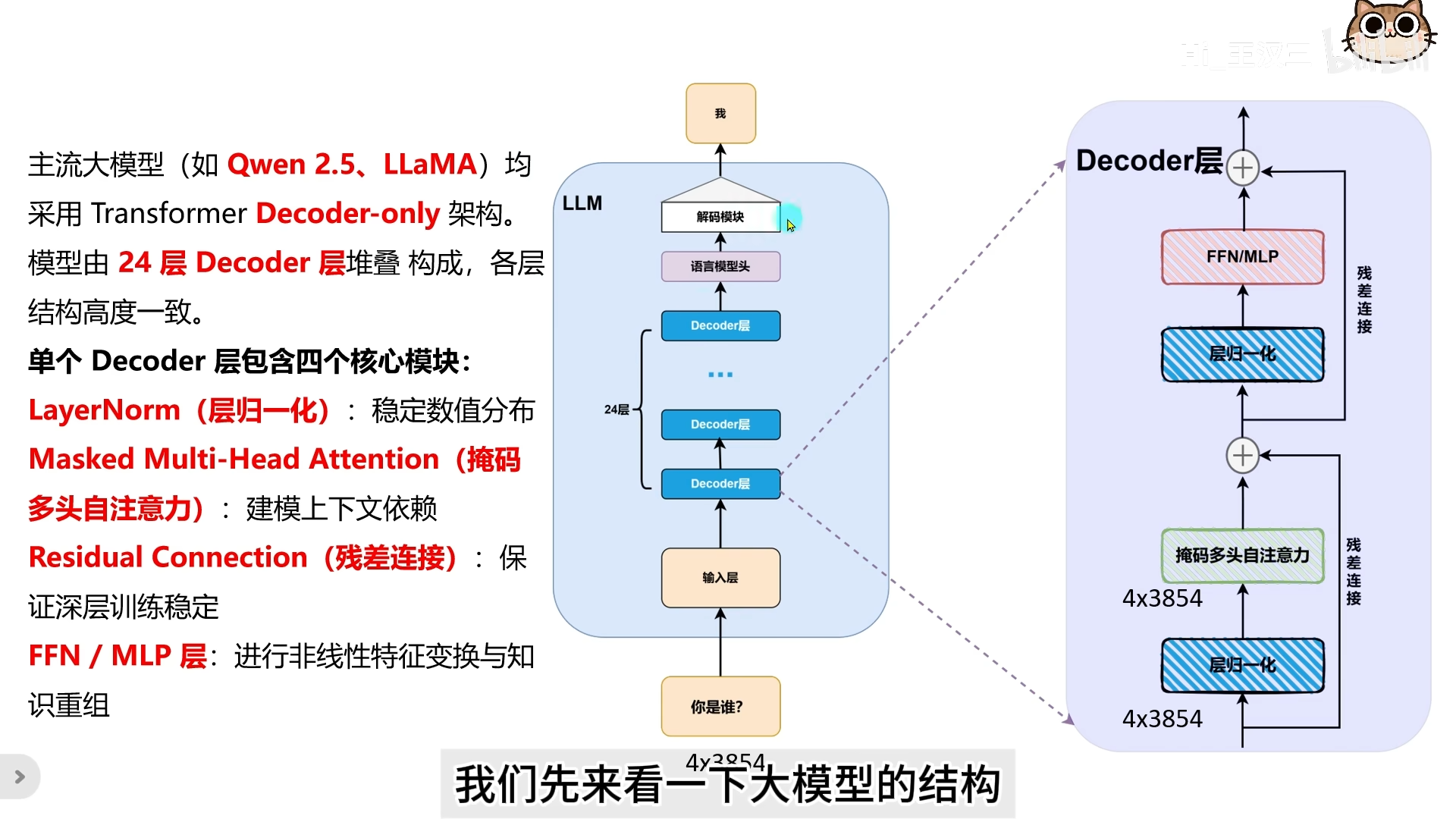
题目 3:Transformer Decoder 层的核心组件有哪些?KV Cache 发生在哪一步?
答案:
Decoder 层包含 4 个核心组件:
- Layer Normal:层归一化,稳定数值
- MHA/MQA/GQA:多头自注意力层,KV Cache 发生在此
- 残差连接:保持训练稳定
- FFN(MLP):非线性变换,大模型的知识存储模块
KV Cache 发生在自注意力层的计算过程中:将每层产生的 K、V 值缓存,以便后续 token 生成时复用。
题目 4:为什么说 KV Cache 本质是 “空间换时间”?
答案:
KV Cache 通过额外占用 GPU 显存空间,换取推理时间的减少:
- 不缓存:每次生成都要重新计算历史 token 的 K、V,时间复杂度 O (n²)
- 缓存:只需计算新 token 的 K、V,时间复杂度降为 O (n)
空间代价:KV Cache 显存占用 ≈ 2 × 层数 × 序列长度 × 隐藏维度 × 2 字节(fp16)
时间收益:长序列生成时,计算量从 O (n²) 降为 O (n),加速显著。
题目 5:KV Cache 在实现时需要注意哪些问题?
答案:
- 显存管理:需要合理分配和释放显存,避免 OOM
- 增量更新:新增 token 时,只需计算其 K、V 并拼接,而非全量重算
- Mask 处理:拼接后需正确应用 causal mask(因果掩码),确保 attention 只看前缀
- 长度限制:虽然有 KV Cache,但最大上下文长度仍受限于 max_position_embeddings
- 批处理优化:多个请求可共享部分 KV Cache(Flash Attention 等优化)
题目 6:简述 GQA 中 Query 与 KV 头配对的计算过程。
答案:
假设 Q 有 28 个头,KV 有 4 个头:
- 分组规则:,每 7 个 Q 头共享 1 个 KV 头
- 配对计算:
- ~ 分别与 、 计算注意力
- ~ 分别与 、 计算注意力
- 以此类推…
- 输出合并:28 个 head 的输出拼接后,通过 矩阵汇总成最终输出
补充:MHA、MQA、GQA 进化专题
相同点
- 都属于自注意力机制的变体,用于 Transformer 模型。
- 都包含 Query(Q)、Key(K)、Value(V) 的线性投影,然后计算注意力得分。
- 都可以在训练和推理中使用。
不同点
1. 多头结构
- MHA:Q、K、V 都拆分成多个头(例如 8 个头),每个头独立计算注意力,最后拼接。
- MQA:K 和 V 只有一个头(即所有 Query 头共享同一个 K、V),而 Q 仍然有多个头。
- GQA:将 K 和 V 分成若干组(例如 4 组),每组对应多个 Query 头。也就是介于 MHA 和 MQA 之间。
2. 计算量(FLOPs)
- 在生成阶段(自回归解码):
- MHA 每个头都要计算自己的 K、V,计算量最大。
- MQA 因为 K、V 只有一个共享头,计算量最小(约减少为 MHA 的 1/num_heads)。
- GQA 的 K、V 分组数(g)通常小于头数(h),计算量比 MHA 小,但比 MQA 大:约是 MHA 的 g/h。
- 在训练阶段:三者计算量接近(因为训练时并行处理所有序列位置),但 MQA 和 GQA 因为 K、V 分头少,也有一些微小节省。
3. 显存占用(特别是 KV Cache)
- KV Cache 是自回归推理时为每个已生成 token 缓存的 K、V 张量,用于加速后续计算。
- MHA:每个头都要缓存 K 和 V,所以缓存大小为
(batch_size, num_heads, seq_len, head_dim)× 2。 - MQA:所有头共享同一份 K 和 V,缓存大小仅为
(batch_size, 1, seq_len, head_dim)× 2,显存降低约 num_heads 倍。 - GQA:缓存大小为
(batch_size, g, seq_len, head_dim)× 2(g 为分组数),显存占用介于 MHA 和 MQA 之间,降低为 MHA 的 g/num_heads。
- MHA:每个头都要缓存 K 和 V,所以缓存大小为
4. 模型效果
- MHA:表达能力最强,每个头可以关注不同的模式,通常效果最好。
- MQA:由于 K、V 共享,会降低表达能力,导致模型效果略差,尤其是在需要 K、V 区分度大的任务上(如长文本、细粒度语义)。
- GQA:通过分组折中,在保持部分多样性的同时大幅降低显存。实践中(如 LLaMA 2 70B 使用 GQA),效果接近于 MHA,而显存效率远高于 MHA。分组数越大(越接近 MHA)效果越好,但显存节省越少。
总结表格
| 特性 | MHA | MQA | GQA |
|---|---|---|---|
| K、V 头数 | 等于 Q 头数(h) | 1 | 分组数 g(通常 1 < g < h) |
| 训练计算量 | 高 | 略低(可忽略) | 介于中间 |
| 推理 KV Cache 显存 | 高(h 倍) | 极低(1/h) | 低(g/h) |
| 模型效果 | 最好 | 略差 | 接近 MHA |
| 适用场景 | 训练、大显存 | 极端显存受限 | 主流高效推理(如 LLaMA 2/GPT-4) |
实际选择:MHA 适合训练,MQA 适合极小显存设备,GQA 是目前平衡效果和效率的最佳方案。
核心概念
MHA(Multi-Head Attention,多头注意力) 是 Transformer 架构中原生的注意力机制。其核心思想是将 Q、K、V 矩阵的词向量维度拆分为多个子空间,每个子空间由一个独立的 “头” 进行处理,各头并行计算注意力后拼接融合输出。
MQA(Multi-Query Attention,多查询注意力) 于 2019 年提出,通过让所有 Q 头共享同一组 K 和 V 头来大幅减少 KV Cache 显存占用,是 MHA 的推理优化变体。
GQA(Group-Query Attention,分组查询注意力) 是 MHA 与 MQA 的折中方案,将 Q 头划分为多个组,每组共享一组 KV 头,在显存效率与模型表达能力之间取得平衡。
MHA 详解
计算流程:
- 输入经线性变换得到 Q、K、V 三个矩阵
- 将 d_model 维向量按头数均分(如 768 维 / 3 头 = 每头 256 维)
- 各头独立执行 Scaled Dot-Product Attention 计算
- 各头输出拼接后经线性变换得到最终结果
核心优势:
- 多头并行计算可捕捉不同类型的语义关联(如主语关系、指代消解、词序关系等)
- 不同头关注不同子空间的特征,提升模型表达能力
MQA 详解
问题背景:MHA 存在两个显存瓶颈:
- 显存占用:每个 token 均需存储独立的 KV Cache,序列越长显存压力越大
- 带宽瓶颈:每次前向传播需将 KV Cache 从显存搬运至计算单元,KV 过大时数据搬运成为性能瓶颈
实现方式:将 KV 头数从 H 压缩为 1,所有 Q 头共享同一组 KV。
- KV Cache 体积降至 MHA 的 1/H
- 显存占用显著下降
代价:所有 Q 头共用一组 KV,信息来源被压缩,模型表达能力有所下降。
GQA 详解
原理:在 MQA 基础上引入分组机制,将 Q 头划分为 G 个组,每组内 Q 头共享一组 KV。
数学关系:
- 分组数 G = Q 头数 → 等价于 MHA(每头独立 KV)
- 分组数 G = 1 → 等价于 MQA(所有头共用 KV)
设计理念:通过适当选择分组数,在保持一定表达能力的同时节省显存。
实际应用:Qwen3 系列采用 32 个 Q 头、8 个 KV 头,分为 8 组;LLaMA 2/3 也采用 GQA 架构。
三者对比
| 特性 | MHA | MQA | GQA |
|---|---|---|---|
| 表达能力 | 最强 | 较弱 | 中等(取决于分组数) |
| KV Cache 大小 | H 组 | 1 组 | G 组 |
| 显存占用 | 最大 | 最小 | 中等 |
| 计算效率 | 一般 | 最高 | 较高 |
总结
三种注意力机制代表不同的设计权衡:
- MHA:表达能力最强,显存占用最高,适合训练阶段
- MQA:显存占用最小,推理效率最高,但表达能力下降明显
- GQA:在表达能力与显存效率之间取得平衡,已成为大模型推理优化的主流选择
MQA 与 GQA 提出的根本目的是解决大模型推理时的 KV Cache 瓶颈,该瓶颈不仅涉及显存占用本身,还涉及显存带宽瓶颈 —— 当 KV Cache 过大时,数据搬运速度成为制约推理速度的关键因素。
面试题与答案
Q1:什么是 MHA(多头注意力)?它的核心优势是什么?
A1:MHA(Multi-Head Attention)是 Transformer 论文中提出的注意力机制。其核心思想是将 QKV 矩阵的词向量维度拆分为多个子维度,每个子维度由一个独立的 “头” 进行处理。各头独立计算注意力后,最终将结果拼接融合。
核心优势包括:
- 多头并行计算可捕捉不同类型的语义特征(如主语关系、人称代词、单复数等)
- 不同的头可关注不同子空间的特征表示,显著提升模型表达能力
- 在总维度不变的情况下,通过子空间分解增强模型对复杂关联的学习能力
Q2:MQA(多查询注意力)解决了 MHA 的什么问题?如何实现的?
A2:MQA 主要解决 MHA 的 KV Cache 显存瓶颈 问题,具体包括:
- 显存占用过高:每个 token 均需存储独立的 KV Cache,输出序列越长显存压力越大
- 显存带宽瓶颈:每次计算注意力时需将 KV Cache 从显存搬运至计算单元,KV 矩阵过大时数据搬运成为性能瓶颈
实现方式:将 KV 头数量从 H 个压缩为 1 个,所有 Q 头共享同一组 KV。
- KV Cache 大小降至 MHA 的 1/H
- 原本需要存储 H 份 KV,现在仅需存储 1 份
- 显存占用可下降数十倍
代价:所有 Q 头共用同一组 KV,信息来源被压缩,模型表达能力会有所下降。
Q3:GQA(分组查询注意力)的工作原理是什么?它与 MHA、MQA 有什么关系?
A3:GQA 将 Q 头划分为多个组,每组内的所有 Q 头共享同一组 KV 头。
数学关系:
- 当分组数 = Q 头数时 → 退化为 MHA(每头独立 KV)
- 当分组数 = 1 时 → 退化为 MQA(所有头共用 KV)
- 分组数在 1 和 Q 头数之间时 → GQA
设计理念:GQA 是 MHA 和 MQA 的折中方案。通过适当设置分组数,既能保持一定的表达能力,又能节省显存。相比 MQA,GQA 增加了 KV 头的多样性;相比 MHA,GQA 减少了 KV Cache 的体积。
应用实例:Qwen3 系列采用 32 个 Q 头、8 个 KV 头,即分为 8 个组;LLaMA 2/3 系列也采用 GQA 架构。
Q4:为什么说 KV Cache 的显存瓶颈不仅涉及显存本身,还涉及显存带宽?
A4:因为推理过程中存在数据搬运瓶颈:
- 计算前提:每次计算注意力时,必须先将 KV Cache 从显存搬运到 GPU 计算单元
- 瓶颈转移:当 KV 矩阵过大时,模型的性能瓶颈往往不是 GPU 算力不足,而是数据搬运速度跟不上
- 因果关系:KV Cache 体积大 → 搬运耗时长 → 计算单元等待 → 整体推理速度被拖累
因此,MQA/GQA 减少的不仅是显存占用,还有待搬运的数据量,从而同时缓解了显存和显存带宽的双重瓶颈。
Q5:如果一个模型有 16 个 Q 头,要使用 GQA 并使其显存占用为 MHA 的 50%,需要设置多少个 KV 头?请说明计算过程。
A5:需要设置 8 个 KV 头。
计算过程:
- MHA 配置:16 个 Q 头对应 16 组 KV,显存占用为 100%
- 目标显存占用:50%,即需要 16 × 50% = 8 组 KV
- 因此设置 8 个 KV 头,16 个 Q 头分为 8 组,每组 2 个 Q 头共享 1 组 KV
验证:原 16 组 KV 降至 8 组 KV,显存占用正好降低 50%。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)