【AI】【Agent】Agent相关名词的通俗易懂解析
一、LLM(Large Language Model,大语言模型,简称大模型)
类似最开始的GPT3.5,以至于后来的豆包和DeepSeek,常使用的对话形式的AI。
人类的自然语言描述给到大模型,大模型经过内部的运算预测并给出一个准确率较高的回答,之后继续对话,会结合之前的对话历史记录(即上下文),再给出答案,直至人类得到完整的答案。
二、Token(词元,大模型处理文本的「最基本单位」)
大模型的内部做的是执行函数、矩阵运算等等。输入输出皆是数字,无法识别人类的语言。
进一步细分的话,就需要一个中间件进行翻译人类自然语言,这个就是Tokenizer
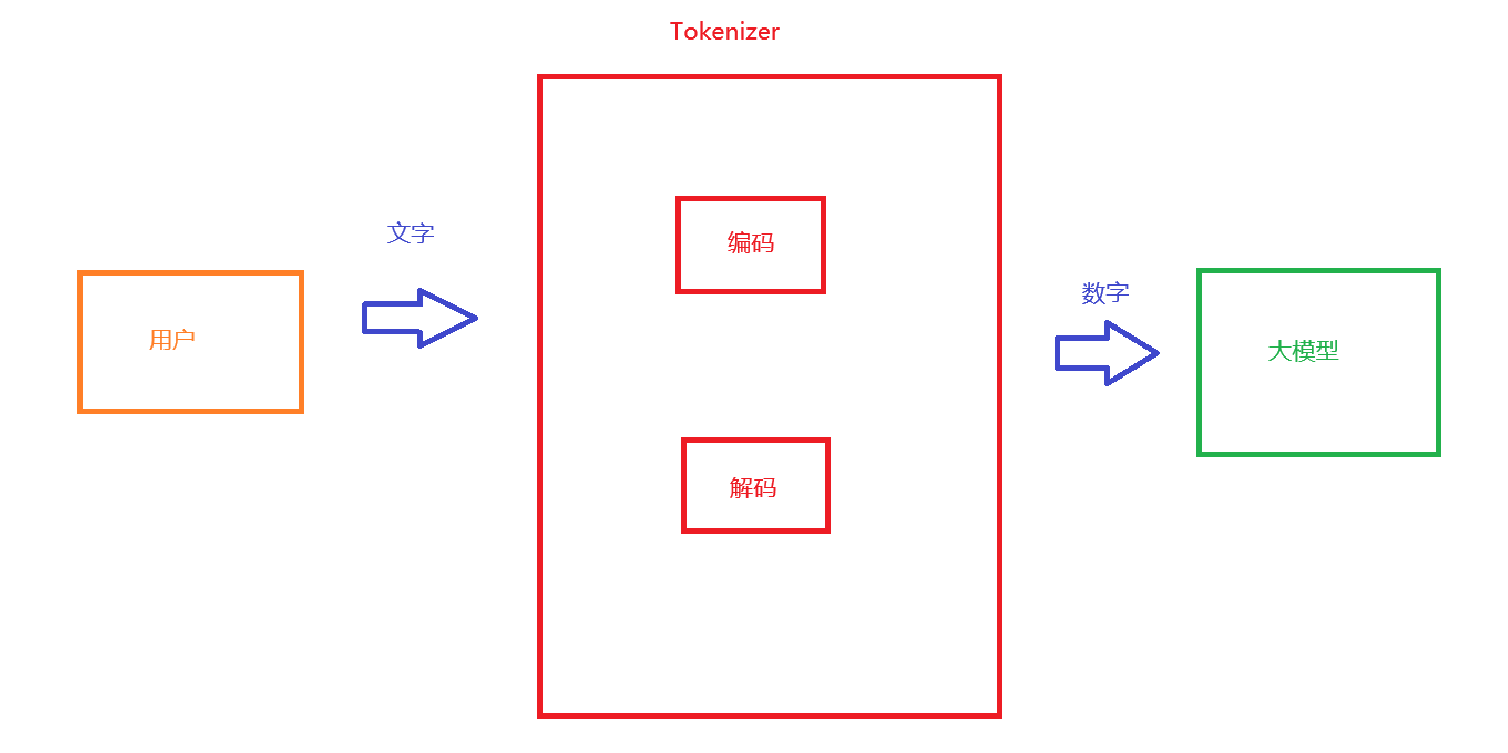
将文字切分并映射为数字
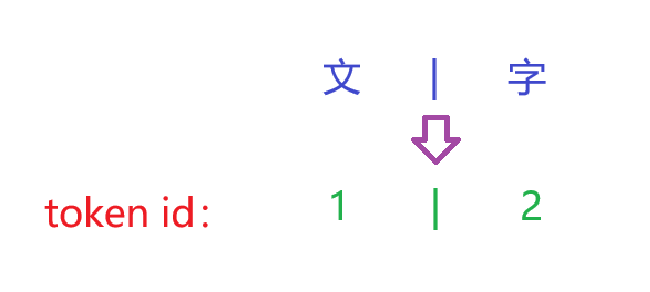
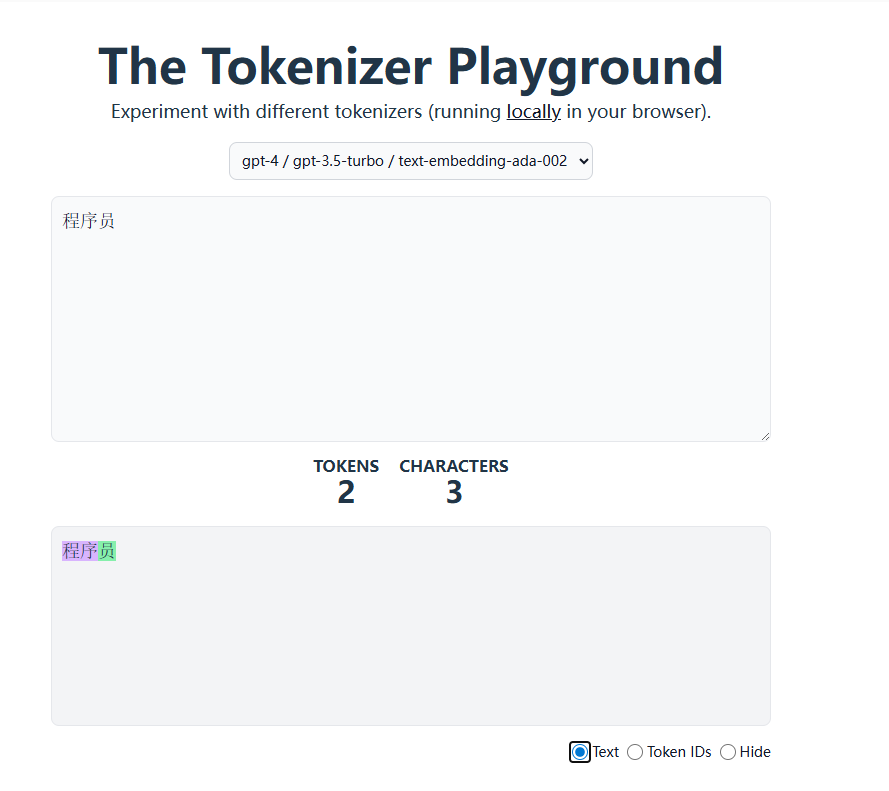
2.1 切分测试
Token 計算機 - AI 模型的文字到 tokens 轉換 | Token Counter

三、Context(上下文,大模型的临时记忆体,大模型每次处理任务时接收到的信息总和)
Context是有极限的。
整个对话记录。
四、Context Window(上下文窗口,能容纳的最大词元数量)
描述整个对话记录的大小。
五、prompt(提示词,用户或系统当前给大模型下达的具体指令或问题)
5.1 User Prompt(用户输入具体任务)
5.2 System Prompt(人设和所处的规则环境)
六、Tool(工具,本质上是一个函数,大模型用来感知和影响外部环境的函数)
根据训练数据给出答案,对于外部的一写实时数据需要借助外部工具进行获取。
大模型只是输出文本。
用户、平台、LLM、工具,四个部分一起合作。需要时,大模型需要向平台申请,平台再调用函数使用外部工具,获取实时数据。
七、MCP(Model Context Protool,模型上下文协议,统一了接入格式的标准协议)
对于各个AI厂家,AI模型接入各种工具 / 数据源 / 上下文时需要统一规范,对于程序员,提到这种,我们马上会想到“协议”。MCP管理LLM与外部世界资源的对接规则


八、Agent(智能体)
到MCP,大模型已经能够使用数据源和调用外部工具,不在只是局限于纯文本交流,再进一步,调用更多的工具,使用足够的权限,完成更为复杂的任务,接近人类的自主规划,成为更强大的系统,即Agent
九、Agent Skills(简写为Skills)(技能,类似使用说明文档,存储在SKILL.md文件)
当有了智能体,那么,在日常使用时,仍然会感觉到给出的答案还是偏大众化,不符合个人习惯,或者公司规范,但是却需要经常使用到这些,为了不重复输入习惯或者规范相关的提示词,则扩展出Skills功能,制定一套个人习惯模板(或者公司规范,或者特定的工作流),然后让Agent输出对应的成果。
以及,会说到把某个人蒸馏为skill,这个本质上是在总结他人的思维方式和解题方法,到文本中,总结出一套prompt,压缩形成一个skill。(经验/风格结构化成 Skill)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)