【踩坑解决】多GPU(DataParallel)训练模型,单GPU测试报错、准确率固定0.5问题根治
·
一、问题背景与现象
本人在使用 GoogLeNet 网络训练猫狗分类竞赛数据集 时,为提升训练速度,采用双卡DataParallel 多GPU并行训练 方式训练模型,并保存最优权重文件 .pth。后续切换至单GPU环境进行模型测试验证时,接连出现两大致命问题:
1.直接加载权重报错:权重参数全部带module.xxx前缀

2.使用strict=False 强制加载后不报错了,但是模型测试准确率永远固定 0.5
#原本的加载模型的代码
model.load_state_dict(torch.load('best_model_cat_vs_dog.pth'))
#使用state=False,强制加载模型
model.load_state_dict(torch.load('best_model_cat_vs_dog.pth'), strict=False)结果
![]()
二、报错根本原因
1.多GPU训练会强制给所有权重添加 module. 前缀
PyTorch 使用 nn.DataParallel 多卡训练时,会自动包装模型,保存的权重字典中,每一层参数名前面都会多出 module.
多GPU保存权重名:module.b1.0.weight
单GPU模型参数名:b1.0.weight
2. 准确率固定0.5
strict=False 的作用是:忽略不匹配的参数,只加载能对上的参数。因为使用双卡训练,所有权重都带 module.,所以全部都对不上,在猫狗这种二分类任务下,只能随机猜测,故测试准确率一直在0.5左右
三、最终解决方案
加载权重文件,手动遍历权重字典,批量删除 module. 前缀,然后最后在正常加载去掉module.前缀的模型,即可正常完成测试
# 1. 加载权重文件
state_dict = torch.load('best_model_cat_vs_dog.pth', weights_only=True)
# 2. 自动去掉多GPU保存的 "module."
new_state_dict = {}
for key, value in state_dict.items():
new_key = key.replace("module.", "")
new_state_dict[new_key] = value
# 3. 正常加载
model.load_state_dict(new_state_dict)解决之后测试准确率恢复正常:
![]()
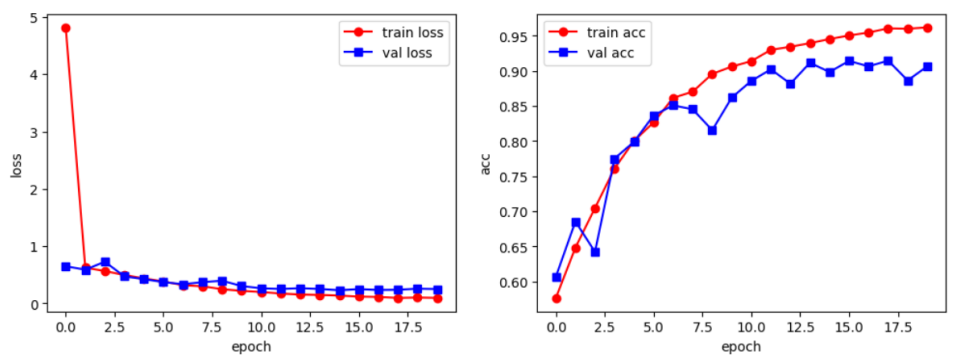
与如下训练和验证得到的准确率相比,发现问题得到解决,模型测试可正常进行:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)